
24년 4월 셋째주 그래프 오마카세
[광고]
이번주 오마카세는 GUG 좋은 소식 그리고 다가올 GraphTalk 연사자 모집에 관해 간단한 광고로 시작하겠습니다.
1.[GUG 전용 챗봇 Graph Protocol 를 활용해보실분을 구합니다.]

작년에 이어 과기정통부 OpenUp에서 진행하는 커뮤니티 지원사업에 GUG가 2년연속 선정되었습니다. 모두 여러분들 덕이라 생각합니다. 엄격한 서류심사와 발표심사를 거치는 동안 강력하게 어필했던해올 해 계획 중 하나가 바로 Graph 지식에 특화된 챗봇이였습니다.
잘 쓰여진 Document, paper 라고 하더라도 아직까지는 ChatGPT4가 부족한 Graph 에 대한 정보를 얻기가 어렵다 판단하여 이에 특화된 ChatGPT 인 Graph Protocol을 만들어 보려합니다.
학계 분들에게 도움이 될까하여 awesome graph paper , 산업계 분들에게 도움이 될까하여 neo4j industry case , 딥러닝 구현하시는 분들에게 도움이 될까하여 dgl , pyg documentation 들을 지식 베이스로 구성하여 RAG 기술을 적용할 예정입니다.
GUG discord 를 통해 활용할 수 있습니다. 5월 중순부터 구현을 시작할 예정입니다. 구현 전 여러분들의 수요에 따라 API usage가 결정되기에, 간단한 수요조사를 하려고 합니다. GraphProtocol 활용에 대해 관심있으시거나, 추가로 아이디어에 조언을 주실 부분이 있다면 하기 GUG 공식 admin 메일로 연락 부탁드리겠습니다.
GUG admin email address - graphusergroup@gmail.com
GUG discord - https://discord.gg/sRSRjQFG
2.[GraphTalks 연사자를 모집합니다.]
벌써 24년 1분기가 지나고 2분기에 돌입했네요. 저에게 반기가 다가온다는것은 Graphtalks 세미나를 진행할 때가 되었음을 의미하기에, 한편으로 걱정되고 한편으로 설레임을 느끼는 요즘이네요.
GraphTalks 는 23년초부터 시작되어 현재 24년도까지 총 3회 이루어졌으며 , 대략 500여 명이 넘는 참석자와 15분이 넘는 연사자분들께서 지식을 공유해주시며 자리를 빛내주셨습니다. 개최 시기는 대략 6월정도로 생각하고 있으며, 그래프 관련 주제면 아무 상관 없습니다!
그동안 여러분들이 성장하신 경험을 공유하며 그래프 분야에 계신 다양한 분들에게 긍정적인 영향을 전파하는 것에 관심있으신분들이라면 연사자가 되기에 충분합니다! 하기 GUG admin 메일로 연락주시면 제가 회신 드리도록 하겠습니다 :) 많은 관심 부탁드리겠습니다.
GUG admin email address. - graphusergroup@gmail.com
역대 GraphTalks 기록들 - https://www.graphusergroup.com/graphtalks/
———
Generalizing Graph Convolutional Networks via Heat Kernel
arxiv 2021
link : https://openreview.net/pdf?id=yBJihVXahXc
code : https://github.com/hazdzz/HKGCN
Keywords
Simplifying Graph Convolutional Networks, Graph Heat Kernal
Background
- 저번 오마카세에서 Spectral Graph Convolutional Networks (ChebyNet, GCN)의 Convolution operation을 Heat kernel로 일반화시키는 방법을 보여드렸습니다.
- 다음과 관련해서 이번주 오마카세로는 GCN의 Non-linear properties를 제거하여 Linear model로 단순화시켰음에도 더 좋은 성능을 입증한 SGC (Wu et al., 2019)의 Heat Kernel 기반 Message passing 과정을 보이는 방법에 대해 소개시켜드리고자 합니다.
- Spectral Graph Convolutional Networks의 Computational complexity, Transductive bias 등을 모두 해결하고, 동시에 Heat Kernel의 장점을 취하여 입력 데이터 상의 Similarity를 극대화하는 방법을 제안하는 다음 논문으로부터 많은 인사이트를 얻어가셨으면 좋겠습니다.
Introduction
- SGC 논문에서는 GCN의 Feature aggregation 과정에서 비선형성 추가가 모델의 복잡도를 증가시키고 불필요한 연산을 요구하는 한계점을 지적하면서, 비선형성을 제거하여 Linear하게 바꾼 Aggregation function만으로도 기존 성능을 충분히 커버할 수 있음을 입증하였습니다.
- 즉, 반복적인 Message passing 과정이 Graph convolutional networks의 representation에 큰 기여를 하고 있다는 사실을 파악할 수 있습니다.
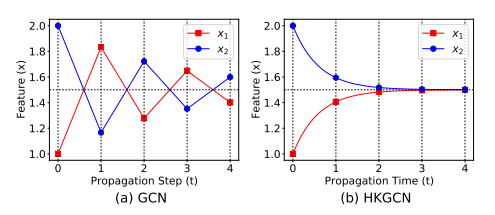
- 하지만 SGC는 기존 GCN의 학습 과정에서 문제점으로 지적되어온 Oscillation 현상을 그대로 상속하고 있으며, 결과적으로 패턴 학습에 오랜 시간을 필요로 한다는 한계점을 해결하지 못함을 지적합니다.
- 위 문제는 Heat kernel의 smoothness함을 적용하여 Oscillation을 최소화할 수 있으며 학습 수렴속도를 크게 개선할 수 있음을 본 저자들은 주장합니다.
- Message passing 과정에서의 Oscillation 현상은 High variation 혹은 Low similarity한 속성을 갖는 두 이웃 노드의 Feature aggregation 과정에서 발생하기 쉬울 것입니다. 이러한 Difference를 Low pass filter로 동작하는 Heat Kernel을 통해 Smooth하게 만들어줌으로써 위 문제를 완화하는 것은 직관적으로 쉽게 이해할 수 있는 부분입니다.
Methodology
- 기존 GCN의 Message Passing으로 정의한 Normalized adjacency matrix은 Discrete한 성질을 가지고 있기 때문에 결과적으로 Oscillation Convergence를 초래하게 됩니다. 그에 반해, Heat diffusion process는 continuous한 시간 t에 따라 smooth하게 에너지를 전달하는 속성에 의해 Oscillation problems을 완화할 수 있습니다.
- 위의 사실에 근거하여, 저자들은 Message passing 과정에 Heat Kernel 개념을 통합시킨 모델 HKGCN을 제안합니다.
- Computational complex의 문제를 피하고 Learnable Kernel 설계를 위해, 저자들은 ChebyNet의 아이디어를 따라 Chebyshev Polynomial 기반 Heat Kernel을 정의합니다. 여기에서 Chebyshev Polynomial의 계수를 얻어내기 위해 Modified Bessel function을 차용합니다.
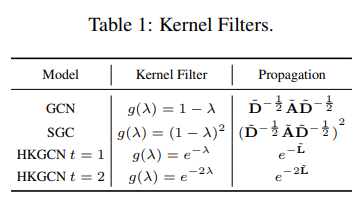
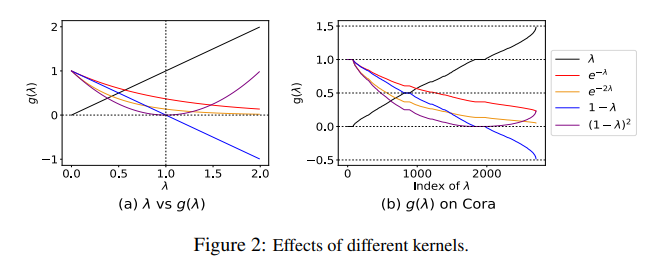
- Table 1, Figure 2는 GCN, SGC, HKGCN의 Kernel 정의와 그에 따른 Convergence 차이를 보여주고 있습니다. Kernel function의 그래프에 따라 해당 고유값에 따른 그 수렴도 차이가 크게 난다는 것을 알 수 있으며, 오직 Heat kernel Function만이 고유값 크기에 상관없이 일관된 수렴성을 보인다는 것을 알 수 있습니다.
Experiments
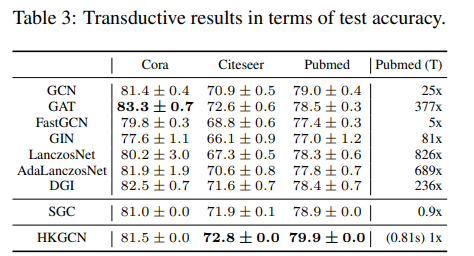
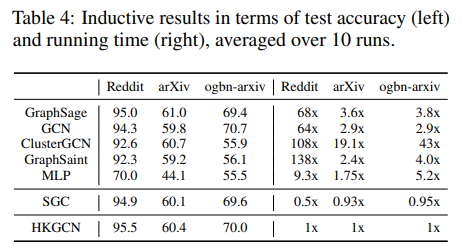
- Transductive setting 및 Inductive setting 에서 실험을 포괄적으로 진행하였으며, 테스트 정확도 측면과 연산 속도 두가지 평가지표에서 좋은 결과를 보여주었습니다.
- 개인적으로 Inductive setting에서 가장 좋은 성능을 달성할 수 있었던 이유가 궁금했었는데, 그 분석이 부재했었던 점이 다소 아쉬웠습니다.

- Fig 3은 Inductive setting에서 시간 t의 흐름에 따른 데이터셋 각각의 정확도 변화를 보여주고 있습니다. t > 9, 12에서 모든 데이터셋의 정확도가 감소하는 결과를 통해, 여전히 Oversmoothing의 영향을 벗어날 수 없는 한계점도 보여주고 있습니다.
Summary
- Linear Aggregation GCN 모델의 Convolutional Operation을 Heat Kernel로 Generalization하는 방법과 해당 아키텍처 HKGCN을 제안합니다.
- HKGCN은 저번 주에 소개해드린 GraphHeat의 Transductive setting 뿐만 아니라, Inductive setting에서도 좋은 성능을 얻어낼 수 있다는 점에서 Application Flexibility한 장점을 가지고 있음을 확인해볼 수 있었습니다.
- 개인적으로 Linear GCN에서의 Graph Heat process를 처음으로 적용하는 부분 및 GCN의 Oscillation 문제를 Low pass filtering을 통해 해결할 수 있다는 가능성을 볼 수 있었던 점에서는 좋았으나, 아이디어 전개 과정에서 Contribution 혹은 Novelty가 크게 느껴지지 않았던 것 같아 아쉬움이 남았습니다.
[Contact Info]
Gmail : jhbae7052@gmail.com / jhbae1184@akane.waseda.jp
Twitter (X): @jhbae1184
—————
Direct Evaluation of Chain-of-Thought in Multi-hop Reasoning with Knowledge Graphs.

정이태
인트로
프롬프트, 과연 그게 중요할까? 라는 의문이 한 때 있었죠. 지시를 잘 하기 위해 사람이 인위적으로 지시문을 작성하고, 지시문을 잘 입력할 수록 그 결과 또한 잘 나온다는 것에 대해 부정적인 시선들을 오마카세 주방장은 주변에서 많이 봤습니다. 충분히 이해가 됩니다.
특정한 공식이 있긴하나 ’아‘ 와 ’어’ 가 다르듯이 프롬프트마다 뉘앙스를 다르게 한다면 그 미묘한 차이가 큰 차이를 불러올 수 있다는 점 그리고 기계에게 지시를 문자로 직접 내린다는 것 자체가 생소했기에 그럴수도 있었다 생각합니다.
이와 같은 점들을 비단 제 주변 뿐만아니라, 전국 그리고 전세계적으로 고민했기에 DsPY 같은 방식이 등장하지 않았을까 싶네요. 자동화된 프롬프트 엔지니어링, 최근 대두되고 있는 개념이긴 하지만 여전히 수동적으로 프롬프트를 작성하는게 아직까지도 보편적인 방식이지 않을까 합니다.
오늘은 LLM에게 직접 추론을 지시하는 방식 CoT에 지식그래프 관점을 접목하여 신뢰할만한 데이터에 접근하여 추론하는지를 프롬프트로 멋지게 풀어낸 논문에 대해 이야기합니다.
왜 ?
최종적으로 유저에게 전달되는 답변도 물론 중요하지만, 답변을 도출하는 과정에서 LLM은 여러 추론과정을 거칠텐데 이에 대한 중요성이 간과되고 있습니다. 이에 개선이 필요함을 논문 저자는 깨닫게되고, CoT reasoning 방식에 Knowledge Graph를 사용하는 방식을 제안합니다.
Chain-of-thought(CoT) Reasoning 이란?
CoT란 reasoning framework 종류 중 하나입니다. 유저의 질의를 받게되면, 이를 chaining(연쇄)방식을 활용하여 LLM에게 연쇄 추론을 하게끔 지시함으로써 답변을 도출하는 프레임 워크입니다.
그래서 한 것
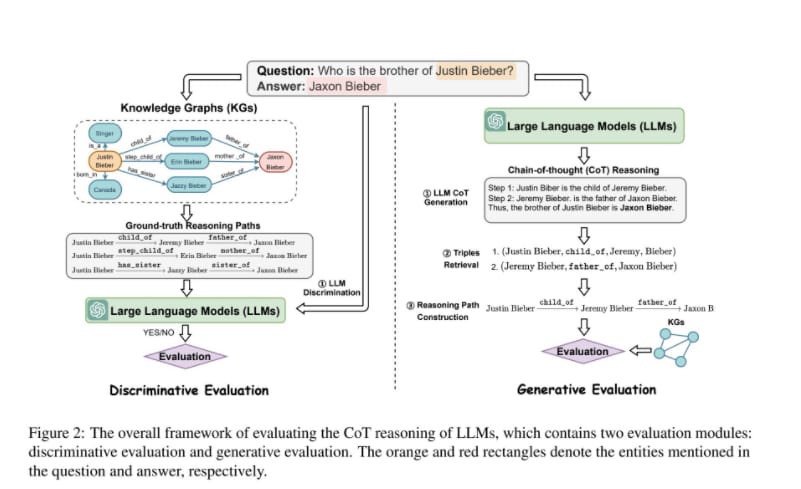
답변을 추론하는 방식에 대해 중요성을 언급했으니, 이를 어떻게 개선할지에 대해 이야기해야겠죠? 논문 저자는 추론에서 이루어지는 과정을 두 가지로 분리하여 이야기합니다.
첫 번째는 LLM이 Knowledge 를 분석하여 faithful reasoning 를 평가하는 Discriminative Evaluation 방식. 두 번째는 LLM이 CoT 과정에서 생성된 faithful reasoning 를 평가하는 Generative Evaluation 방식입니다. 딥러닝을 처음 공부할때 마주하는 GAN 아키텍쳐와 유사합니다. 생성하고 구별하며 모델의 성능을 향상시킨다는 개념을 생각하시면 이해하시기에 편하실 거라 생각합니다. 다만 여기에서 생성과 구별에 토대가 되는 데이터를 Knowledge graph로 활용한다는 점이 차이점이라 할 수 있습니다.
구체적으로 무엇을 기준으로 평가할 것인가.
앞서 언급한 바와 같이 잘 구별하고 , 잘 생성하는것을 평가하기 위한 척도가 필요합니다. 본 섹션에서는 구체적으로 어떻게 무엇을 가지고 평가할지에 대해 이야기합니다.
Discriminative Evaluation, 무엇을 기준으로 구별 품질을 평가할 것인가.
잘 구별하기 위한 기준이 필요합니다. 본 논문에서는 잘 구별하기 위해 기존 ground-truth 를 임의로 섞어주며 좋은 예시와 좋지 않은 예시를 만들어 Prompt 에 직접 주입하는 방식을 활용합니다. 좋지 않은 예시를 만드는 방식은 다음 3가지로 이루어져 있습니다.
- Factual error reasoning path
- 무작위로 valid reasoning path 의 entity를 섞어서 invalid path를 만들어 줍니다.
- Incoherent reasoning path
- valid reasoning path 의 triple 구조 내 요소들을 섞어서 임의로incoherent reasoning path 를 만들어 줍니다.
- Misguided reasoning path
- KG의 다른 질문으로부터 발생한 path를 임의로 섞어서 다른 사실 그리고 다른 triple 구조를 가진 path를 만들어 줍니다.
위 3가지 좋지 않은예시를 형성해준뒤, LLM에게 직접적으로 이 예시들이 유저가 질의한 사항에 부합한 reasoning path인지를 yes or no answering 을 시키며 학습하는 방식입니다.
Generative Evaluation , 무엇을 기준으로 생성 품질을 평가할 것인가.
CoT를 통해 생성된 Triple이 과연 유의미한 Triple 인지를 기존 Knowledge Graph와 대조하며 생성 품질을 평가하는 방식입니다. 생성된 Triple 형태를 기존 Knowledge graph의 Path 형태와 비교할 수 있게형태를 유사하게 만들어주어야 하기 때문에, 프롬프트 디자인이 더욱 중요한 분야라고 할 수 있습니다.
CoT를 통해 만들어진 결과인 Triple를 유의미한 Path로 만들고, 이를 Knowledge graph와 비교하는게 핵심입니다.
먼저 유의미한 Path로 만들기 위해서 본 논문에서는 Embedding 방식을 활용해 Triple을 숫자 형태로 변환해줍니다. 이 때, 활용하는 Embedding 방식은 Sentence-BERT입니다.
이 후, 숫자로 변형된 Triple 과 기존 Knowledge graph를 cosine similarity 를 활용해 유사한 knowledge graph 요소를 top k개를 가져옵니다. 참고로, 이 때 vector database(FAISS)에서 이 모든 연산이 이루어집니다.
이때, entity(relation)가 누락되어, 관련이 있으나 연결이 되어있지 않다는 이유로 retrieval 되지 않은 경우를 방지하기 위해 추가로 triple 중 head , tail 값을 평가 식에 넣어줍니다.
이렇게 만들어진 평가 식을 factual threshold 라 이야기하고 이 임계점 이상 , 이하 인 값을 기반으로 평가하게 됩니다.
앞서 만들어진 평가식 뿐만아니라, 추론 방식이 과연 적합한가 또한 고려하기 위해 다양한 관점을 추가로 차용합니다.
- Factual correctness - 가져온 triple 이 factual 임계 수치보다 낮거나 높을 경우로 판단하는 방식.
- Coherence - 결론을 도출하기 위해 이전에 무슨 근거를 활용했는지 판단하는 방식.
- Final answer correctness - 주어진 factual correct 와 coherent path를 활용하여 나온 답변이 정확한지 아닌지를 판단하는 방식.
결과는 어땠을까? 실험
서두에 언급드린 바와 같이 프롬프트를 어떻게 잘 디자인하는지가 중요한 논문이라 할 수 있습니다. 논문에서는 실험 비교를 위해 3가지 프롬프트 전략을 활용합니다.
- Prompting Strategies
- Few-shot CoT
- CoT 에 5개의 예시를 넣어주는 방식입니다.
- Few-shot CoT with planning (CoT-Plan)
- CoT reasoning 결과물을 언어화 하기 이전에 LLM이 직접 기획하고 decompose 하는 방식을 추가한 프롬프트 전략입니다.
- Few-shot CoT with self-consistency (CoT-SC)
- 답변 일관성 유지를 위해 답변마다 majority votes 의 결과를 집계합니다. 집계한 결과를 기반으로 사고하게끔 LLM에게 유도하여, 답변을 도출하는 프롬프트 전략입니다.
- Few-shot CoT
Discriminative evaluation result
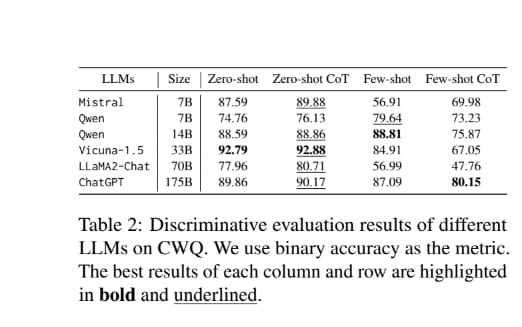
LLMs possess knowledge of valid reasoning
- Zero-shot 과 Few-shot 의 차이가 확연하게 드러나는 실험 결과입니다. Zero-shot은 성능이 준수한 반면에 Few-shot 은 성능이 대체적으로 좋지 않습니다.
- 이를 통해, 확인할 수 있는것은 오히려 Few-Shot 의 예시들이 오히려 노이즈로 작용하여 LLM 추론에 방해가 될 수 있다. 라는 점이라고도 해석할 수 있습니다.
- 아직까지도 LLM은 knowledge graph로 부터 받은 정보를 faithful reasoning 하기에는 갈길이 멀다 라고도 볼 수 있습니다.
Generative evaluation result
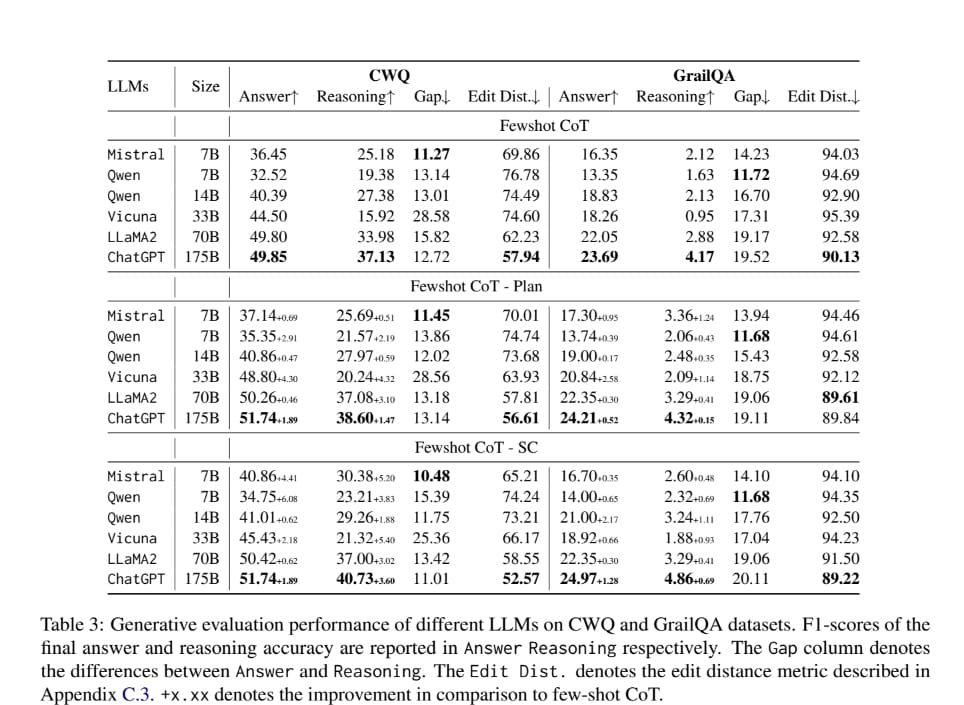
- The correct final answer may not necessarily result from faithful reasoning.
- Answer 과 Reasoning Gap 을 보는게 핵심입니다. Reasoning 성능이 높아질수록 Answer 성능이 높아진다. 라는 인사이트를 Gap을 통해 볼 수 있기 때문입니다. Gap이 적을수록 둘 사이의 의존성이 큼을 의미하고 그렇지 않을경우 적음을 의미하기 때문에, Reasoning이 Answer에 어떤 영향을 미치는가를 확인할 수 있는 구간이기 때문이죠.
- 논문에서 본 실험을 해석한 결과를 한 줄로 말해보자면, 결국 faithful reasoning 이 답변에 유의미한 영향을 주지않을정도로 필수 요소가 아니다 람을 결과로 확인합니다.
- The reasoning gap worsens as the model size increases.
- 모델 사이즈에 따라 reasoning 성능 차이가 있음을 확인할 수 있습니다. 모델 사이즈가 크면 클수록 reasoning 성능이 좋아집니다. 반면, 모델 사이즈가 작다면 성능 향상이 상대적으로 큰 모델 대비 적음을 확인할 수 있습니다.
- Better prompting strategy can improve both the answer and reasoning accuracy.
- Fewshot 만을 활용한 프롬프트 전략과 다르게 Plan - SC 를 활용한 프롬프트 전략이 지속적으로 성능이 좋음을 보입니다. 이를 통해 프롬프트 전략이 답변 그리고 Reasoning 가릴것 없이 효율적임을 확인할 수 있습니다.
마치며
LLM에게 도움이 될만한 path 인지를 구별하고 생성하여 판단하는 방식에 대해 이야기한 논문이였습니다. 구체적인 프롬프트 템플릿 그리고 디자인 전략을 활용해 그 여느 논문들보다 접근성이 매우 우수하고 실무적으로도 접근할 여지가 큰 논문이기에 개인적으로 흥미로운 논문이였습니다. 하지만 reasoning에 대한 효과를 실험 결과로써 입증하긴 했으나, 그렇게까지 매력적으로 와닿진 않았던 논문이라 생각합니다. 실험 결과들 대다수가 reasoning 가 중요하다 라고 생각을 풀어낼정도로 설득력있는 결과를 도출하지 못했기 때문입니다. 그렇지만, black-box 그리고 Hallucination 을 개선해야하는 측면에서 지속적으로 이런 Reasoning 연구들이 활발하게 진행되어야 한다고 생각합니다.