3월 첫째주 그래프 오마카세

Learning Inter-Superpoint Affinity for Weakly Supervised 3D Instance Segmentation
ACCV 2022
배지훈
keyword : Superpoint Graph, Inter-superpoint affinity mining, Volume-aware instance refinement
Introduction
- 저번 주 오마카세 주제와 동일하게, 슈퍼포인트 그래프 표현학습을 활용한 포인트 클라우드 분할 문제 적용에 관련한 논문을 가지고 왔습니다.
- Weakly Supervised learning 방법은 대체로 Fully supervised learning의 메뉴얼한 레이블링 한계점을 극복하기 위하여 소수의 레이블링 정보를 효율적으로 활용하여 좋은 성능을 달성하는 목표를 가지고 있습니다. 다음 방법론의 공통적인 핵심 포인트는 얼마나 좋은 퀄리티의 Pseudo-label을 생성하여 비레이블링(non-label) 데이터에 할당할 수 있는지에 놓여 있습니다.
- 다음 논문에서, 저자들은 슈퍼포인트의 의미론적 특징(Semantic Feature)을 랜덤워크 (Randomwalk) 방식으로 전파하는 알고리즘을 개발하였으며, 랜덤워크의 무작위성을 최대한 잡아주기 위해 인접 슈퍼포인트 간의 의미론적 및 공간적 관계성 기반 유사도를 측정하는 방법을 활용하였습니다.
- 또한 Pseudo-label이 할당되어진 슈퍼포인트들의 Refinement 작업을 다음의 볼륨(Volume) 정보를 활용하여 더욱 Compactness한 인스턴스 분할 결과를 달성해내었습니다
Methodology
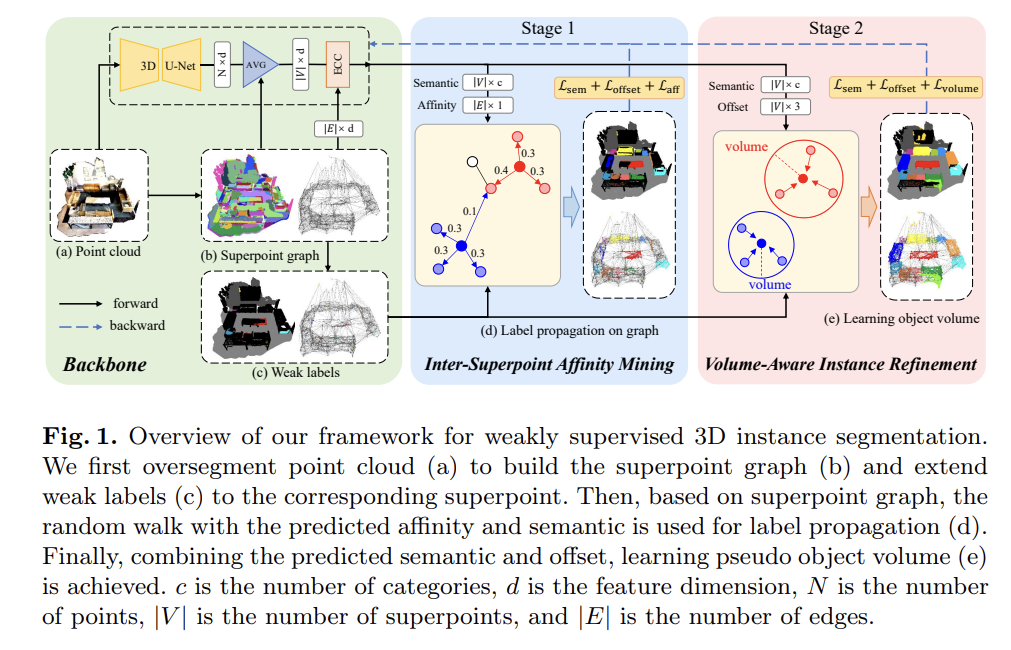
- Fig 1에 Weakly supervised 기반 3D 인스턴스 분할 문제를 다루기 위한 제안 프레임워크가 나와있습니다. 다음은 크게 3단계 (Backbone, Inter-Superpoint Affinity Mining, Volume-Aware Instance Refinement)로 나누어져 있습니다.
- 해당 프레임워크의 핵심 방법을 간략하게 요약하자면, 먼저 Backbone 모델에서 추출한 슈퍼포인트 그래프의 의미론적 정보를 기반으로, 레이블 포인트와 유사도가 높은 비레이블에 동일한 레이블 정보를 전파시킵니다. (Stage 1) 그 이후 추가적으로 포인트들의 볼륨 정보를 활용하여 동일한 인스턴스 레이블을 갖는 포인트들의 상대적 거리를 더욱 가깝게 만들어주는 Refinement 과정을 통해 더욱 Compactness한 인스턴스 분할 결과를 얻어냅니다. (Stage 2)
Backbone
- 본 논문의 저자들은 먼저 슈퍼포인트를 생성하기 위해 기존 방법 (SPG, SSTNet)들을 참고하였습니다.
- Backbone으로 3D U-Net 모델을 사용하여 원본 포인트 클라우드의 특징을 추출해내고, Average Pooling을 통해 평균 임베딩을 해당 슈퍼포인트로 집계합니다. 그 이후 다음 슈퍼포인트들의 KNN 그래프를 생성합니다.
- 다음 슈퍼포인트 그래프는 다시 ECC 레이어를 통해 슈퍼포인트 특징 (Semantic, Offset Vector)을 추출해냅니다.
Inter-Superpoint Affinity Mining
- 추출해낸 슈퍼포인트의 특징을 활용하여 먼저, 다음 모듈에서는 슈퍼포인트 간 유사도 (Affinity)를 측정합니다. 다음 유사도 벡터에는 의미론적 (Semantic) 정보 및 공간적 (Offset) 위치 유사성을 포함하고 있으며, 이를 식 1로 공식 정의하였습니다.
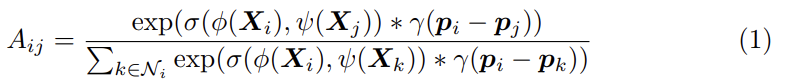
- 다음 유사도 벡터의 결과를 바탕으로, 유사도 값이 높은 엣지 가중치로 연결된 두 임베딩 포인트를 가깝게 이동시키는 학습 방향으로 슈퍼포인트 그래프를 업데이트합니다. 위 과정은 L_{stage1} Loss를 통해 학습이 이루어집니다. (식 9)
Label propagation via semantic-aware random walk
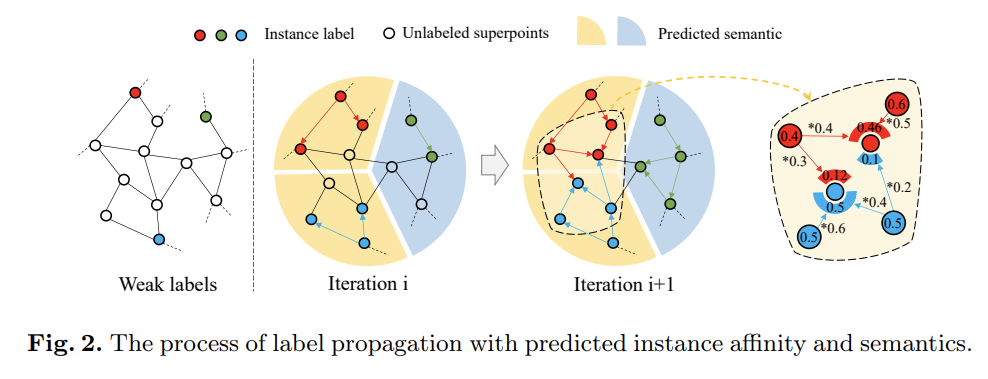
- 가깝게 위치한 임베딩 포인트들에 동일한 인스턴스 레이블을 할당하기 위해, 초기 슈퍼포인트 그래프의 소수 레이블 정보를 업데이트된 그래프로 할당합니다. 다음 과정에서 본 저자들은 랜덤워크 (Random Walk) 알고리즘을 활용합니다.
- 랜덤워크 알고리즘을 활용하여 레이블 포인트로부터 인접한 비레이블 포인트의 위치를 찾아내고, 동일한 레이블의 정보를 전파시킵니다. 하지만 다음 알고리즘이 반복되면 한 포인트 상에서 다른 레이블 정보가 혼합되어질 수 있습니다. (Iteration i+1 그림의 빨강,파랑색 포인트 부분을 참고하시기 바랍니다.)
- 다음의 경우, 위에서 계산한 유사도 (Affinity) 및 의미론적 특징 (Semantic)과 그래프 연결 관계 (인접행렬 A)를 모두 활용하여 레이블 별 가중치를 얻어냅니다. 그리고 동일한 레이블 가중치의 합산을 통해 전파되어질 확률값을 계산합니다. 최종적으로 상대적으로 더 큰 확률값을 갖는 레이블의 정보를 최종 전파시킵니다.
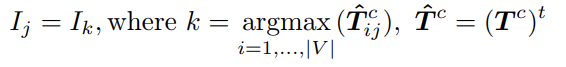
- 논문에서 설명이 나와있진 않았으나, 다음 방법은 인상적인 Pseudo-label 할당 결과를 얻어낼 수 있지만 정확한 할당이 되었다고는 장담할 수 없을 것입니다. 그 이유로는 먼저 랜덤워크의 무작위성(Randomness)이 매우 크다는 부분과, 단순 합산을 통한 레이블 전파 연산은 그래프 연결 구성에 따라 상대적으로 다른 인스턴스에 속한 포인트와 연결이 많이 되었을 경우 틀린 레이블이 전파될 가능성이 높을 수 있기 때문입니다.
- 따라서 본 논문에서는 추가적으로 Refinement 단계를 추가하여 정확도 높은 Pseudo-label 할당을 수행합니다. 다음 과정에서 개별 인스턴스의 볼륨 (Volume) 정보를 활용합니다.
Volume-Aware Instance Refinement
- 먼저 동일한 레이블을 할당받은 모든 포인트들을 동일한 해당 인스턴스에 포함되어 있다고 가정합니다. (논문에서는Pseudo-instance로 표현하였습니다. 잘못 할당된 포인트들도 존재할 수 있기 때문에 다음과 같은 표현을 한 것으로 생각됩니다.)
- 각 인스턴스의 볼륨 정보를 인스턴스를 구성하는 복셀의 개수와, 인스턴스의 중심 좌표로부터 가장 멀리 떨어진 포인트와의 거리로 정의한 Volume Radius를 기준으로 잡았습니다.
- 구체적으로, Offset 정보를 활용하여 인스턴스 내 포인트들이 중심 포인트에 가깝게 위치하도록 이동시킵니다. 그리고 Radius 값을 임계값으로 사용하여 특정 조건을 만족하는 이웃 포인트를 뽑아내고, Breadth-first Search 알고리즘을 사용하여 이들을 하나의 그룹으로 클러스터링합니다.
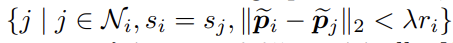
- 다음 클러스터링 결과를 최종 분할 Proposal로 뽑아내며, 부분 분할된 (Fragmented) Proposal의 경우에는 위에서 계산한 복셀 개수를 활용하여 필터링해냅니다.
- 다음 Refinement는 L_{stage2} Loss 함수를 통해 학습이 이루어집니다. (식 11)
Experiments
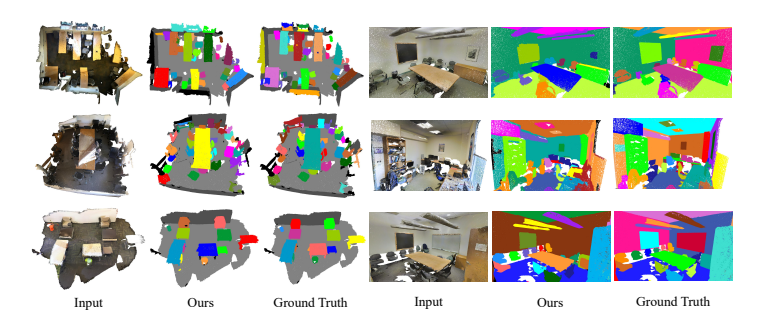
- 정성적 실험 결과를 살펴보면 의미론적 특징정보들을 활용하였기에 조명 빛, sparse한 노이즈에 크게 영향받지 않고 기하학적 구조들까지 잘 분할해내었음을 확인할 수 있었으며, 시야(view)에 따라 원거리의 작은 객체들까지 구분해낼 수 있었습니다.
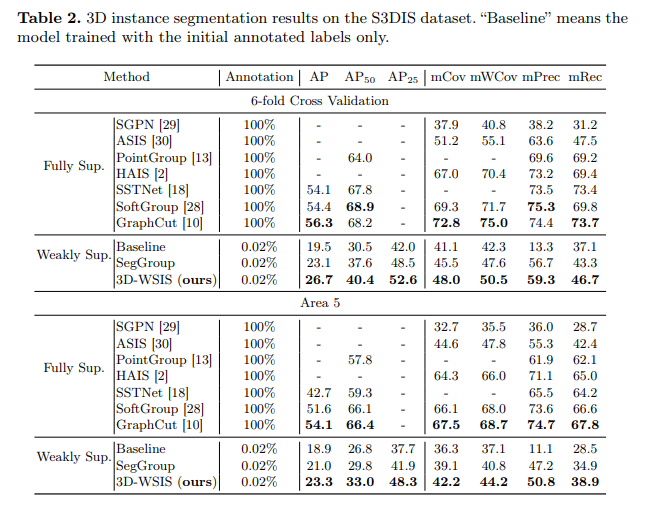
기존 Weakly Supervised 방식들과의 정량적 비교 결과에서 가장 높은 평가 지표를 얻어내는 등의 인상적인 결과를 보여주었으며, Fully Supervised 방식들과는 차이가 조금 나긴 하였지만 0.02%의 매우 소수의 어노테이션 레이블만 가지고도 좋은 결과를 보여주었습니다.
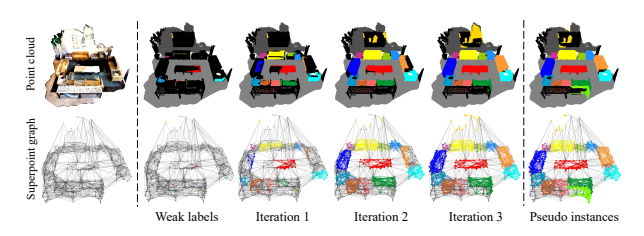
- Pseudo-label 전파 과정의 시각화 결과에서, 적은 iteration 만으로도 인스턴스 별 Ground Truth Label과 유사한 할당 결과를 얻어내었다는 점도 눈여겨볼만한 부분이었던 것 같습니다.
Conclusion
- 이번 논문에서도 슈퍼포인트 그래프 표현학습을 통하여 Semantic Segmentation보다 더 복잡하고 어려운 문제인 Instance Segmentation에서도 인상적인 결과를 얻어낼 수 있다는 점을 확인할 수 있었습니다.
- 개인적으로 레이블 전파 과정을 기존 그래프 컨볼루션 신경망의 학습 메커니즘과 연관되어있다는 부분도 느낄 수 있었고, 슈퍼포인트를 그래프 노드로 정의하여 학습을 진행하는 점에 집중하면 Node Classification 분야에서도 활용해볼 만한 아이디어가 있지 않을까 생각해보기도 했었습니다.
- 상대적으로 쉽게 그래프로 표현할 수 있는 포인트 클라우드 포맷의 효율적인 그래프 표현학습 방법들이 많이 등장하고 있는 만큼, 특히 3D 비전의 다양한 문제에서 그래프 활용을 통한 인상깊은 방법론들이 제안되기를 바라는 마음입니다.
[Contact Info]
Twitter (X): @jhbae1184
G-Retriever: Retrieval-Augmented Generation for Textual Graph Understanding and Question Answering
정이태
PaperLink : https://arxiv.org/pdf/2402.07630.pdf
CodeLink : https://github.com/XiaoxinHe/G-Retriever
Keywords : Graph RAG , Retrieval-augmented generation , Large Language Model, hallucination , Graph Neural Network
[Content]
논문을 이야기하기에 앞서, GraphRAG 를 어떻게 적용하는지
- GNN(graph neural network) 의 결과값인 그래프 임베딩을 활용하여 유저 질의 응답추론에 활용하는 텍스트 임베딩에 그래프 임베딩을 덧붙여 활용합니다.이 방식은 Soft-prompting 이라고 불리며, 프롬프트 엔지니어링 방식 중 하나입니다.
- 프롬프트 엔지니어링은 크게 Hard, Soft 두 가지로 분류를 나누어 볼 수 있습니다. Hard 는 Explicit 형태로 프롬프트를 제공하는 형태를 의미합니다. 주어진 유저 질의문에 맥락을 임의로 작성해 부여해주는 방식입니다.
- 예를 들자면, '나는 오늘 빵을 먹고 싶어' 형태로 유저 질의가 주어졌다면, '[task] 당신은 고객에게 빵을 잘 제공해야하는 임무가 있습니다. [context]질의가 온 시각은 아침시간대이니, 되도록 소화가 잘되는 빵종류를 제공하는게 좋을거 같습니다. 또한 [persona] 고객의 주 특징은 다이어트 중인 20대 여성분이오니, 정제된 탄수화물이 들어간 흰빵 종류는 추천 대상에서 자제해주세요. [example] 좋은 예시로는 추천 빵 이름과 빵을 맛있게 먹는 방법 그리고 빵 칼로리를 같이 이야기해주세요. [tone] 친절한 어투로 작성해주세요' 와 같이 task , context , persona, example, format , tone 6가지를 임의로 입력해주어야합니다.
- 보시다시피, '임의'로 작성하였기에 프롬프트를 작성하는 사람의 주관이 많이 개입되어 있고 해당 프롬프트가 최적인지 판단하기에 어렵다는 단점이 있습니다. 하지만, 간단하게 구현할 수 있다는 장점이 있죠.
- 이와 반대로, Soft 는 Implicit 형태로 프롬프트를 제공하는 형태를 의미합니다. 모델이 질의와 유사한 추론 결과를 도출할 때 기존 텍스트 임베딩에 추가로 임베딩 정보를 부여하는 방식을 뜻합니다.
- '학습'된 맥락인 임베딩 정보를 부여하였기에 객관성이 보장되며, 최적화된 가중치 값을 도출할 수 있습니다. 하지만, 간단하게 텍스트로 입력하는게 아닌 직접 모델을 설계 및 구현 해야한다는 점때문에 구현이 어렵다는 단점이 있죠.
GraphRAG 를 언제 쓰는게 좋을지
- GraphRAG가 만능은 아닙니다. 기존 RAG 가 잘 작동하는데 무리해서 Advanced RAG 인 GraphRAG를 사용한다? 주변 시선이 그렇게 좋지만은 않을거라 생각되네요. 기존 시스템에 무언가를 개선하려 할 때, 당위성이 필요합니다. 즉, 이걸 왜 해야돼 라는 주변의 물음에 사실 근거를 통해 답변하고 설득해야 하는거죠.
- Retrieval 단계에서 가져오는 정보들과 유저 질의 의도가 매칭이 잘 되지 않을때, 시도해볼만합니다. Vector Search 의 근본적인 한계와 비슷한 맥락입니다.
- Similarity 측정을 통해 Retrieval 하기에 엄밀히 말하면 '정확'한 값을 기반으로 정보를 가져오는게 아닌, '근사'한 값을 기반으로 정보를 가져오기 때문에 부정확한 정보를 가져올 수 있습니다.
- 이를 개선하려고 주로 BM25 를 도입하여 exact search 를 추가한 hybrid search 방식을 활용하거나, Ranking process 를 개선하여 Reranker function 을 만든다거나, 혹은 embedding 품질 개선을 위한 Fine-tuning 등 다양한 시도를 하게됩니다.
- 이 다양한 시도를 했음에도 불구하고 RAG 성능 개선이 미미하다 싶을때 GraphRAG 도입을 고민해보시는걸 추천합니다.
G-Retriever 가 어떻게 작동하는지
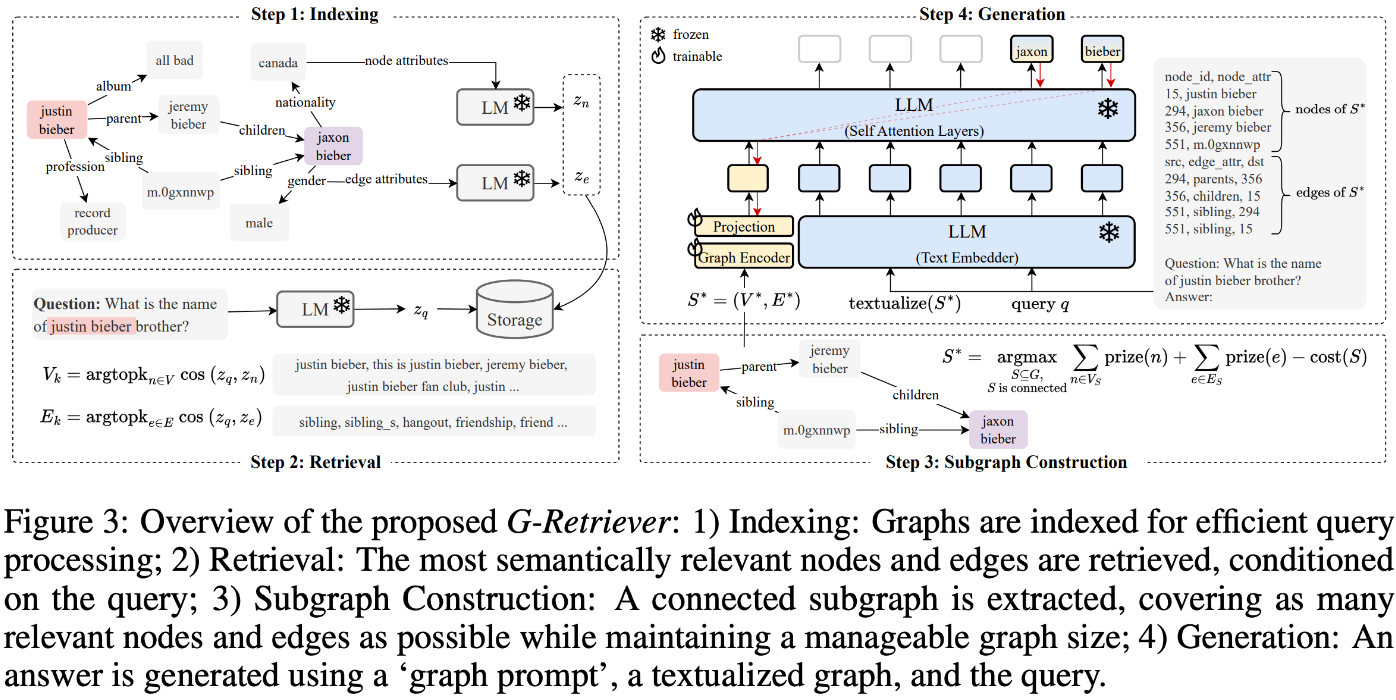
1.Indexing
- 사전에 활용할 정보들을 잘 다듬어 불러오기 좋은 형태로 데이터를 가공하고 보관하는 과정입니다. GraphRAG 에서 사전에 활용할 정보들은 그래프 내 노드와 엣지의 프로퍼티에 담겨있는 텍스트 정보들을 의미하며, 이를 정량화된 값으로 변환하기 위해 언어 모델을 활용합니다.
2.Retrieval
- 유저 질의와 보관된 데이터가 얼마나 관련있는지 측정하고 불러오는 과정입니다. 관련성을 측정하기 위해 언어 모델로 '질의' 와 그래프 내 '노드','엣지' 값의 유사성을 K-nearest neighbors 을 활용하여 측정합니다.
3.Subgraph Construction
- 다른 RAG에서 document 를 가져오는 것과 다르게, GraphRAG는 유저 질의와 관련있는 그래프를 가져와야 합니다. 앞선 Retrieval 과정에서는 단순히 유저 text 와 그래프 text 값 비교를 통해 정보를 가져왔기에, 엄밀히 말하자면 그래프의 연결관계인 Semantic을 활용했다 라고 보기 어렵습니다.
- 그래서 이를 활용하기 위해 각각 노드 엣지가 유저 질의와 얼마만큼 Semantic 유사성이 있는지를 판단해야 합니다. 판단 방식으로는 PCST(Prize-Collecting Steniner Tree)을 활용합니다.
- PCST 방식을 간단히 말씀드리자면, 우선 노드와 엣지에 각각 prize를 부여합니다. 이 때, prize 를 부여하는 값을 설정할 때 앞선 과정 Retrieval 에서 진행되어 나온 유저 질의와 유사한 노드 , 엣지들의 랭킹 유사도를 활용합니다.
- 유사한 노드들에게는 Prize 로 큰 값을 부여합니다. 반면에, 유사하지 않은 값들에게는 적은 값 혹은 0 을 부여해줍니다.
- 부여된 prize 값들을 기준으로 연결된 노드 엣지들마다 덧셈을 해줍니다. 총합이 높은 노드 , 엣지들을 추출하여 이 값은 즉, 총합이 높은 노드 엣지들 이 때, 서브그래프가 사이즈를 조절해주기 위해 cost 라는 파라미터를 활용하여 edge 마다 패널티를 얼마나 줄지를 사전에 지정합니다.
- 최종적으로, 서브그래프 사이즈를 조절하고 유저 질의와 유사한 정보를 담은 서브그래프들을 추출하게 됩니다.
4.Answer generation
- 질의에 대한 답변을 생성하는 단계입니다. 텍스트 임베딩 값과 그래프 임베딩 값을 조합해 답변 생성에 활용합니다.
- 여기에서 잠깐, 텍스트 임베딩이 갑자기 나와서 혼란스러우실수도 있는데요. 텍스트 임베딩은 가중치 갱신이 되지않게 Frozen 한 Pre-trained LLM의 self attention layer 값을 의미합니다.
- 그럼 결국 그래프 임베딩 값 기반으로 학습되기에 초반에 이야기한 soft-prompt 의 장점인 최적화된 가중치 값을 추출 및 갱신하여 답변 생성에 Semantic 을 활용한다 라고 할 수 있습니다.
- 그래프 임베딩 값을 도출하고 텍스트 임베딩 값과 조합하기 위한 방식은 간단합니다. 1. GNN으로 node embedding 을한다. 2. Pooling layer를 활용해 그 값들을 종합한다. 3. Pooling layer 로 도출된 값과 텍스트 임베딩 값의 차원을 맞춰주기위해 MLP 레이어를 통해 projection 합니다.
G-Retrieval 인사이트
1.Efficiency Retrieval
- Efficiency 기준이 모두 다를거라 생각합니다. 본 논문에서는 Efficiency 를 Retrieval 전 / 후 를 비교하여 Token 의 활용양이 얼마나 절약되는지를 기준으로 이야기합니다.

- RAG의 핵심 중 하나는 주어진 토큰 용량내에 최적의 정보를 넣는게 핵심이라 할 수 있는데요. G-Retrieval 를 활용했을시, 무려 토큰의 량이 83% 부터 99% 까지 감소하는 효과를 보입니다.
2.Architecture
- G-Retriever의 효과를 입증하기 위해 총 3가지 아키텍쳐를 비교실험합니다. 1.Pretrained 된 가중치만을 활용하는 아키텍쳐 2. Pretrained 된 가중치와 프롬프트 엔지니어링을 활용하는 아키텍쳐 3. Finetuning 된 가중치와 프롬프트 엔지니어링을 활용하는 아키텍쳐 위 세 아키텍쳐마다 가지고 있는 함의가 각자 다릅니다.
- 우선 첫번째 아키텍쳐에서는 textual graph 가 유의미한지를 알아보기 위함이고, 두번째 아키텍쳐에서는 Graph Encoder 와 projection 을 통해 soft-prompt 가 유의미한지를 알아보기 위함입니다. 마지막 세번째 아키텍쳐에서는 Graph 와 별개로 LLM 가중치를 최적화하는게 유의미한지를 알아보기 위함입니다.

- 결론적으로 모든 아키텍쳐마다 Graph 가 유의미함을 실험결과로써 입증합니다.
3.Performance
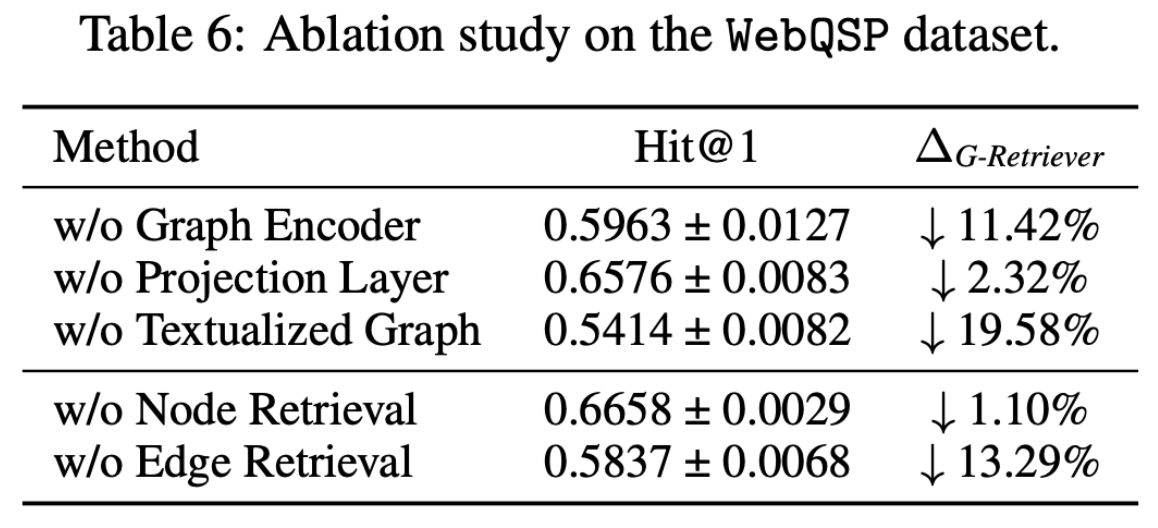
- Ablation study 의 결과또한 재밌습니다. 특히, Graph 관련 부분에서 w/o Edge Retrieval 에서 13%가까이 성능이 저하됨을 확인할 수 있습니다. 이를 해석해보자면, Edge 즉 Semantic Retrieval 이 RAG 에서 중요한 기능을 하는 요소라 볼 수 있습니다.
끝으로, GraphRAG 에서 유의할 점은 무엇인지
- Graph 를 Retrieval 하는것도 중요하지만, 어떻게 전체 그래프를 설계했는지 또한 중요합니다.
- 본 아이디어에서는 Knowledge graph 벤치마크 데이터셋을 가져와서 Retrieval 하는것만 보여주었기에 어떻게 그래프가 만들어졌는지에 대한 이야기는 생략되어 있습니다.
- 이 점을 유의하여,어떻게 노드가 만들어졌고 어떻게 엣지가 만들어졌고 더 나아가 Semantic 을 왜 이렇게 설정했는지에 대한 근본적인 의문을 유지하면서 Task를 수행하는것을 추천드립니다.
[Contact Info]
Email : jeongiitae6@gmail.com
Linkedin : https://www.linkedin.com/in/ii-tae-jeong/