25년 6월 5주차 그래프 오마카세
안녕하세요 GUG입니다.
어느덧 내일 GUG 7번째 세미나가 진행됩니다. 5회차 세미나부터 늘 '온톨로지' 라는 키워드를 가지고 세미나를 진행했는데, 유독 이번 세미나는 관심과 신청이 더 많았던게 느껴졌네요. 아마 팔란티어 기업의 활약이 주된 이유이지 않을까 싶네요. 좋은 현상이라 생각합니다. 그래프란 분야가 온톨로지 덕분에 빛을 발하는 시기가 되는거 같아 더더욱 열심히 하게되는 동기가 되는거 같습니다.
오프라인 세미나는 아무래도 공간 대관 , 연사자 모집 , 콘텐츠 구상 , 기획 등 여러 요소들을 고려해야 하다보니 이벤트를 구성하는 운영진 입장에선 큰 부담이 되기 마련입니다. 때문에, 한 번 세미나를 개최하는데 저도 가끔 주저할 때가 있곤 합니다. 그 원인이 무엇일까 하니 결국 위에 언급한 요소들이라 생각되었네요.
때문에, 그 원인을 최소화하고 그래프 지식전파를 위해 이전부터 만들어둔 그래프 유튜브 채널에서 매 달마다 그래프 관련 연구자 및 현업에 계시는 산업계 분들을 모셔서 미니 세미나를 진행할 예정입니다. 오프라인으로는 자주는 개최하진 못하지만, 온라인으로는 오마카세와 유사하게 주기적으로 지식을 교류하는 자리를 마련하고자하오니, 구독 좋아요 알림설정 부탁드립니다..!

Community Takes on the Future of Graph Learning
Blog link : https://substack.com/inbox/post/166241782
- 매주 수요일마다 그래프 관련 연구 결과를 공유 및 토론하는 그룹 커뮤니티 GLOW (Graph Learning on Wednesdays)에서 그래프 학습의 미래에 대한 내용 시리즈를 블로그 게시물에 요약해두어 공유해드립니다. 다음 게시물에는 많은 유명 연구자 (Michael Galkin, Bastian Rieck etc)의 의견들이 담겨있기에 오마카세 여러분들께 유의미한 인사이트가 될 수 있을거라 생각합니다.
- 그래프 학습이 LLM, Agent 및 현재 AI 트렌드에 메인스트림을 잡고 있는 연구 도메인에 비해 특정한 정체성의 위기를 겪고 그 매력이 부족한 이유에 대한 의견이 다양하게 담겨 있습니다. 이전 오마카세에서 그래프 학습이 왜 AI 트렌드에 편승하고 있지 못하는가에 대한 게시글과 연결되는 부분이며, 해결을 위한 많은 관심이 들어가있는 부분입니다.
- 부분적으로는 새로운 연구자들을 끌어들일 수 있는 "Killer" application이 없다는 점에 중점을 둡니다. 새로운 세대의 LLM과 Agent로 진정한 과학적 발견을 수행할 수 있을 때 아무도 GCN/GAT/Graph Transformer의 또 다른 변형이나 색다른Positional Encoding 또는 loss 함수 등의 근본적인 고민이 부족하며, 그로 인해 다른 연구자들로부터 필요성을 충분히 제공하지 못하고 있다는 사실을 의논하였습니다.
- 해당 문제에 대한 견해들은 위의 커뮤니티 글 또는 Position paper를 통해 더욱 자세히 나와있으니 직접 확인해보시고 읽어보면서 지속적으로 같이 고민해보고 생각해보면 좋을 것 같습니다.
Time Series Forecasting with Graph Transformers
Blog link : https://kumo.ai/research/time-series-forecasting/

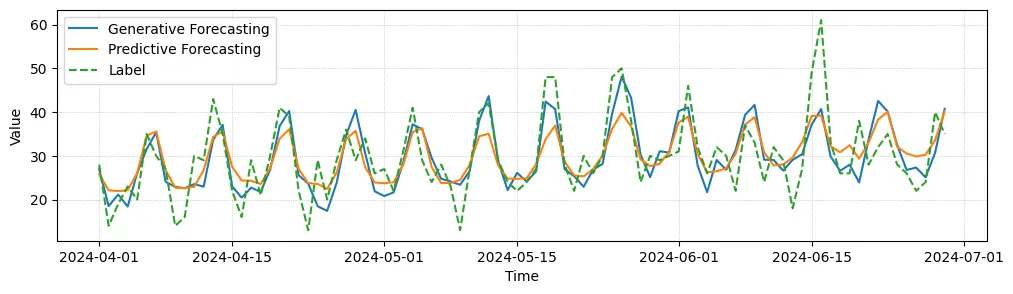
- 최근 Kumo.AI에서 관계형 DL에서 그래프 Feature가 시간에 따라 변하는 Time dependency를 처리하는 것 대한 흥미로운 내용을 게시글로 공유하였습니다.
- 실제 어플리케이션 상에서 중요한 타임 패턴이 다양한 데이터 소스 상에 상호적으로 연결되어 존재하는 경우가 많으며 자연스러운 그래프 구조화를 통해 예측 가능한 주요 신호를 잠재적으로 캡처하는 단순 아키텍처를 위와 같이 설계하였습니다. 관계형 DL 패러다임에 따라 부분 그래프 샘플링을 통해 구조화된 하위 그래프를 Graph Transformer를 통해 인코딩 후, 해당 임베딩을 과거 일련의 시퀀스 정보들과 조건화하는 Past Encoder (1D-CNN)의 임베딩과 함께 Transformer 계열 디코더에 입력되어 미래 시계열 시퀀스를 예측합니다.
- 일반적으로 시계열 예측은 입력 시퀀스에 대한 미래 예측의 매핑 모호성으로 인한 확률론적 작업으로 바라볼 수 있습니다. 따라서 저자들은 함수 (Regression Forecasting) 대신 무작위 변수에 대한 분포를 모델링하는 기법 (Generative forecasting) 의 차이점에 대한 논의와 향후 시사점을 제공합니다.
- Regression forecasting은 그래프 Feature 이력들이 암시적으로 가우시안 분포를 따른다고 가정하여 regression head에 MLP를 통해 단순하게 모델링하여 효율적인 예측 패러다임을 제공할 수 있다고 합니다. 하지만 Mean Collapse 현상이 발생하기 쉬우며 실제로 가우시안 분포로부터 멀리 떨어진 경우 더 높은 frequency forecast를 smoothing할 수 있습니다. 다음 문제를 완화하는 여러가지 대안 방법들이 존재하지만 주어진 시계열 데이터에 대한 엄격한 가정이 요구되어집니다.
- 따라서 저자들은 확산 모델을 대신 훈련시키는 Generative Forecasting 기법을 사용합니다. 다음 접근으로부터 어떠한 가정의 필요하지 않게 되며, 여러번의 샘플링을 통해 경험적인 통계량을 근사적으로 얻어낼 수 있음을 발견하였음을 언급합니다. 실험적으로도 실제 레이블과 유사한 결과를 얻었음을 보이고 있습니다.
- 관계형 DL 방식을 통해 관계형 데이터베이스(Relbench)에서 시계열 패턴을 갖는 상호 연결된 데이터 소스에 대한 그래프 구조를 자동으로 추출할 수 있다는 이점과 Graph Transformer 기반 시계열 예측 문제의 적용 가능성을 보여주고 있습니다. 전체 그래프에 국한되지 않고 Temporal Sampler를 통한 기능적 하위 그래프의 노드 집합에 대한 임의의 예측 작업들에도 적용할 수 있음을 언급하며 그 효율성을 제시합니다.
[Contact Info]
Gmail: jhbae1184@akane.waseda.jp
Twitter (X): @jhbae1184
RAG vs. GraphRAG: A Systematic Evaluation and Key Insights
https://arxiv.org/pdf/2502.11371
정이태
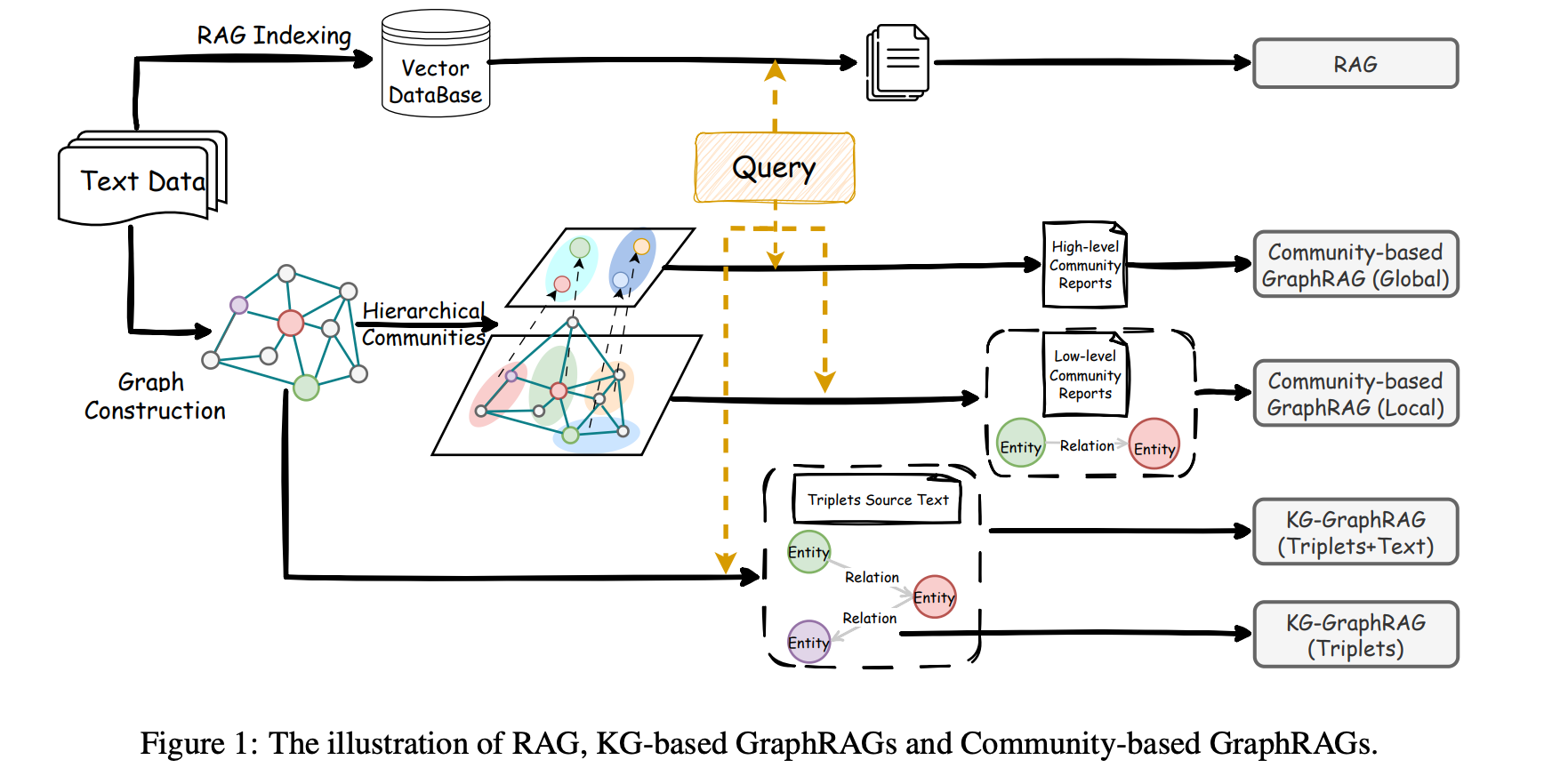
2.GraphRAG vs. RAG systematically analysis reference가 필요하신 분들.
3.GraphRAG 개념들이 혼재되어 있는데, 이를 두 가지 카테고리로 나누어, 한 번 정리하고 싶으신 분들.
안녕하세요 정이태입니다.오랜만에 제 고민들을 속 시원하게 해결해준 논문을 발견했습니다. msu , oregon college & meta 에서 작성한 논문입니다. 오마카세에서는 큰 틀에서 이야기만 드릴테니, 날 잡고 모두 읽어보시는걸 추천드립니다.
먼저 논문 초록에 다음과 같은 문구가 인상적이였는데요.
Our results highlight the distinct strengths of RAG and GraphRAG across different tasks and evaluation perspectives.
Additionally, we provide an in-depth discussion of the shortcomings of current GraphRAG approaches and outline directions for future research.
RAG와 GraphRAG 각각 잘하는게 무엇인지를 정의하고 이를 실험했다. 또한 GraphRAG내에서도 여러 approach 가 있는데, 이또한 각각 결과가 어떠했는지 실험해보았다. 그리고 어떠한 한계가 있었다는 문구가 흥미를 끌었습니다. 이렇게까지 이야기한 논문을 그간 만나지 못했던 것도있고, 메타 소속인 저자들도 있었기에 산업계ㆍ학계 라면 이럴수도 있겠다? 라는 생각에 스키밍을 시작했고, 이렇게 여러분들에게 전달을 드리게 되었네요.
그럼 위에 언급한 내용들을 논문에서 풀어냈는지 한 번 같이 살펴볼까요?
Introduction 에 다음과 같은 이야기가 있습니다.
To bridge this gap, we systematically evaluate the performance of RAG and GraphRAG on general text-based tasks using widely adopted datasets, including Question Answering and Query-based Summarization.
그간 제가 봐왔던 논문들과 다르게 'widely adopted dataset' & task 를 2개(QA , query-based summarization) 로 나누어서 말 그대로 systematically evaluate 합니다. 때문에, graphRAG system 구축시 고민할 부분들을 속 시원하게 긁어주는거죠. 예를 들자면, 기존 RAG 파이프라인에서 무엇을 잘하고 있고 무엇을 잘 못하는지를 명확히 정의를 내리기 위한 레퍼런스가 필요한데, 본 논문이 그 레퍼런스가 되는거죠.
Our findings reveal that RAG and GraphRAG are complementary, each excelling in different aspects. For the Question Answering task, we observe that RAG performs better on singlehop questions and those requiring detailed information, while GraphRAG is more effective for multi-hop questions.
In the Query-based Summarization task, RAG captures fine-grained details, whereas GraphRAG generates more diverse and multi-faceted summaries. Building on these insights, we investigate two strategies from different perspectives to integrate their unique strengths and enhance the overall performance.
여기까진 여타 다른 GraphRAG 포스팅이나 논문들과 별반 차이는 없습니다. RAG 는 single hop 잘하고, GraphRAG는 multi-hop 잘한다. RAG는 fine-grained detail , GraphRAG는 diverse & multi-faceted summaries 잘한다. fine-coarse 관점도 역시 비슷하구요. 그럼에도 제가 관심이 생겨서 여러분에게 공유하려고 했던 이유는 다음 요소들 때문이였는데요.
#1. RAG wrong/correct & GraphRAG wrong/correct
Related work에서 다음과 같은 이야기를 합니다.
> It remains unclear how GraphRAG performs on general text-based tasks compared to RAG. More importantly, when and how should GraphRAG be applied to such tasks for optimal effectiveness? Our work aims to bridge this gap by systemically evaluating GraphRAG and comparing it with RAG on general text-based tasks.
아픈 부위를 꼬집습니다. RAG가 잘하는 부분이 있고, GraphRAG 가 잘하는 부분이 있다곤하는데, 이를 실증적인 결과 데이터와 함께 증빙하는 부분이 늘 아쉽곤 했는데요. 논문에서는 RAG는 fact-based queries 를 잘하고, GraphRAG 는 reasoning based queries that involve chaining multi facts together 를 잘한다 라는 가정을 하고 실험을 했다고 합니다. 그 결과가 다음 confusion matrix로 나타났구요.
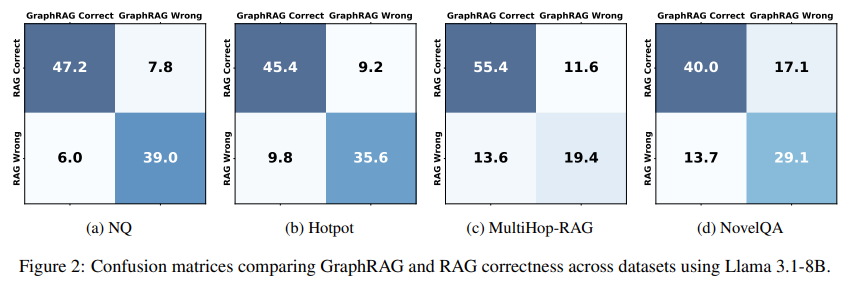
참고로, (a)~(d) 의 task들은 Question Answering 과 Query-based summarization 중 question answering에 속한 task들이구요. 각각 (a) Natural quesiton은 single-hop QA를 대표하는 데이터셋, (b) Hotpot 은 multi-hop 데이터셋, (c) multihop-RAG 는 multiple documents with metadata 에 retrieval & reasoning 를 위한 데이터셋 그리고 NovelQA는 long-text understanding 을 위한 데이터셋 입니다. 각각 성질이 모두 다른 데이터셋을 가져와서 실험을 진행했습니다.
#2.모델 크기를 마냥 키우는게 중요하지 않다. RAG와 GraphRAG selection & integration hybrid 전략을 고려해보는 선택지도 있으니, 이 관점도 적용해보자.
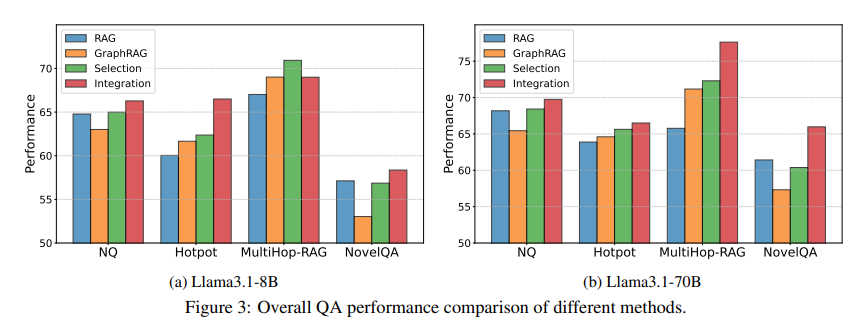
네 위 차트는 Llama3.1 8B와 70B 활용해서 실험한 결과입니다. 당연히 파라미터가 큰 모델 성능이 좋을 것이라 생각드시겠죠. 당연합니다. 하지만, 70B와 8B의 운용 비용 차이는 꽤나 크죠..? 뿐만아니라, 70B는 multi-gpu 를 활용해야하기에 인프라 엔지니어링까지 고려하며 추가적인 고려사항이 더욱 증가하기 마련입니다. 때문에, 이런 비용을 모두 상쇄할만한 가치가 있어야 70B를 활용한 multi-hop query 에 대한 당위성이 생기는거죠. 다음 표와 포스팅의 일부는 비용 관련 내용이니, 참고하시면 좋을거 같습니다.
| 항목 | LLaMA 3.1 8B | LLaMA 3.1 70B |
|---|---|---|
| 최소 GPU 요구 | 1x A100 40GB 또는 RTX 4090 | 2~4x H100 80GB 또는 8x A100 80GB |
| 추론 속도 (1K tokens) | 100~300 ms | 1~3초 이상 |
| GPU 비용 (AWS 기준) | ~$3/hr (A100 기준) | $8~$16/hr × N개 (H100 기준) |
| 1회 추론 비용 (1K tokens) | $0.005 | $0.04~$0.08 |

다시 돌아와서, selection / integration 에 관해 이야기합니다. 쿼리가 들어왔을때 과연 RAG 를 사용하는게 좋을지 GraphRAG 를 사용하는게 좋을지 아니면 둘 다 사용하는게 좋을지에 대한 고민이 있을텐데요. 그 고민에 대한 힌트를 줄 수 있는 결과라 생각합니다.
유심히 지켜보시면 좋을 부분은 다음 세 가지 부분입니다.
1.차트 양상은 모두 비슷한데, 유독 8B , 70B 다른점이 보이는 부분인 multi-hop 실험 부분입니다. 8B 로는 integration 이 selection 보다 성능이 좋지 않았는데, 반대로 70B에서는 integration이 selection 보다 성능이 좋습니다. 그 이유가 무엇인지 곰곰이 생각해보면 좋을거 같네요. (힌트, 오히려 정보가 노이즈가 될 수 있음.)
2.대체적으로 single hop, long understanding 에서는 RAG 성능은 선방하고 있음. 반대로 hotpot 이나 multi-hop query에서는 GraphRAG 성능이 선방하고 있음.
3.selection / integration 에 따라 차이가 나는 부분을 우선 살펴보고, 이를 판별하는 기준인 prompt를 살펴보기. RAG 는 Fact-based query 라고 가정하고 GraphRAG 는 Reasoning-based query라고 가정하였음. 이 classification이 결과와 무슨 인과성이 있는지 생각해보기.(힌트, graphrag 의 최대 난제인 incomplete subgraph)

#3.GraphRAG들간 비교
사실 GraphRAG 논문들을 보면 웬만하면 our approach 가 좋음을 이야기합니다.때문에, 이를 카테고리화해서 비교해서 보기엔 Bias가 다소 있었습니다. 하지만, 본 논문은 systematic evaluation 이 핵심이기에 그런 Bias 가 없이 실험을 진행합니다. KG-GraphRAG 를 LightRAG, Community-GraphRAG 를 Microsoft 의 GraphRAG 로 보셔도 무방합니다.
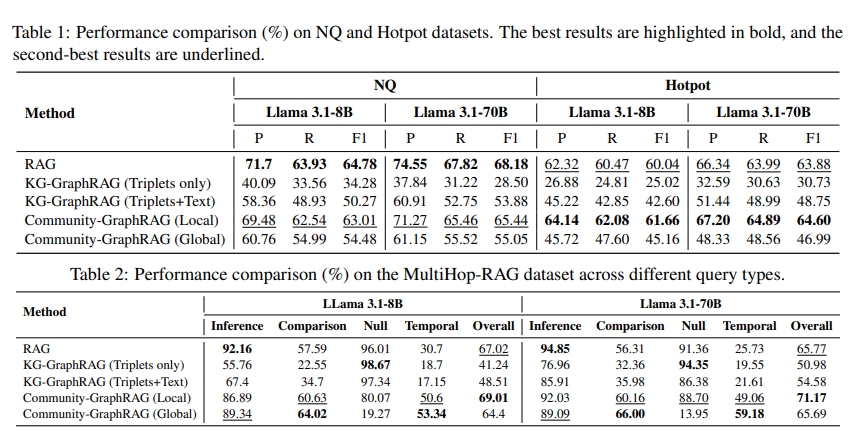
Table1의 결과는 당연해보이네요. Single-hop query가 많은 NQ 데이터셋 특성상 RAG가 잘합니다. 제가 늘 강조드린 것처럼 GraphRAG 를 도입 전 문제가 무엇인지 즉, 어떤 쿼리의 답변 성능이 잘 나오지 않는지를 생각해보자! 라는 말이 생각나는 대목입니다. Hotpot 같은 경우엔 KG-GraphRAG가 오히려 RAG 보다 못할때가 많습니다. 대다수가 못합니다. Community-GraphRAG(Local) 가 가장 성능이 좋긴 하지만, RAG와 비등비등합니다. 여기에서 의미하는 바가 무엇일까요? 바로 hierarchical 입니다. hierarchical 을 반영한 쿼리인 global query report 보다 local query report 의 차이를 생각해보시면 좋을거 같네요.
Each community is associated with a corresponding text summary or report, where lower-level communities contain detilaed information from he original text. the higher-level communities further provide summaries of the lower-level communities.
저 자신도 놓치고 있던 부분이 많았다는걸 깨닫게 해준 정말 좋은 논문이였습니다. rag 파이프라인에서 graphrag 파이프라인으로 넘어가실때 생겨날 이슈들을 거의 커버했다 라고 할 수 있을만큼 고려사항들을 많이 짚었습니다. 물론, 마지막에 limitation 으로 graph construction이 있고, 실제 meta -> graph process 는 어쩔수는 없겠지만요. 하지만, system view로 보기엔 거듭 언급하지만 정말 좋은 논문이라 생각하네요. 도움이 되었으면 합니다.