3월 1주차 그래프 오마카세

Identifying critical nodes in complex networks by graph representation learning
[https://arxiv.org/pdf/2201.07988.pdf]
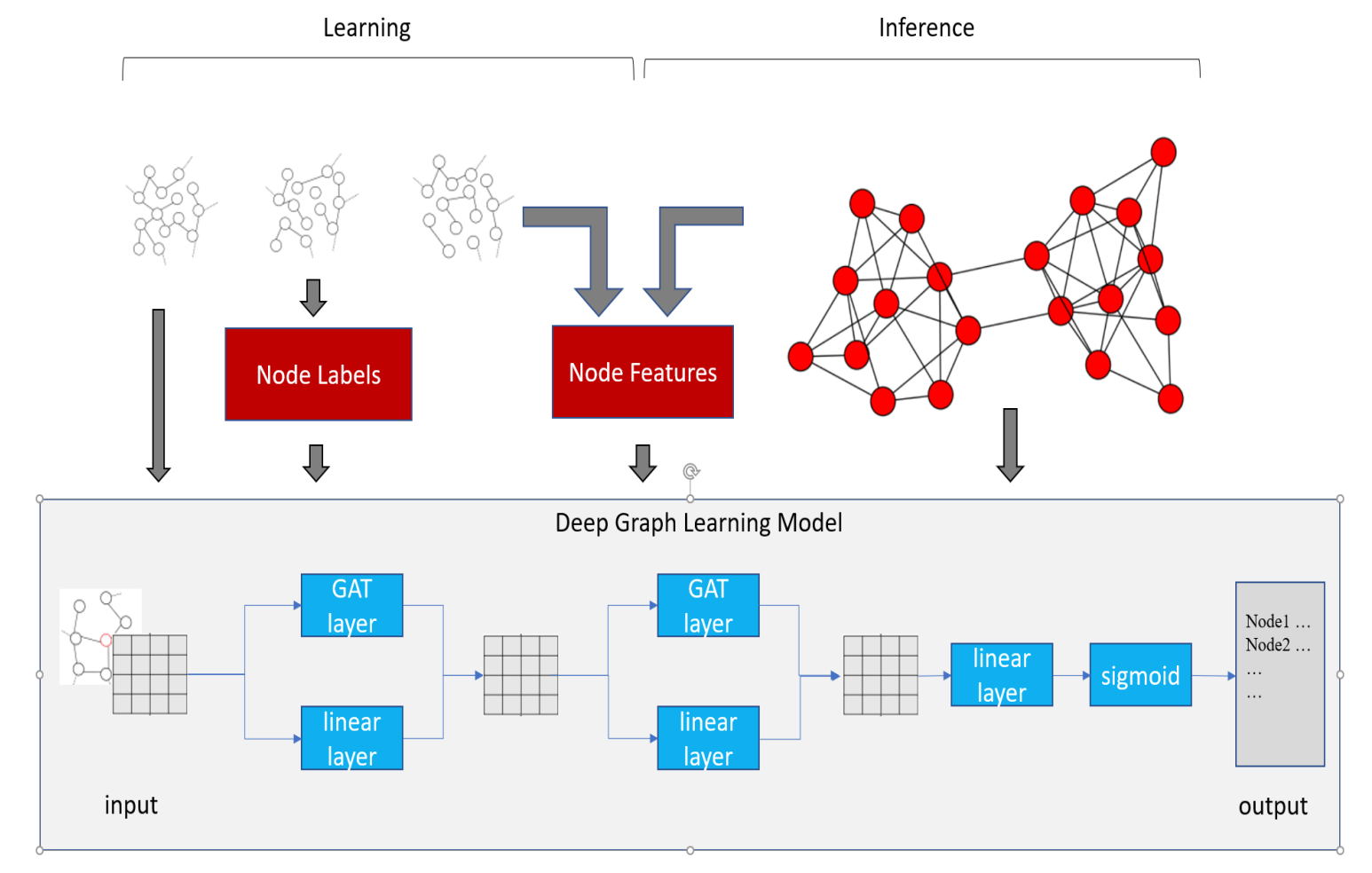
- 네트워크 데이터에서 중요한 노드,엣지를 찾는것은 복잡계 네트워크 뿐만아니라, 물리 통계 수학 분야를 가리지 않고 많은 학문적 연구가 이루어져 왔습니다. 그 결과로 저희가 자주 활용하는 pagerank, degree centrality 등이 탄생하게 된거죠. 하지만 데이터 양이 기하급수적으로 증가하며 무수한 노드 중 ‘중요’한 노드를 찾는것은 무척이나 어렵게되어 특정 부분을 컷팅(샘플링)해서 그 부분만을 기준으로 활용한다는지 등 휴리스틱(인간편향)적인 방식을 적용합니다. 구체적으로는 , percolation 이론을 사용하여 최적 솔루션의 대략적인 결과를 얻기 위해 몇 가지 휴리스틱 규칙(iterative selection or local attributes grouping)을 설계하는 방식으로 진행합니다.
- 본 논문에서는 그래프 임베딩 방식과 위에서 언급한 휴리스틱을 조합한 방식을 통해 네트워크 데이터에서 중요한 노드를 추출하는 아이디어를 제시합니다. 바로, influence maximization이라는 방식을 활용합니다. influence maximization 이란, 특정 네트워크를 input 으로 넣었을 때 정보의 양(엔트로피)가 가장 큰 형태를 추적하여 변경한 뒤 수정된 네트워크의 형태를 output 으로 도출하는 기술이라고 보시면 되겠습니다. 즉 input에서 정보의 교류가 많이 발생한 형태를 찾는게 목적인 방식입니다. 여기에서는 그 방식을 위해 SIR 모델을 차용합니다. SIR 모델을 통해 정보 전파 경로를 확인하고, 그 경로 기반으로 그래프 임베딩을 하며 학습을 하면서 최적의 노드 전파 경로를 학습하는거죠. 그렇다면 최종적으로 어떤 노드를 경유하면 네트워크에 정보가 잘 전달될지를 파악할 수 있습니다.
- graph embedding 의 핵심은 결국 message passing 인데, 그 message passing 핵심 요소를 SIR 모델로 잘 겨냥하지 않았을까 싶습니다. 이 뿐만아니라, network critical node identifiy 를 위해 복잡계 네트워크 연구자들이 어떤 방식을 적용했었는지에 대한 히스토리들이 잘 정리되어있어서 몰랐었던 지식을 충전하는 느낌이라 굉장히 흥미로웠었던 논문이였습니다. 특히, VoteRank, EnRenew, Improved Kshell and NCVoteRank 라는 methodology 들에 대해 알게되어 한 층 성장한 느낌이라 너무 좋았던 논문이였습니다. 이제 pagerank 뿐만아니라, 앞서 언급드린 방식들을 적용해서 다른 관점으로 critical node 들을 찾아보는것을 시도해보시는건 어떠실까요?
LINK PREDICTION WITH NON-CONTRASTIVE LEARNING
[https://arxiv.org/abs/2211.14394]
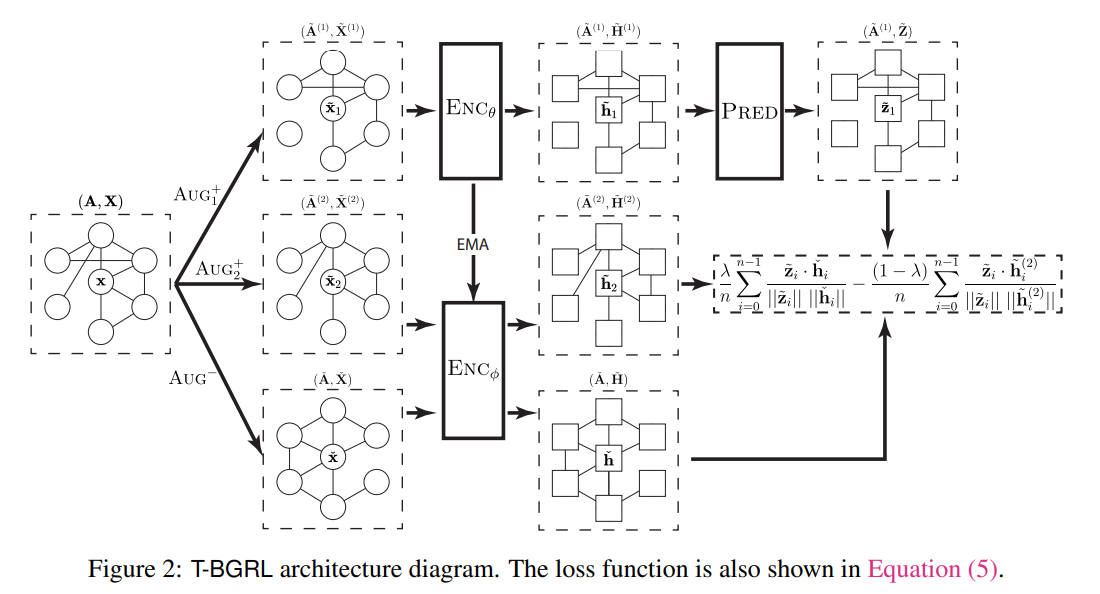
- contrastive-learning , positive sample 과 negative sample를 조합해서 임베딩을 더 잘해보려는 방식입니다. Link prediction 특히 recommender system 에서 많이 활용되고 있는 방식인데요. 저자는 이 방식에 1. Negative sampling cost 2. Overfitting 문제가 있다고 주장합니다. 그래서 저자는 non-contrastive learning 방식을 활용해보고자 하는데요. Simple corrpution function 을 통해 negative sampling 진행하여 expensive cost 를 cheap cost로 전환하려는 아이디어를 제안합니다.
- 그렇다면, 여기서 드는 의문점 하나가 있으실텐데요. contrastive learning 의 negative sampling cost 를 개선하는게 본 논문의 목적인데, 다시 negative sampling? 이라는 의문을요. 그럼 도대체 non-contrastive learning 이 무엇인지에 대해 다시 생각해보시게 될겁니다. 그 둘의 차이는 간단하게 pos , neg 에 대해 leveraging 을 주는가에 대한 여부로 보시면 되겠습니다. Contrastive learning 에는 neg sample 에 가중치를 주는 등 augmentation 에 양념을 바르곤 합니다.
- Transductive learning 실험 결과는 다음과 같습니다. BGRL(제안 방법) 과 ML-GCN(기존 방법)의 training 이 후 pos , neg 데이터 분포를 관찰한 결과, w/o leveraging negative sampling 에 대한 차이를 그렇게 보이지 않음을 확인할 수 있습니다. ML-GCN 의 성능이 우세하나, 압도적이지 않음을 저자는 강조합니다.
- Inductive learning 에서는 반전의 결과가 펼쳐집니다. BGRL 이 ML-GCN 대비 훨씬 우세한 결과를 보입니다. 이를 통해, negative sampling 에 leveraging 을 해주는 technique 이 inductive setup 에서는 그다지 효용적이지가 않음을 유추해 볼 수 있습니다. 즉, real-world 에 가까운 셋팅인 inductive learning 에서는 contrastive-learning 이 만능은 아니다 라는 것이죠.
- 잠깐 Transductive / inductive 의 차이에 대해 말씀드리자면, 학습때 활용했던 노드를 유지할것이냐 없앨것이냐 라고 볼 수 있습니다. Transductive learning 에서는 학습에 적용했던 노드를 그대로 train/test/inference에 적용하고, 반대로 inductive learning 에서는 그 노드들을 모두 없앤 상태에서 진행합니다. 결국 inductive learning 이 훨씬 어려운 task에 속한다고 볼 수 있죠.
- 그렇다면 본 논문에서 핵심인 corrpution function 은 무엇일까? 가 슬슬 궁금하실텐데요. 굉장히 간단합니다. Node feature 을 row-wise shuffle 해주는 겁니다. Structure 는 그대로 유지하고, Feature 만을 random shuffle 해주는거죠. 예로 들자면, 오마카세 주방장의 기존 feature 은 꽃 , 바람 , 새 였다면 shuffle 을 통해 새 , 바람 , 꽃 순서대로 학습을 하게 되는겁니다.
- Cold-start problem , graph SSL 등이 화두가 되며 contrastive learning 의 관심이 부쩍 올라가고 있는 추세입니다. 늘 트렌드 곁엔 부작용이 있기 마련인데요. 그 부작용을 잘 설명해준 논문이 아닐까 싶습니다.
Global Context Enhanced Graph Neural Networks for Session-based Recommendation
[https://arxiv.org/pdf/2106.05081.pdf]
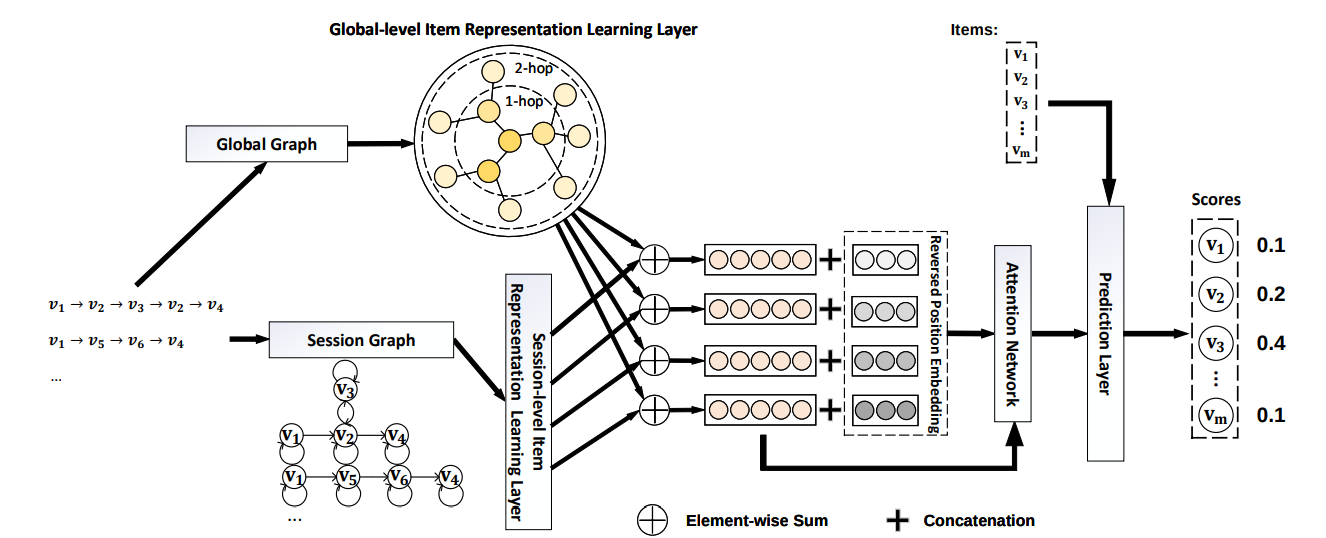
- jure leskovec 교수님과 더불어 pyg 에서 지속적으로 강조하는 논문을 가져왔습니다. 논문 핵심은 “session 마다 context 가 발생할텐데 이를 global 과 session 으로 구분지어 임베딩한다.” 입니다. session graph 를 설계하는 방식은 유저의 행동을 시간별로 정렬해서 그래프로 이어준다는 기존 방식과 동일합니다. 그렇다면 global graph이 결국 새로운 관점이자, 논문의 주 아이디어라고 보실 수 있겠습니다.
- global graph를 만드는 방식은 다음과 같습니다. 1. session 을 나열한다. 2. 특정 시점에 발생한 행동을 기준으로 전/후 행동을 cutting 한다. 3. 그렇게 cutting 된 특정 시점 행동 그리고 전/후 맥락을 하나의 그래프로 이어준다. 이때, 전/후 맥락을 정하는건 하이퍼 파라미터로 조절할 수 있습니다. 만약 유저의 long-term 을 확인할 때는 이 파라미터를 높게 short-term 을 확인할 때는 낮게 잡는 식으로 목적에 따라 다르게 global graph를 형성할 수 있습니다.
- 형성된 그래프를 training 시 다음 4가지 파라미터를 학습해줍니다. 1. in 2. out 3. in-out 4. self 4가지 파라미터는 곧 edge weight 로 볼 수 있겠습니다. graph 의 특성인 weighted 와 directed 를 활용한다고 보시면 되겠습니다. 이렇게 4가지 edge 를 학습해준다면, 행동의 값들이 중첩되며 어떤 시점에 어떤 행동이 중요한 특성이였는지를 확인할 수 있게됩니다.
- 이쯤에서 드는 의문이 있으실텐데요. 눈치채셨을지도 모르겠으나, 세션에서 행동의 순서를 그럼 어떻게 반영하지?라는 의문입니다. 그 순서를 본 논문에서는 간단하게 positional vector를 만들어주고 concatenate 해줍니다. 그렇다면 최종적으로 특정 세션마다 전후맥락이 담겨있고, 세션의 어느 위치에 위치했었는지에 대한 정보 두가지가 모두 벡터로 정량화되는결과를 낳게 됩니다.
- 마지막엔, 전후맥락(Global feature)이 성능에 얼마나 영향을 미치는가 , 세션의 순서(positional encoding)이 성능에 얼마나 영향을 미치는가 등 5가지의 research question에 대해 이야기합니다. 실험 결과가 매우 흥미롭기에, 시간이 없으신 분들은 위에 제가 작성한 것들만 인지하신 상태로 Experiment section 을 꼭 보시는걸 추천드립니다!
- 추천시스템에서 왜 유저의 전후맥락이 중요할까? 라는 의문을 가지면서 보시면 좋을 논문이라 생각되네요. 참고로 이전 게시물에서 언급한 kumo 추천시스템과 연계지어서 보신다면 그 효율이 2배 가까이 향상될거라 생각됩니다. 그래프가 왜 추천시스템에서 효율적인가 부터 얼개를 파악하시면서 트렌드인 session-based graph 흐름까지 이해하실수 있기 때문이죠.
LT-OCF: Learnable-Time ODE-based Collaborative Filtering
[https://arxiv.org/pdf/2108.06208.pdf]
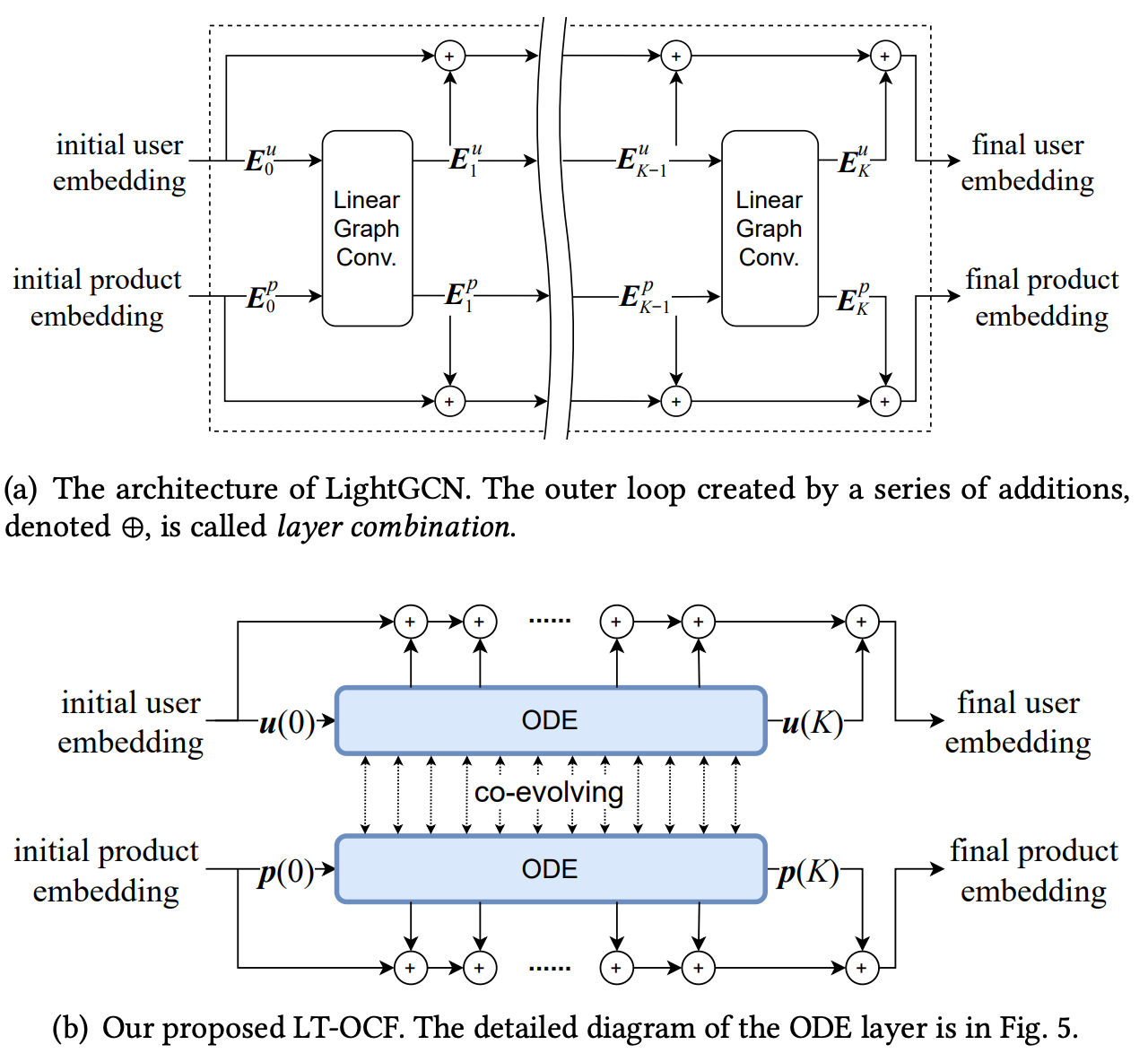
- 오랜만에 수학 수식 한가득 논문입니다. 복잡하다는 이유로 수학을 기피하기 보다 엔지니어링과 수학 테크닉을 골고루 배합하며 편식하지 않는게, 역량 향상에 많은 도움이 된다 생각하여 가져온 논문입니다. 미분 방정식과 graph smoothness의 조합이 왜 협업 필터링(CF)에서 유의미한지에 대해 이야기합니다.
- 협업 필터링과 추천시스템 그리고 그래프 하면 생각나는 모델이 있으실 텐데요. 바로 LightGCN입니다. 유명한 추천 모델 LightGCN 의 layer combination 에 유저와 아이템간 시간 공통 흐름(co-evolving) 을 추가해서 예측에 활용합니다. 이때, 두가지 의문이 드실텐데요. 1. 왜 시간개념을 추가하는지 2. 시간 개념(time point)은 이산(discrete)일텐데 이를 어떻게 활용할지. 해답인 시간 개념을 추가하는 이유는 간단합니다. 시간 경과에 따라 유저와 아이템간 의도가 서로 다를텐데 그 의도를 담기 위해서 라고 보시면 되겠습니다. 이산형에 속한 시간 개념을 미분방정식을 통해 해석이 가능하게끔 변환하고 trainable 형태로까지 만들어주는거죠.
- 주의깊게 보시면 좋을 기술은 non-backpropagation 입니다. adjoint sensitivity method 라는 방식을 활용해서 역전파를 대신합니다. 이 역시도 non-linearity 를 linearity 로 대신한 모델 특성 덕분에 가능한데요. adjoint 방식은 간략히 이야기해보면, 변수에 대한 방정식(scalar)의 부분 미분 행렬인 야코비안 행렬의 전치를 취함으로써 optimization 해주는 방식이라고 보시면 되겠습니다. 이 adjoint sensitivity method 를 저자는 time 활용하기 위해 customize 해줍니다.
- 정리해보면 본 논문의 장점은 다음 두가지라고 보시면 되겠습니다. 1. 미분방정식을 활용해 parameter 를 많이 줄였다. 2. discrete 형식의 time value 를 continous 하게 변형하여 활용한다. 유저 아이템 간의 상호작용에서 행동에 따라 유저의 의도를 반영하고자 시도한 session-based 모델링 방식과는 다르게 수학적으로 시간 개념을 어떤식으로 담을것인가에 대해 잘 고찰한 논문이라 생각됩니다. 제안하는 미분 방정식 이외에도 다양한 미분방정식을 적용한 실험과 결과가 있기에, 수학적 테크닉과 시간의 흐름에 따른 추천시스템에 대해 궁금하신분들께서 보시면 좋을 논문이라 생각되네요.

안녕하세요 Hardy 입니다. 이번 포스팅에서는 제가 싱가폴에서 겪은 색다른 경험에 대해 공유해보려고 합니다. 바로 싱가폴에서 진행한 k8s meetup 에 참여한 경험입니다. Meetup 이야기 전, 독자분들의 원활한 글 이해를 위해 k8s 에 대해 간략한 설명으로 포스팅을 시작해보겠습니다.
K8S 란?
K8s, or Kubernetes, is an open-source container orchestration platform used for automating the deployment, scaling, and management of containerized applications. It was developed by Google and is now maintained by the Cloud Native Computing Foundation (CNCF).
Kubernetes provides a set of abstractions that allow developers and system administrators to easily deploy, manage, and scale containerized applications across clusters of machines. It provides features such as automated rollouts and rollbacks, self-healing, service discovery and load balancing, and storage orchestration, among others.
By using Kubernetes, teams can focus on developing and deploying their applications without worrying about the underlying infrastructure. Kubernetes provides a flexible and extensible platform that can be run on-premises or in the cloud, and it has become one of the most popular tools for managing containerized workloads in production environments. From chatGPT
설명에서 말한것과 같이 k8s 는 시스템을 다루기 위한 management 도구라고 보실 수 있습니다. 그렇다면, 저는 왜 k8s meetup 에 참여하게 된걸까요?
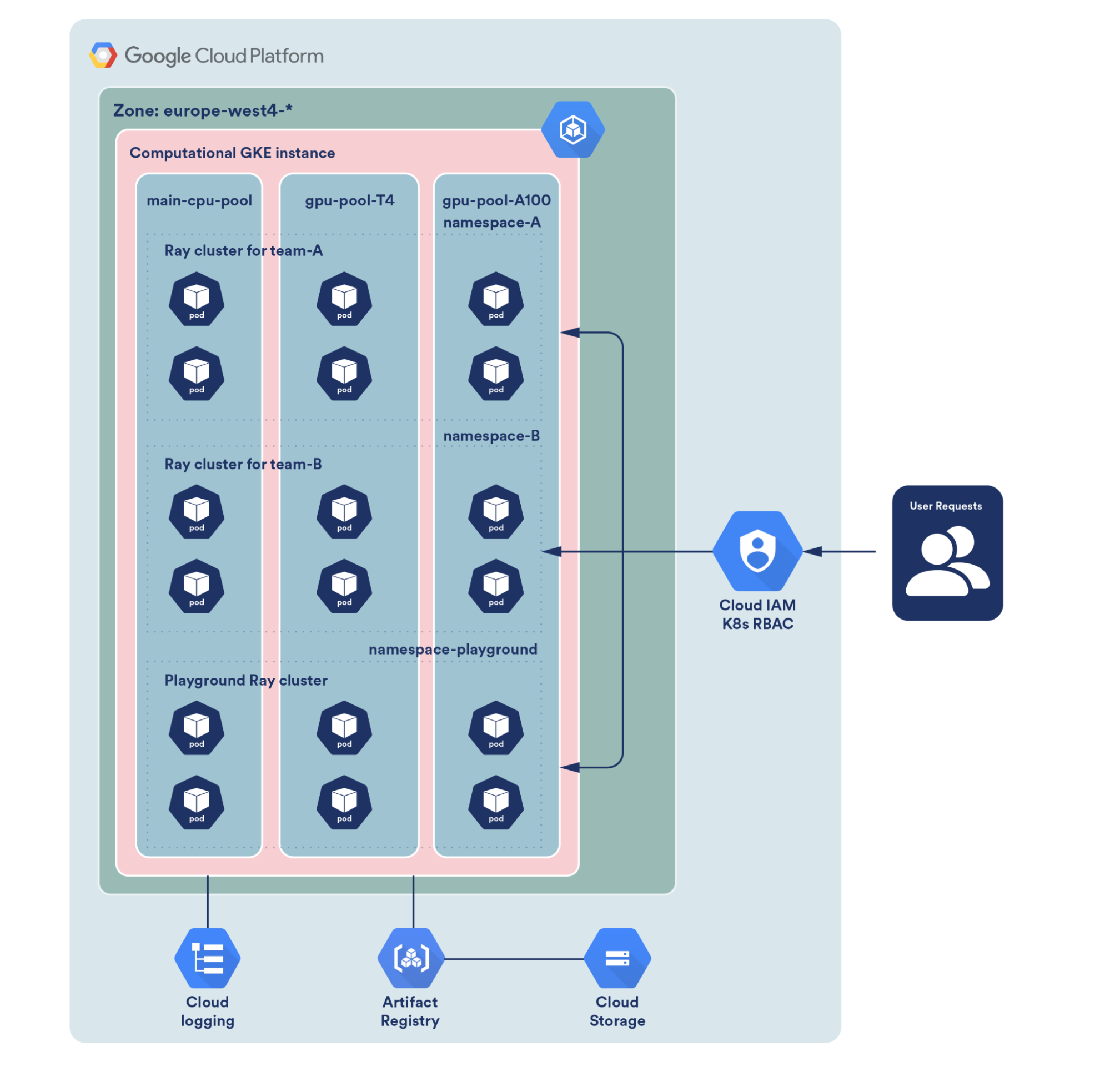
Hardy가 k8s 에 관심을 가지게 된 이유.
최근 k8s에 대한 관심이 커지고 있는데요. 목적에 따라 각기 다양한 이유들이 있을거라 생각되네요. 저는 그 중 MLops with graph machine learning 으로부터 k8s에 대해 관심을 가지게 되었습니다. 구체적으로는 한 포스팅이 발단이 되었는데요. 바로 Spotify Engineering 팀에서 발행한 포스팅이였습니다. PyG conference 발표부터 시작된 호기심이 Spotify engineering architecture 까지 이어진거죠. 그래프 추천 모델을 현업에서 직접 적용한 좋은 사례라 생각되어 주기적으로 동향을 체크하고 있던 중 포스팅을 발견하게 된거죠.
포스팅에서는 ray 와 k8s 를 적용하여 머신러닝 엔지니어 , 데이터 사이언티스트 (ML practioners) 들이 겪고 있는 문제인 ML ecosystem 관리를 편리하게 할 수 있다 라는 점을 시작으로, 왜 ML practioners 들에게 이 관리가 중요한지 그리고 spotify 에서는 그 관리를 어떻게 하고 있는지 아키텍쳐 설명과 코드까지 잘 풀어놓았습니다. ray 라는 툴이 언급되는데요. 간단히 말씀드리면, 저희가 모델을 학습시키기 위한 일련의 과정을 편리하게 자동화하며 관리할 수 있는 도구 라고 보시면 되겠습니다.
ray를 통해 발생한 하나하나 각각의 ecosystem 을 k8s로 관리하는 내용이 담긴 이 포스팅을 보고 저는 k8s에 대해 알게 되었고, 마침 싱가폴 여행 스케쥴과 겹쳐 주저할 틈없이 meetup 에 신청했습니다.
Meetup 에선 무엇을 배웠나요?
밋업은 약 3시간동안 5가지 세션으로 구성되었으며, 다음 순서대로 진행되었습니다.
- Welcome / Introductions by the Organizers, @K8SUG / K8SDM
- Docker 101 Hands-on by Sachin Choube Solution Architect @DSA
- GKE Cluster Hands-on by Yongkang HE, Organizer @K8SDM.com
- GKE Backup Hands-on by Yongkang HE, Organizer @K8SUG.com
- Open Mic, Photo Time, Networking, Q & A - all
- Docker101 Hands-on session 에서는 도커 컨테이너를 관리하는 법에 대해 배웠습니다. 이미지를 불러와서 빌드하고, 빌드된 컨테이너에서 무엇이 발생하는지 로그를 찍어보는 등에 대한 설명으로 진행되었습니다.
- GKE Cluster Hands-on session 에서는 GCP 에서 GKE cluster 를 만들고 deploy 그리고 delete 까지 하는 법에 대해 배웠습니다. 원래 이 모든 과정들을 손수 CLI에서 기입하며 진행해야하는게 맞지만, 시간여건상 발표자분께서 준비해 온 쉘스크립트를 실행하는 것으로 대체했습니다.
- GKE Backup Hands-on session 에서는 생성된 GKE cluster를 주기적으로 관리해야할텐데, 필요한 요소들이 무엇이며 어떤식으로 관리하는게 효율적인지에 대해 배웠습니다. 이때, CloudCasa라는 플랫폼을 통해 CLI 가 아닌 GUI 를 통해 간단하게 어떻게 policy build 등 planning 을 할지에 대해 간단하게 체험해보았습니다. 저는 이 때 처음 알게되었는데, 이 부분에서 대다수 k8s 를 활용하시는 분들께서 어려움을 겪고 계신다고 하시더라구요. 그 어려운 과정을 저같은 초보자도 GUI를 통해 쉽게 해결할 수 있게 잘 만든 툴이였었기에 비슷한 문제로 고민하시는 분들이 계신다면 CloudCasa를 활용해보시는것을 추천드립니다.
- Open Mic , Networking session에서는 밋업 현장 / 온라인 참여한 사람들을 대상으로 자신이 누구이며, 무엇에 관심있는지 등 자기소개를 하는 시간이였습니다. 저포함 3명정도가 앞에 나가서 자신에 대해 어필하였는데요.
마치며
정리해보면, 하나의 노드에 속한 도커 컨테이너를 관리하는 미시적인 관점부터 클러스터를 만들고 그 클러스터를 다루는 방식인 거시적인 관점까지 all-in-one 으로 다뤄보게되어 너무 좋았던 경험이였습니다. 비록 디테일한 내용은 시간 여건상 발표자분께서 미리 준비해온 쉘스크립트로 대신하는 등 생략되어 아쉬웠지만, k8s 가 어떤식으로 활용되며 내부에 어떤 요소들이 존재하는지에 대한 전반적인 아키텍쳐를 알게된 좋은 배움의 기회였었다고 생각됩니다.
기술관점와는 별개로 또 다른 배움과 자극이 있었습니다. 국적 가릴 거 없이 어딜가나 정보 교류 선순환을 위해 열심히 활동하는 분들이 존재하는구나 라는 깨달음을 얻게되는 시간이였습니다. 이타적인 삶에 대해 글또 첫 글에서 이야기 했었는데요. 말은 거창하게 했지만, 남을 위해 만드는 콘텐츠들이 어느순간 나를 위해 만드는 콘텐츠로 변질되려고 하는 순간들이 종종 존재하더라구요. 그 순간마다 콘텐츠를 만드는 목적에 대해 다시 되새기며 힘을 내곤하는데, 이 밋업 참여경험이 이타적인 삶에 대해 앞으로 많은 동기부여가 될 수 있을거 같네요.
혹시 이 글을 보시는 분들중 그래프 지식 교류에 대해 관심 있으신 분들이 계시다면 아래 그래프 유저 그룹 사이트에 접속하셔서 좋은 얻음이 있었으면 합니다. 아직 초기단계라 콘텐츠가 많이 미비하긴하지만, 점차 발전하는 모습으로 여러분들에게 도움드릴 수 있는 공간이 되게끔 노력하도록 하겠습니다. 뿐만아니라, 콘텐츠 제작에 관심있으신분들은 언제든지 말씀해주시면 감사하겠습니다.