2월 1주차 그래프 오마카세


GNN4DM: A Graph Neural Network-based
김지원
[Content]
subject : method to identify overlapping functional disease modules
keyword : #gene_interpretation #GraphNeuralNetwork #GNN
사이트 🔗:
GNN4DM: A Graph Neural Network-based method to identify overlapping functional disease modules
호기심 많은 웡카: 이 논문을 왜 오늘 오마카세에 들고 오신걸까요?
나: 건강해지는 초콜릿은 무엇일지 궁금하네요. 저는 질병과 관련있는 유전체 분석을 할 때에 흔히 바이오마커 발굴이라는 과정을 거치는데, 이는 질병의 병인 혹은 진행을 보여주는 데이터를 비교분석을 하여 이에 관련있는 유전자들을 찾아나간다는 작업을 거칩니다. 스토리상 말이 되는 십여개의 유전자들을 분석하여 결과 및 토의에 적어놓는 논문들이 있지만, 유전자 숫자가 100개 이상이 된다고 하면 해석이 매우 어려울거 같습니다. 건강해지는 초콜릿도 건강의 구성요소가 매우 복합적이고 다양한 재료들로 만들어질 듯 하네요.
호기심 많은 웡카: 그럼 이 논문의 저자들은 비교분석할 유전자 갯수가 100개 이상이 될 때 어느 것이 중요한 지? 해석을 어떻게 해야할까에 대한 논문입니까?
나: 네, 맞습니다. 흔히들 biological network 분석을 많이 하고 있습니다. 또한 딥러닝이 새로운 norm으로 가는 만큼, 생물에서 Graph Neural Network을 쓰이는 사례들이 많아지고 있습니다. 본 논문의 저자들은 다음과 같이 데이터를 구성했습니다.
나: 벌크 (bulk) 유전체 발현 데이터를 조직별로 있는 GTEx (링크) 뽑아 조직데이터를 확보 그리고, population 레벨에서의 유전자와 phenotype (질병 포함)에 대한 관계성과 유전자간의 관계를 확보하기 위해 String DB(링크)와 Genome wide association study ATLAS (링크)의 데이터 또한 사용을 했습니다. 노드는 StringDB에 포함되어있는 유전자들에 한해서, attributes는 조직 발현량, 질병과 유전자의 관계성, 그리고 network node properties를 넣었습니다. Edges는 StringDB에서 확보한 protein-protein interaction으로 정의했습니다. 데이터의 관계성 성질을 잘 반영하고 community detection을 더 잘하기 위하여 GNN을 활용했습니다.
호기심 많은 웡카: GNN은 그럼 다음에 이용한걸까요? 건강 초콜릿을 만들려면 재료 레시피가 정말 중요해요. 딥러닝은 구성을 잘 모르는 블랙박스 형식이여서 community detection만 가능하고, 그에 대한 해석은 불가능하지 않아요?
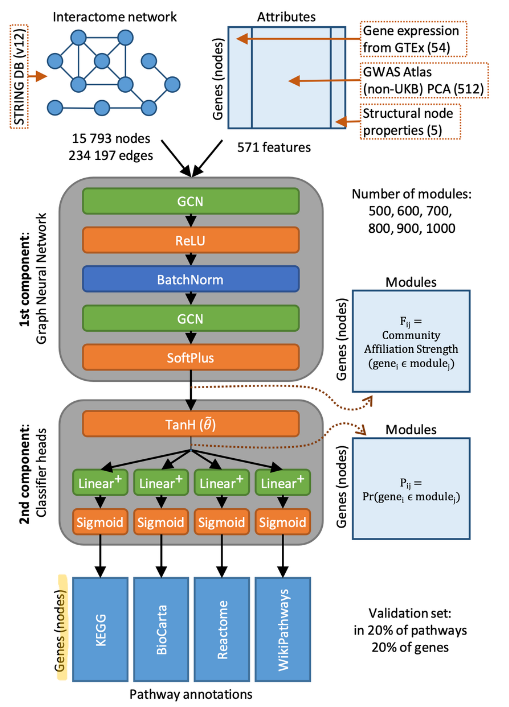
나: 여기서 novelty가 들어가는것 같습니다. 저자들은 첫번째 component는 서로 다른 activation functions를 사용한 2-layer GCNs을 통하여 유전자 (노드)들이 “x” 모듈 (meta-node? 인가요)에 속함을 말하고 있는 weights를 구했습니다. Loss는 “Bernoulli-Poisson loss”를 주어 positive/negative edges를 학습하였습니다. (이어서..)
다음은 각각의 probabilities를 구할 수 있게 scaled tanH function을 거친 Classifier head로 구성했습니다. constrained logistic regression을 구성하여 non-negative 값들을 뽑아내게 해주어 그 weights 크기를 통해서 해석 가능하게 만들어주고, linear regularization 도 걸 수 있는 장치를 만들어냈습니다. 맨 마지막에 binary cross entropy loss를 걸어 이 classifier head도 학습이 가능한 것으로 만들어냈습니다.
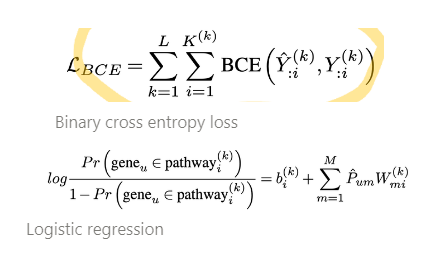
호기심 많은 웡카: 결과는 어떤가요? 당연히 좋겠죠?
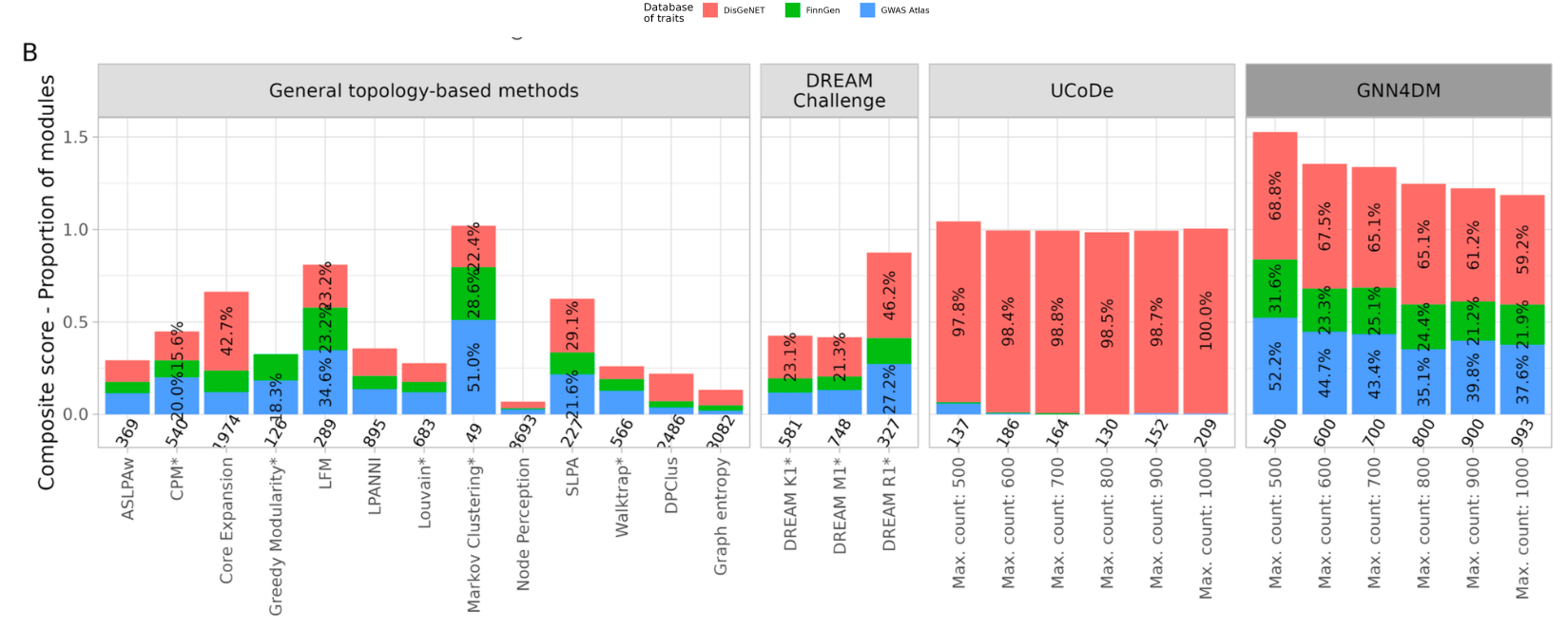
나: 네, 좋구말구요. 파리마터들을 통해 모듈사이즈와 모듈 갯수조절을 해야하겠지만, 밑에 bar graph를 보시면 상당히 잘 다양한 phenotypes (i.e. DisGeNet, FinnGen & GWAS Atlas) 모두 반영하는것 같습니다.
호기심 많은 웡카: 아쉬운 점이 혹시 있을까요?
나: 아쉬운 점은 유저들이 커스텀하게 변경하고 싶은데, 그럴 수 없다는 점이 있습니다. 더 질문 없을까요?
호기심 해결한 웡카: 네, 없습니다.
나: 본 논문을 읽으면서 저는 실험을 통해서 뽑힌 유전자들을 좀 더 스마트하게 aggregate 하여 분석하기 원했는데, 이 툴을 쓰면 좋을것 같네요.
[Contact Info]
Gmail : kjwk1221@gmail.com
LinkedIn : https://www.linkedin.com/in/jiwonkimbrian/
Exphormer: Scaling transformers for graph-structured data (ICML 2023)
배지훈
link : https://arxiv.org/abs/2303.06147
video : https://icml.cc/virtual/2023/poster/23782
Keyword : Graph Transformer, Scalability, Expander Graph, Global Attention
[Content]
- 다들 잘 아시다시피, 그래프 신경망은 기본적인 학습 메커니즘인, 메세지 전달 과정을 통해 노드 정보를 전파, 업데이트합니다. 이웃 노드의 정보를 반복적으로 집계하기 때문에 자연스럽게 Locality가 강한 속성이 있으며, 따라서 다음 학습 메커니즘은 장거리 노드의 종속성 포착의 취약점이 존재하게 됩니다.
- 트랜스포머 모델의 Global Attention( 메커니즘의 장점을 그래프 노드 집계 과정에 도입하면서 파생된 새로운 그래프 학습을 활용하고 있는 그래프 트랜스포머 모델은 그래프 신경망의 새로운 패러다임을 제시하였습니다.
- 그래프 트랜스포머의 기본 아이디어는 그래프 상 모든 노드의 정보를 직접적으로 한번에 집계할 수 있는 가상 노드(Virtual node) 집합을 포함하는 완전 연결된 그래프 (Fully-connected Graph) 를 가지고 기존 Global Attention 메커니즘을 모델링하는 것입니다.
- 하지만, 직관적으로 다음 방법을 그대로 학습에 활용하기에는 연산 효율성이 매우 나쁘며, 확장성(Scalability)의 제한적인 한계점과, 강력한 Local Connectivity를 기반으로 동작하는 그래프 신경망의 Inductive bias의 손실을 불러오게 됩니다.
- 기존 연구들에서 위 문제점들을 해결하기 위해 희소 어텐션 그래프 트랜스포머 (Sparse-attention graph transformer) 기반 다양한 모델들을 제시하였으나, 확장성 문제를 본질적으로 해결하지 못한 점에 본 논문의 저자들은 집중합니다.
- 희소 어텐션 프레임워크의 확장성 문제를 해결하기 위해, 본 논문의 저자들은 원본 그래프의 Locality한 구조성을 그대로 유지하면서 (a) 추가적으로 확장 그래프 (Expander Graph) (b) 및 Global Attention 메커니즘을 모델링한 가상 노드 (c) 속성들을 활용합니다. 다음 개념은 본 논문의 Fig 1에 쉽게 표현되어 있습니다.
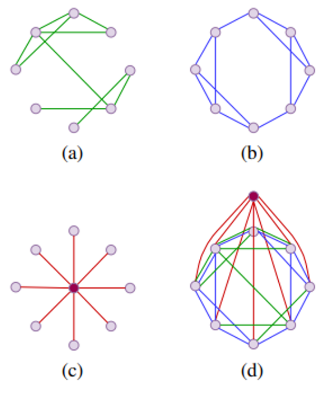
- 스펙트럼 및 랜덤워크 혼합 (Spectral Properties & Random walk mixing) 바탕의 이론적 증명으로부터, 저자들은 다음 확장 그래프의 개념이 기존 그래프 트랜스포머의 완전 연결 그래프의 구조적 속성을 근사화할 수 있음을 설명하고 있습니다. 또한 Exphormer의 희소 어텐션 그래프를 자체 루프 (Self-loop)를 갖는 구조로 표현하였을 때, universal approximation의 속성을 가질 수 있음도 보입니다. (Section 4 및 Supplement를 참고하시기 바랍니다.)
- 제안하는 Exphormer 모델은 Global Attention의 적절한 복잡도를 얻어내기 위한 일정한 Degree의 확장 그래프 개념과 작고 일정한 수의 가상 노드를 사용하기에 입력 그래프 크기에 선형적이며, 기존 그래프 트랜스포머만큼의 좋은 표현력과 Universial approximation의 속성을 따르게 됩니다.
- Exphormer의 성능을 평가하기 위해, 저자들은 메세지 전달 및 그래프 트랜스포머 메커니즘을 모두 결합하여 다양한 데이터 셋에서 다양한 폭넓은 실험을 진행하였으며 (Table 2~5 참고), 결과적으로 기존 그래프 트랜스포머의 확장성을 능가하며 좋은 성능을 확인할 수 있습니다.
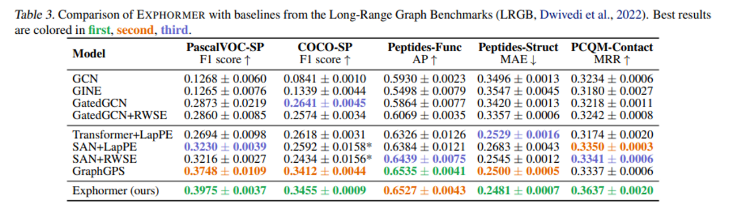
- 본 논문을 읽으면서, 어떻게 그래프 트랜스포머의 Global Attention 기반 Fully-conneted한 계산 그래프(Computational graph)의 Locality를 유지하면서 효율적인 Scalability를 얻기 위한 Sparse한 구조로 표현할 수 있을지 궁금했었는데, 새로운 확장 그래프의 장점을 도입하며 두가지 토끼를 한번에 잡았던 부분이 상당히 흥미로웠습니다.
- 그래프 트랜스포머의 Scalability에 관심이 있으신 분들은 링크로도 공유한 해당 저자의 발표 비디오를 통해 Exphormer의 요약 설명을 참고하시면서 본 논문을 읽어보시면 좋을 것 같습니다.
[Contact info]
Gmail : jhbae7052@gmail.com
LinkedIn : https://www.linkedin.com/in/jihun-bae-757302289/
Twitter : @jhbae1184
Pick and Choose: A GNN-based Imbalanced Learning Approach for Fraud Detection
정이태
[paperInfo]
[Architecture]
[Content]
- 알리바바 그룹 데이터를 보면 오직 0.5 % 만의 유저들이 credit debts 를 갚지 못하는 defaulter라고 합니다.
- 이들을 구분하기 위해 여러 방식들을 시도했으나, 다음 두 가지 챌린징때문에 추론 성능이 좋지 않아 고민이 많다고 합니다. 구체적으로는 먼저, 관련없는 관계(엣지) 정보들이 오히려 노이즈 형태로 작용한다는 겁니다. 예를 들면, spammer들이 의도적으로 spam review를 작성하기위해 정상적인 아이디를 잠시 빌리고 게시하게 되면, 그 spam review 는 정상 아이디로부터 작성되었기에 spam 과 spam 아님에 대한 정보가 희석되어 구분하기가 힘들다고 합니다. 머신러닝 관점에서 말씀드려보자면 feature-based , label-based similarity 는 0과 1이 뒤섞여 있는 관계가 발생하기에 이를 어떻게 구분할까에 대한 기준이 명확치 않아 오히려 성능이 저하된다는거죠.
- 다음은 의도적으로 악의 유저들끼리 거래(상호작용)를 발생하지 않게끔 자체 룰을 설정하여, 악의적인 유저들끼리 관련없게끔 보이게 위장한다는 겁니다. 동일 인물이 여러 개의 거래를 할 때 이 거래 패턴들이 유사하나, 모두 다른 아이디로 거래한다는거죠. 동일 인물이나, 실제로 '동일 인물'이 아니라고 인지하기 때문에 거래의 주체인 '노드'를 기점으로 패턴 유사도를 파악하는게 중요하지만, 이를 잘 구분하지 못한기 때문에 성능이 저하된다는겁니다.
- 여기까지 문제를 정리해보면, 1. 정상 거래와 비정상 거래를 의도적으로 혼합하여 거래하기 때문에 탐지 모델이 구분하기 어려워진다. 2. 사람이 보았을 때 비슷한 거래 패턴이긴하나, 그 거래 주체인 아이디가 모두 다르기 때문에 탐지 모델이 이를 구분하기 어려워진다. 다음 두 가지로 문제를 정의할 수 있습니다. 이 문제를 해결하기 위해 본 논문에서는 '패턴'에 유의미한 정보를 잘 추출하고 구분하기 위해 정상 거래 대비 다소 적은 양의 비정상 거래 패턴을 잘 Pick 하고 잘 Choose해보자 라는 아이디어를 제시합니다.
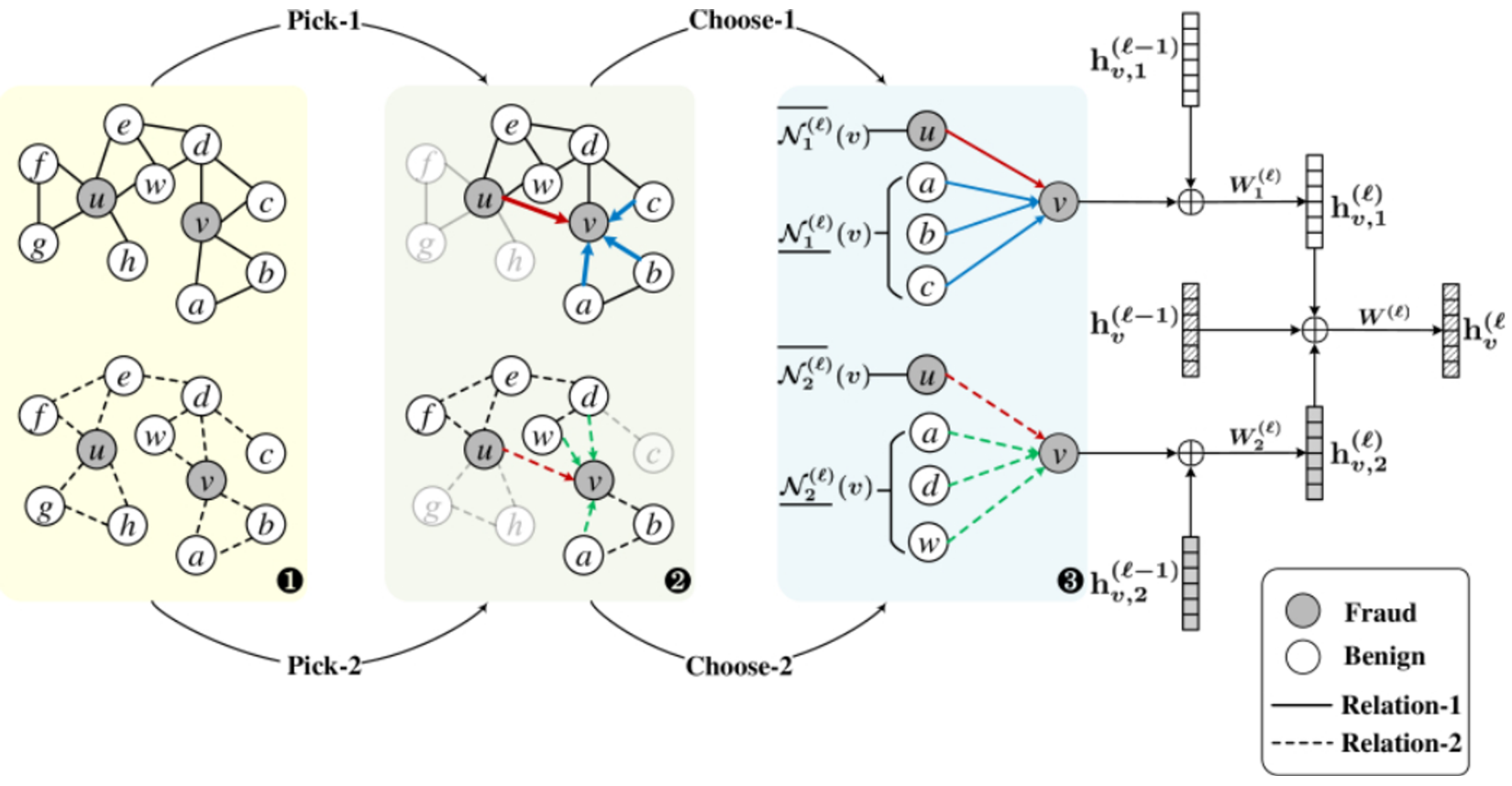
- 핵심 아이디어는 Pick, Choose 제목에 나와있는 그대로입니다. 학습을 위해 미니배치마다 서브그래프를 추출할 때 imbalance 를 최소화 하기 위해 label-balanced 샘플링을 합니다. 이 때 샘플링하는 확률이 핵심입니다. label 분포를 분모로, 분자로는 해당 노드의 인접 행렬로 설정해주어, label 분포인 분모가 커질수록 서브그래프 추출에 포함될 확률이 적어지고 반대로 label 분모가 작을수록 서브그래프 추출에 포함될 확률이 커지게 됩니다. 이처럼 label 의 많고 적음에 따라 규제를 적용하여 균형잡힌 서브그래프를 추출합니다.
- 다음으로는, 추출된 서브그래프에서 추론 성능 향상을 위해 유의미한 정보량을 늘리기 위해 거리 기반 함수를 활용해 필터링을 해줍니다. 간단하게, 서브그래프에서 1-hop 이웃들을 살펴보았을 때 상대적으로 적은 label 을 가진 노드들을 over-sampling 해주고 많은 label 을 가진 노드들을 under-sampling을 해준다고 보시면 되겠네요. 하지만, 무작정 sampling 해주는게 아니라, 과연 해당 노드가 유의미한 정보를 가졌는가에 대해 판단하기위해 거리 기반 함수를 활용합니다.
- 평소에 알고 있던 거리 기반 함수인 유클리디안 함수와 같은 경우는 추론에 활용되는 label 정보를 고려치않기에, 본 아이디어에서는 label 정보를 고려한 거리 기반 함수를 만들기 위해 완전 연결 계층을 만들어 줍니다. 다시 말해 Fraud 와 연결된 계층의 weight 값, Benign 과 연결된 계층의 weight 값의 차를 활용해 이 값이 적을 수록 유사하고, 이 값이 클수록 유사하지않다라고 가정하고 유사한 값은 over sampling 유사하지 않은 값은 under-sampling 을 해주는거죠.
- 이렇게 under sampling , over sampling 된 최종 결과물들을 합쳐준 뒤 학습을 하게 됩니다. 이 때, loss 값이 기존에 진행했던 gnn 값 뿐만 아니라, pick choose 를 통해 도출된 거리기반 함수의 loss 값을 추가로 고려하여 2개의 loss 값을 최소화 하는 방식으로 학습이 진행됩니다.
- 본 아이디어와 유사한 모델들을 베이스라인으로 설정해두고 실험한 결과 모두 성능이 좋게 나왔습니다. RQ1 에서는 fraud detection model , sampling 에 특화된 model , minority 에 특화된 모델 등 세 가지 측면에서 본 아이디어가 왜 성능이 잘 나왔는지에 대해 이야기합니다.
- 실험결과들이 단연 모두 재밌었으나, 그 중 눈길이 갔던 부분은 Table 5 부분입니다. ablation study 의 결과인데요. label-balanced sampler 를 뺀 \p 모델과 neighborhood sampler 를 뺀 \c 모델 그리고 두 모델이 모두 적용된 최종 모델 3가지 결과를 비교해보았을때, 두 모델을 모두 적용한 최종 모델이 당연하게 성능이 좋지 않을까 하는 생각과 다르게 \p 모델이 압도적인 성능을 보입니다. 이를 다르게 해석해보면 label-balanced sampler 즉 label 의 분포에 따라 subgraph를 추출하는것보다 그냥 단순히 random 으로 추출한 결과를 기반으로 under , over sampling 한게 좋다 라고도 해석할 수 있습니다. 이 부분은 제 생각이구요. 논문에서는 상대적으로 적은 label class 때문에 subgraph 추출시 정보손실이 많이 발생하므로 이런 결과가 발생했을것이라고 말합니다.
[Contact info]
email - jeongiitae6@gmail.com
linkedin - https://www.linkedin.com/in/ii-tae-jeong/