24년 5월 3주차 그래프 오마카세


Inferring Point Cloud Quality via Graph Similarity
TPAMI 2020
작성자 : 배지훈
link : https://arxiv.org/abs/1901.09993
Keywords
Point cloud Quality Assessment, Human visual system (HVS), Graph Signal Processing (GSP), GraphSIM
Summary
- 인간의 시각 시스템 (Human Visual System, HVS) 기반 인지 과정 (Perception process)을 기반으로, 포인트 클라우드 품질 (Point Cloud Quality)을 객관적으로 평가하는 사실적인 지표 (Metrics)을 제안한 논문을 하나 소개해드리고자 합니다.
- 2D Image & Video 등에서 잘 구축되어진 Structural Similarity Index (SSIM) 지표가 존재하는 것과는 달리, 비구조적(Unstructed)이고 downsampling & distortion 변환 등을 적용한 여러 deformation shape에 inconsistence한 3D 포인트 클라우드에 대한 품질 평가 지표를 정의하는 것의 어려움을 문제점으로 지적합니다.
- 인간의 시각 시스템 (HVS)에 관련한 수많은 연구들을 통해 실제로 Contrast, Edge 등과 같은 High spatial frequencies 요소들에 크게 집중하여 해당 물체를 정확하게 인지한다는 놀라운 사실을 바탕으로, 포인트 클라우드의 정확하고 효과적인 품질 평가 방법 및 지표를 처음으로 제안합니다.
- 제안 아이디어는 포인트 클라우드 상의 Local neighbors points의 connectivity를 명시적으로 임베딩하여 Point-wise relationships을 바탕으로, 입력 포인트 클라우드를 효율적으로 Characterize할 수 있는 그래프 표현 (Graph representation) 방법에 기초를 두고 있습니다.
- 그래프 표현 방법은 고차원 시각적 데이터에 대한 모델링을 가능하게 하므로, 이러한 사실로부터 HVS의 메커니즘과 큰 연관성을 갖게 됩니다.
- 저자들은 입력 포인트 클라우드의 그래프 표현 결과가 해당 객체 혹은 장면의 기하학적 요소들을 얼마나 정확하고 효과적으로 표현하였는가를 평가하기 위해, 새로운 포인트 클라우드 품질 평가 프로세스 GraphSIM를 제안합니다.
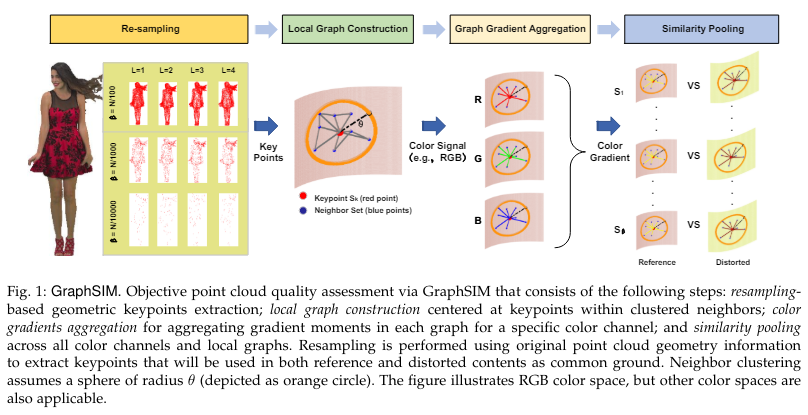
- Fig 1과 같이 GraphSIM 프로세스는 크게 4단계로 구분되어 있습니다.
- Re-sampling : 입력 포인트 클라우드의 기하학적 정보를 활용하여 Keypoint를 추출합니다.
- Local graph construction : 추출된 Keypoint를 spherical center point로 간주하고, 특정 반경(θ) 이내의 모든 노드들을 Neighbors로 간주하여 Local Graph를 구축합니다.
- Feature aggregation 및 Similarity measurement 이후 Graph deformation을 측정하기 위해, 기준이 되는 Reference 및 Distorted points에 대한 Local Graph 구축하였습니다. (식 10)
- Graph Gradient Aggregation : Reference 및 Distorted Local Graph의 Signals(R,G,B)을 기반으로 각각의 Graph Gradient를 계산하여 이들을 Aggregation 합니다. 이를 통해 Local Graph 상의 Signal Distribution을 잘 설명하고자 합니다.
- 임의의 신호 f에 대하여 해당 Graph Gradient는 graph Laplacian regularizer으로부터 파생된 모든 Edge Derivation의 집합으로 정의합니다. (식 2~5)
- Signal을 Color channel (RGB)로 고려하였을 때, RGB 채널 별 Color Gradient Features를 0차~2차 moments으로 나누어 Mass (식 11), Mean (식 12), (Co-)Variance features (식 15, 16)으로 표현합니다.
- Similarity pooling : 위의 3가지 features를 활용하여 Reference & Distorted Local graph 사이의 Similarities를 계산하고 (식 18,19,20), 이들을 Fuse하여 Pooling 연산에 적용합니다 (식 21).
- Pooling factor를 사용하여 시각적 인지 과정에서의 개별 Color Channel의 중요도를 반영할 수 있는 효과를 얻어냅니다.
- Pooled Color Channel에 대한 전체 평균을 통해 최종 포인트 클라우드 품질을 얻어냅니다. (식 22)
- 전체적인 내용을 간략하게 요약하면, 본 논문에서는 인간의 시각적 인지 시스템을 그래프 표현 방법으로 모델링하여 포인트 클라우드 상의 새로운 품질 평가 프로세스를 새롭게 정의한 GraphSIM를 제안하였습니다.
- 다양한 Point impairment datasets 상에서 GraphSIM을 기반으로 Mean Opinion Scores (MOS)를 예측하는 데 있어서, 기존 평가 지표 (e.g. PSNR, point-to-point & plane)보다 뛰어난 성능을 Experiement section에서 보여주었습니다.
[Contact Info]
Gmail : jhbae7052@gmail.com / jhbae1184@akane.waseda.jp
Twitter (X): @jhbae1184
Pinterest 엔지니어링 특집.
작성자 : 정이태
총 3주차에 걸쳐 Pinterest 에서 발행한 포스팅들에 대해 이야기할 예정이에요. 첫번째는 pinterest recommendation 두번째는 Text2SQL 세번째는 Anomaly detection입니다. 새롭게 문제를 정의하고 해결하는 논문들도 물론 좋지만, 현실 문제를 어떻게 해결하는지에 대한 엔지니어링 관점 또한 중요하다 생각하여 여러분들고 함께 하면 좋겠다 싶어 이런 특집을 만들어보게 되었네요.
Pinterest section 1 → Recommendation
Pinterest section 2 → Text2SQL
Pinterest section 3 → Anomaly detection
CS224w에서도 언급할만큼 GNN usecase 로 자주 거론되는 PinSAGE 그리고 해당 아키텍쳐를 활용해 유저에게 유용한 경험을 제공하는 Pinterest 플랫폼. 과연 지금은 어떤 엔지니어링을 통해 고객에게 감동을 전달하고 있을까요? 오늘은 Graph 를 사용한 section1 , 사용하지 않은 sesction2 그리고 내부 Data analytics 직군 생산성 향상을 위해 분석 생성형 AI를 구축하는 section3 이 3가지를 가지고 이야기합니다.
Section 1,2 는 Graph 를 사용했을때 설계방식과 사용하지 않았을 때 설계방식을 비교해보시는것을 추천드립니다. 둘 다 추론시 PinSAGE 임베딩을 활용한다는 공통점은 있으나, Graph 방식 사용여부에 따른 차이점이 있습니다. 이를 중점적으로 비교해보시며 오마카세 구독자 분들께서 추천시스템 기획시 현재 우리 기업에서는 Graph를 사용하는게 좋은지 안좋은지에 대한 참고 기준으로 살펴보시면 좋을것 같네요.
Engineering section 1 - (1)
LinkSage: GNN-based Pinterest Off-site Content Understanding
핀터레스트의 핵심은 유저에게 영감을 주는 것 입니다. 핀 보드 형태로 게시물들이 한 화면에 등장하며, 유저가 게시물을 보고 클릭하고 영감을 받게끔 행동을 유도하는 것이 핀터레스트 핵심이라 할 수 있습니다.
그럼 결국 유저에게 적합한 게시물들을 제공하는게 핵심이라 할 수 있습니다. 특히, 핀터레스트는 이미지 위주로 게시물들이 생성되기에 이미지 추천에 근접한 플랫폼이라 할 수 있습니다.
특히, 핀터레스트는 한 화면(랜딩페이지) 에 대략 10개 정도의 게시물(핀)이 노출됩니다. 그러기에 한 랜딩페이지마다 유저가 관심가질만한 10개의 후보 핀을 스크롤 행위에 따라 신속하게 제공해야하는게 핵심이기에, 엔지니어링 측면에서도 고려해야할 부분이 굉장히 많다 라고 생각할 수 있습니다.
여기에서 후보 핀들은 이전에 유저가 관심을 가졌던 핀들을 기준으로 유사한 핀들이라 할 수 있습니다. 여기에선 Positive Pin이라 합니다. 반면에, 후보가 되지않은 핀들은 제외하는 기술 또한 필요한데 이때 후보 핀과 유사하지 않은 핀들을 Negative Pin이라 부르고, 임베딩 시 negative dataset 으로 활용합니다.
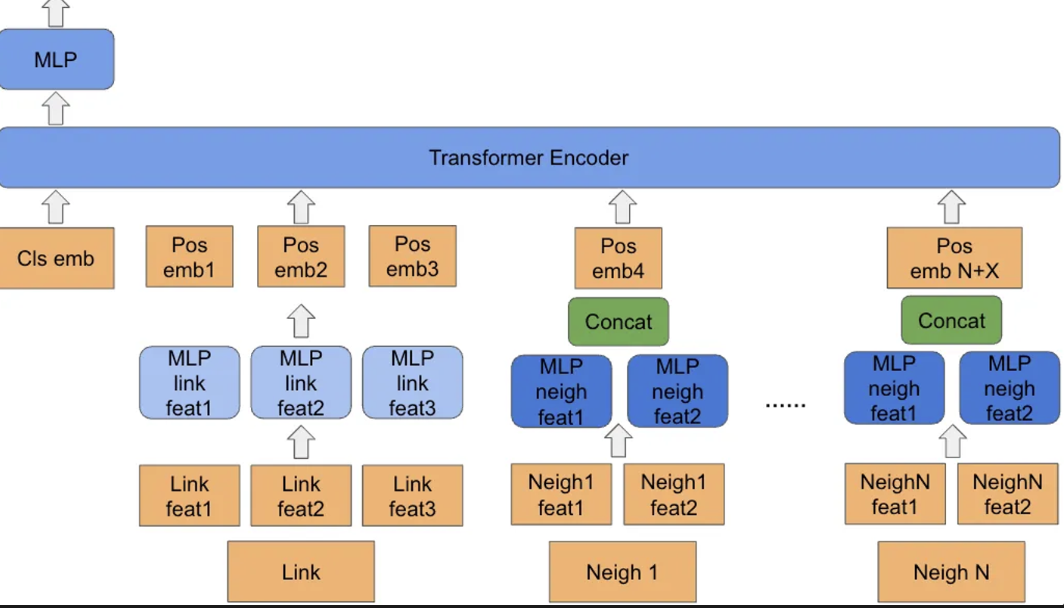
이렇게, 유저에게 어떤 정보를 제공하면 좋을지 기획이 진행된후엔 본격적으로 데이터를 활용해 추천을 해주어야 할 준비를 해야합니다. 이때, 문제가 발생하는데요. 특정 핀 후보군을 어떻게 선정하냐는거죠. 핀터레스트에는 굉장히 많은 게시물들이 매일 생성됩니다.
2018년 핀터레스트 게시물에 의하면 “10 billion recommendations every day.” 라는 말이 있을 정도로 대량의 데이터들이 발생합니다. 이를 선정하고자 **XPixie 에서는 random walk 방식을 차용해 특정 쿼리(유저가 질의한 것)을 기준으로 traversal 중요도를 산출하여 sampling(후보군 선정)합니다. 이를 동일하게 가져와 LinkSage에서도 마찬가지로 활용합니다.
서두에 언급한 바와같이, 해당 핀들은 image형태로 되어 있습니다. 그렇기에 핀의 구조적 특성 뿐만아니라 핀 자체의 콘텐츠인 이미지에 대해서도 고려해야합니다. 이를 LSH , Spark 그리고 Tensorflow 활용해 image searching 한 알고리즘인 Neardup 을 차용해옵니다.
최종적으로 이 과정을 통해 총 3개의 feature가 만들어집니다. 1.self landing page features, 2.neighbor landing page features, and 3,graph structure features. 이 모든 feature들을 transformer encoder 에 input 형태로 넣어주고 학습합니다. 기존 transformer 와 동일하게 attention 연산 , positional embedding 값이 활용되고 positional embedding 값을 통해 어떤 이웃들(random walk를 통해 생성된 sequence)이 중요한지에 대한 값 산출 또한 가능하게 됩니다.
****Pixie, An update on Pixie, Pinterest’s recommendation system[**https://medium.com/pinterest-engineering/an-update-on-pixie-pinterests-recommendation-system-6f273f737e1b]
Neardup, Detecting image similarity using Spark, LSH and TensorFlow[https://medium.com/pinterest-engineering/detecting-image-similarity-using-spark-lsh-and-tensorflow-618636afc939**]
지금까지 일련의 과정을 통해 나온 산출물들의 핵심은 다음과 같습니다.
Multi-dimensional representation
‘Matryoshka Representation Learning’ 관점을 활용해 5가지 각각의 Off-site content 값을 LinkSage 학습에 활용함으로써, 각각의 임베딩 값마다 다양성을 반영하여 학습할 수 있다는 장점. 이때 각각 5가지 feature 는 Cultural Relevance , User surface Recommendation , Shopping , Ads, Board Recommendation값을 의미합니다. 여기에서 특정 feature 를 사용 여부에 따라 performance 와 cost 간 trade-off 가 발생하게 되는데, 이를 유저가 적절하게 사용할 수 있는 유연성이 있다는 점이 핵심이라 할 수 있습니다.
Compatibility of XSage(Pinsage…)
Downstream inference 를 목적에 두고 학습한 임베딩 값이기에, 타 모델 추론시에도 활용할 수 있다는 점이 장점입니다.
Incremental serving
특정 핀과 관련된 대량의 데이터가 매일 10B 규모로 발생하는 만큼 적절한 값을 추론에 활용하고 이를 서빙하는것 또한 중요한 과제라 할 수 있습니다. 이를 위해 당일 랜딩페이지(유저가 보는 화면 기준 나열된 값들)를 임베딩하고 추론을 위해, 이전 임베딩값만을 가져와 merge한 후 추론합니다.
이 결과물들이 과연 비즈니스에 유의한가를 확인하기 위해 A/B test (Online experiment) 를 진행합니다.
User facing surfaces
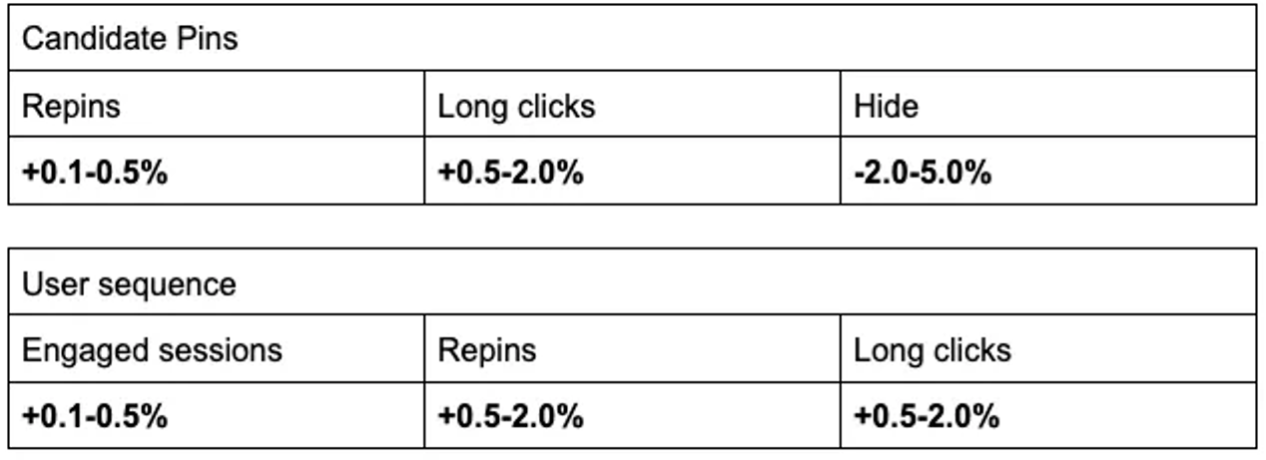
Pinterest 에서는 ‘repin, long click , engaged session‘ 3가지 유저 행동을 통해 유저의 positive engagement를 평가합니다. 반대로 ‘hide’라는 유저 행동을 통해 negative engagement 를 평가합니다. 이 4가지 긍정/부정 지표를 기반으로 LinkSage 모델 도입 전 후 결과를 비교한 표는 다음과 같습니다.
Ads
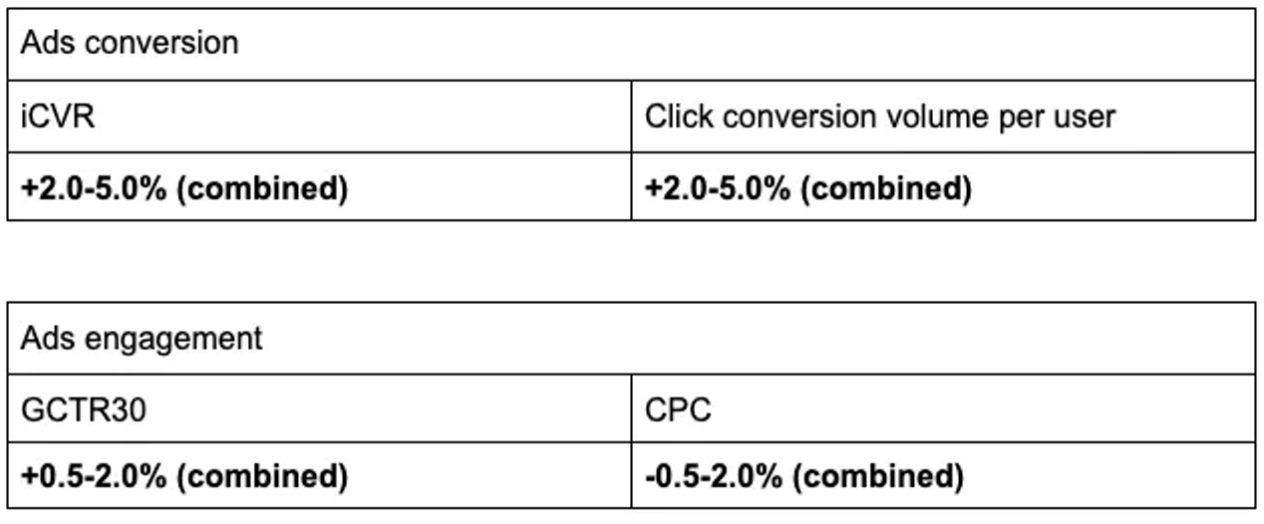
유저의 conversion 과 engagement 를 측정하기 위해 iCVR, conversion volume , long click through rate 그리고 CPC라는 4가지 지표를 활용하여 측정합니다.
Board

자체 pinterest Board ranking(Board Picker) 실험 확인결과 유의미한 상승이 있음을 확인할 수 있습니다.
GNN 베이스 모델인 LinkSage에 대해 이야기 했습니다. Heterogeneous graph 형태를 학습하여 다양한 entity 의 의미론적 정보를 활용할 수 있다는 점 그리고 graph / target 의 가지치기 기술(positive / negative pair pin & landing page Cohension 그리고 Neardup 이미지 유사도 비교 기술)을 통해 graph density 를 높였다는 점이 그래프 구조를 잘 활용한 예시라고 할 수 있습니다.
또한, 기존에 활용한 Pinterest ML signal(PinSAGE)와 같은 모델들과 compatiblity 할 수 있기에 downstream task 측면에서도 활용도가 높다는 점이 인상적입니다. Matryoshka Representation Learning 라는 관점을 차용해 Multi-dimensional representation 을 이야기하는데, 주방장도 처음 보는 관점이라 되게 신기했었습니다.
Different granularities 정보를 encoding 하고 이를 computational constraint 하여 downstream task에 활용한다는 점이 굉장히 흥미로웠었던 방식이였네요. 아무래도, 핀터레스트 특성상 다양한 형태의 텍스트 이미지등의 피쳐들이 존재하기에 이 피쳐들을 곧이곧대로 사용하기보다, 효율적으로 활용하기 위해서 고안한 방식 같습니다.
Engineering section 1 - (2)
User Action Sequence Modeling for Pinterest Ads Engagement Modeling
이번 섹션에서는 고객 경험을 위해 다음 3가지를 중점적으로 다룹니다.
Design for user sequence features
- 유저의 순서를 반영하기 위한 피처들 그리고 임베딩 방식
Leveraged Transformer for sequence modeling
- 유저의 행동순서를 어떻게 디자인하여 트랜스포머 아키텍쳐를 활용할 것인가.
Improved the serving efficiency by half precision inference
- serving 을 효율적으로 하기 위한 부동 소수점 튜닝 방식.
- Design for user sequence features
유저가 Pinterest 플랫폼에서 무엇에 관심을 갖고 어떤 콘텐츠에 무슨 의견을 가지고 있는지 피드백 관점을 도출하기 위해 engagement model 을 개발합니다. 이를 위해, 유저의 특성을 특정할 수 있는 패턴이 필요합니다. 이 패턴을 위해 본 섹션에서는 Sequence feature 를 추출하기 위해 어떤 요소를 고려하고 무엇을 통해 feature 형태로 만드는지 이야기합니다.
우선 피처 타입으로는 2개의 피처를 만들었습니다. 하나는 모든 Pins에 관여함을 나타내는 피처, 나머지는 ads 에 관여하는 피처. 이를 통해 Ads 로 발생하는 Pin 혹은 일반적인 추천 결과로 등장하는 Pin을 구분하여 유저의 관심도를 파악할 수 있다는 장점이 있습니다.
피처 특성으로는 user-engaged event 를 대표하기 위한 메타들인 timestamp, item representation(embedding) , id features, 그리고 taxonomy features 를 활용합니다. 이때, pre-trained embedding(GraphSage)를 활용해 각각의 아이템들간 interaction 을 임베딩한 값을 item representation 으로 적용하여 feature 로 간주합니다.
2)Leveraged Transformer for sequence modeling
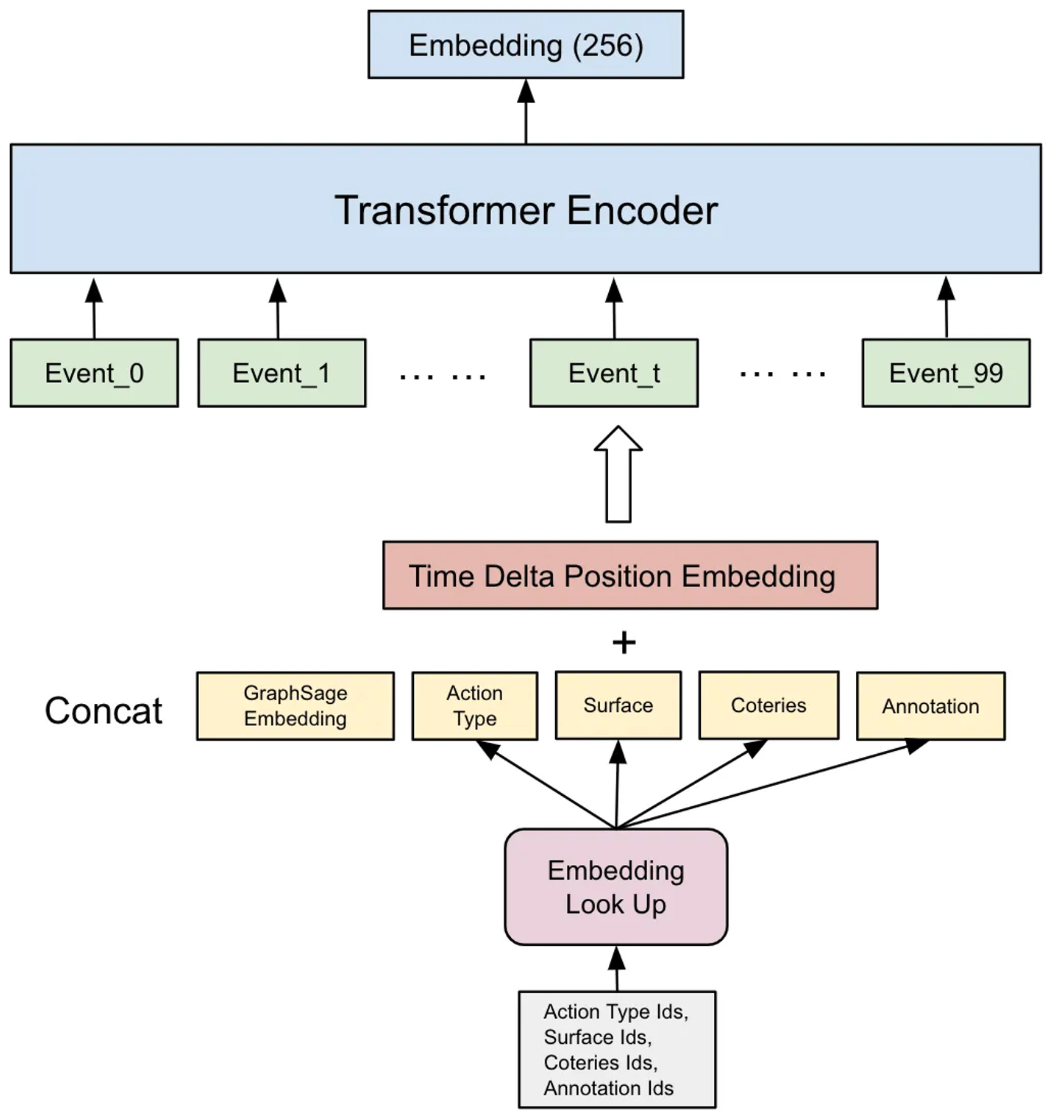
총 6개의 Embedding , feature 들이 connection 되어 특정 기간동안 발생한 Event 에 유저가 개입함을 대표한다 가정하고 Transformer Encoder에 주입하여 학습합니다. 이를 통해 최종적으로 256 차원의 임베딩이 발생하고 이 값을 기반으로 추론합니다.
이 방식을 본 포스팅에서는 Feature Connection 이라 말하며, 특정 event dimensionality 를 조정함으로써 각각의 Feature importance 를 조정할 수 있다는 점을 장점으로 언급합니다.
주목할점은 시간을 어떻게 임베딩하는가 입니다. 본 포스팅에서는 Period embedding 라는 방식을 활용합니다. 기간별 특성을 반영하기 위해 Sum Pooling 하는 방식입니다. 유저 행동 데이터를 기간별로 나눈 뒤 기간에 해당하는 이벤트끼리 Sum Pooling 형태로 임베딩하는 형태입니다. 이를 통해, 해당 기간에 이루어진 이벤트인 Pin , Ads 를 종합하여 정량화 할 수 있습니다.
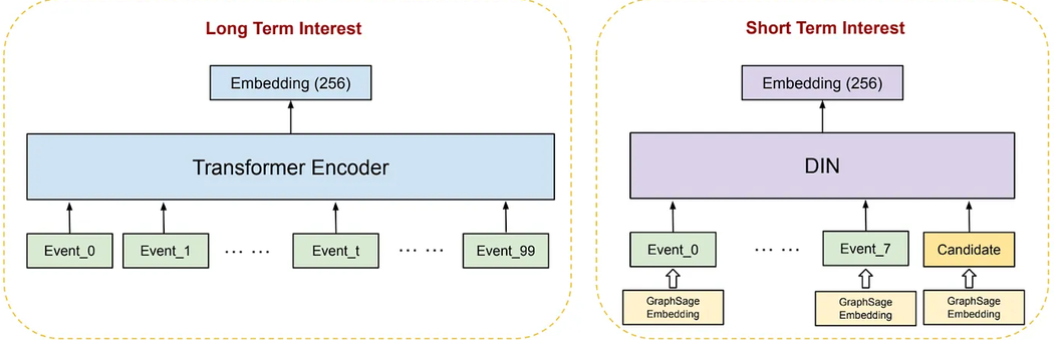
기간을 어떻게 구분하는지에 따라 모델이 유저가 무엇을 좋아하는지를 다르게 판단할만큼, ‘기간’은 굉장히 까다로운 파라미터라고 할 수 있습니다. 이를 위해, user-engagement 팀은 long / short term 을 나누어 임베딩을 진행했습니다. long term 은 지금까지 진행한 모든 과정들을 Transformer encoder 에 주입하고 short term 은 DIN(Deep Interest Network)을 활용하는 차이점이 있습니다. 또한, short term 을 최근 8개의 이벤트라 가정하고 이를 따로 떼내어 활용합니다.
DIN 을 활용하는 이유는 transformer 와 유사하게 attention 메커니즘을 활용하고, 이를 통해 Adaptive Interest Learning 를 하며 longer-term 와 short-term 간 변동을 capture할 수 있다 라는 점이 장점이기 때문입니다.
3)Improved the serving efficiency by half precision inference
좋은 피처 , 좋은 모델을 사용한다고 한들 결국 추론 값이 유저에게 얼마만큼 신속하게 전달되는지가 고객 경험 측면에서 중요하다 라고 할 수 있습니다. 이를 위해 mixed precision 기법을 활용합니다. 기존 부동소수점을 float32 를 사용하던 부분을 16으로 압축한다면 결국 특정 값을 대표하는 값 또한 압축되기 때문에, 데이터 표현에 제한이 생길 수 밖에 없습니다. 신속하게 추론이 가능하나 값을 대표하는 부동소수점 범위가 줄어들기 때문에 정확도 측면에서는 감소하기 때문에 trade-off 관계라 할 수 있습니다.
이 trade-off 를 최소화하기 위해, 본 포스팅에서는 layer의 크기마다 float16 , 32 데이터 타입을 각각 주입해보고 layer 마다 성능 저하가 얼마나 발생하는지를 실험해보며, 데이터 타입과 적합한 layer를 선정해줍니다.
이렇게 각각의 layer마다 다른 데이터 타입을 활용해 순전파 역전파 연산이 진행되다 보면, 결국 layer마다 값들이 상이하게 나옴을 예상할 수 있습니다. 이를 방지하기 위해 Resilient Batch Norm 을 적용합니다. 덕분에 각 레이어마다 나온 값들을 안정화 시킬 수 있다는 점을 이야기합니다. 하지만, 여기에서도 stale or delayed feature values , feature absence, 그리고 distribution shift 와 같은 이유때문에 extreamly small variance 과 같이 이슈가 발생하는것을 문제로 이야기합니다.
이를 위해 Resilent Batch Norm 의 2가지 하이퍼파라미터인 minimal_variance 그리고 variance_shift_threshold를 통해 어떻게 해결하는지에 대해 이야기합니다.
Evaluation
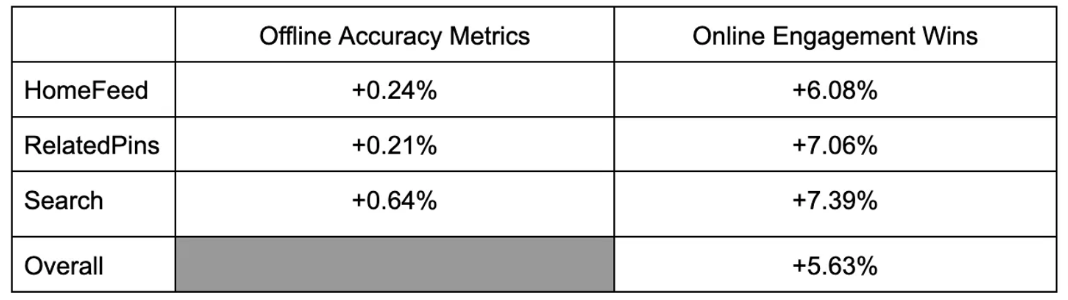
Offline 에서도 물론 성능 향상은 있었지만 Online 에서는 그 성능 향상이 상당함을 실험 결과 표를 통해 확인할 수 있습니다.
끝으로
이번 포스팅에서는 어떻게 유저의 behavior 과 feedback 을 반영할지를 feature, model architecture 관점에서 이야기했습니다. personalized 그리고 relevant 를 위해 long-term, short-term hybrid 방식으로 임베딩하였고, 그 결과 유의미한 성능 향상이 있음을 확인했습니다.
또한, 유저에게 신속한 추론 결과를 제공하기 위한 엔지니어링 관점인 mixed precision 도 알아보았습니다. 데이터 타입 그리고 모델 레이어 pairwise 관점으로 접근하여, 성능 저하가 적은 pair 를 도출하는 방식 그리고 모델 레이어 결과 값들이 상이할텐데 이를 어떤 방식으로 안정화 시킬지에 대해 고민한 결과인 reslient batch norm 에 대해서도 이야기 했습니다.
Engineering section (1) 과 (2)를 비교해보며, 고객 피처를 어떻게 구성하는지 그리고 동일하게 Transformer encoder를 사용하지만, 주입하는 Embedding feature 를 어떤식으로 설계하는지에 대해 비교해보며 오마카세 구독자 분들께서 설계할 추천시스템과 적합한 아키텍쳐를 도출하시면 굉장한 도움이 되지 않을까 싶네요.
[Contact Info]
Gmail : jeongiitae6@gmail.com
Linkedin : https://www.linkedin.com/in/ii-tae-jeong/