2월 넷째주 그래프 오마카세


Learning Superpoint Graph Cut for 3D Instance Segmentation
NIPS 2022
배지훈
keyword : Point cloud segmentation, Graph Attention learning, Edge Score Prediction Network, Superpoint Graph Cut Network.
[Content]
Introduction
- 컴퓨터 비전 분야에서, 픽셀 클러스터링 방법으로 잘 알려진 슈퍼픽셀 생성 알고리즘이 존재합니다. 다음은 이미지 상 유사도가 높은 픽셀들을 하나의 그룹으로 클러스터링하는 방법으로써, 유의미한 정보들만 모아 표현된 입력 이미지들을 통해 네트워크의 학습 효율성을 향상시키고 전체 픽셀 개수도 줄여주어 연산량 또한 효과적으로 감소시키는 이점을 가져다 줍니다. 대표적 슈퍼픽셀 알고리즘으로는 SLIC이 있습니다.
- 슈퍼픽셀 아이디어를 따라 포인트 클라우드 상에서도 유사한 포인트들을 하나의 그룹 포인트로 클러스터링하는 슈퍼포인트 (superpoint) 개념이 존재합니다. 다음 알고리즘을 처음으로 제안한 논문은 슈퍼포인트 상에 잘 구축된 그래프(Superpoint Graph)를 통하여 포인트 클라우드 분할 작업을 수행한 선행 작업으로써, 해당 오마카세와 큰 연관성을 가지고 있습니다.
- 간단하게 슈퍼포인트란, 원본 포인트 클라우드 상의 기하학적 특징정보들과 클래스 정보들을 종합적으로 고려하여 하나의 점으로 변환시킨 것을 의미하며, 슈퍼포인트 그래프는 다음 슈퍼포인트 간의 연결 관계를 포착하여 최소한의 엣지 (SuperEdge)로 구성한 그래프를 의미합니다. 슈퍼포인트는 각각의 클러스터를 구성하는 포인트들의 모든 임베딩 특징 및 의미론적 정보 모두를 포함하고 있습니다.
- 이번주 오마카세에서 소개해드릴 논문은다음 슈퍼포인트 그래프를 활용하여, 기존 3D 포인트 인스턴스 분할 문제에서의 complex한 기하학 구조정보를 포착하지 못하는 문제를 해결하고자 합니다. 본 저자들은 슈퍼포인트 그래프를 활용한 learning-based 방식으로 3D 포인트 클라우드의 로컬 기하학 구조정보(local geometric structure)를 명시적으로 학습하는 방법을 제안합니다.
- 주요 아이디어는 SSL 분야와 유사하게, 같은 인스턴스에 속하는 슈퍼포인트 노드끼리는 가깝게 끌어당기고, 다른 인스턴스에 속하는 노드끼리는 서로 밀어내도록 하여 그 엣지를 잘라내는 방향으로 네트워크를 학습하는 것입니다. 다음은 본 논문에서 제안하는 두 가지 네트워크(Edge Score Prediction Network와 SuperPoint Graph Cut Network)를 통해 수행되어집니다.
Methodology
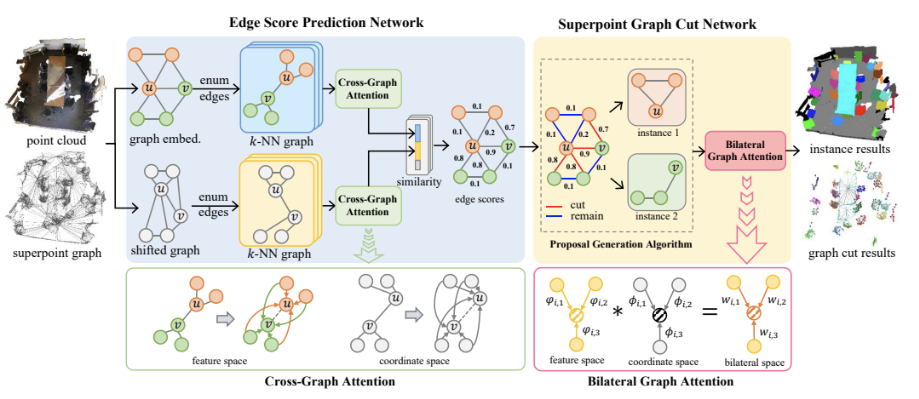
Edge Score Prediction Network
- Edge Score Prediction Network는 슈퍼포인트 그래프의 엣지 임베딩을 얻어내기 위하여 엣지 간 유사도 스코어 (Similarity-based Edge Embedding)를 학습하는 네트워크입니다. 여기서 학습되어진 엣지 유사도 임베딩은 연결된 두 노드 (위 그림에서는 노드 u, v)들이 동일한 인스턴스에 속해있는지 여부를 판단할 수 있는 중요한 정보를 담고 있습니다.
- 다음 네트워크에서 주목할 부분은 shifted graph와 Cross-Graph Attention 학습 모듈입니다.
Shifted Graph
- 저자들은 슈퍼포인트 표현이 원본 포인트 클라우드 표현보다 더욱 coarse하기 때문에 직접적인 활용은 로컬 기하학적 구조(local geometric structure) 포착의 어려움이 존재하다는 점에 초점을 둡니다.
- 다음 문제를 해결하기 위해, 저자들은 먼저 초기 슈퍼포인트 그래프의 임베딩 정보를 바탕으로 원래의 입력 포인트 위치를 이동(shift)시킵니다.
Cross-Graph Attention
- 이동된 그래프 상에서, 다른 인스턴스에 속해있는 두 노드 u,v를 포함하는 로컬 그래프 (G_u, G_v)를 KNN 알고리즘을 통해 구축한 후, Cross-Graph Attention 학습을 수행합니다. Cross-Graph Attention 학습을 통해, 두 그래프 사이의 기하학적 유사도(Geometric Similarity)를 임베딩할 수 있으며, 특징 공간 및 좌표 공간 상에서의 유사도 벡터들과 이동된 노드 u,v 사이 거리 정보를 모두 종합하여 엣지 스코어(Edge Scores)를 계산합니다.
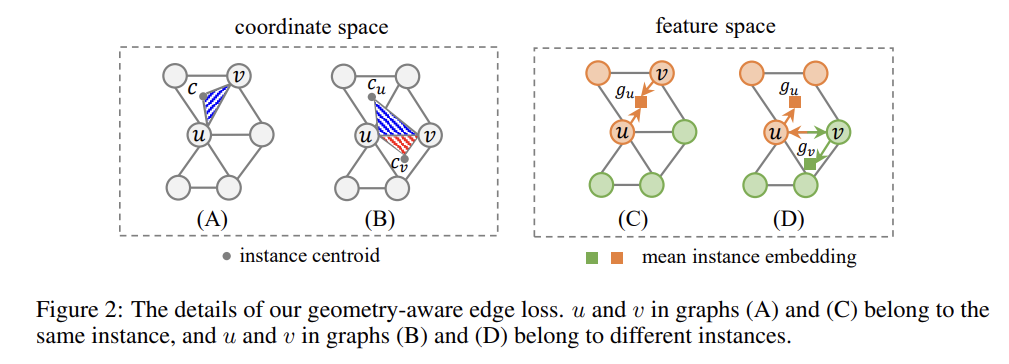
- Cross-Graph Attention 학습은 두 노드 u,v와 포함하고 있는 인스턴스의 중심 포인트 (c)에 대하여 L2 거리를 최소화하는 방향으로 진행됩니다.
- 만약 두 노드가 같은 인스턴스에 속해 있는 경우, 좌표 공간 상에서 삼각형 ucv의 영역 ((A)의 파란색 삼각형)을 최소화하고, 특징 공간 상에서 해당 인스턴스 임베딩 평균 포인트 g_u의 위치에 가까워지도록 합니다.
- 그 반대의 경우, 즉 두 노드가 다른 인스턴스에 속해있는 경우 좌표 공간 상에서는 두 삼각형 영역들((B)의 파란색, 빨간색 삼각형)을 최소화하고, 특징 공간 상에서는 각각의 임베딩 위치가 해당 인스턴스 평균 임베딩 포인트 g_u 및 g_v에 가까워지도록 하여 서로의 거리가 더 멀어질 수 있도록 합니다.
- Edge Score Prediction Network 네트워크의 전체 학습은 Geometric-aware Edge Loss (L_geo)를 통해 진행됩니다.
Superpoint Graph Cut Network
- Cross-Graph Attention 학습 이후, 출력되어진 엣지 스코어를 기반으로 슈퍼포인트 그래프 상의 다른 인스턴스 클래스에 포함된 노드들을 연결한 엣지를 잘라내야 합니다. 다음은 Superpoint Graph Cut Network을 통해 이루어집니다.
- 다음 네트워크에서 주목할 부분은 Proposal Generation 알고리즘과 Bilateral Graph Attention 학습 모듈입니다.
Proposal Generation
- Proposal Generation 알고리즘은 크게 Coarsening, Edge Cut, breadth-first-search의 세 단계로 이루어져 있습니다.
- 먼저 해당 슈퍼포인트 그래프의 의미론적 유사 스코어(Semantic Scores)를 바탕으로 coarsening을 수행합니다. 다음은 유사도가 높은 노드들을 연결하는 엣지는 남겨두고, 그렇지 않은 엣지는 사전에 제거하는 작업으로 볼 수 있습니다.
- 그 이후, 이전 단계에서 구한 엣지 스코어(Edge Scores)를 바탕으로 Coarsen 그래프의 엣지별 임계값 0.5보다 큰 스코어의 엣지를 잘라냅니다.
- 마지막으로 N개의 클래스에 대해 반복적으로 Breadth-first-search 알고리즘을 사용하여 최종 proposals 집합을 생성합니다.
- 다음 알고리즘 과정은 아래 Algorithm 1을 참고하시기 바랍니다.

Bilateral Graph Attention
- Proposal Generation 알고리즘으로 얻어낸 Proposals에 대한 판별적인(Discriminative) 임베딩을 얻어내기 위해 Bilateral Graph Attention 학습을 수행합니다. 다음은 proposal 내부의 슈퍼포인트 그래프에 대하여 특징 및 좌표 공간 상에서의 어텐션 메커니즘을 통해 각각의 인스턴스를 생성 및 최종 분할 결과로 출력해내는 과정을 담고 있습니다.
- 각각의 슈퍼포인트에 대하여, 좌표 평균값을 통한 중심 포인트 c_i와, inverse distance weighted average 계산을 통해 그 임베딩을 보간(interpolation)시킵니다.
- 그 이후, 좌표 및 특징 공간 상에서 슈퍼포인트와 해당 proposal의 중심 포인트 사이의 좌표 및 임베딩 차이를 인코딩하는 두 맵핑 함수를 통해 맵핑한 결과를 내적하여 가중치 w_ij를 얻어냅니다.
- 그리고 다음 가중치를 슈퍼포인트 임베딩과 가중합하여 최종 판별적인 proposal 임베딩을 얻어냅니다.
- Superpoint Graph Cut Network 네트워크의 전체 학습은 Instance Loss (L_ins)를 통해 지도되어집니다.
GraphCut Framework
- 저자들은 Edge Score Prediction Network와 Superpoint Graph Cut Network를 포함하는 전체 프레임워크를 GraphCut이라 칭하였습니다.
- 다음 GraphCut 프레임워크를 End-to-End 방식으로 한번에 학습하기 위한 Joint Loss (L_joint)를 정의하였으며, GraphCut 학습을 통해 최종 분할된 세부 인스턴스들의 결과를 출력합니다.
Experiment
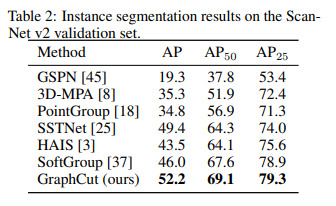
- 저자들은 실험 데이터셋으로 ScanNet V2, S3DIS를 사용하였습니다. 전체적인 실험 평가 지표로는 ScanNet V2에서는 Average Precision (AP)을, S3DIS에서는 mean coverage(mCov), mean weighted coverage(mWCov), 그리고 mean recall(mRec)을 사용하였습니다.
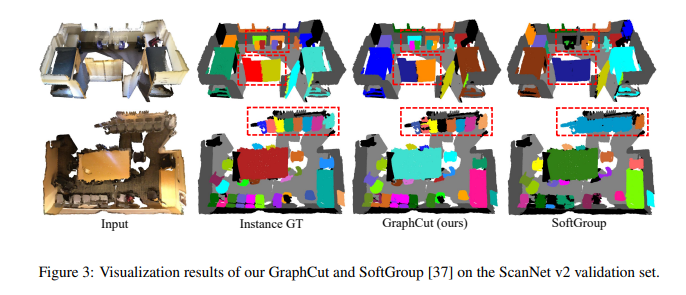
- Fig 3의 정성적 평가에서, SoftGroup의 방법은 인스턴스 내 포인트 모두를 한번에 클러스터링 하기에, 세부 정보를 무시한 채 하나의 인스턴스로 분할해버리는 반면에, 제안 방법(GraphCut)은 로컬 기하학 정보 전체를 사용하여 객체의 경계부분을 따라 분할하기에 더 나은 인스턴스를 생성해낼 수 있음을 관찰할 수 있습니다.
- 정량적 평가에서도 이러한 이유로 기존 방법론보다 더 나은 SOTA 결과를 달성하였음을 확인할 수 있습니다.
Conclusion
- 유사한 포인트 클라우드를 클러스터링하는 슈퍼포인트의 그래프 표현을 통한 인스턴스 객체 분할 작업에 활용된 사례를 소개하였습니다. 포인트 클라우드의 기하학 및 각각의 인스턴스 레이블 정보를 기반으로 그 유사도 관계를 추출 & 활용하여 그래프 어텐션 메커니즘 학습을 통해 좋은 결과를 보여주었던 점이 인상깊었습니다.
- 또한 다음 논문은 구성된 슈퍼포인트 그래프 상의 학습 방향을 SSL 방식과 유사하게 포인트 클라우드의 다른 두 공간 (좌표, 특징공간) 사이의 정보 교환을 잘 활용하여 기존 방법들보다 더 나은 결과를 달성하였으며, 이를 통해 포인트 클라우드 분야에서 그래프 표현 학습의 효과를 확인해볼 수 있었던 것 같습니다.
[Contact Info]
Twitter (X): @jhbae1184
Neural Scaling Laws on Graphs
정이태
: Data scaling , Modelscaling Collapse , Large graph deep learning teaching materials
[Content]
- 모델의 사이즈와 성능이 비례할까요? 학습데이터 사이즈와 성능이 비례할까요 ? 많이 학습할수록 성능이 향상할까요?이 세 가지 요소들과 모델 성능간의 관계를 증명하는 분야를 neural scaling laws 라고 합니다.
- neural scaling 은 자연어처리 , 이미지처리 분야에서 주로 많이 연구되어져왔고, 그 결과로써 현재 ChatGPT 과 같은 결과물이 등장하게 되었는데요. 데이터양이 많으면 많을수록 좋고 질 또한 좋으면 좋을수록 좋다. 라는 공식이 잘 적용된 사례라고 할 수 있습니다. 반면, 그래프에서도 이 법칙이 통용될까요?
- 자연어처리나 이미지처리 분야에서 활용하는 텍스트, 이미지와 다르게 그래프는 비정형 형태로 non-euclidean 공간속에서 주로 다루어지고 유연한 구조를 가지고 있기 때문에 데이터 형태 자체가 다르다고 할 수 있습니다. 다시 말해서, 데이터마다 가지고 있는 특성들 즉 모델 파라미터 또한 데이터마다 가지각색입니다.
- 예를 들어보자면, 텍스트같은 경우 문장을 단어 단어로 분절하여 그 단어들끼리 모든 연결되어 있고 그 관계들을 활용해 학습되기 때문에, 어느 단어에 많은 연결이 있고 어느 단어에 적은 연결이 있는 경우와 같이 분포가 균등치 않은 경우가 발생치 않습니다.
- 이미지또한 특정 이미지를 패치 형태로 나누어 그 이미지들끼리 관계를 학습하여 패치들마다의 관계를 기반으로 맥락을 학습하기 때문에 분포가 균등치 않은 경우를 보기 드물다고 할 수 있습니다.
- 하지만 그래프는 어떨까요? 그래프는 특정 노드에는 많은 연결이 있고 적은 연결이 있는 비균등한 분포를 띄는 경우를 자주 볼 수 있습니다. 또한, 분자구조, 단백질구조 등 x,y 2차원 공간에서 확장한 3차원 공간을 고려하는 경우도 자주 발생하기 때문에 표현할 부분이 더 까다롭고 많다 라고 할 수 있습니다.
- 정리해보면 균등한 분포를 가지고 있는 자연어 , 이미지 처리 분야에서 활용하는 텍스트 이미지와 다르게 비균등한 분포 그리고 3차원 공간을 표현해야한다는 점이 표현 방식에서 다릅니다. 결국 , neural scaling laws 를 확인하기 위해서는 비균등한 분포 그리고 3차원 공간을 추가로 고려해야한다는거죠.
- 논문 저자는 이 점을 확인해보고자 본 논문에서 ‘모델’ , ‘데이터’ 관점에서 이 법칙이 언제 어디서 어떻게 통용하고 왜 그런 현상이 발생했는지에 대해 이야기합니다.
- 먼저 어떻게 neural scaling laws 를 검증하는지 설명하는게 우선일 거 같네요. 간단합니다 .아까 말씀드린 요인 세 가지인 model parameter , training dataset , amount of computation 을 독립변수로 두고, test error 를 종속변수로 둡니다.
- 당연하게도 떠오르는 의문이 있는데요. 바로 모델 파라미터와 트레이닝 데이터셋간 그리고 오버피팅간 관계에 대한 의문입니다.
- 신기하게도 이 의문에 대한 답을 비례 반비례 관계로 도출한 논문이 있어 그 논문을 저자는 related work 에 추가해놓았습니다.
- 모델 파라미터가 데이터셋의 일정 비율 이상을 초과하게 된다면 성능에 부정적인 영향을 준다는 논문의 내용인데요. 궁금하신분들은 찾아서 한 번 보시는걸 추천드립니다.
- 모델 성능이 데이터셋 사이즈와 모델 사이즈에 따라 어떻게 변하는지 확인하기 위해 모델 사이즈를 depth , width 로 두 카테고리로 나누어 모델 depth 를 고정하고 모델 width 를 늘리고 줄이는 형식으로 실험을 진행합니다.
- 여기에서 depth 는 모델 레이어를 의미하고 width 는 모델 파라미터를 의미합니다. 예를 들어 depth 를 6 width 를 1024로 한다면 6개의 레이어에 가중치를 학습하는 뉴런들이 있고, 그 뉴런들이 1024차원의 가중치를 가지고 있어 학습된다는거죠.
- 모델 , 데이터 스케일링을 다양하게 진행하며 얻은 인사이트들을 observtation 이라는 항목으로 친절하게 정리되어있습니다.
- Observation 1. The model and data scaling behaviors in the graph domain can be described by neural scaling laws.
- => 서두에 언급한 요인 3가지와 성능을 방정식 형태로 구성한 부분 기억나실까요? 그 방정식이 유의미함을 확인하였다고 합니다. 이를 통해 graph task에선 모델과 데이터셋 사이즈가 커질수록 그 성능 또한 비례하여 개선될 수 있음을 이야기하고 잠재성에 대해 언급합니다.
- Observation 2. The model scaling collapses in the graph domain often happen due to the overfitting.
- => graph 데이터셋은 자연어와 이미지 데이터셋 대비 상대적으로 수가 적기 때문에 오버피팅이 발생할 확률이 더 높을것이라 이야기합니다. 그 이유로는 model scaling collapse 때문인데요. 간단하게 말하면, 오버스무딩 때문에 model scaling collapse 가 발생한다. 라고 생각하시면 되겠습니다. 여기에서 model scaling collapse 란 학습하는 학습데이터 사이즈 대비 모델의 사이즈가 너무 커서 모델 성능 개선에 실패하는 현상을 의미합니다.
- Observation 3. Deep graph models with varying depths will have different model scaling behaviors.
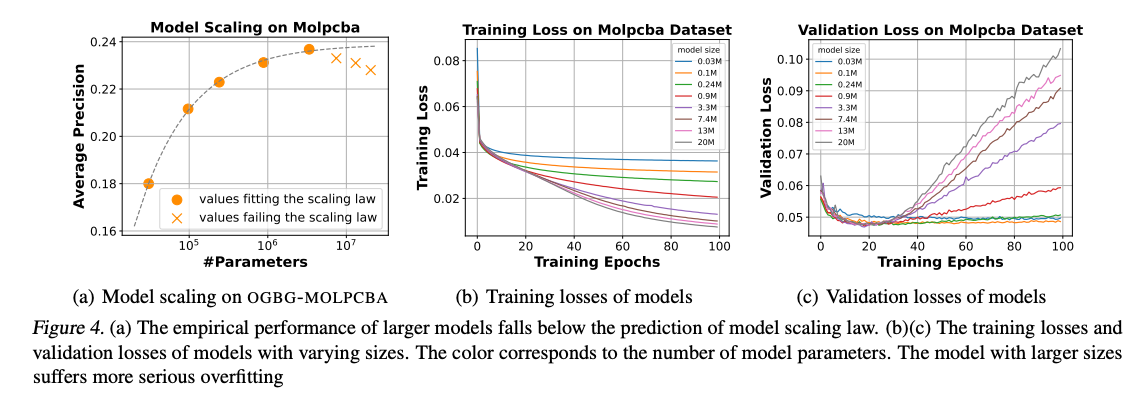
- => 딥러닝에서 통용되는 진리의 case by case 가 그래프 딥러닝에서도 적용됨을 observation3 에서 보여줍니다. 특정 상황, 특정 task , 특정 모델 등 어느 때에 어떤 모델이 무조건 좋다 라는 최적의 공식이 없기때문에, 무작정 다 실험해봅니다. 그 결과, 모델마다 제각각 model scaling 을 보이는데요. 특정 모델은 레이어가 증가하며 파라미터도 증가하고 성능 또한 개선되다가 특정 파라미터에서 감소되는 선을 보이는 반면, 어느 모델은 시작부터 레이어 상관없이 성능이 개선되는 실험 결과를 보입니다.
- Figure 4,5,6 에서 각각 training epochs, parameters, model architecture 을 바꿔가며 실험합니다. 쉽게 말하면, 많이 학습해보고 , 차원을 늘려보고 , 모델을 바꿔보고 , 모델 레이어를 더 쌓아보고 등 할 수 있는 경우의 수를 모두 실험보았고, 실험 결과를 통해 Observation 2,3를 도출했다 라고 생각하시면 되겠습니다.
- Observation 4. The number of edges is a better data metric for data scaling law compared to the number of graphs.
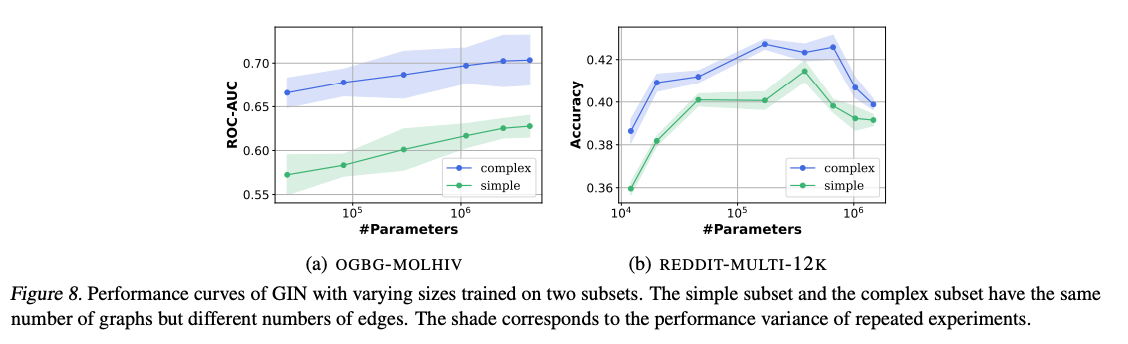
- => 그래프마다 고유의 토폴로지(노드마다 연결된 엣지 수)가 다르기 때문에, graph task 에서는 graph 기반으로 학습 데이터를 구성하면 비효율적임을 이야기합니다. 이를 개선하기 위해선, graph 내의 복잡도를 추가로 고려하여 학습 데이터를 구성해야한다고 하는데요. 이 가설을 실험한 결과가 Figure 8 , Figure 9에 담겨있습니다.
- 동일한 파라미터라 할지라도, 복잡한 구조를 가지고 있는 그래프 토폴로지가 성능이 좋음이 증명되었습니다. 이러한 결과는 그래프의 복잡성을 적절히 반영한 학습 데이터 구성이 그래프 기반 작업에서의 모델 성능 향상에 중요하다는 것을 보여줍니다.
- 따라서, 그래프 내의 복잡도를 고려하여 학습 데이터를 최적화하는 것이 그래프 태스크를 해결하는데 있어 효과적인 접근 방법임을 시사합니다. 이러한 접근 방법은 향후 그래프 데이터를 이용한 다양한 응용 분야에서 더 나은 결과를 얻기 위한 기초가 될 수 있습니다.
- Observation 5. Node classification, link prediction, and graph classification tasks could follow the same form of data scaling law with the number of edges as data metric.
- => 이전까지는 Graph task에 집중하여 진행했으나, 논문 저자들이 보너스 느낌으로 node classification 과 link prediction 에서도 복잡한 그래프 구조일수록 성능이 높다 라는 공식이 통용되는지 확인해보았는데요. 동일하게 통용된다고 합니다.
- 대용량 그래프가 있고 실험을 할 타이밍이다? 하실때 보시면 좋습니다. 저도 마냥 그래프 분포를 보고 데이터가 어떻게 생겼구나 하고 파악만 한 뒤 학습을 하는데요.
- 앞으로 이 논문을 자주 참고하며 지금 가지고 있는 데이터는 어느정도에서 오버피팅이 발생할 가능성이 크겠구나 하며 대략적인 사고실험을 할 수 있을거 같네요. 다만, graph classification task 에 많이 집중된 논문인 만큼 다른 task 인 node classification , link prediction 에서는 생각해 볼 여지가 많을거 같네요.
[Contact Info]
Gmail : jeongiitae6@gmail.com