25년 1월 4주차 그래프 오마카세

Supporting Ontology and Knowledge Graph Development on the Web
youtube link : https://youtu.be/g9pgQIs8lso?si=QWcP8xFDPgHEJhXN
- 안녕하세요. 벌써 25년 1월의 4번째 주 오마카세를 작성하고 있으니 시간이 정말 빨리 흘러가는 것 같습니다. 이번 주에도 어떤 내용을 전달해드리면 좋을 지 열심히 서칭하고 있었는데 다음 유튜브 영상을 발견하게 되었습니다.
- '웹에서 온톨로지 및 지식 그래프 개발 지원' 이라는 제목을 보자마자 이거 도움이 될 수 있겠다 생각이 들어서 다음 강연을 시청한 후 여러분들께 공유드리게 되었습니다.
- 최근 "지식 그래프"의 인기가 급상승하게 되면서 다양한 웹 커뮤니티 상 지식그래프 사용자들로부터 정확하게 정의된 의미 체계를 갖춘 논리 기반 지식 표현 언어 (Logic-based knowledge representation languages)의 채택에 대한 수요가 점점 늘어나는 새로운 경향이 발견되었다고 합니다.
- 다음 사실을 기반으로 정보 정확성, 관리 및 배포와 지식 발견의 용이성 개선에 집중하기 위한 온톨로지의 적용을 중심으로 연구를 진행하시는 스탠포드 대학의 Rafael 조교수님께서 Pinterest, Elsevier, BASF 등과의 다양한 협업 경험을 기반으로 웹 상의 온톨로지 및 지식 그래프 엔지니어링을 개선하는 방향 및 새로운 기능에 대한 추가 과정 등을 폭넓게 해당 영상에서 논의하고 있습니다.
- 해당 내용에 더욱 전문가이신 구독자 여러분들께서 영상을 시청해보신 후 의논된 다양한 사항들에 대해 깊게 생각해볼 수 있는 기회가 되었으면 좋겠습니다.
Large Language Models, Knowledge Graphs and Search Engines : A Crossroads for Answering Users' Questions
paper link : https://arxiv.org/abs/2501.06699
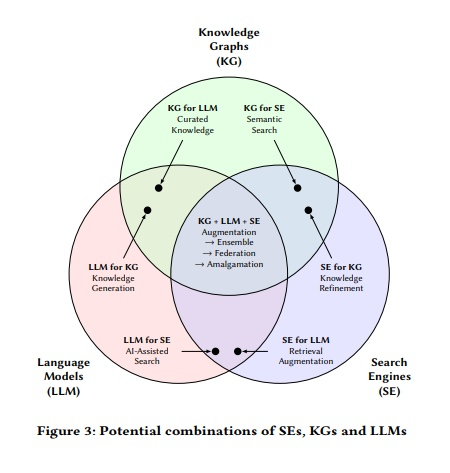
- 오마카세 글 작성일 기준 (1/18), 6일전에 갓 아카이브에 따끈따끈하게 올라온 재밌는 논문을 발견하여 여러분들께 공유드리고자 합니다.
- 대규모 언어 모델, 지식 그래프, 검색 엔진 간의 시너지 효과를 얻어낼 수 있는 결합 방식에 대한 다양한 논의가 존재합니다. 하지만 사용자 관점에서 이들의 다양한 측면 및 레벨 수준을 고려 및 통합하여 방대한 요구 사항을 해결하는 문제는 여전히 존재하고 있음을 언급합니다.
- 다음 논문에서는 사용자 정보 요구 사항에 대한 분류법을 소개하며 이를 통해 (제목과 같이) 대규모 언어 모델, 지식 그래프, 검색 엔진의 장단점 및 이들의 시너지 효과를 연구하여 제시하고 있습니다. 위의 그림을 참고해보시면 좋을 것 같습니다.
- 다음 논문을 통해 해당 문제를 처리하기 위한 미래 연구방향성 및 로드맵 제시에 많은 도움이 될 수 있을거라 생각합니다. 관심이 있으신 구독자 여러분들께서 해당 논문의 따끈함이 식기전에 (빨리) 읽어보시고 많은 인사이트를 얻어가셨으면 좋겠습니다.
From Local to Global : A GraphRAG Approach to Query-Focused Summarization
paper link : https://arxiv.org/abs/2404.16130
- 마지막으로 마이크로소프트의 GraphRAG 논문을 공유해드리고자 합니다. 워낙 유명한 논문이고, 많은 연구자들 사이에서 빠르게 공유되고 있기에 몇몇 구독자 여러분들께서는 이미 접해보셨을 수 있는 논문이라 생각이 됩니다.
- 해당 링크드인의 글을 가볍게 전달해드려보면, 지식 그래프와 RAG의 결합 방식에 고민하면서 HAR (Hypothetical Answer Retrieval) / HQR (Hypothetical Question Retrieval) 과 GraphRAG 방식에 더욱 초점을 맞추어 해답을 찾고자 하였습니다.
- 후자, GraphRAG의 경우 그래프 구조에 따라 BFS/DFS 알고리즘을 선택하고 관련 청크 노드를 검색하여 그에 맞는 LLM 컨텍스트를 찾아나가는 방식으로 진행됩니다. 아래 예시를 통해 쉽게 이해해볼 수 있었습니다.
- E.g. if you asked a question "What is an MLP?" you might match with a chunk inside "Deep Learning" node, and then descending down a level you traverse through "Neural Network" node's neigborhood and fetch "CNN", "RNN", "transformer", "MLP", and other such nodes.
- GraphRAG에 대한 필자의 부족한 이해 및 백그라운드 지식으로 인해 부정확한 정보전달을 방지하기 위해 디테일한 주장 및 아이디어에 대해서 오마카세로 자세히 다루는 것은 어려울 듯 합니다.
- 하지만 더욱 전문가 선생님들이신 구독자 분들께 시간을 투자하여 해당 논문을 깊게 읽어보시고 탐구해보시는 것을 저는 추천드리고 싶습니다. 그만한 많은 인사이트를 얻어가시고 새로운 관점에서 해석해볼 수 있는 기회로 충분하다고 생각되어집니다.
- 위의 링크드인 게시글에서 잘 요약된 핵심 내용들과 댓글 내용들도 추가적으로 살펴보시면서 꼼꼼하게 검토해보시는 것 또한 추천드립니다 !
[Contact Info]
Gmail: jhbae1184@akane.waseda.jp
Twitter (X): @jhbae1184
LIGHTRAG: SIMPLE AND FAST RETRIEVAL-AUGMENTED GENERATION
https://arxiv.org/pdf/2410.05779
안녕하세요. 정이태 입니다. 최근 LightRAG를 찾는 분들이 부쩍 많아졌습니다.
그 이유가 무엇일까하며 생각해보니 대체적으로 다음 과정을 겪고 계시는거 같았습니다.
0.Vector 관점으로 RAG 첫 시작.
1.간간이 발생하는 환각현상을 해소하기 위해 Reaonsing 키워드 발견. 여러 고도화 기술 중 Knowledge graph 를 발견.
2.기존 vector RAG 파이프라인에 접목해보기 위해 Neo4j 의 GraphRAG 를 발견 및 시도.
3.데이터 내 온톨로지 추출하기가 까다롭고 복잡함을 깨달음.
4.Entity Extraction 부터 knowledge base 구축까지 한번에 해결해주는 Microsoft GraphRAG 시도
5.LLM cost 비용이 높고, latency 가 긺.
6.LightRAG GraphRAG 발견 및 시도
핵심을 살펴보면 큰 틀에선 환각현상 해소 작은 틀에서는 온톨로지 추출 , 비용 절감이 니즈임을 관찰할 수 있습니다. 오늘은 작은 틀한(GraphRAG)에서 한 번 이야기해보도록 하겠습니다. 어떻게 비용-효과 측면에서 GraphRAG를 잘 구현할 수 있는가.
우선 LightRAG 에서 제기하는 문제들은 다음과 같습니다.
1.엔티티들간의 관계를 이해하고 정보형태로 가공하는데 주저하고 flat data 표현에 많이 의존하였음.
2.그간 RAG 시스템들은 다양한 엔티티간 역학관계 보존 및 결합을 활용한 contextual awareness 가 부족했음.
이를 개선하고자 lightRAG에서는 다음과 같은 포부를 밝힙니다.
1.문서 내에 존재하는 엔티티들간 의존성을 발견하고 이를 활용한다.
2.retrieval efficiency 를 활용해서 response time 을 줄인다.
3.새로운 데이터가 발생했을때 지식 베이스 업데이트하는 비용을 줄여서 신속하게 적용할 수 있게한다.
위 3개의 포부를 해결하기 위해 다음과 같은 아키텍쳐를 제안하는데요. 한 번 살펴보겠습니다.
Architecture
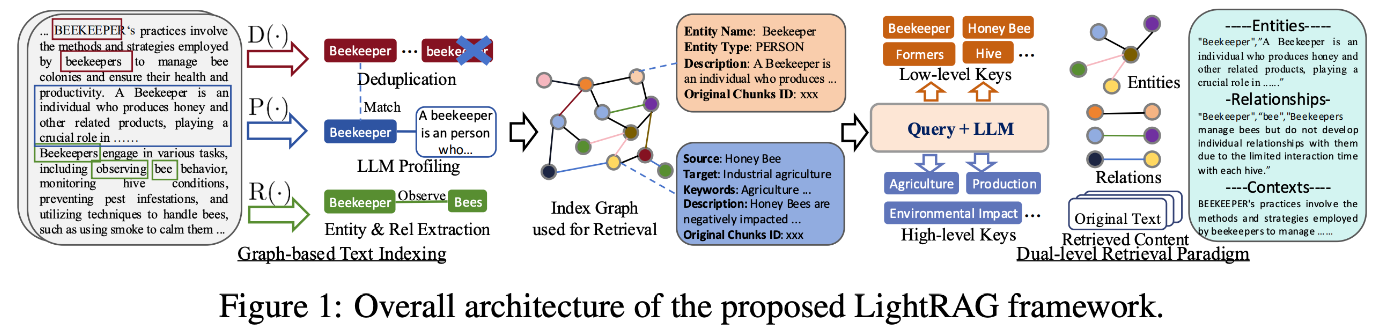
Figure 1을 살펴보면 다음 4가지 순서로 LightRAG 가 진행된다는걸 알 수 있습니다.
1.Graph-based Text Indexing
2.Index Graph used for Retrieval
3.Dual-level Retrieval Paradigm
기존에 저희가 알고 있던 GraphRAG와 다르게 무엇이 다를까 생각해보면, 다음 한가지를 발견할 수 있습니다. Dual-level Retrieval Paradigm. 구체적으로 말씀드리기전에 간단히 설명을 드리면 Dual-level retrieval paradigm은 엔티티들에게 2가지 추상화 레벨을 적용해 거시적인 답변을 위해 필요한 엔티티 처리 , 미시적인 답변을 위해 필요한 엔티티 처리 하는 부분입니다.
어디에서 비슷한 내용을 들어보시지 않으셨나요? 네 바로 Microsoft GraphRAG는 이를 Community detection 하고 이를 traversal 하는 관점과 비슷한 내용인데요. 여기에선 Community detection을 하지 않습니다. 그럼 여러분들이 재밌게 보실 부분은 LightRAG 의 Dual-level retrieval paradigm 과 Microsoft 의 Community detection 를 비교하며 어떤점에서 비용효용적이고 정확도 결과 또한 개선할 수 있었는가에 대한 부분인데요. 이 부분 제외하고도 재밌는 내용들이 많으니, 다른 내용들도 설명드리며 차차 말씀드리겠습니다.
위 아키텍쳐를 통해 LightRAG 가 잘한다라고 주장하는 포인트를 저는 다음 3가지로 이해했습니다. 본문에서 인용한 문장들과 함께 저희가 의문을 가지고 보면 좋을 점들을 추가해봤습니다.
LightRAG employs efficient dual-level retrieval strategies: low-level retrieval, which focuses on precise information about specific entities and their relationships, and high-level retrieval, which encompasses broader topics and themes.
low-level retrieval 을 활용해서 특정한 엔티티 그리고 그들의 관계를 도출해서 정확한 정보에 집중할 수 있다. 또한 high-level retrieval 을 통해 borader topic 그리고 theme들을 아우를수 있다.
-> 무슨 기준을 가지고 low-level , high-level 를 분류하는지.
LightRAG effectively accommodates a diverse range of quries, ensuring that users receive relevant and comprehensive responses tailored to their specific needs. Additionally, by integrating graph structures with vector representations, our framework facilitates efficient retrieval of related entities and relations while enhancing the comprehensiveness of results through relevant structural information from the constructed knowledge graph.
유저의 특정 니즈가 반영된 쿼리가 인풋으로 들어오더라도, 관련성 있고 풍부한 답변을 할 수 있다. 추가로 벡터 표현과 지식그래프 표현을 잘 통합해서 comprehensiveness 개선할 수 있다. 특히 저는 이 부분이 궁금했는데요. 기존 Vector RAG 시스템에 Graph 관점을 어떻게 프롬프트에 녹여내고, 이를 평가까지 하는지를요.
-> 1.어떻게 user query tailored 하는지.2. 어떻게 vector RAG 와 Alignment를 어떻게 하는지.
By eliminating the need to rebuild the entire index, LightRAG reduces computational costs and accelerates adaptation, while its incremental update algorithm ensures timely integration of new data, maintaining effectiveness in dynamic environments.
전체 인덱스를 재설계하는 수고를 덜함으로써, Dynamic adapation(지식베이스가 빈번히 업데이트 되는) 상황시 연산 비용 그리고 업데이트(속도)를 가속화 할 수 있음.
-> 어떻게 index rebuild 비용을 줄이는지.
여기까지 아키텍쳐에 대한 오버뷰 그리고 아키텍쳐를 활용했을때 얻을 수 있는 장점들을 살펴봤는데요. 1.유저 쿼리의 추상성을 반영해서 답변할 수 있다 2. 기존 Vector RAG 시스템과 효율적으로 통합할 수 있다. 3. 기존 RAG 인덱싱 비용을 개선할 수 있다. 라고 볼 수 있습니다. 그럼 다음엔 이를 위해 어떤 알고리즘들이 개발되었는지 살펴보겠습니다.
Graph-based text indexing
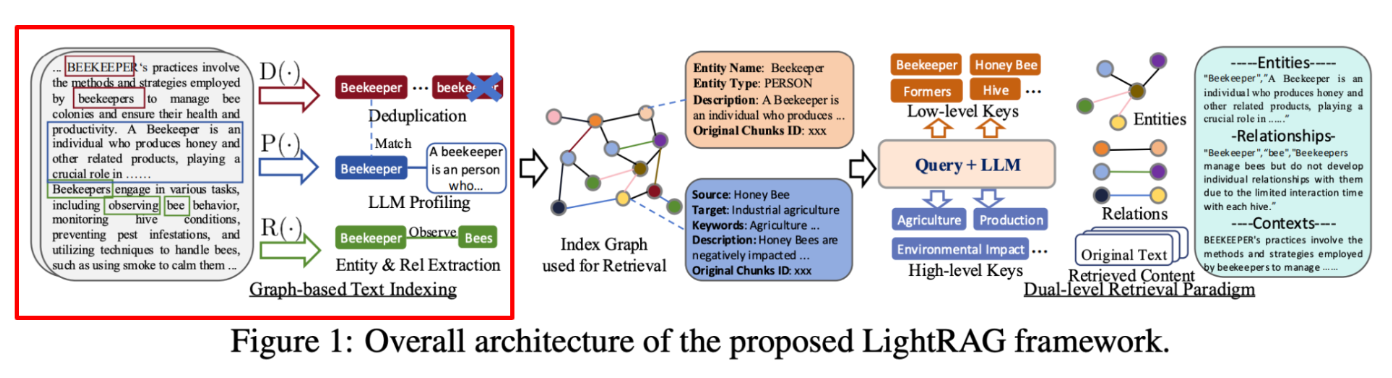
첫 단계입니다. 텍스트 데이터에서 그래프를 설계하는 과정입니다. 간단하게 3가지 함수를 통해 그래프로 변화됩니다. 1. Recognize(엔티티 , 엣지 추출) , 2. Profiling(엔티티 검수) 그리고 3. Deduplication(중복 제거). 엔티티 엣지를 인지하고 검수하고 중복제거하는 단계로 이루어집니다. 여기에서 2번 profiling 이 독특한데요. 엔티티 와 엣지들을 key-value store 에 저장합니다.
여러 문서들마다 발생하는 entity 들이 있을테고, 그때마다 relationship 이 다를수도 있으니 이를 key-value store 를 활용해 모두 보관한다는 거죠. 그리고 retrieval 마다 엔티티가 호출될때 다양한 relationship 들 중 연관성이 있는 relationship을 가져와 kg context 로 활용한다는게 핵심입니다.
추가로 entity extraction시 high-level keyword 또한 추출하게 되는데요. 문서 내 엔티티들을 추출할 시, 콘셉이나 테마 혹은 토픽을 반영한 엔티티가 있을때 이를 따로 가져와서 보관해라 라는게 직접적으로 프롬프트에 기재가 되어있습니다. 아래 프롬프트 중 일부를 발췌한 내용을 살펴보시면 흥미로운 부분이 많은데요.
방금 언급했듯이, capture the overarching ideas present in the document 를 프롬프트에 직접해주었고, 아래 예시로 텍스트를 주어주고 사용자가 사전에 정의한 high_level_keywords few shot example 를 입력해준다는 것입니다.
저는 개인적으로 이 부분이 가장 핵심이라 생각하는데요. high_level keyword 를 과연 어떤 기준으로 추출하는지가 애매한 LLM에게 얼마만큼의 도메인 전문성(domain bias)이 반영된 품질이 좋은 예시들을 입력해주느냐에 따라 성패가 갈릴거 같다라는 생각이 들기 때문입니다. 누군가에겐 high_level_keyword 가 아닐수도 있기에, general 그리고 specific 밸런스를 잘 유지하는 프롬프트 그리고 예제를 입력해야 한다는게 최우선일거 같습니다.
# lightrag/prompt.py/entity_extraction
Identify high-level key words that summarize the main concepts, themes, or topics of the entire text. These should capture the overarching ideas present in the document.
Format the content-level key words as ("content_keywords"{tuple_delimiter}<high_level_keywords>)
Text:
while Alex clenched his jaw, the buzz of frustration dull against the backdrop of Taylor's authoritarian certainty. It was this competitive undercurrent that kept him alert, the sense that his and Jordan's shared commitment to discovery was an unspoken rebellion against Cruz's narrowing vision of control and order.
Then Taylor did something unexpected. They paused beside Jordan and, for a moment, observed the device with something akin to reverence. “If this tech can be understood..." Taylor said, their voice quieter, "It could change the game for us. For all of us.”
The underlying dismissal earlier seemed to falter, replaced by a glimpse of reluctant respect for the gravity of what lay in their hands. Jordan looked up, and for a fleeting heartbeat, their eyes locked with Taylor's, a wordless clash of wills softening into an uneasy truce.
It was a small transformation, barely perceptible, but one that Alex noted with an inward nod. They had all been brought here by different paths
# high_level_keywords 만을 한정해서 가져옴.
("content_keywords"{tuple_delimiter}"power dynamics, ideological conflict, discovery, rebellion"){completion_delimiter}
Indexing
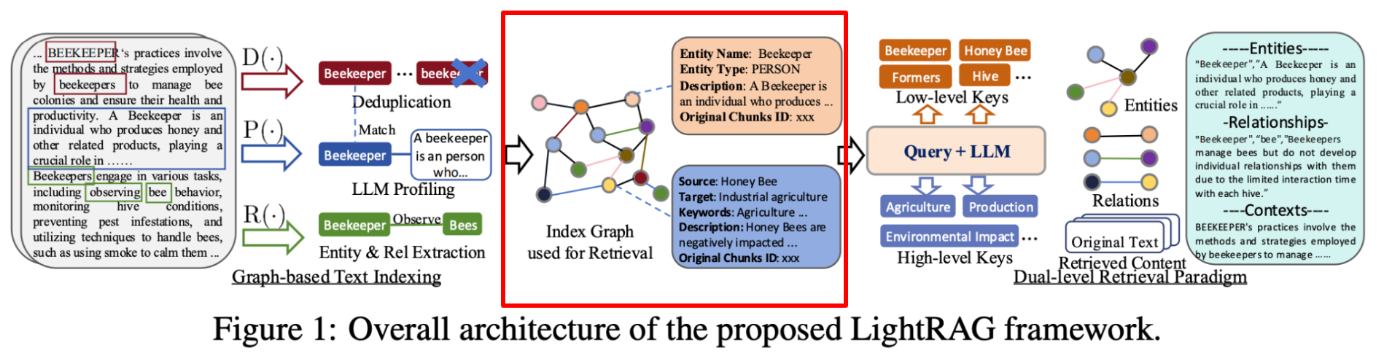
위 그림의 노드 , 프로퍼티에서 특이한 부분을 발견할 수 있습니다. 바로 description , original chunks id 인데요. original chunks id 는 이 엔티티가 어디에서 왔는지 Reference 를 위함이고, description 은 entity , relationship 에 대해 LLM이 자체적으로 한 번 더 생각해보게끔 유도한 결과가 반영된 프로퍼티라고 할 수 있습니다.
프롬프트를 살펴보자면 'Comprehensive description' 과 'explanation as to why you think the source entity and the target entity are related to each other' 을 확인할 수 있습니다. 어디에서 많이 살펴본 프롬프트 구절이죠? CoT와 유사합니다. 즉 LLM에게 self-reflection 을 명령하는거죠. 이를 통해 나온 결과물을 활용해서 여러 데이터들로부터 발생한 엔티티들을 구별하고 맥락을 유추하는데 활용합니다.
간단히 생각해보자면 비슷한 도메인의 문서들마다 동일한 엔티티들이 있겠으나, 각기 다른 맥락으로 엔티티가 쓰일 확률이 높으니 이를 모두 보관 및 관리하고 메타까지 추출해서 generation 시 활용한다는거죠.
# lightrag/prompt.py/entity_extraction
- entity_description: Comprehensive description of the entity's attributes and activities
- Format each entity as ("entity"{tuple_delimiter}<entity_name>{tuple_delimiter}<entity_type>{tuple_delimiter}<entity_description>)
- relationship_description: explanation as to why you think the source entity and the target entity are related to each other
- relationship_keywords: one or more high-level key words that summarize the overarching nature of the relationship, focusing on concepts or themes rather than specific details
Format each relationship as ("relationship"{tuple_delimiter}<source_entity>{tuple_delimiter}<target_entity>{tuple_delimiter}<relationship_description>{tuple_delimiter}<relationship_keywords>{tuple_delimiter}<relationship_strength>)
Dual level retrieval
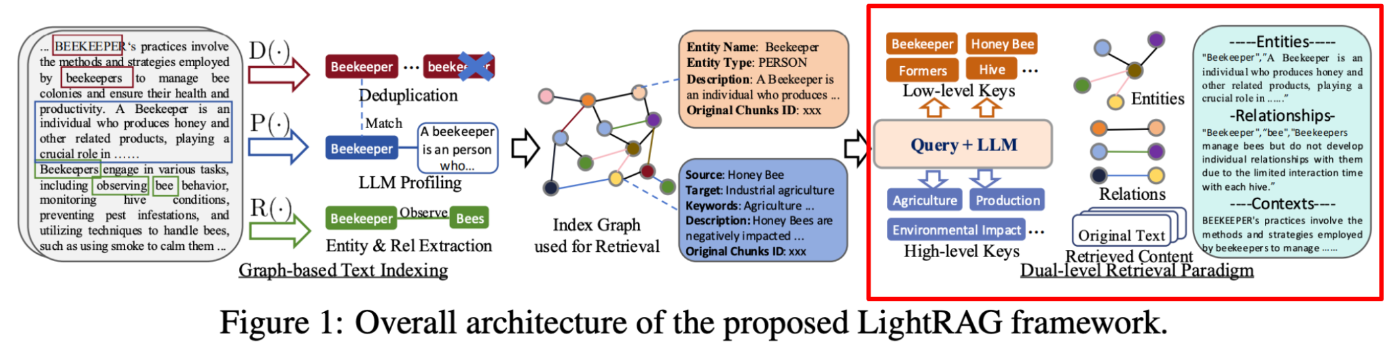
프롬프트 핵심부분만 가져와서 살펴보면 유저의 쿼리가 들어왔을시, high-level , low-level keyword 를 추출합니다. 이때, overarching , specific 이라는 단어를 기입하여 추상성 레벨을 조절해주고, 이를 반영한 few-shot example 을 보여줍니다. LLM이 앞선 프롬프트의 추상성 레벨 단어와 예시들을 보면서 유저의 쿼리를 거시적 , 미시적 관점으로 나눠주는거죠.
# lightrag/prompt.py/keywords_extraction
You are a helpful assistant tasked with identifying both high-level and low-level keywords in the user's query.
---Goal---
Given the query, list both high-level and low-level keywords. High-level keywords focus on overarching concepts or themes, while low-level keywords focus on specific entities, details, or concrete terms.
---Instructions---
- Output the keywords in JSON format.
- The JSON should have two keys:
- "high_level_keywords" for overarching concepts or themes.
- "low_level_keywords" for specific entities or details.
# lightrag/prompt.py/keywords_extraction_examples
Output:
{
"high_level_keywords": ["International trade", "Global economic stability", "Economic impact"],
"low_level_keywords": ["Trade agreements", "Tariffs", "Currency exchange", "Imports", "Exports"]
}
rag_response 즉 generation 할때 드디어 indexing 단계에서 저장한 keyword 들을 json format 에서 꺼내와 활용합니다. 유저가 입력한 쿼리를 high-level , low-level keyword 로 분류해주고 , 이 분류된 키워드와 기존에 지식 베이스에 저장한 high-level ,low-level keyword 를 매칭해주며 그에 따라 추상성 레벨을 반영한 답변을 내놓게 되는거죠.
# lighrag / prompt.py / rag_response
You are a helpful assistant tasked with identifying both high-level and low-level keywords in the user's query.
---Goal---
Given the query, list both high-level and low-level keywords. High-level keywords focus on overarching concepts or themes, while low-level keywords focus on specific entities, details, or concrete terms.
---Instructions---
- Output the keywords in JSON format.
- The JSON should have two keys:
- "high_level_keywords" for overarching concepts or themes.
- "low_level_keywords" for specific entities or details.
######################
-Examples-
######################
{examples}
#############################
-Real Data-
######################
Query: {query}
######################
The `Output` should be human text, not unicode characters. Keep the same language as `Query`.
Output:
Integrating Graph and Vectors for Efficient Retrieval
위에서 여러 맥락을 추출했으면 이제 맥락들을 종합하는 단계입니다. 우선 vector knowledge base 에서는 topk 를 최소 10개 지정해서 가져옵니다. 그리고 Vector , KG context 들 중 연관성 있는 5개의 context 들을 리스트업 해서 reference 라는 명목으로 유저에게 제공해라 라는 말이 프롬프트에 입력되어 있습니다. 저희가 흔히 활용하는 reranker 기능을 여기에 추가해뒀네요.
이외에 추가로 살펴보면 좋은 부분은 'When handling information with timestamps' 입니다. 지속적으로 갱신되는 지식베이스들 중 유의미한 context 들을 어떻게 도출할지가 작성되어 있습니다.
핵심은 "가장 최신의 information이라 해서 마냥 좋은건 아니다. content 와 relationship 그리고 timestamp 3가지를 주안점으로 두고 판단해라. 만일 시의 적정성(time-specific) 관련 쿼리가 발생한다면 Temporal 에 우선순위를 두어라." 라고 할 수 있겠습니다. 서두에 언급한 Rapid knowledge update and efficient retrieval 에 해당하는 부분이지 않을까 싶네요.
# lightrag / operator.py
async def get_vector_context():
# Reuse vector search logic from naive_query
try:
# Reduce top_k for vector search in hybrid mode since we have structured information from KG
mix_topk = min(10, query_param.top_k)
results = await chunks_vdb.query(query, top_k=mix_topk)
if not results:
return None
# lightrag / prompt.py / mix_rag_response
---Role---
You are a professional assistant responsible for answering questions based on knowledge graph and textual information. Please respond in the same language as the user's question.
---Goal---
Generate a concise response that summarizes relevant points from the provided information. If you don't know the answer, just say so. Do not make anything up or include information where the supporting evidence is not provided.
When handling information with timestamps:
1. Each piece of information (both relationships and content) has a "created_at" timestamp indicating when we acquired this knowledge
2. When encountering conflicting information, consider both the content/relationship and the timestamp
3. Don't automatically prefer the most recent information - use judgment based on the context
4. For time-specific queries, prioritize temporal information in the content before considering creation timestamps
---Data Sources---
1. Knowledge Graph Data:
{kg_context}
2. Vector Data:
{vector_context}
---Response Requirements---
- Target format and length: {response_type}
- Use markdown formatting with appropriate section headings
- Aim to keep content around 3 paragraphs for conciseness
- Each paragraph should be under a relevant section heading
- Each section should focus on one main point or aspect of the answer
- Use clear and descriptive section titles that reflect the content
- List up to 5 most important reference sources at the end under "References", clearly indicating whether each source is from Knowledge Graph (KG) or Vector Data (VD)
Format: [KG/VD] Source content
Add sections and commentary to the response as appropriate for the length and format. If the provided information is insufficient to answer the question, clearly state that you don't know or cannot provide an answer in the same language as the user's question."""
프롬프트만으로 보면 이해가 어려운 부분일거라 생각되어 보다 원활한 이해를 위해 논문에 있는 Figure3 를 가져왔습니다. 아래 그림과 같이 high-level keyword , low-level keyword 를 추출하고 그에 따른 Entity , relationship (KG) 그리고 sources(Vector)를 retrieval context로 넣어줍니다.

Evaluation & metric
• (RQ1): How does LightRAG compare to existing RAG baseline methods in terms of generation performance?
• (RQ2): How do dual-level retrieval and graph-based indexing enhance the generation quality of LightRAG?
• (RQ3): What specific advantages does LightRAG demonstrate through case examples in various scenarios?
• (RQ4): What are the costs associated with LightRAG, as well as its adaptability to data changes?
위에서 아키텍쳐 그리고 세부 모듈들을 프롬프트와 함께 살펴봤습니다. 이 아키텍쳐가 정말 효율적인지 입증하기 위해 실험이 필요하겠죠? 본 논문에서는 아래 4개의 Research Question을 설정하고 실험합니다. RQ1,2는 기존 RAG (vector) 대비 좋은지 , dual-level(추상성레벨)을 반영한 관점이 얼마만큼 성능 향상에 기여하는지를 관찰하기 위해 실험한 내역이고, RQ3,4는 GraphRAG vs. LightRAG 성능 그리고 비용 효용 측면을 비교한 실험 내역입니다.
이번 오마카세 에서는 GraphRAG vs. LightRAG 를 살펴보는게 핵심이기때문에, RQ3,4 만을 중점적으로 이야기해보겠습니다.
RQ3,4 에서 활용한 지표는 다음과 같습니다. 많이 익숙하실텐데요. Microsoft GraphRAG 에서 VectorRAG 와 실험할 때 활용한 지표입니다.
i) Comprehensiveness: How thoroughly does the answer address all aspects and details of the question?
ii) Diversity: How varied and rich is the answer in offering different perspectives and insights related to the question?
iii) Empowerment: How effectively does the answer enable the reader to understand the topic and make informed judgments?
iv) Overall: This dimension assesses the cumulative performance across the three preceding criteria to identify the best overall answer.
RQ3. What specific advantages does LightRAG demonstrate through case examples in various scenarios?

LLM as judgement 결과입니다. 3가지 부문에서 모두 LightRAG가 우수하다는 평을 받았는데요. 각 부문마다 LightRAG가 우수하다는 리뷰의 핵심 키워드를 살펴보면 broader array of metrics including MAPK ... , not only covers a wide variety of metrics but also includes nuanced explanations of how some ... , empowers the reader more effectively by detailing ... 과 같은 요소들이 작용했음을 알 수 있습니다.
이러한 결과에 대해 논문 저자들은 다음과 같이 이야기합니다. "This success is due to LightRAG’s hierarchical retrieval paradigm, which combines in-depth explorations of related entities through low-level retrieval to enhance empowerment with broader explorations via high-level retrieval to improve answer diversity" low-level ,high-level retrieval 로 나누어 계층을 만들어서 활용한게 성공의 요인이였다. 이를 간접적으로 생각해보면 community-based traversal 에서 만들어진 계층대비 LightRAG에서 프롬프트와 KV store 를 활용한 계층이 더 우수하다라고 해석해 볼 수 있는데요.과연 비용도 그렇게 우수할까요? 다음 RQ4에서 이야기해보겠습니다.
RQ4. MODEL COST AND ADAPTABILITY ANALYSIS

Figure 2를 통해 GraphRAG 와 LightRAG 를 비교한 결과를 해석해보자면 다음과 같습니다.
GraphRAG:
- 1,399개의 커뮤니티를 생성하며, 그 중 610개의 레벨-2 커뮤니티를 정보 검색에 사용.
- 각 커뮤니티 보고서는 평균 1,000 토큰으로 총 610,000 토큰을 소비.
- 개별 커뮤니티를 순차적으로 탐색해야 해 수백 건의 API 호출이 필요, 검색 오버헤드가 큼.
- 새로운 데이터 추가 시 기존 커뮤니티 구조를 완전히 재구성해야 하며, 재구성에 약 1,399 × 2 × 5,000 토큰이 필요, 비용 비효율적.
LightRAG: - 키워드 생성과 검색에 100 토큰 미만을 사용하며, 단 1회의 API 호출로 작업 수행.
- 그래프 구조와 벡터 표현을 통합한 검색 메커니즘으로 초기 대량 데이터 처리가 불필요.
- 새 데이터 통합 시 기존 그래프에 바로 병합 가능해 토큰 및 오버헤드가 대폭 절감됨.
핵심은 다음과 같습니다.
- 효율성 비교: LightRAG는 GraphRAG보다 훨씬 적은 토큰과 API 호출로 검색 작업을 수행하며, 비용과 시간 효율성이 높음.
- 동적 데이터 관리: LightRAG는 기존 그래프를 유지하며 새 데이터를 손쉽게 통합하는 반면, GraphRAG는 모든 커뮤니티를 재구성해야 해 비효율적임.
- 비용 절감: LightRAG는 검색 및 데이터 업데이트 과정에서 GraphRAG 대비 훨씬 낮은 오버헤드를 제공.
이것저것 디테일도 작성하다보니 글이 길어졌네요. 오늘은 LightRAG에 대해 알아봤습니다. 텍스트 처리시 Recog 엔티티 추출하고 , Prof 프로파일링하고 그리고 Dedupl 중복제거을 통해 그래프를 설계하는 것. 이때, Profiling 시 엔티티, 엣지를 key-value 형태로 저장해서 다양한 entity 들과 결합할 때 key index만을 이용해서 효율적인 retrieval 한다는 점이 중요했습니다.
Dual-level 관점으로는 high-level , low-level query 를 나눌때 keyword prompt 를 활용하는것. 여기에서 keyword propmpt 에는 프롬프트에 kg_context 와 vector_context 를 함께 입력해 둘의 장점을 동시에 활용함으로써, RAG 시스템 완성도를 높였다는 점. 이 기존 GraphRAG 패러다임과 다른점이라고 할 수 있었습니다.
특히, 대중들에게 많이 알려진 Microsoft GraphRAG과의 차별점을 리마인드해보자면 community-based traversal 과 다르게 LightRAG는 high-level 관점과 description 관점을 결합해 추상 레벨이 높은 거시적인 질문이 들어왔을때 답변을 한다는 점.이라고 할 수 있겠습니다.
Entity extraction 프롬프트에선 동일하게 continue 관점을 가지고 있지만, 위처럼 추상레벨이 높은 답변을 하기위해 소요되는 비용들이 절약됨으로써 상대적으로 빠르고 저렴하게 GraphRAG 효용을 모두 활용할 수 있다는게 핵심입니다.
GraphRAG 논문들을 마주하다보면 "프롬프트를 어떻게 설계해서 온톨로지를 추출했을까?" 라는 생각부터 드는 요즘입니다. 그만큼 데이터 통합시 발생하는 다양한 데이터 메타들을 잘 추출하고 엔티티에 결합했는지가 중요하다라고 느끼고 있고, GraphRAG 트랜드도 그런 방향으로 가고 있음이 느껴지고 있기 때문인데요.
정답은 없는 영역이라 생각합니다. 여전히 도메인 지식이 중요하고 이를 어떻게 프롬프트에 녹여내는지가 GraphRAG 성능의 핵심 중 하나가 되지 않을까 생각하네요.
[Contact Info]
Gmail: jeongiitae6@gmail.com
Linkedin : https://linkedin.com/in/yitaejeong