
24년 4월 넷째주 그래프 오마카세
Simple Spectral Graph Convolution
ICLR 2021
Keywords
Simple Graph Convolution, Markov Diffusion Kernel
Background
- GCN (kipf et al.)이 수많은 Graph Convolution 정의의 바탕이 되고 있으며, Variant networks의 발전이 빠르게 이루어지고 있는 사실은 다들 잘 아시고 계실 것입니다.
- 기존 Spectral Graph Convolution 정의를 Approximation하여 Operation process를 단순화하였으며, Normalized Graph Shift Operator (GSO) 및 여럿 Tricks를 추가하여 Oversmoothing 문제를 회피하면서 적은 레이어로도 Semi-supervised Learning 분야에서 좋은 성능을 달성할 수 있는 점에서 큰 기여를 하였다는 것을 알 수 있습니다.
- 하지만, Residual connection을 통해 이전 레이어의 정보를 잃어버리지 않으면서 레이어를 매우 깊게 쌓을 수 있으며 상당한 Benefit을 얻어낼 수 있는 CNN의 장점을 GCN에서는 제한적이라는 점이 현재까지도 거론되고 있는 문제 중 하나로 남아있습니다.
- 이는 레이어를 깊게 쌓을수록 그래프 상 모든 노드의 Feature value가 유사해짐으로써 Class distinguishable 할 수 없어지게 되는 Oversmoothing 현상이 존재하기 때문입니다. 다음 문제는 이전 오마카세에서 다루어본 Spectral Graph Convolution의 Aggregation terms를 잘 살펴보면 이해해볼 수 있는 부분이라 생각합니다.
- 결과적으로 대부분의 GCN 기반 Variant models는 깊은 레이어를 쌓을 수 없고 대체로 2개의 레이어로만 도메인 성능을 커버하는 경향이 존재하며, Long-range Dependency를 포착하지 못하는 한계점을 드러내게 됩니다. 즉 Global Relation 정보를 놓치기 쉬우며, Real world dataset에서 만연한 중요한 Feature를 학습하지 못하게 됨으로써 성능적으로도 나쁜 결과를 얻어내게 됩니다.
- 이러한 문제를 해결하기 위해 많은 방법론들이 제안되어져 왔으나, 이번에 소개해드릴 오마카세는 vanilla GCN의 Non-linear 성분을 제거함으로써 Computational Complexity를 크게 감소시키면서도 더 높은 성능을 달성할 수 있었던 SGC (Wu et al.) 모델의 새로운Specteal kernel 설계를 기반으로 접근한 논문 한편을 소개해드리겠습니다.
Introduction
- 다음 논문에서도 GCN의 문제점 (Limit of stacking layers, oversmoothing)을 언급하면서, 그 원인으로 모델 설계과정에서 Required Neighbors size와 Depth of Neural Network 설정이 서로Independent하게 고려된다는 사실을 언급합니다.
- 위의 설명을 생각해보면, 높은 Similarity를 갖는 이웃 노드들을 모두 커버하기 위한 Optimal Receptive Field와 최대 2개로 지정되는 Layer Depth의 Cover Boundary는 서로 비례하지 않는다는 것으로 이해해볼 수 있습니다.
- 일부 연구 (Klicpera et al.)에서는 기본 Convolution mechanism을 수정하기 위해, Personalized PageRank Matrix를 활용하여 Power of Normalized Adjacency matrix를 대체하는 방법을 제안하였습니다. 그로써 Oversmoothing 문제를 완화할 수 있었으나, Highly complexity 및 Long-range dependency 문제를 해결하지 못하였습니다.
- 다음 논문에서는 그래프 스펙트럼 이론을 기반으로 한 Oversmoothing 및 Long-range dependency 문제들을 해결할 수 있는 방법론을 설명합니다. 핵심 아이디어는 Network depth의 의존도에서 벗어나, Aggregated Neighbors boundary를 점진적으로 확대해가면서 Local & Global context를 동시에 포착할 수 있는 Low & High-pass filter bands의 Trade-off Filter를 설계하는 것입니다.
Methodology
- Filter 설계에 있어서 해결방법으로 고려해야 할 중요한 2가지 주장을 합니다.
- Claim I : 가장 가까운 이웃 노드에 더 높은 가중치를 할당할 수 있어야 한다. Diffusion step의 관점에서 다음 사실은 낮은 가중치를 할당받은 이웃 노드들은 높은 가중치의 이웃 노드에 속할 수 있음을 내포한다.
- Claim II : 필터의 차수(K)가 무한대에 가까운 매우 큰 값을 가질 때, 해당 Receptive field는 낮은 차수의 Receptive field를 커버하면서 그보다 더욱 큰 Receptive field와 통합할 수 있어야 한다.
- (다음 주장에 대한 세부적인 내용은 본 논문의 Supplementary를 참고해주시기 바랍니다.)
- 위의 주장을 따라 기존 Markov Diffusion Kernel을 수정한 Spectral Kernel을 설계하기로 하였으며, 결과적으로 최적 파라미터 K=16의 넓은 Receptive field를 갖는 제안 Kernel에서 Oversmoothing 문제 없이 기존 SGC (K=4) 필터의 Cover Boundary를 더 넓게 확장시킬 수 있었다고 합니다.
- (자세한 수학적 전개 및 설명은 생략하겠습니다.)
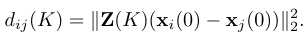
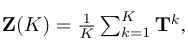
- 여기에서 T는 Normalized Adjacency Matrix(GSO)로 정의합니다.
- Markov Diffusion Kernel은 K차수 GSO(T^k)의 평균으로 정의한 Linear filter (Z(K))를 가지고 식 10의 Markov Diffusion distance를 정의함으로써, 이웃 노드의 Boundary를 정의합니다.
- 식 10을 보아, 노드 i에 대한 Markov Diffusion Kernel의 (output) Feature map은 아래와 같습니다.
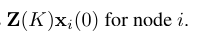
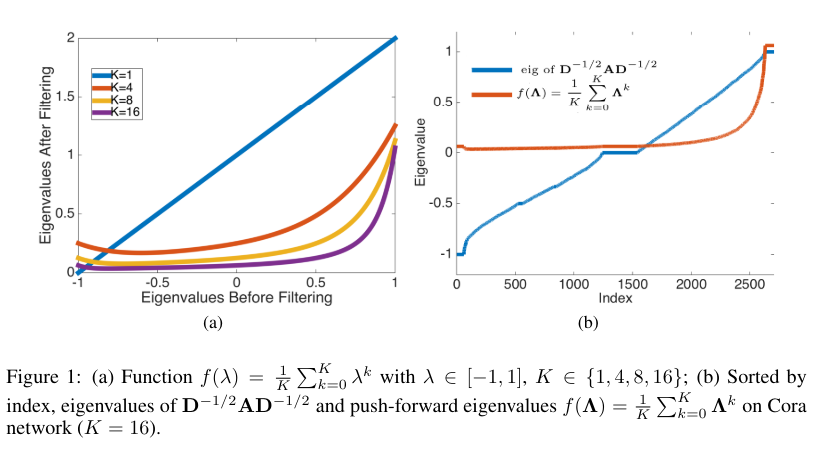
- 제안 필터의 동작을 간략하게 Fig 1에서 확인해볼 수 있습니다.
- Fig 1 (a)은 고유값 \lambda(or spectrum) 함수 f(\lambda)의 K값 차이에 따른 그래프 변화를 보여주고 있습니다. K값이 커질수록 filter Z(K)는 더욱 Low-pass filter로 동작하게 되는 부분을 확인해볼 수 있으며, Fig 1(b)에서는 K>1의 경우에서 T(Normalized Adjacency Matrix)의 큰 고유값 (eigenvalue index >= 1500) 요소들을 잘 보존하는 사실도 알 수 있습니다.
- 즉, Markov Diffusion Kernel은 K값이 커짐에 따라 그래프 상 노드들의 Locality를 유지하면서 더 넓은 범위의 이웃 노드들까지 모두 포착할 수 있는 이점을 확인해볼 수 있습니다.
- 위 사실을 바탕으로 저자들은 Markov Diffusion Kernel을 SGC 모델에 적용시킨 SSGC 모델을 새롭게 제안하였으며, 다음의 Convolution은 아래와 같이 정의합니다.
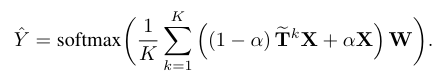
Experiment
- Node clustering, Community Prediction, Node classification, Text classification의 4가지 task에서 SSGC를 검증합니다.
- Oversmoothing 및 Long-range dependency 문제에 맞는 실험환경을 구축하기 위해 Large scale benchmark dataset에서 baseline models의 레이어 깊이에 따른 성능 결과를 잘 분석해 제공합니다.
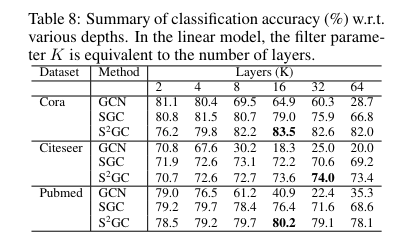
- Table 8은 레이어 깊이에 따른 baseline model 및 SSGC의 node classification accuracy를 비교하였습니다.
- K>4의 기존 GCN, SGC의 성능은 모든 데이터셋 상에서 떨어지는 반면, SSGC는 K=16 or 32까지 깊은 레이어에서 더 좋은 성능을 얻어낼 수 있다는 사실로부터 저자들이 주장했던 내용 (Claim II)을 뒷받침해주는 결과를 확인해볼 수 있습니다.
Conclusion
- 본 논문에서는 Markov Diffusion Kernel을 적용한 SGC 모델인 SSGC를 설계하고, 기존 GCN 계열 모델의 문제점을 해결하는 방법을 제안하였습니다.
- 점진적으로 이웃 노드의 범위를 확장하여 Global & Local Context 포착의 균형을 유지하면서, 기준 노드로부터 가장 가까운 이웃 노드에 더욱 큰 가중치를 할당할 수 있어야 하는, Markov Diffusion Kernel 설계를 위한 두가지 저자들의 주장을 기반으로 여러 Tasks에서 좋은 성능을 확인하고 그에 따른 분석을 해석해볼 수 있었습니다.
- 글의 복잡도를 낮추기 위해, 자세한 아이디어 전개 설명 및 기존 GCN 계열 모델과 제안 SSGC 모델의 연결 관계 부분을 해당 오마카세에서는 생략하였으나, Generalization 측면에서 한번쯤 읽어보시면 괜찮을 것 같습니다.
[Contact Info]
Gmail : jhbae7052@gmail.com / jhbae1184@akane.waseda.jp
Twitter (X): @jhbae1184
Scalable Multi-Hop Relational Reasoning for Knowledge-Aware Question Answering
정이태
논문 : https://arxiv.org/pdf/2005.00646.pdf
코드 : https://github.com/INK-USC/MHGRN
한 줄 두 줄
- Path-based 의 근본적인 문제인 scalability 와 embedding 의 black-box 문제를 attention score로 잘 풀어낸 논문. in-context 방법론 중 Knowledge graph reasoning & retrieval 이 관심받고 있는 가운데 한 번 읽어보면 좋을 논문.
무슨 문제를 정의했는지?
- scalablity - Knowledge graph 에서 발생하는 확장성을 GNN 관점의 Message passing을 활용해 해결해보고자 함.
- interpretability - Attention score와 probabilistic graphical models 관점을 활용해 연산된 값을 디코딩하여 해결해보고자 함.
요약에 요약
- 지식그래프 -> GNN Message passing GNN message passing 은 interpretability가 어려움.
- interpretability를 위해 attention score 사용.
- attention score 연산량을 감소하기 위해 Probabilistic graphical model 형태로 각 sequence condition 마다 node , relationship attention score가 어느정도인지를 확인함.
- text + graph 임베딩 값을 plausability score 라고 지칭하며, 각 score마다 해당 값들을 추론했을시, 답변이 correct / incorrect answer인지를 학습하며 cross entropy 함수로 최적화함.
- 추론시 answer entity 그리고 path length attention score 를 활용해 연관있는 reasoning path를 decoding 할 수 있다.
논문 아키텍쳐
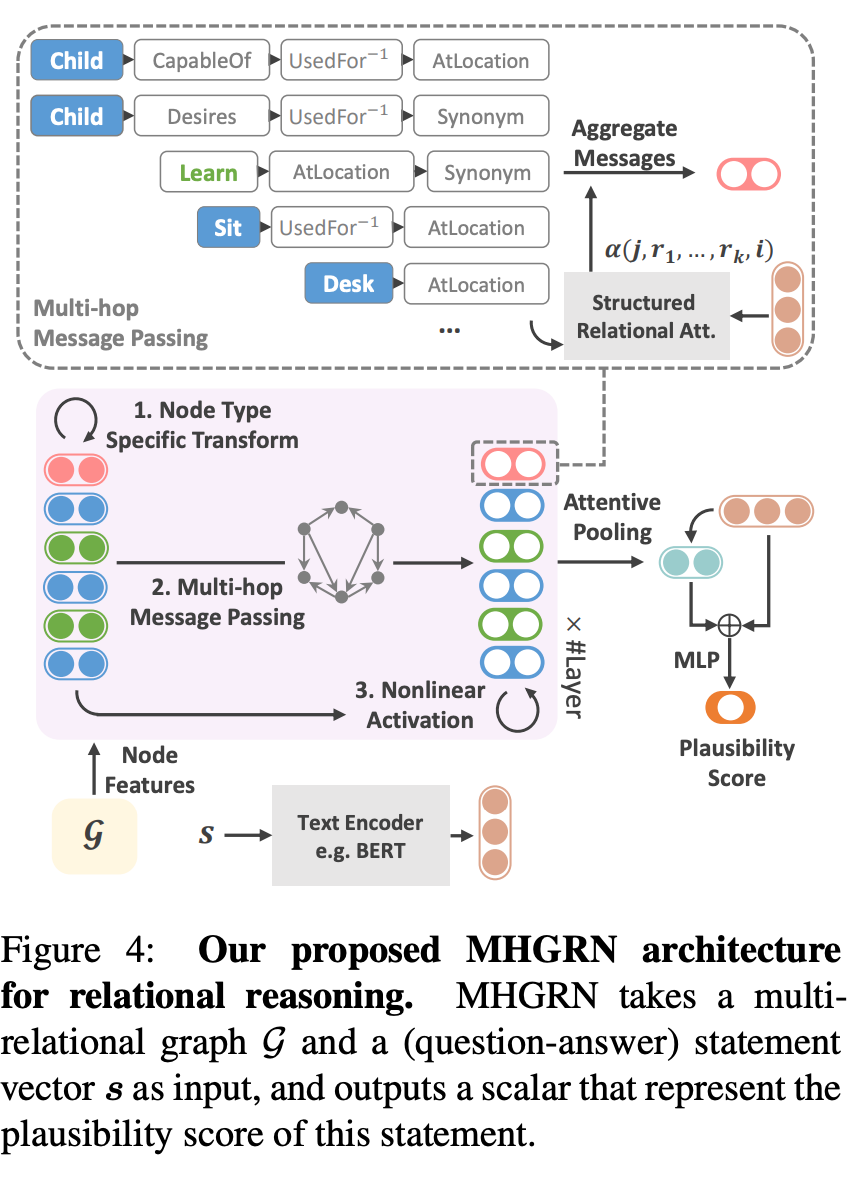
지식그래프의 고질적 문제인 Scalability와 핵심 장점인 Interpretability는 어떻게 ?
- Knowledge Graph(KG)의 장점을 떠올려보자면 노드와 노드 사이 의미가 부여된 semantic 을 통해 logical 하게 데이터를 해석할 수 있다. 라고 할 수 있습니다. 바로, 서두에 이야기한 interpretability입니다.
- 해석을 위해선 관련 있는 노드와 엣지를 가져와야 합니다. 하지만, 기존 KG path-based method 들은 너무 많은 종류의 노드 그리고 엣지들 때문에 가져오기 위한 연산량이 polynomial , exponential 하게 증가합니다. 아무리 좋은 해석력을 가지고 있다고 하더라도 활용하기 위한 연산량이 상당하기에, 이를 어떻게 할 지 고민이였던거죠. 이 점을 논문 저자는 기존 방식인 path들을 sequence model를 활용해 임베딩하는 것이 아닌 , GNN 의 Message passing 을 활용하여 해결해보고자 시도합니다.
- GNN 모델은 scability 측면에서 message passing을 통해 가져오면 되기에 상대적으로 연산 이슈가 적습니다. 하지만, message passing에서 기존 interpretability를 위한 transparency를 어떻게 가져올지도 고민해야했음. 이 때, attention score를 활용해 node , relation 마다 얼마나 중요한지를 대신하여 측정하고 판별하는거죠.
- 알고리즘 동작 중 재밌는 부분은 (11) equation 입니다.

- probabilstic graphical model 형태의 식과 유사합니다. condition 에 따라 값이 달라지는 메커니즘을 활용합니다. 특정 relation type , node type 마다 condition 인 statement 를 활용해 attention score parameter 를 효율적으로 활용하기 위해 재밌는 시도를 합니다.
- 또한, 본 과정을 통해 산출된 k-hop relation들을 decomposing 하여 유의미한 relation type인지를 판단하기 위한 기준으로 \tau 를 활용합니다. 이를, 통해 relation이 high-importance 혹은 nosiy 인지를 판별하여 path-based method의 정교함을 더합니다.
Knowledge graph 가 유의미한지를 판단하는 기준
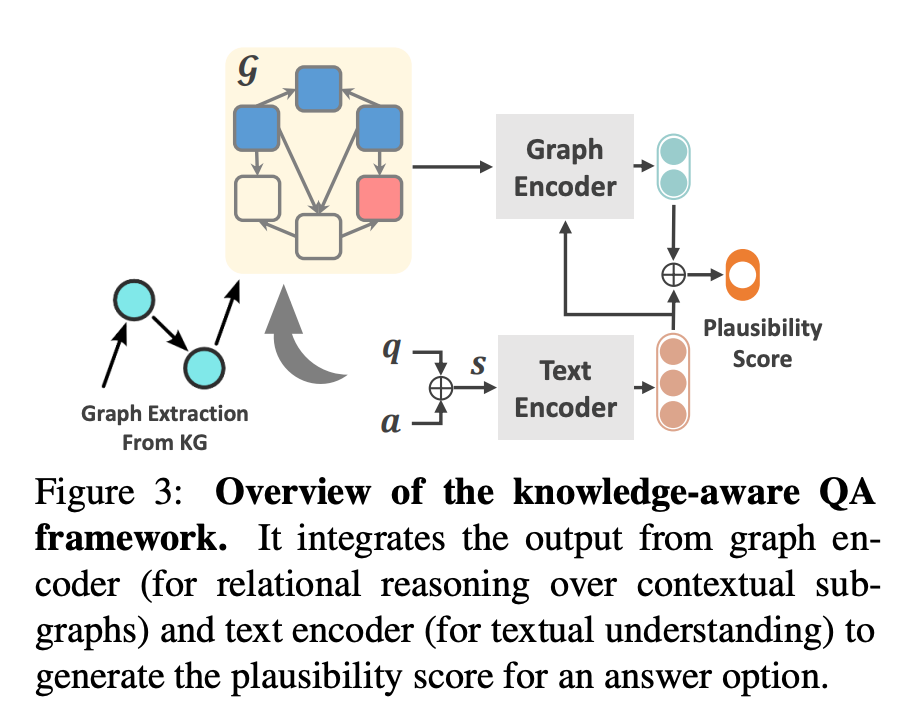
- 최종 목적은 Knowledge graph embedding 값을 활용했을시, 모델이 CommonQA task 에서 성능 향상이 있는지 없는지를 확인하는 것이기에, knowledge graph embedding 값이 유의미한지를 확인하는 기준이 필요합니다.
- 이를 위해, knowledge graph로부터 받아온 knowledge source가 question 에 부합한 재료인지를 판단하기 위한 기준으로 plausibility score 관점을 사용합니다.
- 각 node embedding된 값들이 property로 있는 entity node들을 attentive pooling 하여 graph representation 값을 얻습니다.
- text representation 값과 graph representation 값을 함께 사용하여 plasubility 값을 도출합니다.
- cross entropy loss function을 활용해서 correct answer 와 incorrect answer 최적화합니다.
주방장 생각
- In-context learning 이라는 방법이 대세인데, 돌고 돌아 기초를 찾듯이 본 논문이 Knowledge graph reasoning 기초인 path-based 를 재밌고 쉽게 풀어냈습니다.
- 너무 많은 학습량 때문에, 질문에 부합한 내용이 무엇인지를 주는 것이 좋은 방안으로 이슈가 되고 있습니다. 하지만 근본적인 의문이 들었습니다. context 를 주는게 맞을까 아니면 embedding과 함께 context 를 주는게 맞을까에 대한 본질적인 의문이 떠올랐습니다.
- 본 논문 아이디어는 그에 대한 해답을 얻기 위한 탐험 과정이 되지 않을까 합니다.
- 이를, 반영하기 위한 Reasonable knowledge 를 가져오는 방식에 대해 기초적인 접근으로 보면 좋을 논문이라 생각합니다.
- 특히 , compared methods 들로 그 당시 쟁쟁한 모델들과 비교하여 결과를 보여준 부분은 하루가 멀다하고 새로운 모델들이 나오는 요즘 역사로부터 배운다 라는 말이 떠오를만큼 그 때 당시와 지금을 비교해서 보는 것 또한 논문 재미 포인트 중 하나라 생각합니다.
- 과연 직접적으로 knowledge 를 주입하는 것이 아닌 텍스트와 그래프 임베딩 값을 통합하는게 맞는 선택인지에 대한 고민에 도움이 될 논문이라 생각합니다.