24년 10월 2주차 그래프 오마카세
배지훈
CliquePH: Higher-Order Information for Graph Neural Networks through Persistent Homology on Clique Graphs
paper link : https://www.arxiv.org/abs/2409.08217
Index
- What is clique graph ?
- Methodology : Graph Lifting
- Methodology : Learnable Persistent Homolgy
- Methodology : Information Combination
- 안녕하세요 오마카세 독자 여러분들. 어느덧 제가 그래프 오마카세를 여러분들께 발행해드린지 어느덧 9개월의 시간이 흘렀습니다. 올해 1월부터 GUG 커뮤니티에 들어와서 오마카세라는 컨텐츠를 맡아, 누락없이 최소 꾸준하게 발행해보자는 것으로 계획하고 실천해나가던 것이 어느덧 제 삶의 일부가 되어버린 것 같습니다.
- 그래프를 사랑하시는 여러분들께 아카데믹 혹은 인더스트리 쪽에서 최대한 인사이트를 드릴 수 있는, 혹은 주무시기 전에 가볍게 읽어보실 수 있게끔 한 편씩의 논문을 리뷰하는 다음 컨텐츠의 주 목적성을 잃지 않기 위해 노력해오셨던 이태님 덕분에 그 숟가락을 얹었던 선택이 어느덧 100번째 오마카세 발행이라는 놀라운 결과로 이어져서 기뻤습니다.
- 두서가 많이 길어졌는데, 지속적으로 관심을 가져주심에 감사드립니다 ! 앞으로 더욱 성장할 GUG 많이 기대해주세요. 그리고 아카데미, 인더스트리 쪽에서 여러분들께서 가지고 계신 귀중한 그래프 지식을 GUG를 통해 같이 공유하고 나누고 싶으시다면 부담없이 저 또는 graphusergroup@gmail.com 로 연락을 주시면 정말 감사드리겠습니다.
- 이번 주 오마카세로 여러분들께 전달해드릴 것은 Clique graph에 지속성 호몰로지 (Persistence homology) 개념을 적용한 재밌는 아이디어입니다. Clique graph 역시 여러가지 도메인에서 널리 사용되어지고 있는 그래프 구조 중 하나인데요, 다음 그래프 구조를 활용하여 기존 지속성 호몰로지 적용 방법들의 확장성 (Scalability) 문제를 해결하는 방법을 제안하는 다음 논문을 소개해드릴 수 있도록 하겠습니다.
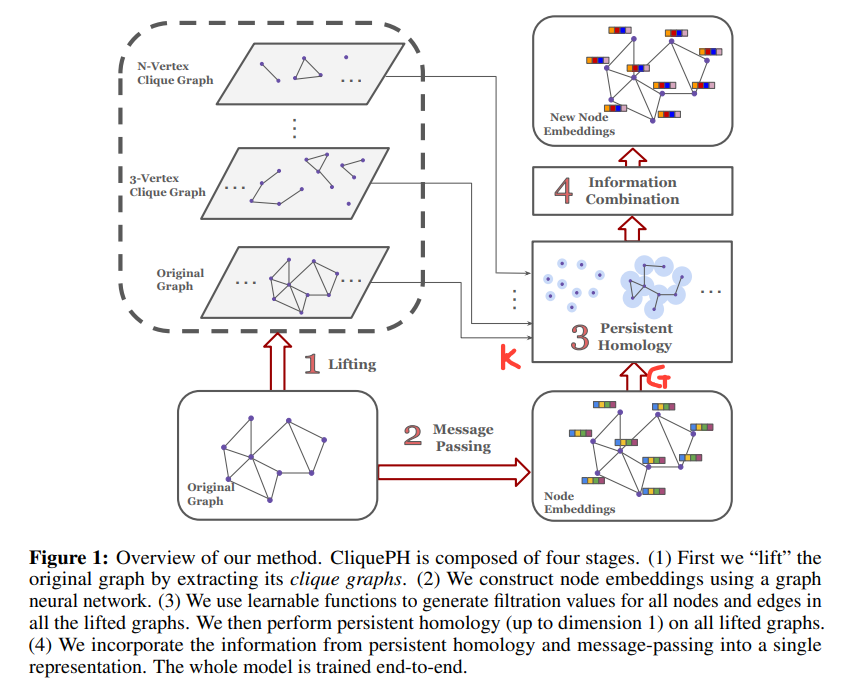
What is clique graph?
- 다음 논문에서 타겟으로 잡은 Clique graph란 무엇일까요? 본 논문에서도 개념을 가볍게 설명해주고 있는데, 먼저 위키피디아의 설명을 살펴보면 무향 그래프에 대하여 인접하게 연결되어 있는 노드의 하위집합으로 나와있습니다. 다음 Clique (혹은 위의 조건을 만족하는 노드 하위집합)들을 모아 만든 그래프를 Clique graph라고 부르며, 다음 그래프는 완전 그래프 구조를 형성합니다.
💡
A clique, C, in an undirected graph G = (V, E) is a subset of the vertices, C ⊆ V, such that every two distinct vertices are adjacent. This is equivalent to the condition that the induced subgraph of G induced by C is a complete graph. In some cases, the term clique may also refer to the subgraph directly.
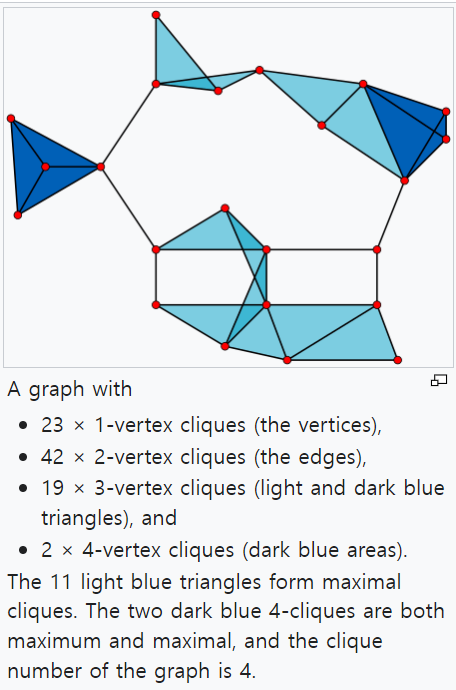
- 위의 예시 그림을 살펴보시면, 꽤 Simplicial complex 구조와 유사한 Clique graph 구조를 확인해볼 수 있습니다. 다른 점은 두 그래프를 형성하는 조건이며, Simplicial complex는 반드시 포함(incidence) 조건을 만족해야 했습니다. (그로부터 face / co-face 개념이 존재하게 되었죠)
- 본 논문에서 Clique graph는 원본 그래프 G 상의 Clique로부터 표현되는 구조 정보를 잘 요약하고 있음을 설명해주고 있습니다.
💡
In other words, the r-vertex clique graph K(r) (G) summarizes the structure of the r-vertex cliques in the graph G.
- 어찌보면, 그래프 G를 구성하는 Clique들에 대하여 몇 개의 노드(r-vertex clique)를 선택하느냐에 따라 표현할 수 있는 하위 그래프 구조정보들이 정말 다양할 것 같습니다. Fig 1의 좌측 상단 예시와 같이 말이죠.
- 표현할 수 있는 모든 그래프 구조들 혹은 N-vertex Clique graph들을 지속성 호몰로지 개념에 적용하여 Higher-order information을 뽑아내고, 다음 임베딩 정보들의 피쳐들 중 오랜 지속성을 갖는 피쳐들 (혹은 중요하다고 고려할 수 있는 정보)만을 선정하여 기존 메세지 전달 메커니즘을 통해 업데이트된 노드 임베딩에 병합합니다. 이것이 해당 논문에서 제안하는 방법이 되며, 그로부터 논문 제목 의미를 단번에 이해해볼 수 있겠습니다.
Methodology : Graph Lifting
- 구체적으로 어떠한 방식으로 Clique graph의 higher-order info와 기존 pairwise embedding을 합칠 수 있을까요? 가장 먼저 가질 수 있는 질문으로는 두 차원의 차이를 어떻게 해결할 수 있느냐가 될 수 있을 것 같습니다.
- 저자들은 다음 방법을 Graph Lifting이라는 방법을 통해 해결하고자 하였습니다. 한마디로 잘 정의된 맵핑 함수를 사용하여 저차원 임베딩으로부터 고차원 임베딩 공간으로 맵핑하는 과정을 달리 표현한 것으로 생각하시면 되겠습니다. (개념 : 'Topological Deep Learning: Going Beyond Graph Data' 75 page - Lifting maps 참조)
💡
Lifting refers to the process of mapping a featured domain to another featured domain via a well-defined procedure
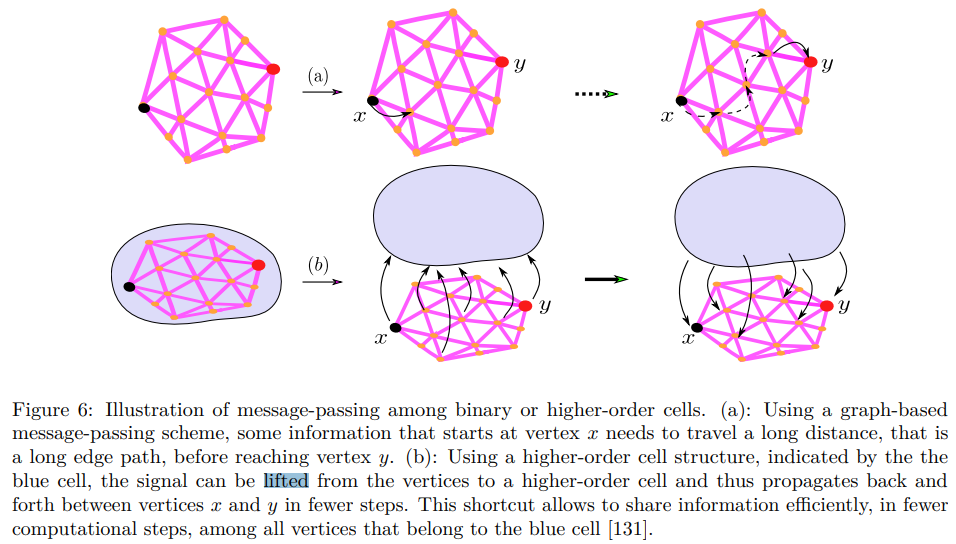
- 위 논문에서는 일반 그래프를 고차원의 Complex 공간으로 맵핑하는 방법을 보여주고 있으나, 다음 저자들은 Clique graph를 추출하는 데 다음 맵핑 방법을 활용하였습니다. 최적의 Clique 값 (r)은 주어진 데이터셋에 따라 다르게 설정될 수 있으며 저자들은 빠른 동작 시간을 고려하여 r=5를 주었다고 합니다.
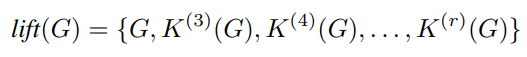
Methodology : Learnable Persistent Homolgy
1 - Filtration values for nodes and edges
- Lifting 방법으로 찾아낸 Clique graph와 원본 그래프를 포함하는 Lift(G)에 대하여 유의미한 토폴로지 특징을 추출하기 위해 필트레이션 (Filtration) 방법을 활용합니다.
- 필트레이션 개념을 리마인드해보면, 주어진 그래프의 노드 혹은 포인트에 대하여 점점 일정 크기의 반지름 원을 키워나가면서, 할당된 임계값에서의 각 포인트 간의 연결성을 포착하여 0-homology (connected components), 1-homology (loops), 2-homology(void) 등의 토폴로지 특징들의 지속성을 뽑아내는 방법입니다. 토폴로지 데이터 분석 (TDA)에서 핵심적인 도구로 많이 활용됩니다.
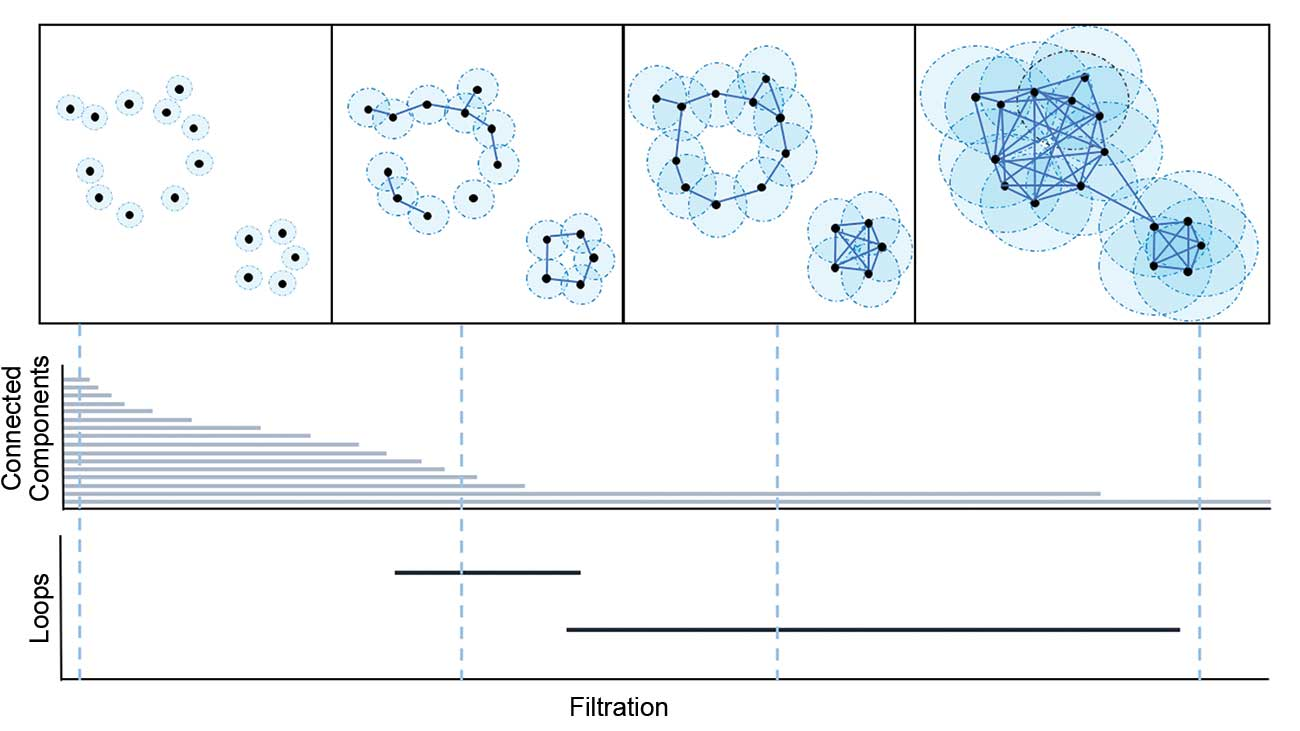
- 여기에서 저자들은 Lift(G)의 모든 그래프들에 대한 필트레이션 값을 학습하여 최적의 결과를 활용하는, 학습 가능한 지속성 호몰로지 방법을 생각합니다. 원본 그래프 G와 Clique graph K(G)의 각 노드 및 엣지에 대하여 개별 2-layer MLP를 활용합니다.
- 원본 그래프 G의 방법을 살펴보자면, 메세지 전달 메커니즘으로 얻어낸 pairwise node embedding 행렬 (H)을 MLP (f_0)에 통과시켜 노드 별 최적 필트레이션 값 (F_0(v))을 학습합니다. 엣지의 경우 연결된 두 노드의 임베딩 ( H(u), H(v) )을 concat하고, 다른 MLP (f_1)에 통과시켜 필트레이션 값을 학습시킵니다. 그 이후 아래와 같이 연결된 두 노드 중 큰 필트레이션 값과 엣지 필트레이션 값을 합하여 최종 결과로 뽑아냅니다.
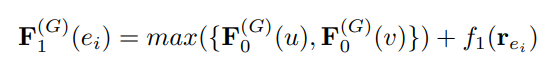
- Clique graph의 경우, 해당 그래프를 구성하는 노드 및 엣지에 대하여 동일한 방식으로 학습하여 결과를 뽑아냅니다. 다음 과정은 생략하겠습니다.
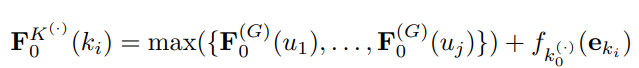
2 - Persistent homology
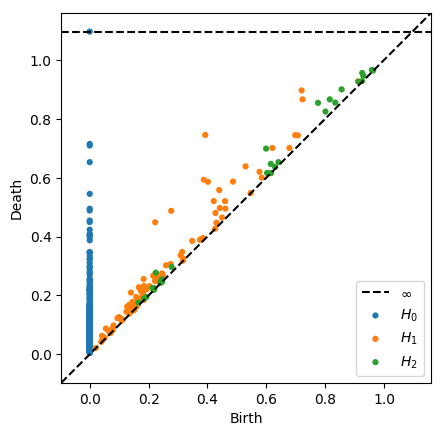
- 위에서 뽑아낸 필트레이션 값을 활용하여 지속성 호몰로지를 계산함으로써 지속성 다이어그램 (Persistence diagram)을 뽑아냅니다.
- 지속성 다이어그램은 각 토폴로지 특징 (connected component, loops ...)의 지속성을 2D 좌표 점(birth, death) 형식으로 나타낸 것을 의미합니다.
3 - Embed persistence diagrams
- 지속성 다이어그램의 정보들을 임베딩하기 위해, 널리 사용되고 있는 Deepset network를 활용하여 원본 그래프 G 및 Clique graph K의 각 노드, 엣지에 대한 임베딩 벡터들을 뽑아냅니다.
Methodology : Information Combination

- 노드 임베딩 벡터 (H)와 임베딩 호몰로지 (E_G & E_K)들을 가지고, SCATTER 함수를 통해 엣지 임베딩을 노드 임베딩에 더한 뒤, 노드 간의 embedding summation의 방식으로 구현됩니다. 이로부터 pairwise embedding + higher-order embedding의 결과를 얻어낼 수 있습니다.
- 구체적으로, 엣지에 연결된 각각의 cliques에 대하여 (e.g. E_K : k = (u, v, z) for 3-vertex clique) 아래와 같이 더하여집니다.
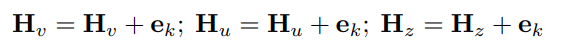
- Graph-level task의 경우, 다음의 summation 이후에 pooling method를 추가하여 최종 결과 임베딩 벡터를 뽑아냅니다.
- 이 모든 과정을 임의의 GNN 모델에 추가하고 엔드투엔드로 학습시킬 수 있는 CliquePH 이름의 토폴로지 레이어를 제안하였습니다. 이론적으로, 실험적으로 다양한 GNN (e.g. GCN, GIN, GAT) 모델에 대하여 단일 모델 & 기존 토폴로지 레이어 (e.g. TOGL)를 추가한 것보다 제안 레이어를 추가하였을 때 일관된 성능 향상의 효과를 보임을 입증하였습니다.
- 또한 기존의 다른 지속성 호몰로지 방식을 사용하여 모델을 학습시켰을 때에 비해 큰 폭으로 연산 효율성을 향상시킬 수 있음도 확인해볼 수 있습니다. 거대한 그래프의 경우 모든 그래프를 고려하지 않고, Clique graph라는 subgraph structure에 적용되는 알고리즘의 효과로 생각해볼 수 있겠습니다.

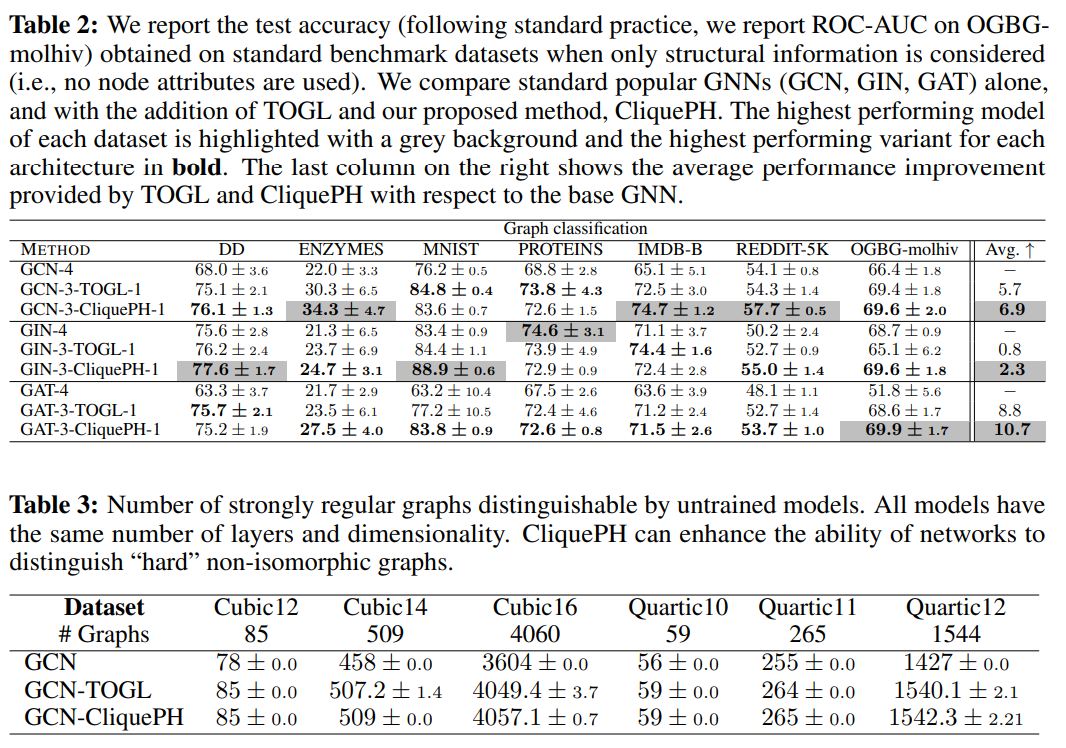
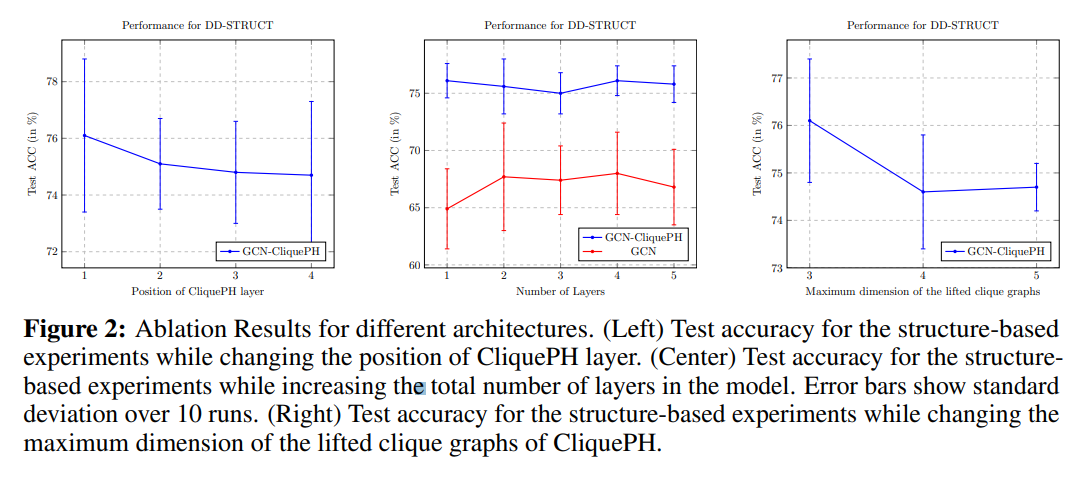
- 추가 성능 실험으로 CliquePH 레이어의 추가 위치를 바꾸어 성능 차이를 비교하였습니다. 자세한 설명은 해당 논문의 실험 파트를 참고해주시기 바랍니다.
- 메세지 전달 메커니즘의 pairwise information을 확장하기 위해 등장한 지속성 호몰로지 기반의 higher-order information 활용 아이디어에 문제점 (e.g. computational & scalability for large graph)을 완화하기 위해 Clique graph라는 하위 그래프 개념으로 바꾸어 접근하였고, 두 정보를 광범위하게 사용할 수 있게 임의의 기존 GNNs 모델에 쉽게 추가 가능한 토폴로지 레이어, CliquePH을 소개하였습니다.
- CliquePH 이름의 제안 레이어는 위의 이점들을 모두 활용할 수 있기 때문에 다양한 graph-level tasks에서 좋은 결과를 보였고, 이로부터 그래프로 표현되는 추가적인 토폴로지 정보의 추가가 중요한 성능 향상의 포인트가 될 수 있다는 인사이트를 얻어갈 수 있을 것 같습니다.
- 저자들이 말하길, CliquePH 역시 몇가지 제한점이 존재함을 밝혔습니다. 거대 그래프가 입력일 경우, 최소 크기의 Clique로 제한시키는 것이 빠른 연산을 위해 3 이상으로 설정할 수 없다는 점 - 결국 근본적인 문제 원인을 해결하는 것은 아님 - , 그로부터 연산 복잡도의 감쇠 효과가 모든 데이터셋에 대하여 항상 보장되는 것은 아니기 때문에, 결국 Clique 크기를 얼마나 잘 선택하느냐가 제안 아이디어의 효과를 볼 수 있는 데 중요한 요소가 될 것 같습니다. 이론적으로 안정된 결과라기 보다는, 실험적으로 증명된 아이디어 효능이 더욱 크다고 생각합니다.
- 하지만, 기존 그래프 문제의 해결 방법들에 추가적인 고차원 토폴로지 그래프 표현 정보를 활용하는 것의 가치와, 그로부터 활용 방법에 대한 다양한 논문들이 제안되고 있다는 사실을 그 외의 다른 문제들 해결에도 넓게 고려해볼 수 있지 않을까도 생각해봅니다.
[Contact Info]
Gmail : jhbae1184@akane.waseda.jp
Twitter (X): @jhbae1184