1월 3주차 그래프 오마카세


Graph interview
1번째 그래프 인터뷰, 이진호 교수님.
Graph interview 소개
- 국내ㆍ외 그래프 석학분들과 현업분들의 귀중한 인사이트를 공유하자는 취지로 기획하게 된 프로젝트입니다.
- 이번 인터뷰 대상자는 서울대 이진호 교수님입니다.[bio]
- 날짜는 2월 초중순 정도로 예상합니다.
- 채널은 유튜브를 통해 실시간 중계할 예정입니다.녹화본 공유 예정이나, 편집으로 몇몇 부분이 생략될 수 있습니다.
- 이런분들이 함께 하시면 더더욱 좋을거 같아요.
- 1. GPU 가속이 어떤식으로 Graph Neural Network 에 적용되는지.
- 2. 컴퓨터 구조와 머신러닝이 어떤식으로 상호유기적 관계를 띄는지.


A graph clustering algorithm for detection and genotyping of structural variants from long reads
[Link]
keywords : graph clustering, structural variant, DBSCAN
- 구조적 변이; Structural variant (SV) ?진핵 생물은 세포 분열과 자손 번식 등 가장 기본적인 생명 과정을 수행하며, DNA 재조합, 복제 및 복구와 관련된 과정은 유전 정보를 보존하는데 핵심적인 역할을 합니다. 이 과정에서 유전자 돌연변이가 발생할 수 있습니다.
- 그리고 구조적 변이는 그 중 하나입니다.SV는 유전체 다양성을 제공하고, 이는 유전자 발현, 표현형 변이 및 질병 감수성 변화를 초래하는 기능적 변이로 이어집니다.
💡 Take-home messages
필자 생각: 변이에 대해서 그래프와 연관지으면서 나중에 더 깊게 다루겠습니다.
- 구조적 변이 길이 또한 리드 길이를 종종 초과하기 때문에 현재의 도구로 변이을 알아내고 해석하기엔 역부적입니다.
- Long-read SV caller가 존재하지만, 이 또한 제한적입니다.
- 이러한 도구는 read alignment algorithm의 정확도에 의존하며, ambiguous alignment에는 성능이 떨어지기 때문에 전반적인 정확도에 방해가 됩니다.
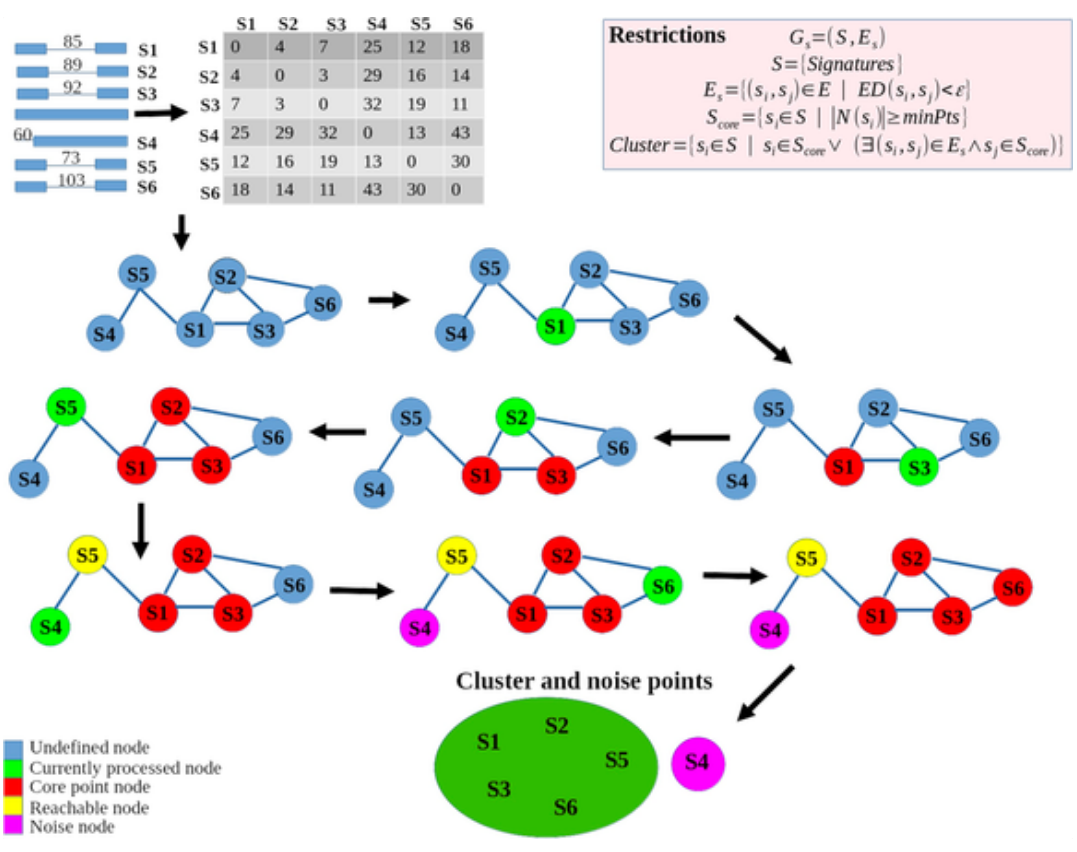
- 따라서 저자들은 (1) interalignment (2) intraalignment 사례들로 분류된 SV 신호용 데이터를 고안했습니다. 이러한 데이터 표현을 통해 거리 행렬을 쉽게 만들 수 있었고, 이 행렬은 그래프를 만드는 데 활용되었습니다.
- 저자들은 베이지안 확률에 기반한 유전자형 구조적 변이를 최종적으로 식별할 수 있도록 SV 신호용 데이터를 그룹화하기 위해 DBSCAN 클러스터링 알고리즘을 사용했습니다.
- Genotype Call: 'Heterozygosity' or 'Homozygosity'
- Alignment 후에 나오는 CIGAR status string는 read # (read depth) 만큼 데이터가 생성되고, long read sequencer specification에 한해서 길이가 결정된다.
- 모델링 할 때 제일 큰 문제가 데이터가 없는 것인데, 이 부분은 outliers 와 noises 에 강건한 DBSCAN clustering method로 일종의 일정하게 나타나는 common features들을 뽑을 수 있어 performance가 reliable하게 나올 수 있다고 생각된다
- 주어진 데이터들을 연결시키는 similarity matrix에 기반한 계산법이다
- 데이터 크기와 다양성에 의존적일것 같다
- 정렬 (alignment) 과 탐지 (detection) 프로세스 모두 알고리즘에 크게 의존한다는 점에 유의해야 합니다. genomic event에 대한 실험적 검증은 여전히 어려운 과제로 남아있습니다.
[Contact Info]
Gmail : kjwk1221@gmail.com
LinkedIn : https://www.linkedin.com/in/jiwonkimbrian/
Beyond Low-frequency Information in Graph Convolutional Networks’ (AAAI 2021)
link : https://arxiv.org/abs/2101.00797
code : https://github.com/bdy9527/FAGCN
Keyword : Node Classification, Low & High Frequecy Graph Signal, Adaptively Aggregation.
- 대다수의 노드 분류문제에서 반지도학습을 기반으로 좋은 성능을 보여주고 있는 그래프 컨볼루션 신경망(GCNs)의 학습 메커니즘은 입력 그래프의 타겟 노드를 중심으로, 그 이웃노드들의 정보를 집계하여 업데이트하는 방식으로 진행됩니다.
‘왜 이러한 학습 메커니즘이 동작을 잘 하는 것일까?’
라는 근본적인 질문을 기반으로 수많은 연구들에서 그 이유를 분석하였고, 그래프 스펙트럼 관점에서 얻어낸 공통적인 결론은 ‘다음 메커니즘은 입력 데이터의 저주파수 성분 (유사한 색상, 형태 등의 패턴을 포함하는 특징정보) 를 학습하도록 저통과 필터 (Low-pass filter)로 동작한다’ 라는 것이었습니다. 다음 저주파수 요소의 주요 성분은 노드 신호의 부드러움(Smoothness), 즉 노드 간 유사도(Similarity)에 있습니다.
(관련 논문 : ’Revisiting Graph Neural Networks: All We Have is Low-Pass Filters (ICPR 2020) , ‘Analysing The Expressive Power of Graph Neural Networks In A Spectral Perspective’ (ICLR 2021) )
- 본 논문 저자들은 이러한 사실을 바탕으로, 한가지 추가 질문을 던집니다.
저주파수 성분만이 학습에 필요한 정보인 것일까? 고주파수 요소들은 GNNs 상에서 어떠한 역할을 맡고 있는가?
- 실제로, 단백질 구조와 같은 Real World 데이터에서, 이들의 화학적 상호작용 효과를 조사하는 경우 ‘다른 종류의 아미노산 간의 상관관계’ 라는 노드의 고주파수 성분이 훨씬 더 유용하다는 사실과, 널리 알려져있는 GNNs의 고질적인 문제인 Over-Smoothing의 원인이 저주파수 성분만 고려한 결과라는 사실이 존재합니다. 즉, 한쪽으로 편향된 노드 신호의 학습은 다양한 그래프 네트워크 상에 최적의 솔루션을 제공하지 못한다는 것으로 이해할 수 있겠습니다.
- 그들은 좀 더 깊게 이러한 질문의 해답을 찾기 위해, 동일한 학습 메커니즘 (메세지 전달 프로세스) 상에서 입력 그래프 노드가 가지고 있는 저주파수 및 고주파수 요소들의 역할을 조사합니다.
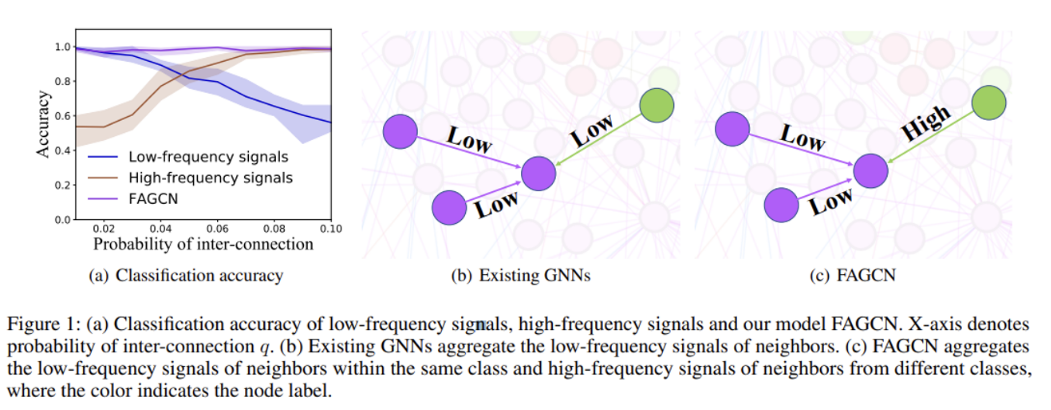
- 다음 논문에서, 저자들은 그래프 상 타겟 노드 혹은 그 이웃노드들로부터 전파되어지는 정보들의 다른 신호들을 적응적으로 집계할 수 있는 FAGCN (Frequency Adaptation Graph Convolutional Networks)를 제안합니다.
- 입력 노드 신호로부터 ‘향상된, Enhanced’ 저통과 (Low-pass) 및 고통과 필터(High-pass)를 설계하여 각각의 성분을 추출한 후, Self-Gating 메커니즘을 활용하여 다음 성분들을 통합합니다. 따라서 Fig 1(c)과 같이, 기존 GNNs의 저주파수 성분만 받는 것을 넘어서(’Beyond Low-frequency Information’), 고주파수 성분까지도 같이 집계함으로써 더욱 효과적인 노드 업데이트 계산을 수행할 수 있게 됩니다.
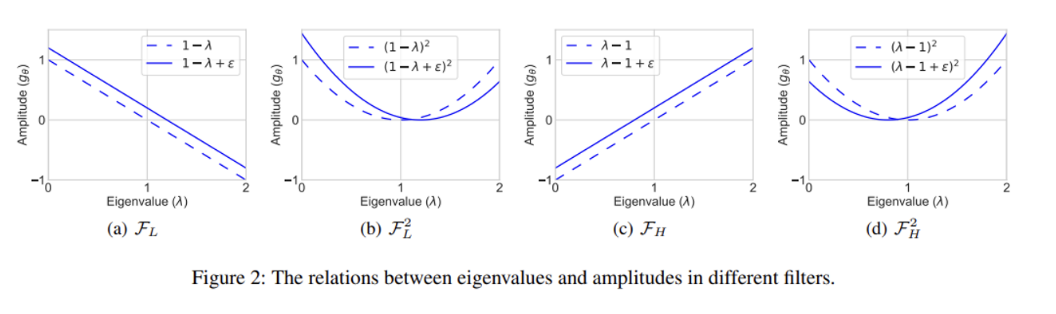
- Fig 2는 저자들이 설계한 ‘향상된’ 저주파수 및 고주파수 필터 (실선)와 기준 모델로 선택한 GCN 필터 (점선)의 비교를 나타냅니다. 여기에서 저자들은 각 주파수 요소를 더욱 잘 포착하기 위해 sigma 파라미터를 추가하였으며, 음의 크기를 방지하기 위해 제곱 꼴의 형태로 필터를 설계하였다고 합니다.
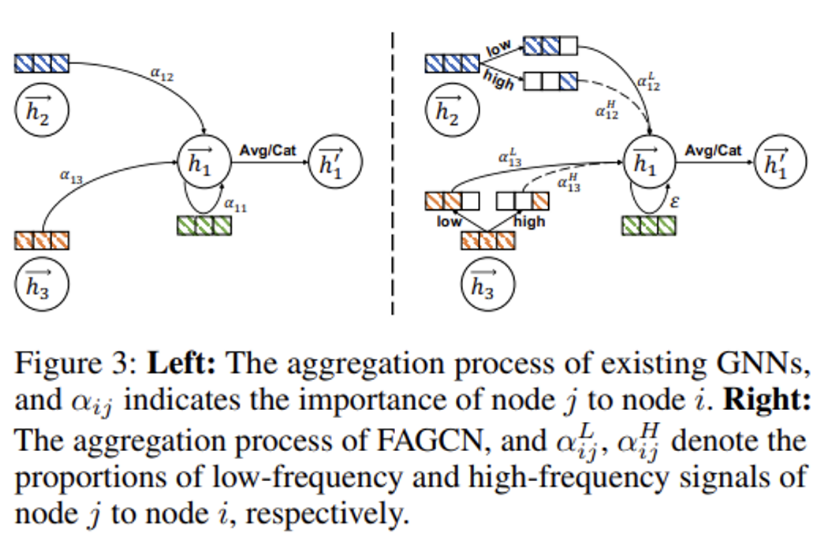
- Fig 3은 기준 모델 GAT와 제안하는 FAGCN의 학습 메커니즘 혹은 메세지 집계 과정을 보여주고 있으며, 주목할 점은 이웃 노드들의 원본 신호를 필터링하여 분리한 각각의 주파수 성분에 가중치 alpha를 다르게 부여하여 그 중요도를 학습하도록 설정한 것입니다. 다음의 핵심 포인트 부분은 논문의 Remark 3에 기술되어 있습니다.
- 해당 논문에서, FAGCN이 대부분의 기존 GNNs (GCN, GAT)의 일반화 형태 꼴로 표현가능하며, 이론적으로 FAGCN의 향상된 표현력을 설명합니다. 또한 Table 2에서 그래프 벤치마크 데이터셋 상에서 진행한 실험 결과를 기반으로, Over-smoothing 문제를 완화할 수 있음을 저자들은 언급합니다.
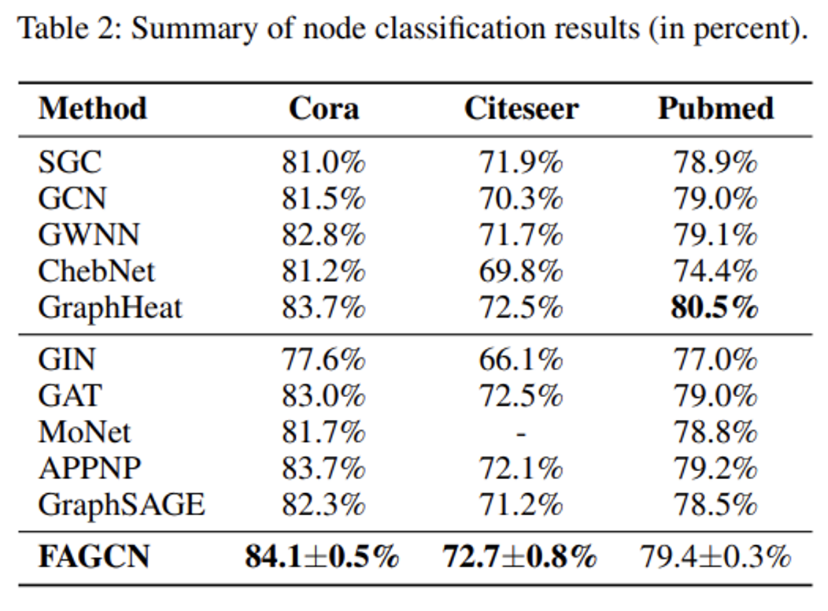
- 결론적으로, 해당 논문은 기존 대다수의 GNNs 모델들이 입력 데이터들의 저주파수 성분 혹은 신호의 부드러움(Smoothness)만을 학습에 사용하는 한계점을 넘어서, 적응적으로 고주파수 성분까지도 집계할 수 있는 FAGCN을 제안하며 더욱 복잡하고 포괄적인 Real World 데이터의 적용 가능성을 보여주었습니다.
- 글 작성자도 궁금했던 근본적인 질문에 대한 해답을 이론적으로, 실험적으로 잘 제공해주었으며, 기존 GNNs을 실험 파라미터 수정을 통해 쉽게 일반화시킬 수 있다는 점이 상당히 흥미로웠습니다.
- 기존 GNNs의 Over-smoothing 문제 및 제한된 task에서의 성공 한계점을 보여주고, 스펙트럼 관점에서 그래프 상 노드의 모든 주파수 성분을 활용하였을 때의 향상된 성능 결과를 통해 차후 관련 모델 설계 및 데이터 분석 활용에 긍정적인 방향을 보여주었다고 생각합니다.
- 하지만, Real world 데이터 상에서 괄목할만한 성능을 보여준 것은 아니었으며, 그에 대한 분석이 부재하였다는 점. 그리고 명시적인 방법 없이 실험적으로 Over-smoothing 문제를 완화하였다는 설명이 살짝 아쉬웠습니다.
[Contact info]
Gmail : jhbae7052@gmail.com
LinkedIn : https://www.linkedin.com/in/jihun-bae-757302289/
Twitter : @jhbae1184
Label Information Enhanced Fraud Detection against Low Homophily in Graphs
code link
[https://github.com/Orion-wyc/GAGA/blob/master/pytorch_gaga/data/grouping.py]
paper link
[https://arxiv.org/pdf/2302.10407.pdf]
[keyword]
homophily labelpropagation groupaggregation anomalydetection
[Content]
- 이상 탐지 분야에서 논의되는 여러 문제 중 하나는 '불균형 데이터'입니다. 이 불균형을 준지도 학습 관점으로 접근하여 라벨이 되어 있지 않은 부분을 연결로써 고려하여 추론할 수 있다는 점에서 그래프 딥러닝이 각광을 받고 있습니다. 하지만, 여기에서 한 걸음 더 나아가면 그래프도 마찬가지로 라벨이 되어 있지 않은 노드를 어떻게 다뤄야 할지에 대한 문제에 직면하게 됩니다. 네트워크 관점으로 표현하면 'isolated node'라고도 합니다. 본 논문은 이러한 문제를 'homophily'라는 지표를 활용하여 측정하고, 어떻게 하면 라벨이 되어 있지 않은 노드와 기존에 라벨이 지정된 노드들로부터 이상치 정보를 효과적으로 추출할 수 있는지에 대해 이야기합니다.
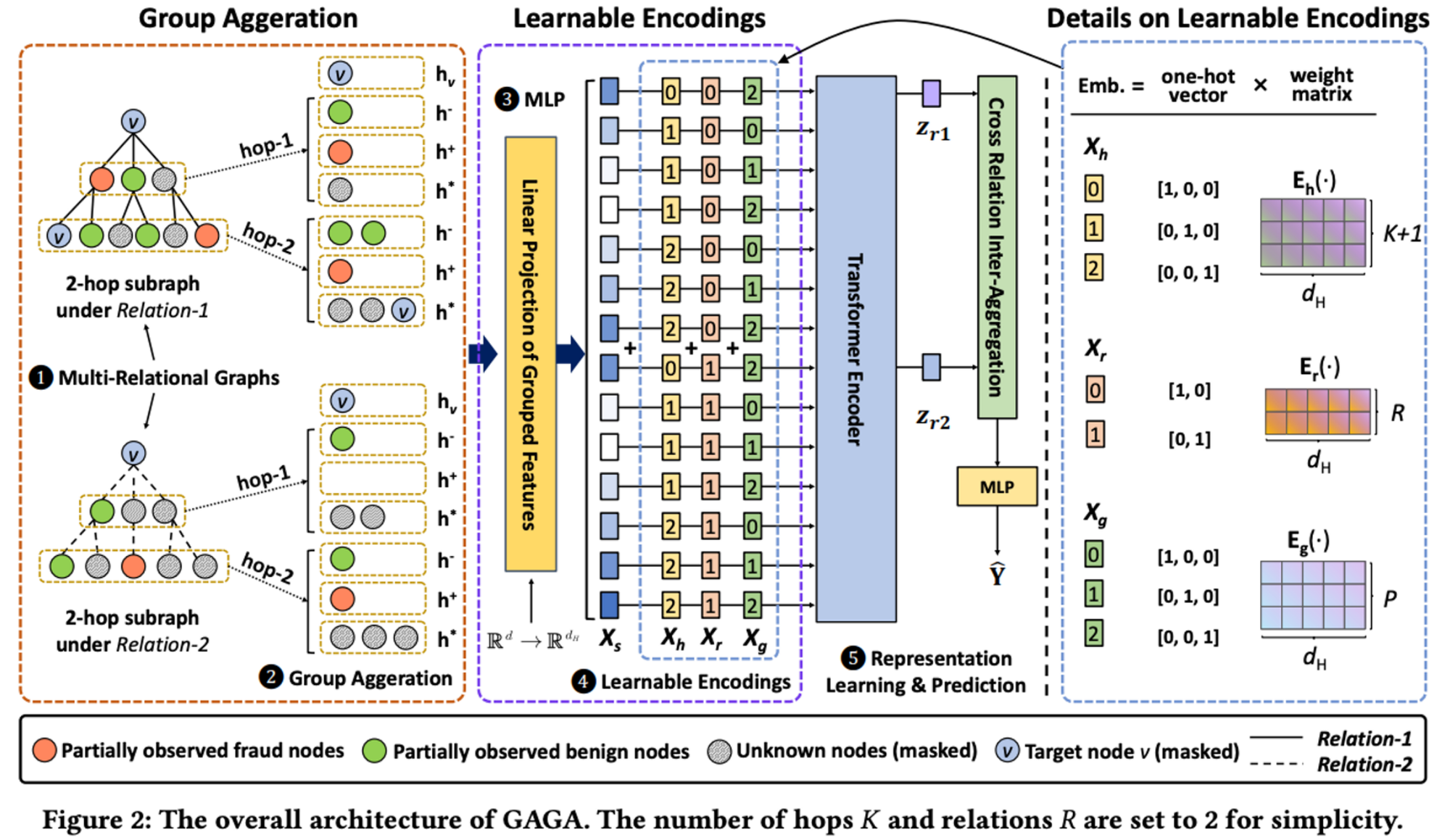
- 핵심 방법을 한 줄로 요약해보자면, '연결 다양성', '연결 깊이', '그룹 연결 집계' 정보를 임베딩에 담았고, 그 임베딩을 인풋으로 활용한 트랜스포머 아키텍처를 이상치 탐지에 활용했다고 할 수 있겠네요. 앞서 언급한 문제인 불균형 데이터를 완화하기 위해 이러한 인코딩 및 그룹 집계를 시도합니다. 연결이 다소 부족한 노드들을 그룹으로 묶어 정보를 공유한 뒤, 활용한다는 것입니다.
- 이렇게 인코딩이 다양해진다면, 모델 인풋으로 들어가는 인코딩 특성을 구분하기 위한 구분 식별자가 필요합니다. 더불어 라벨링 정보도 반영될 수 있기 때문에 label leakage도 고려해야 합니다. 그를 위해 one-hot 벡터 방식을 활용하고, label이 담긴 타겟 노드는 마스킹을 통해 그 정보가 반영되지 않게 처리해줍니다. 이후, 완성된 피처를 Linear layer에서 가중치를 붙여주고, transformer에서 각 임베딩마다 내적곱을 통해 추가 반영된 연관성 정보 임베딩을 마지막 추론 레이어에 적용하여 학습합니다.
- 실험 결과 재미있는 부분은 multi-relationship, hop, group에 따라 달라지는 attention score입니다. Attention score는 각 데이터들이 encoding된 결과가 어떻게 transformer 아키텍처에서 작용하는지로 볼 수 있는 중요한 힌트이기에, 성능 측면으로 해석할 때 많은 함의를 제공합니다. 연결 관계가 다양할수록 좋을까? 불균형 정보를 어떻게 나눠 반영하면 좋을까? 메시지 패싱 작동 시 연결을 얼마나 깊게 설정하면 좋을까?에 대한 고민이 있으신 분들에게 좋은 인사이트를 볼 수 있는 섹션이니, 한 번 확인해보시는 것을 추천드립니다. 5.8 Visualization 부분에서 확인할 수 있습니다.
- 포인트로 보시면 좋을 부분은 '라벨링' 정보를 어떻게 활용할 것인가와 그에 따른 모델들 'LPA', 'C&S', 'BoT'은 각각 어떤 알고리즘으로 작동되며, 왜 결과가 다르지? 세 가지로 생각합니다. 이상 탐지 분야에서 유독 중요한 부분인 라벨링 활용, 정보 활용, 연결 활용 그리고 실제 프로덕션에서도 활용할 수 있을 여지가 있는 알고리즘 이기 때문인데요. 알고리즘을 신속하며 편리하게 활용할 수 있다는 장점과 더불어 노드 분류 측면에서 성능 향상에 많은 기여를 할 수 있기 때문입니다.
- 요즘 그래프 엔지니어링 그리고 실제 활용할 수 있는 모델에 많은 관심을 가지고 있는 덕분에 아쉬운 부분도 약간 보인 아이디어네요. 과연 모든 피처를 내적 곱해야 하는 트랜스포머가 만능일까? 그리고 원핫 인코딩 방식을 활용하게 되면 자연스레 피처에 따라 인코딩 정보를 반영하기 위한 컬럼 갯수가 선형적으로 증가하게 될텐데, 이에 대한 연산을 어떻게 처리할까라는 부분이 아쉽긴 했네요.
[contanct info]
Email - jeongiitae6@gmail.com,
Linkedin - https://www.linkedin.com/in/ii-tae-jeong/
blog - https://inblog.ai/graphwoody