2월 2주차 그래프 오마카세


PU-GCN: Point Cloud Upsampling using Graph Convolutional Networks (CVPR 2021)
배지훈
keyword : Point Cloud Upsampling, Graph Convolution, NodeShuffle, Inception DenseGCN
[Content]
Introduction
- 포인트 클라우드의 기하학적 구조정보를 포착하고, 포인트 사이의 관계정보를 학습하는 그래프 신경망을 활용하여, 다양한 포인트 클라우드 분석 및 처리 분야에서 활발한 연구들이 진행되고 있습니다.
- 이번에 소개드릴 논문은, 3D Sensor로부터 얻어진 Sparse Noisy한 포인트 클라우드를 Dense Clearly하게 정제 처리하기 위한 방식으로 그래프 컨볼루션 신경망을 사용한 선행 연구로 볼 수 있습니다.
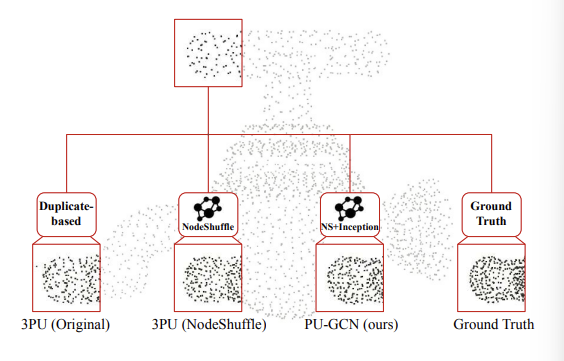
- 기존 포인트 클라우드 업샘플링 방법들은 크게 Multi-branch MLPs와 Duplicate-based approach로 나눌 수 있습니다. 본 논문 저자들은 Multi-branch MLPs의 Point-wise한 특징에 집중한 업샘플링 방식이 포인트 클라우드 내 이웃과의 관계정보를 무시한다는 문제점과, Duplicate-based 방식의 값비싼 연산량을 문제점으로 지적합니다.
- 위의 문제점들을 해결하기 위해, 즉 포인트의 Local detail을 잘 활용하고, 더욱 적은 학습 파라미터로 학습 속도를 향상시키기 위해, 저자들은 그래프 컨볼루션 기반 2가지 모듈, ‘Inception DenseGCN’과 ‘NodeShuffle’ 을 제안하였습니다. 각각은 포인트의 다중스케일(Multi-scale) 특징정보를 추출하기 위한 연산자와, 추출된 포인트 상에서 업샘플링을 수행하는 연산자로써 활용됩니다.
- 왜 그래프 컨볼루션을 선택했는지의 질문에, 저자들은 기존 방법의 원본 포인트 클라우드 또는 MLPs의 출력으로 얻어낸 포인트들을 복제하는 과정이 필요 없이 Latent Space 공간에 새로운 포인트들을 생성할 수 있으며, 포인트 이웃들과의 공간적 관계정보를 더욱 잘 인코딩하여 업샘플링 퀄리티 및 모델 성능을 향상시킬 수 있기 때문이라고 설명합니다.
Details
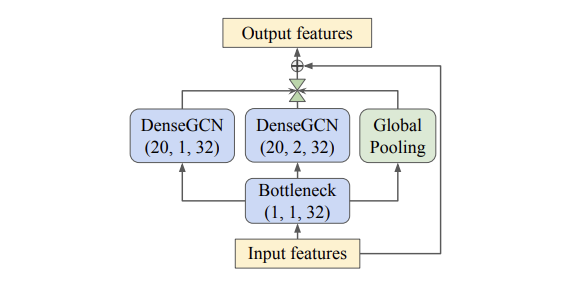
- 구체적으로, 먼저 ‘Inception DenseGCN’ 모듈은 GoogleNet의 Inception Bottleneck 모듈 구조를 활용하여 이후의 GCN 레이어에서 연산해야 할 파라미터 수를 줄인 후, Multi-scale한 로컬 특징을 추출하기 위한 커널 사이즈를 키우는 것 대신에 DeepGCNs(Lim et al., 2019)에서 제안되었던 Dilated Graph Convolution을 사용하였습니다. 또한 Global Pooling 레이어를 추가하여 글로벌한 컨텍스트 특징도 활용하였으며, Residual Connection을 통해 이전 레이어의 학습된 풍부한 특징정보들을 학습하는 구조를 설계하였습니다.(아래의 Fig 3을 참고하시기 바랍니다.)
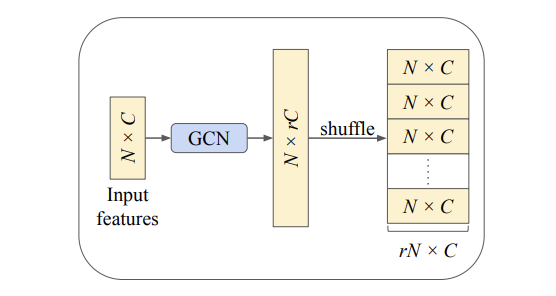
- NodeShuffle 모듈은 먼저 1개 레이어의 GCN을 통해 입력 포인트의 채널정보를 확장(Channel Expansion) 시킨 후 (C → C`), Periodic Shuffle** 방법을 통해 형태값을 재정렬시킵니다. (N x C → rN x C) (아래의 Fig 2를 참고하시기 바랍니다.)
- 실제로 다음 GCN은 포인트 클라우드의 그래프 표현 학습에 Baseline으로 많이 사용되는 DGCNN(Wang et al., 2019)의 EdgeConv로 구현되었습니다.
** Periodic Shuffle 방법은 슈퍼레졸루션 분야에서 제안된 ESPCN (Shi et al., 2016) 논문의 아이디어를 적용한 것으로 생각됩니다. 이에 대한 자세한 설명은 다음 링크를 참고하시면 좋을 것 같습니다. (https://mole-starseeker.tistory.com/84)
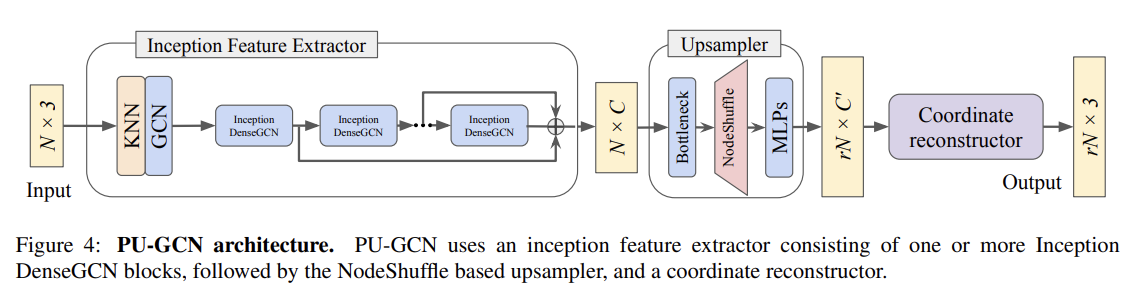
- 저자들은 다음 두 모듈을 하나의 네트워크로 통합하여 PU-GCN의 이름으로 제안하였습니다. PU-GCN의 전체 아키텍처 구조는 Fig 4를 참고하시기 바랍니다.
Experiment
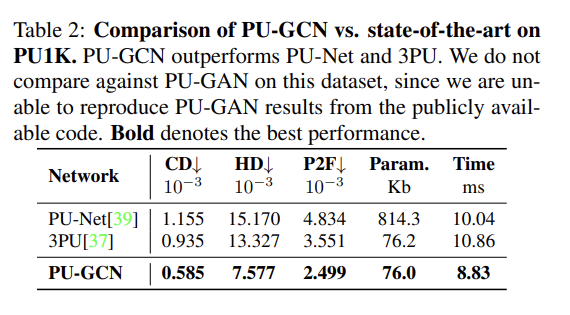
- PU-GCN의 성능을 검증하기 위해, 본 저자들은 포인트 클라우드 업샘플링을 위한 새로운 데이터셋 ‘PU1K’을 제안하였으며, 이전 'PU-GAN' 논문에서 제안되었던 데이터셋도 활용한 포괄적인 정성적 & 정량적 실험에서 모두 기존 업샘플링 방법들보다 향상된 성능을 일관되게 보여주었습니다.
- 평가 검증지표로써, 저자들은 이전 연구들과 동일하게 Chamfer Distance (CD), Hausdorff Distance(HD), Point-to-surFace Distance (P2F)를 사용하였으며, 추가적으로 전체 학습파라미터 수와 추론속도를 함께 제공하여, 기존 모델대비 PU-GCN의 빠른 학습속도와 향상된 성능을 증명하였습니다.
- 자세한 실험 환경 및 분석내용은 본 논문을 참고하시기 바랍니다.
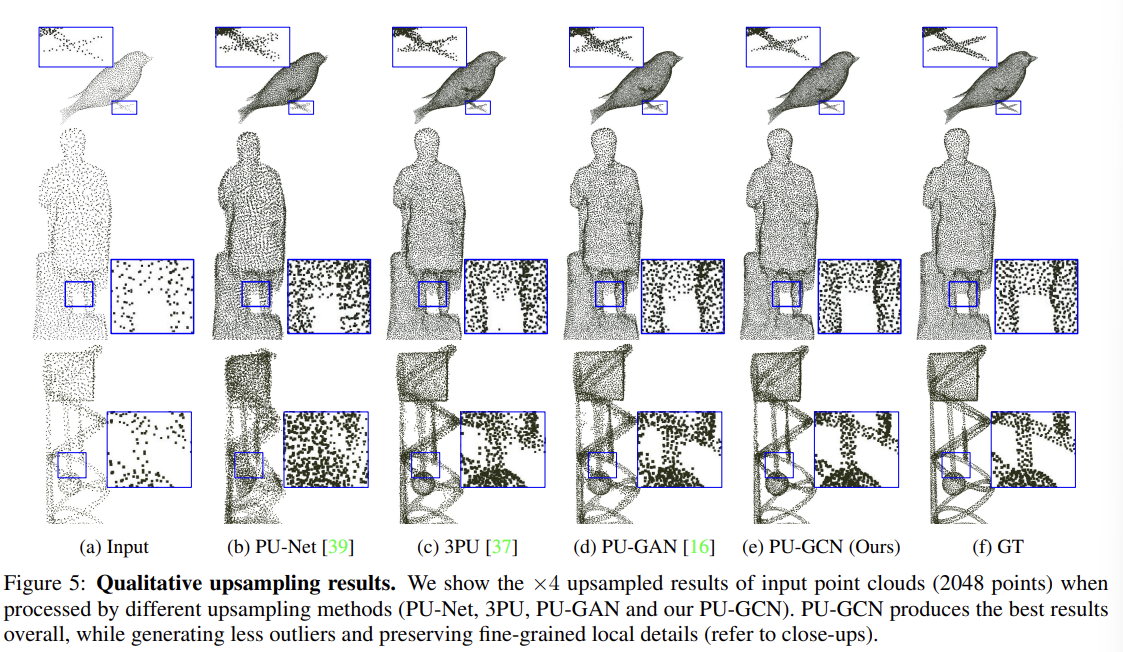
Summary & Conclusion
- 요약하자면, 해당 논문은 본래 Sparse하고 Noisy한 Raw 포인트 클라우드를 Dense하고 Clear하게 업샘플링 하기 위해 그래프 컨볼루션 연산을 활용한 두 모듈 ‘NodeShuffle’ 과 ‘Inception DenseGCN’을 설계하였으며, 이들을 통합시킨 새로운 포인트 클라우드 업샘플링 모델 'PU-GCN'을 제안하였습니다.
- 개인적으로, 해당 논문의 주목할만한 방법이나 아이디어가 크게 느껴지진 않았으나, 그래프 컨볼루션 연산 기반의 포인트 클라우드 업샘플링 분야의 선행 연구로써 그 가치를 인정받은 것 같습니다.
- 다음 논문을 바탕으로 그래프 어텐션 신경망(GATs) 기반 ‘PU-GAT & PU-GACNet’ 및 트랜스포머 모델 기반 ‘PU-Transformer’ 등 차후 포인트 클라우드 업샘플링 방법론의 기초가 되었기에 간단하게 소개드리면 좋을 것 같아서 이번 주 오마카세 리뷰 논문으로 정해보았습니다. (위 논문들도 차차 리뷰해보도록 하겠습니다.)
[Contact]
Gmail : jhbae7052@gmail.com
LinkedIn : https://www.linkedin.com/in/jihun-bae-757302289/
Twitter : @jhbae1184
SGCN: Exploiting Compressed-Sparse Features in Deep Graph Convolutional Network Accelerators
정이태
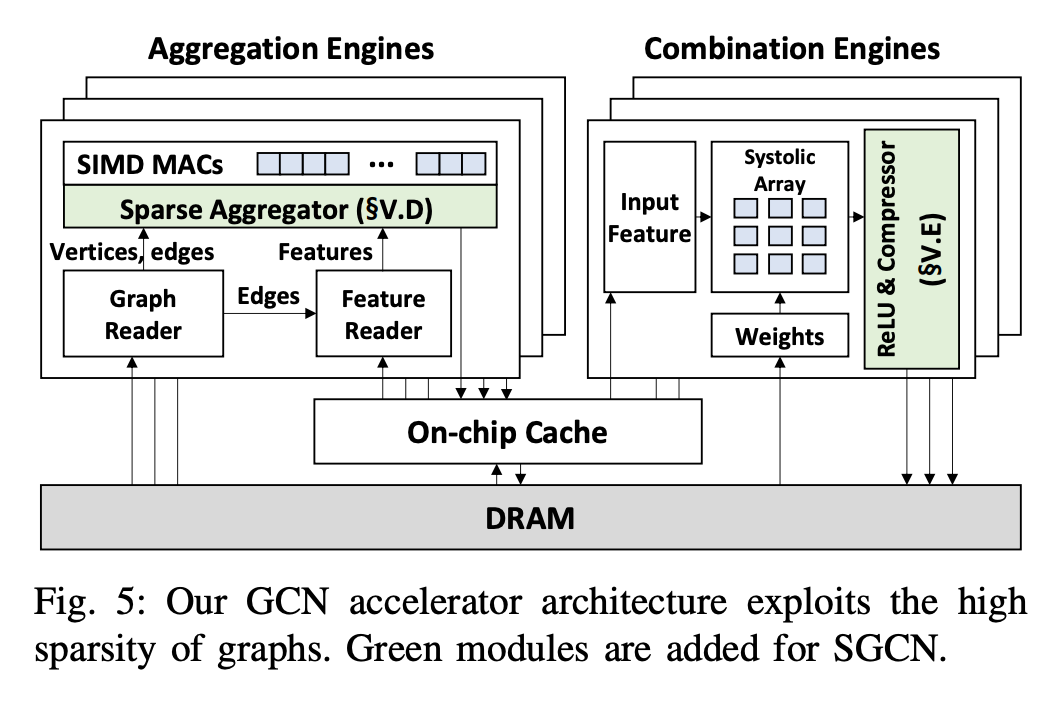
- 오늘 소개시켜드릴 논문은 그래프 딥러닝에서 화두인 특성 희소성을 하드웨어 , 소프트웨어 관점으로 접근하여 어떻게 해결했는지를 이야기합니다. GCN 은 타 딥러닝 아키텍쳐와 다르게 '토폴로지'와 특성을 곱해줌으로써 정보를 어디에서 어디로 가야할지 직접 지정 및 전달해줌으로써 가중치를 업데이트합니다. 이말은즉슨, '토폴로지'에 비례하여 정보가 전달되기에 연결이 적은 노드들은 상대적으로 적은 특성이 전달될것이고, 연결이 많은 노드들은 상대적으로 많은 특성이 전달될건데요. 이처럼 많고 적은 특성들을 효율적으로 컴퓨터에게 입력하기 위해 주로 CSR(Compressed Sparse Row)형태로 전달하곤 합니다. 핵심은 Non-zero(0이 아닌값)의 위치를 효율적으로 확인하고 그 위치만을 연산에 인덱싱하여 연산에 활용하는겁니다.
- 하지만, CSR은 0이 아닌 값마다 추가 요소가 필요하기에 특정 희소성 범위에서만 효율성이 좋고, 특정 범위 이상을 초과하게 되면 오히려 성능 저하를 야기하게 됩니다. 구체적으로는 각 노드의 주변 이웃 그리고 그 주변 이웃 마다 가지고 있는 특성에 접근하여 가져오고 집계하는 GCN 과정동안 메모리에 부여되어 열심히 일을하나 희소성때문에 어떤 프로세스에서는 널널하게 일을하고, 어떤 프로세스에서는 너무 많은 연산때문에 병목현상이 발생하는거죠.
- 위 원인을 해결하기 위해 본 논문에서는 크게 1. 데이터 희소 형태 개선 2. GCN 아키텍쳐 개선 를 시도합니다. 쉽게 말해보자면 Sparse 를 효율적으로 다루기위해 CSR 에서 Bitmap-index 방식을 차용하여 키 값을 포함하는 행의 주소를 cacheline 에 제공합니다. 그리고 입력된 정보들을 Tiling 하여 유사한 희소성을 가지고 있는 이웃들을 탐지한뒤 그 희소성에 따라 집계 하기 위해 cache 마다 적절한 working set size를 적용하여 memory 의 과부하를 방지합니다. 집계되고 업데이트된 가중치를 활성화 함수에 적용하는 등 학습하기위해 임의로 잘 밀집해놓은 데이터를 다시 sparse 형태로 변형합니다. 이 과정을 반복하며 학습된 가중치가 도출되는 거죠.
- 실험들이 모두 재밌었기에 특정 실험을 고르기가 어려웠는데요. 고심끝에 그 중 가장 재밌었던 부분은 Fig 14. memory access 였습니다.memory access 를 1. topology 2. feature input 3. feature output 3가지로 분류하여 학습동안 얼마나 메모리를 고루고루 잘 사용하는지를 보여준 실험결과입니다. 매번 대용량 데이터를 어떻게 처리할지 그리고 그 처리가 효율적인지 측정하기 위한 지표를 고민하곤 했는데 이 실험 결과 덕분에 명쾌해진거 같아 개인적으로 매우 흥미로웠습니다.
- 그래프 딥러닝의 기초라고 할 수 있는 GCN 작동 원리 그리고 하드웨어 소프트웨어 관점에서 어떤식으로 개선할 수 있는지를 알 수 있었던 논문이였습니다. 특히 Bitmap index 방식을 차용해 데이터 표현을 개선함으로써 cacheline & cache capacity 를 활용한 점이 굉장히 재밌게 다가왔던 논문이였습니다. 본 논문과 유사하게 하드웨어 & 알고리즘 그리고 소프트웨어 관점에서 그래프 딥러닝 성능 개선 서베이 논문과 함께 보면 더욱 좋지 않을까 싶어 추가로 첨부합니다.
[Good resource]
A Survey on Graph Neural Network Acceleration: Algorithms, Systems, and Customized Hardware
[Contact]
Email - jeongiitae6@gmail.com,
Linkedin - https://www.linkedin.com/in/ii-tae-jeong/