25년 2월 3주차 그래프 오마카세
Graph technologies outlook in 2025
youtube link : https://www.youtube.com/watch?v=e5MWzPEQk_g
- 2024년에 GraphRAG, Agents, KG에 대한 관심이 급증하면서 그래프 AI 다운스트림 태스크의 활용 측면에서 서비스 개발 및 기술 공유의 빈도수가 크게 늘어났습니다. 그래프 뿐만 아니라 다른 도메인으로의 확장 방향성에 대해서도 많이 논의되었고 현재진행형 이라고 생각합니다.
- KG 팟캐스트 및 다양한 주제를 논의하는 채널을 운영하는 Ashleigh Faith의 최신 영상을 보면 2025년 올 한해의 KG와 전반적인 AI 또는 그래프 외의 다른 도메인에서의 교차 트렌드에 대해 논의하고 있습니다. 지식 그래프에 관심이 많은 분들은 개인적으로 해당 영상 시청을 추천드리는 바입니다.
- 2025년 기대해볼 수 있는 그래프 기술 트렌드 관련한 내용을 간추려보면 아래와 같습니다. (참고: https://medium.com/derwen/graph-technologies-outlook-in-2025-bea621f394d8)
- LLM에서의 추론이 힘을 잃고, 대신 LLM보다 성능이 뛰어난 추론을 위한 더 나은 기존 접근 방식을 활용하는 것으로 대체될 것으로 예상합니다. (참고: neurosymbolic systems graph reasoning)
- GraphRAG는 현재 "그래프"라는 단어가 여러 가지 다른 의미를 갖는 방식을 감안할 때 경계 객체입니다. 표준화되는 대신(즉, 한 라이브러리가 시장 점유율 우위를 차지함) neurosymbolic systems이 확장되고 다양화됨에 따라 이는 실무 커뮤니티로 발전할 가능성이 큽니다.
- “Contextual Engineering”이 증가할 것으로 예상합니다. (참고: Rob Caulk and Elin Törnquist @ AskNews). 그래프 쿼리에 대한 내용이 줄어들고 특히 패턴 및 컨텍스트 마이닝을 위한 그래프 알고리즘에 대한 내용이 늘어날 것으로 예상합니다 (참고: Russ Jurney @ GraphletAI).
- AI 애플리케이션은 과학, 특히 재료 과학, 지구 과학/기후, 제약/생명 과학에서 큰 진전을 이루고 있으며, 이는 대부분 기술 거대 기업과는 무관합니다. (참고: Clem Delangue, et al. @ Hugging Face, Anima Anandkumar, et al. @ Caltech)
- 그래프 관행에서 더 많은 "Layers"을 볼 것으로 예상합니다. 예를 들어 관계형 데이터 관리 시스템 위에 KG를 구축하고 그래프 분석에서 더 많은 “levels of detail (LOD)” 을 볼 수 있습니다. 이는 공간 분석의 LOD와 유사합니다.
- ML 관행에서 평가가 더 공식화될 것으로 예상합니다(참고: Gaël Varoquaux, Olivier Grisel, et al., @ :probabl). 더 작고 계산 비용이 덜 드는 모델(less carbon footprint)에 중점을 둡니다.
- 확실히 그래프 친화적인 수학자들을 주의 깊게 살펴볼 것입니다.특히 확률 회로(참고: Guy Van den Broeck, et al. @ UCLA StarAI Lab)와 최적화된 인과 그래프(참고:Urbashi Mitra, et al. @ USC Viterbi)의 발전에 주목해야 합니다. 이러한 발전은 AI 애플리케이션을 증강하여 인간과 기계의 협업적 결정을 인간 규모에서 더 쉽게 이해하고 조작할 수 있게 만들 가능성이 높습니다.
- 영상에 나오셨던 Paco Xander의 Medium 글과 함께 해당 영상을 시청하시면 그래프 기술 흐름에 대해 가볍게 짚고 넘어가는 것에 도움이 많이 되실 것 같습니다.
How to Implement Graph RAG Using Knowledge Graphs and Vector Databases
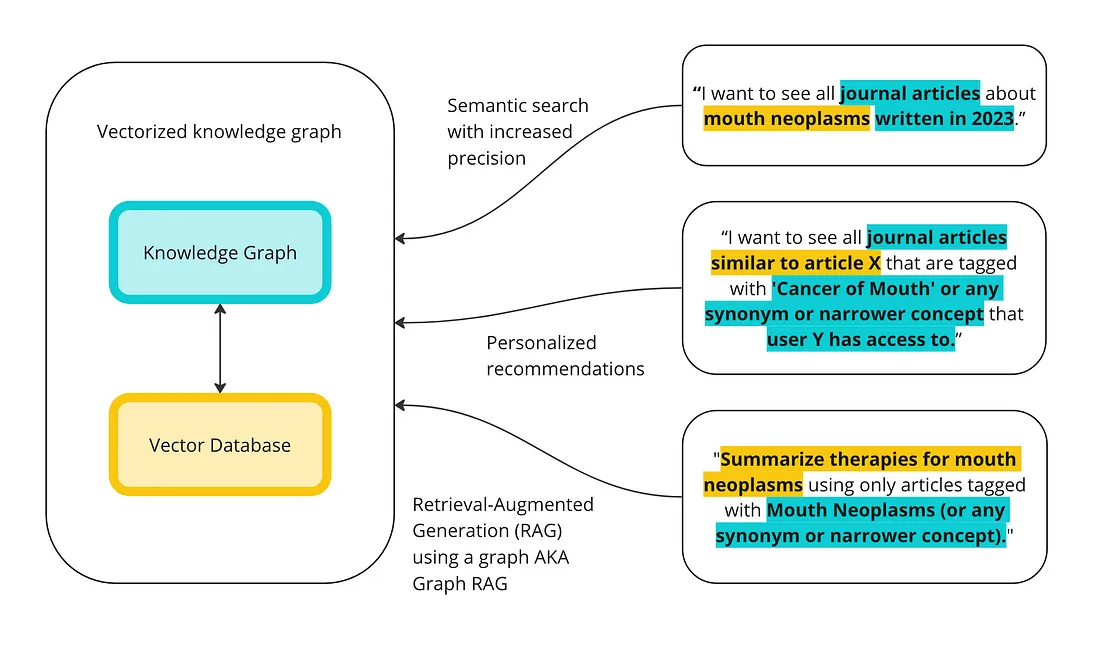
- RAG, Semantic Search, and Recommendations의 단계별 구현 튜토리얼을 제공하고 있는 유용한 블로그 글입니다. 다음 목표는 KG와 벡터 데이터베이스 간의 차이점을 설명하고 이들이 함께 동작할 수 있는 방법을 제공하는 것이라고 합니다. (위의 그림 : '벡터 데이터베이스와 KG가 advanced queries를 실행하는 개괄적 개요' 참고)
- 블로그 요약을 아래와 같이 제공하고 있습니다. 해당 내용만 가볍게 짚고 넘어가셔도 괜찮을 것 같습니다. 핵심만 간추리면 아래와 같습니다.
- 벡터 데이터베이스는 몇 가지 경고와 함께 의미 검색, 유사성 계산 및 일부 기본 형태의 RAG를 꽤 잘 실행할 수 있습니다. 벡터화 모델은 주로 비정형 데이터에서 학습되므로 엔터티와 관련된 텍스트 청크가 주어지면 잘 수행됩니다.
- 벡터 데이터베이스만 사용하는 가장 큰 단점 중 하나는 설명 가능성이 부족하다는 것입니다. 하지만 의미 검색, 유사성 및 RAG에 KG를 사용하는 가장 큰 장점은 때때로 "enhanced data enrichment" 또는 "graph as an expert"라고 불리는, KG를 사용하여 검색어를 확장하거나 정제할 수 있는 이점으로부터 설명 가능성 문제를 커버할 수 있습니다.
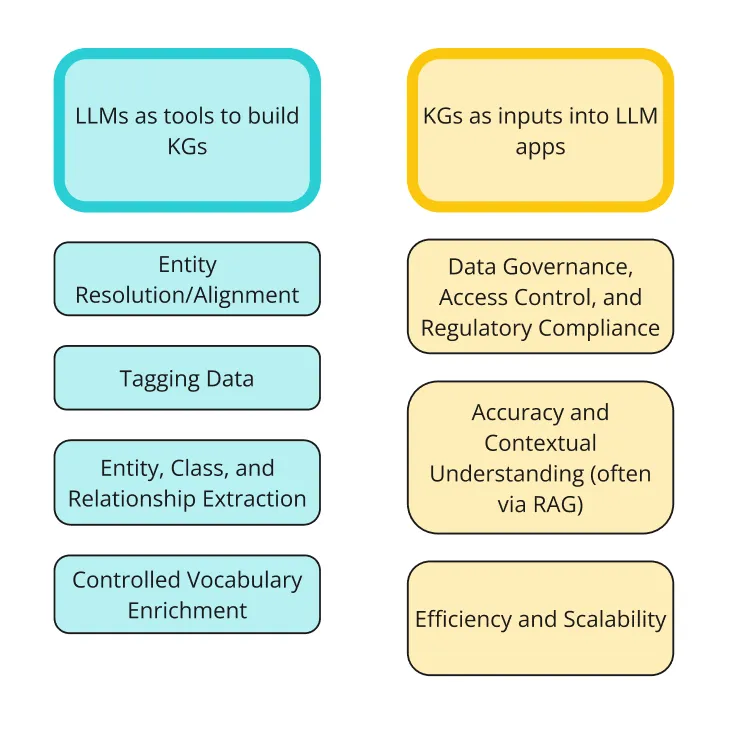
- KG 사용을 시작하는 데 가장 큰 장애물 중 하나는 KG를 구축해야 한다는 것입니다. 즉, LLM을 사용하여 KG 구축 속도를 높이는 방법은 여러 가지가 있습니다. (아래 그림 참고)
- 'Context poisoning': 벡터 데이터베이스에서 관련 없는 콘텐츠가 반환될 가능성은 검색 및 유사성에는 귀찮은 일이지만 RAG에는 큰 문제입니다. 위험한 점은 응답이 반드시 사실적으로 부정확하지 않고 부정확한 데이터에 기반하지 않으며 질문에 답하기 위해 잘못된 데이터를 사용하는 것입니다. 그러나 KG는 컨텍스트 오염 가능성을 줄이는 데 도움이 될 수도 있습니다.
- 해당 튜토리얼에서 제공하는 내용은 벡터 데이터베이스를 KG로 변환하여 Semantic search, similarity search, RAG에 대한 3가지 검색 테스트 (Vector-based, Prompt-to-query, and hybrid retrieval)를 수행합니다. Medium 블로그에 그 과정에 대한 코드와 자세한 설명이 제공되어 있으니, 참고해보시면 좋을 것 같습니다.
[Contact Info]
Gmail: jhbae1184@akane.waseda.jp
Twitter (X): @jhbae1184