
24년 6월 1주차 그래프 오마카세

Uncovering Implicit Mechanisms in Graph Contrastive Learning
NIPS 2023
배지훈
Keywords
Graph Contrastive Learning (GCL), Implicit Regularization Mechanism, ContraNorm
Summary
- 위 저자들은 Visual domain에서 Graph Contrastive Learning (GCL)을 적용한 연구들 사이의 공통적 사실을 제시합니다. 그리고 다른 Visual Contrastive Learning (VCL)과 차별화된 GCL만의 특성을 폭넓게 분석하고 제안합니다.
- GCL은 유사한 조건에서 성능 저하가 발생하는 Visual Contrastive Learning (VCL)과 달리, 명시적인 Positive 또는 Negative 샘플 없이도 강력한 성능을 유지하면서 Agnostic Augmentation (e.g. Gaussian Nosie)만으로 견고성을 보여줍니다
- 다음 논문에서 기존의 다양한 VCL와 비교하여 독특한 GCL만의 특성들을 설명하기 위해 기존 아키텍처들을 분석하고, 그 요소 및 Contrastive learning의 목표 사이의 흥미로운 상호작용을 설명합니다.
- GCL에서 수행되는 Graph Convolution의 내재적인 정규화 메커니즘에 집중합니다. 구체적으로, Feature Aggregation 단계에서 이웃 노드와 유사해지도록 업데이트를 수행하여 Alignment loss를 최소화합니다. 다음 사실로부터 Positive sample로부터 자유로워지는 GCL 방법을 설계할 수 있습니다.
- 또한, GCL 상에서 Negative sample이 없는 경우, 혹은 특수한 아키텍처 설계가 필요없는 Projection head의 역할을 집중 탐구합니다. 그로부터, 다음 Projection head가 내재적으로 모델 수렴을 위한 Low-rank의 feature subspace를 선택한다는 사실을 발견합니다.
- Node classification 문제에서 활용되는 정규화 레이어를 통합하여 uniformity loss 없이 단일 GCN 인코더만으로도 Feature collapsing 문제를 방지할 수 있다는 사실을 보여줍니다.
- 일반적으로 GCL은 그래프 증강 기법을 통해 Positive & Negative samples를 생성하고, 그로부터 노드 혹은 그래프 표현을 학습하기 위한 대조를 수행합니다. 위 사실로부터, 기존 GCL의 방법들과 차별화된 더욱 단순하고 강력한 방법을 본 논문에서 제안합니다.
- 논문의 소제목들을 통해 다음을 요약해보자면,
- Positive Sample은 필수적이지 않다.
- Graph Classification의 경우 Negative sample도 필수적이지 않다. Node Classification의 경우 인코더의 Normalization만으로도 충분하다.
- 단순한 증강 기법만으로도 GCL의 성능을 유지할 수 있다.
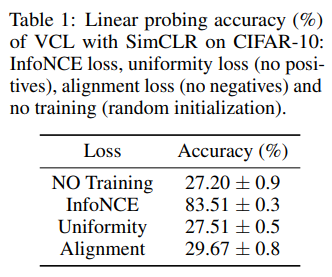
- Table 1과 같이, 저자들은 예기치 않게 기존 GCL 방법이 Positive sample 없이도 적절한 성능을 달성한다는 것을 Node & Graph Classificatioon 문제에서의 광범위한 실험을 통해 발견합니다.
- 다음 사실로부터 GCL에서 사용되는 GNN 인코더 (e.g. MPNN)들은 내재적으로 Positive smaple의 Aggregation을 활성화하는 Implicit Regularization effect를 가지고 있다는 사실을 알 수 있으며, 저자들은 일반적인 GCN의 컨볼루션 상의 정규화 메커니즘을 자세히 풀어냄으로써 위 현상에 대한 이론적인 인사이트를 제공합니다.
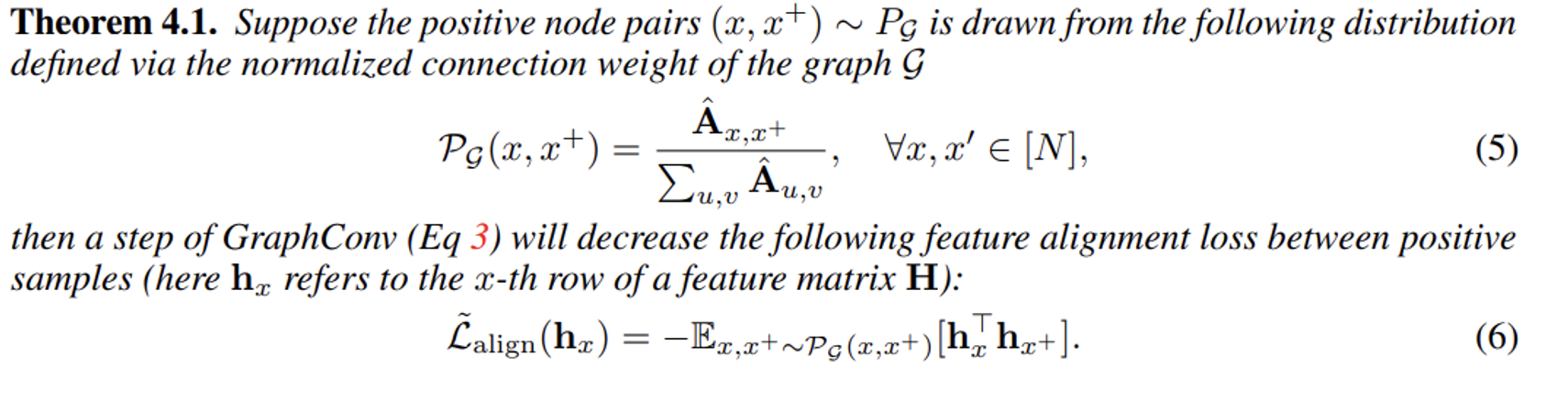
- Theorem 4.1에서 제공하는 사실은 그래프 컨볼루션과 Alignment objective 사이의 일반적으로 형성되는 관계를 대변할 수 있으며, 그로부터 그래프 컨볼루션 연산자가 GCL에서 자연스러운 Positive sample에 대한 alignment loss를 대체할 역량을 가질 수 있음을 증명합니다.
- Negative sample이 없는 GCL의 Graph classification의 경우, 놀랍게도 Projection head으로부터 Feature collapse의 영향을 받지 않고 기본 Alignment loss만으로도 잘 동작한다는 사실을 발견합니다. 하지만 Node classification의 경우 단순히 Negative sample을 제거하는 것은 Feature collapse 현상을 해결할 수 없음을 발견합니다.

- 후자의 경우, Theorem 4.1 , 5.2를 바탕으로 단순하게 ContraNorm(CN)으로 불리우는 특수한 정규화 요소를 GCL 인코더에 통합하는 것이 암시적으로 Neighbor-induced Contrastive Loss를 최적화하여 Collapse 현상을 피할 수 있다는 것을 설명합니다.
- 다음 통합 모듈은 Flexible하게 다른 GCL 방법에도 적용할 수 있습니다.
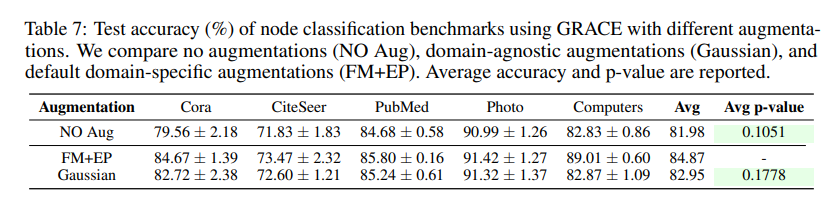
- Table 7와 같이, 단순한 random Gaussian Noise만을 증강기법으로 추가함으로도 도메인 특화적인 증강기법 (e.g. Edge Perturbation, Node removal)과 비교하여 성능의 강건함을 유지할 수 있음을 보여줍니다.
Conclusion
- 본 논문에서는 기존 Visual Contrastive Learning과 달리 GCL만의 흥미로운 몇가지 사실을 증명하였습니다.
- Positivie Sample의 영향이 크지 않다.
- Graph Classification의 경우 Negative Sample의 영향이 크지 않다. 하지만 Node Classification의 경우 Feature Collapse 현상이 존재하며, 다음은 ContraNorm + Graph Convolution의 통합 모듈을 통해 해결할 수 있다.
- 단순한 그래프 증강 기법 (e.g. Gaussian Nosie)만으로도 꾸준한 성능 유지가 가능하다.
- 다음 논문에서 중요한 고려사항은, 저자들은 위 사실들을 광범위한 Node & Graph Classification 실험을 통해 유도해내었으며, 이러한 사실이 모든 GCL 방법들을 커버할 수 있다는 것은 아니라는 점입니다.
- 저자들은 모델 구조의 내재적인 메커니즘인 Message Passing을 그래프 인코더로 활용하는 경우에 대한 GCL의 개별적인 특성 및 그와 관련한 관찰 결과들을 제공하였으며, 그에 대한 신빙성을 일부 Theorem을 통해 제시하였습니다.
- 하지만, 해당 논문에서 발견한 사실들은 기존 VCL과 비교하여 GCL에 대한 새로운 인사이트를 충분히 제공하였으며, 이로부터 차후 단순하고 효율적인 그래프 특화된 SSL을 연구 및 설계하는 데 큰 도움이 될 수 있을거라 생각합니다.
[Contact Info]
Gmail : jhbae1184@akane.waseda.jp
Twitter (X): @jhbae1184
Bring Your Own Algorithm to Anomaly Detection
정이태
안녕하세요 Pinterest Engineering 마지막 시리즈 입니다. Pinterest 에서 발생하는 여러 이상 데이터들을 탐지하기 위해 어떤 방식을 그 동안 사용하고 있었으며, 그 방식의 개선을 위해 어떤식으로 노력을 기울이고 있는지를 알아보고자 합니다.
https://medium.com/pinterest-engineering/bring-your-own-algorithm-to-anomaly-detection-bdc0eef3fa79
Pinterest는 사실 그간 야후에서 개발한 EGADs 라는 open-source를 이상탐지에 활용하고 있었습니다. 하지만, java 로 구현되어있고 제한되어있는 알고리즘 때문에 특정 알고리즘을 모듈형태로 새로이 넣을때 불편하다는 단점이 존재했습니다.
이를 개선하기 위해 Warden이라는 확장된 개념의 라이브러리를 개발합니다. EGADs의 기능을 동일하게 활용할 수 있으며, 파이썬으로 개발된 새로운 이상탐지 알고리즘도 적용할 수 있게 되었습니다. 생각해보면, 기존 java로도 충분히 활용이 가능했으나 데이터 사이언스 분야에서 파이썬을 주력 언어로 활용하고 있기 때문에 생태계 관점에서 파이썬을 접목하는게 Pinterest 입장에서도 언젠간 풀어야할 숙제였기에 이런 시도를 하지 않았을까 싶습니다.
Warden는 하기 그림의 순서대로 작동하며, 핵심 가치는 다음과 같습니다.
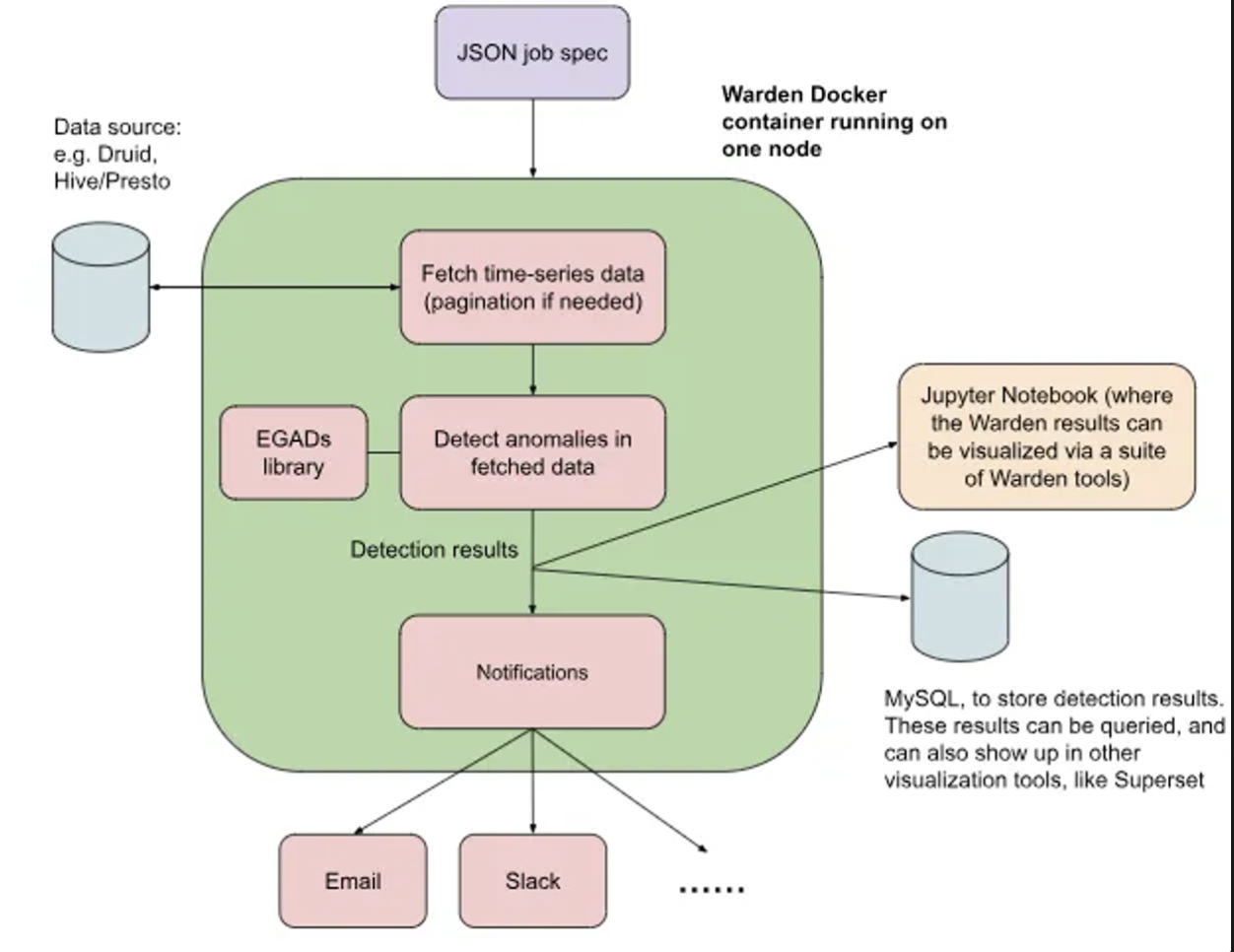
그 중 가장 돋보이는 구간은 바로 Data fetching 입니다. 평소에 이상탐지를 하는 부분에서 간과하는 부분이 바로 Data injection 부분입니다. 실시간으로 발생하는 데이터들을 모두 관리하고, 이 데이터 내에서 이상한 부분을 찾기도 전에, 데이터 관리에서 OOM같은 이슈가 발생하곤 합니다.
이 관점을 고려하여 Warden에서는 각 알고리즘 binary executable 형태로 만든 뒤, 각 Warden node에 할당해줍니다. 덕분에, database fetching 후 알고리즘 적용할 때마다 각 알고리즘이 컴파일 형태로 되어있기에 기존인터프리터에서 발생하는 병목 현상을 완화해줍니다. 간단하게 말해보면, 알고리즘마다 직렬화 ↔ 역직렬화를 해주어 데이터에 알고리즘 적용할 시, 컴퓨터 자원을 효율적으로 활용할 수 있게끔 최적화해준다는게 핵심입니다.
**자세한 내부 동작 순서 및 원리는 하기 링크에서 확인할 수 있습니다.
Warden 을 활용함으로써, 결국 각 사용자마다 상황에 맞는 알고리즘을 사용할 수 있으며 위에 언급한 것과 같이 EGADs 의 장점을 가져다 쓸 수 있고, 이를 기반으로 production level에서 고민할 부분인 자원 할당 부분인 node cluster 두 가지 요소들을 고려하여 쉽고 안전하게 배포할 수 있다는 점이 되겠네요. 직렬화 비직렬화를 통해 기존 데이터와 알고리즘 적용시에 발생하는 overhead를 최소화할 수 있다는 점 또한 굉장히 매력적으로 와닿습니다.
본 포스팅에서는 인터페이스, 테스트환경 배포 , production level 배포 관점이 생략되어있습니다. 관심있으신분들은 한 번 살펴보셔도 좋을 것 같네요.
추가로, 본 포스팅과 유사하게 국내 카카오뱅크에서 이상탐지를 위해 어떤식으로 엔지니어링 + 알고리즘을 적용하는지 잘 작성되어있는 게시물이 있어 공유드립니다. 본 포스팅과 함께 살펴본다면 이상탐지 과업을 수행시 레퍼런스 삼기에 좋을것이라 생각합니다.
킁킁!킁! 어디서 사기 냄새 안나요? : FDS 시스템에 AI 적용하기, https://tech.kakaobank.com/posts/2310-applying-ai-into-fds-system/
 yahoo
yahoo