24년 10월 3주차 그래프 오마카세
Persistent Homology based Graph Convolution Network for Fine-grained 3D shape Segmentation
- 물체를 정확하게 이해하기 위해서는 먼저 그 물체를 구성하는 요소들 하나하나를 정확하게 인식하고, 그로부터 전체적인 형상을 추론할 수 있는 능력이 매우 중요할 것입니다. 3D shape segmentation 도메인에서 매우 중요한 포인트입니다.
- 예를 들어, 자전거와 오토바이를 생각해보시면 똑같이 핸들, 두 개의 바퀴, 안장 등과 같은 동일한 요소들을 가지고 있지만 세부적으로 핸들에 달린 기어, 브레이크의 위치와 모양, 바퀴의 크기와 그 모양, 안장의 너비 등등 복합적인 정보들을 한번에 인지하여 저희들은 정확하게 그 차이점을 구별할 수 있습니다.
- 이렇게 3d 객체의 세부 구성 인스턴스들의 복합적 관계 혹은 그 계층적 형상을 파악하는 것은 정확한 클래스 인지 문제에 있어서 매우 중요한 정보가 되지만, 그만한 정교한 알고리즘을 요구합니다.
- 대강적인 물체 형상은 유연한 그래프의 구조를 통해 충분히 커버할 수 있겠으나, 그것만으로는 뭔가 많이 부족할 듯 싶습니다. 또한 그래프 학습 메커니즘의 pairwise relationship으로는 고차원의 복잡한 구조를 포착하기 어렵습니다.
- 그로부터 개선을 위해, 토폴로지를 이해하는 접근 방법 해당 도메인에서 등장하고 있으며, 이러한 fine-grained한 객체를 이해하는 필수적인 단서로써 활용될 수 있음이 입증되고 있습니다. 결국에는 TDA에서 핵심 도구로 자리잡은 지속성 호몰로지의 역할이 중요해지고 있으며, 필트레이션 알고리즘을 통해 다중 스케일의 토폴로지 특징들을 계산하여 그 구조적 변화를 추적하는 프로세스를 따라갑니다.
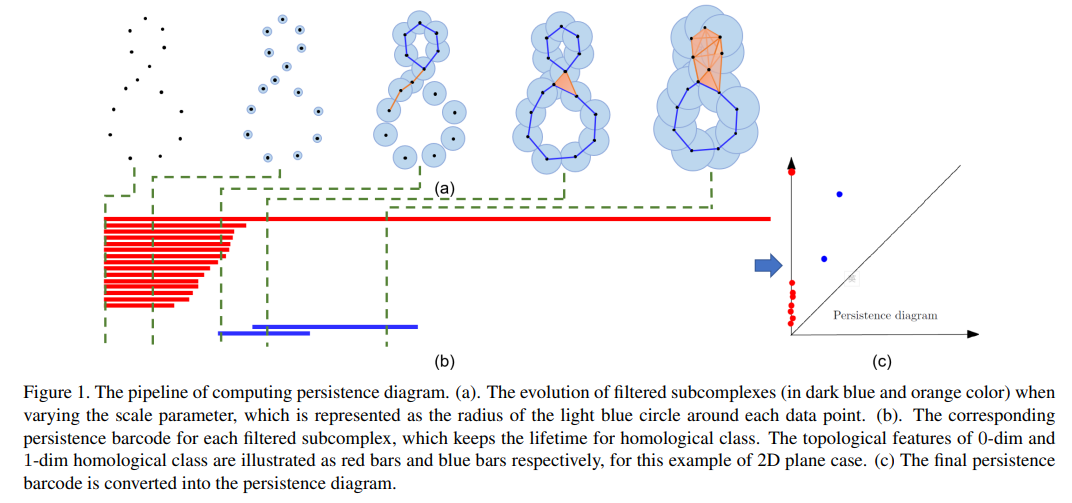
- 이번 주 오마카세에서 전달해드릴 논문에서는 지속성 호몰로지 정보를 기존 GCN 모델에 통합시켜 fine-grained한 3d 객체의 복합 구조를 토폴로지 기반으로 포착할 수 있는 능력이 부여된 새로운 모델을 제안합니다. 또한 자전거의 핸들, 바퀴의 체인 등과 같은 인지하기 어려운 요소들까지도 정교하게 분할할 수 있도록 가이드해줄 수 있는 새로운 토폴로지 목적 함수도 같이 제안합니다.
- 이전 오마카세 글로부터 설명드렸던 TDA의 개념들 (Complex, Homology, Filtration)을 숙지하고 계시다면 다음 아이디어를 이해하는 데 전혀 어려움이 없을거라 생각합니다.
Methodology : PHGCN
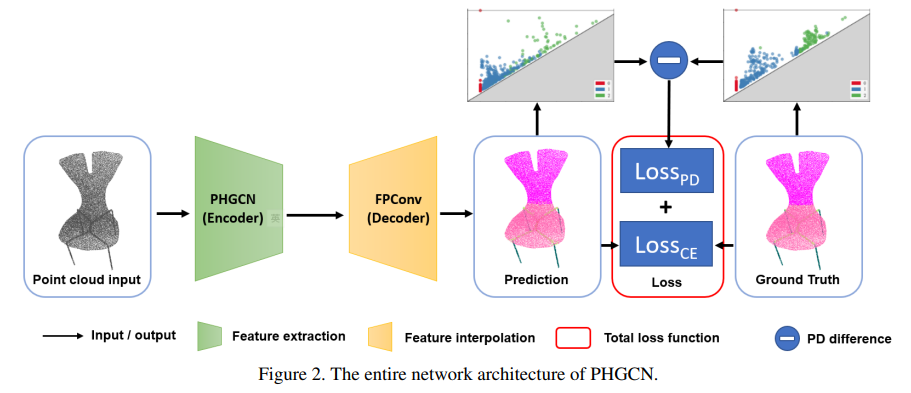
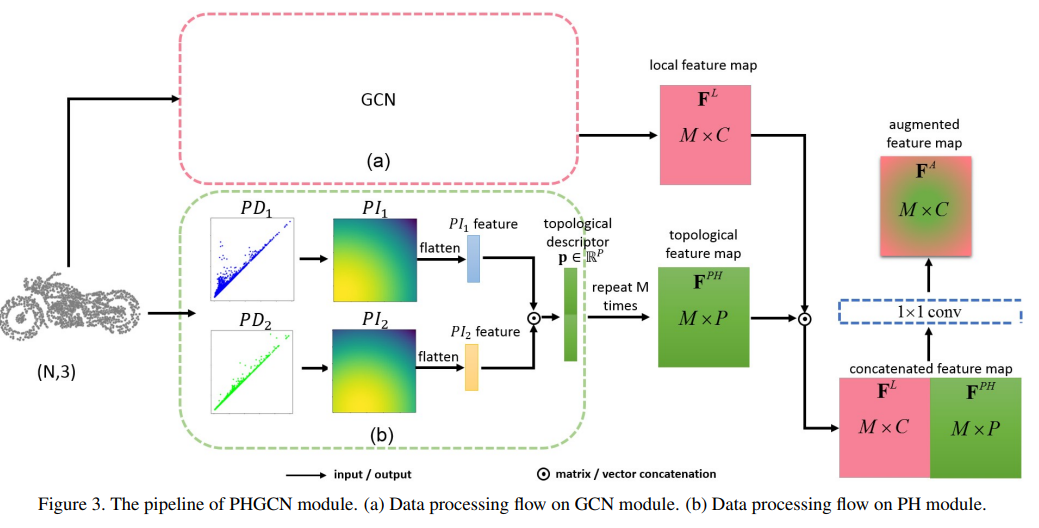
- 제안 모델명 PHGCN은 Fig 2, 3와 같이 데이터 형태를 잘 나타내고 있는 포인트 클라우드를 입력으로 받아, 그래프 표현의 로컬 연결 정보 및 전체적인 토폴로지 특징 정보를 통합 추출하는 인코더 모델로써 설계되었습니다.
- 토폴로지 특징을 인코딩하는 과정에 특별한 기법은 없어보입니다. 필트레이션 과정으로부터 추출된 다중 스케일의 토폴로지 정보를 기반으로 지속성 다이어그램 (PD1, PD2)을 계산하고, 벡터화 과정을 위한 지속성 이미지 (Persistent Image, PI)를 활용하여 토폴로지 특징 벡터를 출력합니다. (PI1, PI2)
- 다음 논문에서 저자들은 복합 구조의 핵심 토폴로지 정보로써 1-dim의 cycles 및 2-dim의 cavities를 활용하는 것이 중요하다고 주장합니다. 필트레이션 결과를 바탕으로 분석된 주장으로 보여집니다.
- GCN 기반 그래프 표현 학습을 통해 뽑아낸 local feature map과 통합하기 위해서 벡터 크기를 맞춰주어야 합니다. 따라서 위의 토폴로지 추출 과정을 M번 반복하여 이들을 Concatenate 시켜줍니다. 이러한 fusion map에 1x1 conv를 적용하여 세부적으로 학습된 point-wise feature representation을 최종적으로 얻어냅니다.
- 본래 포인트 클라우드 스케일로 되돌리는 디코더 모델로는 point-wise하게 적용되는 기존의 FPConv 모듈을 활용하였습니다.
Methodology: Persistence Diagram Loss
- 위의 과정을 통해 습득된 예측 결과에서 분할하기 어려운 토폴로지 구조 (위에서 언급한 작은 부분요소 등)의 일관되고 정확한 분할 결과를 얻어내기 위해 추가적인 토폴로지 목적함수가 필요함을 언급합니다.
- 이러한 토폴로지 비교를 위한 메트릭으로 TDA에서 널리 사용되는 Wasserstein distance을 활용합니다. 아래의 식으로 정의됩니다.
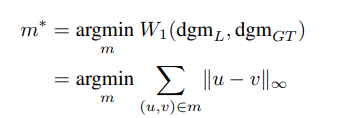
- 다음 식으로 정의된 Wasserstein distance의 의미를 간략하게 설명드리면, 한 지속성 다이어그램으로부터 다른 지속성 다이어그램으로의 최적 매칭 결과 (m*)는 그 매칭된 점들 사이의 거리의 총합이 최소가 되도록 하는 매칭을 의미하며, 그 매칭을 결정짓는 거리값 (W1)으로 정의됩니다.
- Wasserstain Distance로부터 최적의 매칭 m*이 결정되었다면, 토폴로지 목적함수 L_PD를 인스턴스 카테고리 전체에 대하여 square distance로써 정의합니다.
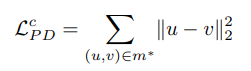
- 새롭게 추가되는 토폴로지 제약으로부터 최종 분할 결과에서 일관성 및 연결성의 최적화를 향상시키는 효과를 얻어낼 수 있음을 본 논문에서 언급합니다.
- 최종 목적함수 L은 L_PD와 Cross-Entropy와의 합으로써 정의됩니다.
💡
As a result, topological constraints are appended in optimization to enhance the coherency and connectivity in segmentation output, especially for fine-grained objects with shape-dependent topological structures.
- 최종 목적 함수를 활용하는 효과는 아래의 Qualitative results를 통해 확인해볼 수 있습니다. Fig 4 (b)와 같이 컵의 손잡이 부분, 오토바이의 핸들 및 바퀴 앞단 부분에 있어서 정교한 분할을 토폴로지 정보를 활용한 PHGCN만이 Ground truth와 거의 유사한 결과를 보여주고 있습니다.
- 실험에 대한 자세한 결과 및 분석은 해당 논문을 참고해주시기 바랍니다.
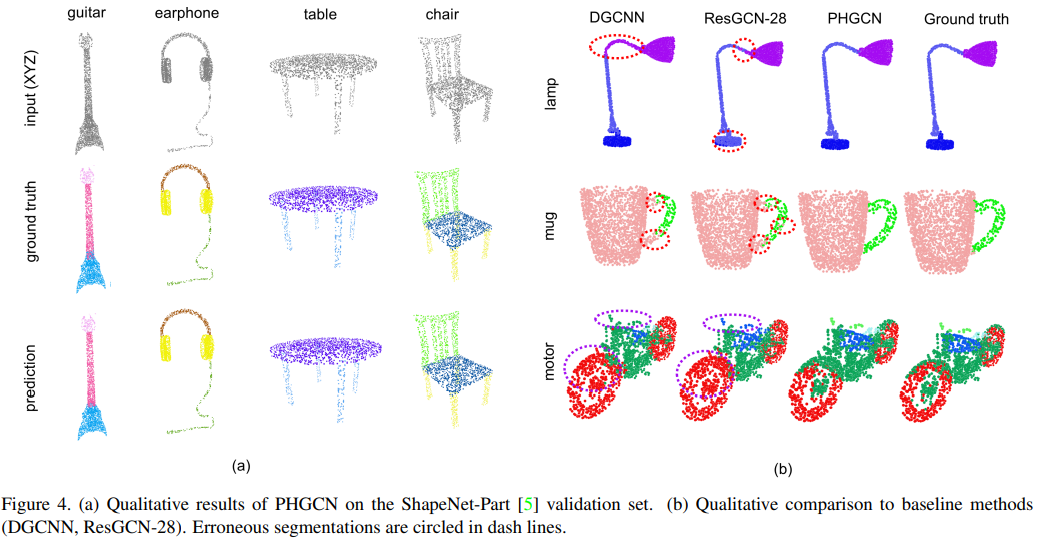

- 어려운 문제점으로 남아있던 fine-grained 3d shape segmentation의 복합적 구조를 정확하게 인식하기 위해, TDA의 핵심 도구들을 활용한 그 부분요소들의 토폴로지 정보를 그래프 구조와 결합하여 보완하고, 정확한 분할 결과의 일관성을 보존하기 위한 제약 함수를 추가 설계한 방법을 제안하였습니다.
- 당시 3d shape segmentation 도메인에서의 새로운 토폴로지 기반 접근법으로 그 기여도를 인정받았으며, 새로운 분야의 TDA 확장의 지표를 열어준 부분에 있어서 개인적으로 높게 평가하는 논문입니다.
- 또한 어떠한 어려운 기법이나 개념, 이론의 이해를 필요로 하지 않고, 기본적인 토폴로지 개념만으로 충분히 이해할 수 있기 때문에, 가볍게 부담없이 읽을 수 있었던 논문이라 생각합니다. 기회가 된다면 다음 메트릭에 대한 내용도 오마카세에서 자세히 다루어볼 수 있도록 하겠습니다.
- 개인적으로 목적 함수를 설계하는 과정에서 기반이 된 Wasserstain distance와, 연관이 깊은 Bottleneck distance에 대한 이론적인 설명을 위해 아래 두 논문을 읽어보시는 것을 추천드립니다.
Comparison of Persistence Diagrams
Topological Data Analysis (TDA) is an approach to handle with big data by studying its shape. A main tool of TDA is the persistence diagram, and one can use it to compare data sets. One approach to learn on the similarity between two persistence diagrams is to use the Bottleneck and the Wasserstein distances. Another approach is to fit a parametric model for each diagram, and then to compare the model coefficients. We study the behaviour of both distance measures and the RST parametric model. The theoretical behaviour of the distance measures is difficult to be developed, and therefore we study their behaviour numerically. We conclude that the RST model has an advantage over the Bottleneck and the Wasserstein distances in sense that it can give a definite conclusion regarding the similarity between two persistence diagrams. More of that, a great advantage of the RST is its ability to distinguish between two data sets that are geometrically different but topologically are the same, which is impossible to have by the two distance measures.
Approximation algorithms for 1-Wasserstein distance between persistence diagrams
Recent years have witnessed a tremendous growth using topological summaries, especially the persistence diagrams (encoding the so-called persistent homology) for analyzing complex shapes. Intuitively, persistent homology maps a potentially complex input object (be it a graph, an image, or a point set and so on) to a unified type of feature summary, called the persistence diagrams. One can then carry out downstream data analysis tasks using such persistence diagram representations. A key problem is to compute the distance between two persistence diagrams efficiently. In particular, a persistence diagram is essentially a multiset of points in the plane, and one popular distance is the so-called 1-Wasserstein distance between persistence diagrams. In this paper, we present two algorithms to approximate the 1-Wasserstein distance for persistence diagrams in near-linear time. These algorithms primarily follow the same ideas as two existing algorithms to approximate optimal transport between two finite point-sets in Euclidean spaces via randomly shifted quadtrees. We show how these algorithms can be effectively adapted for the case of persistence diagrams. Our algorithms are much more efficient than previous exact and approximate algorithms, both in theory and in practice, and we demonstrate its efficiency via extensive experiments. They are conceptually simple and easy to implement, and the code is publicly available in github.
[Contact Info]
Gmail : jhbae1184@akane.waseda.jp
Twitter (X): @jhbae1184