25년 5월 4주차 그래프 오마카세
드디어 GUG 7회차 세미나가 개최됩니다.
어렵사리 연사분들, 장소를 대관하느라 오래걸렸네요. 오마카세 식구분들에게 우선 이 소식을 전달하고 싶어 선공개합니다. 한정된 인원들만 참여가 가능하다보니, 신상이 불분명하신분들은 부득이하게 참여가 어려우실 수도 있습니다. 신청시에, 되도록 소속을 명확히 기입해주시면 감사하겠습니다.
추가로 정말 꼭 참여를 해보고 싶다 하신분들은 graphusergroup@gmail.com 으로 메일을 전달해주시면, 우선으로 자리를 배치해보도록 하겠습니다. 많은 참여 부탁드리겠습니다.
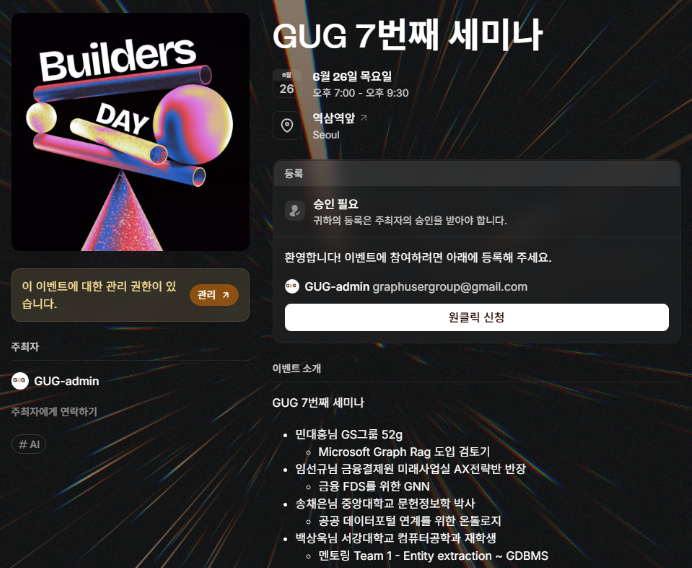
이벤트 링크 : https://lu.ma/69ymean7
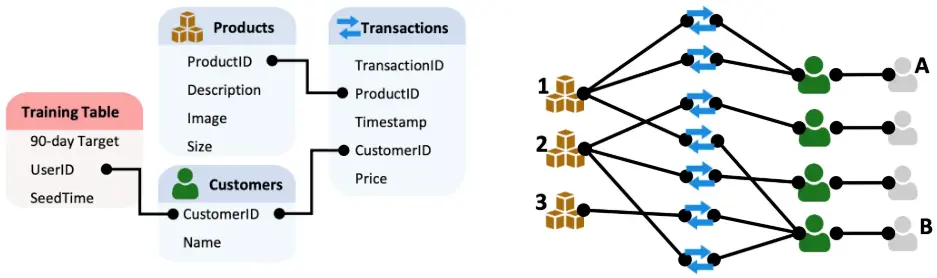
Relational Graph Transformers : A New Frontier in AI for Relational Data
Blog link : https://kumo.ai/research/relational-graph-transformers/?trk=feed_main-feed-card_feed-article-content
- 이번 주 오마카세에서는 다양한 기업 블로그에서 발견한 그래프 관련 설명들을 모아 간단하게 정리하여 보내드리고자 합니다. 이런 글들을 찾아 읽어보면 아카데미에 있는 학생 입장으로서 해당 기업들이 바라보는 미래적 전망과 흐름 및 기술 발전 트렌드를 겉핥기식으로나마 파악할 수 있어서 정말 좋은 것 같습니다.
- 첫번째 블로그는 저번 오마카세에서도 소개해드렸던 Kumo.ai에서 작성한 RelBench용 관계형 그래프 트랜스포머 관련한 방대한 게시물을 공유해드립니다. 비즈니스 상에서 많이 활용되고 있는 관계형 데이터들에 매우 적합한 상호 연결된 그래프들을 방대하게 처리할 수 있는 그래프 트랜스포머 아키텍처를 소개하며 기존 GNNs의 도입 어려움 등을 해결하고 광범위한 피처 엔지니어링 및 복잡한 파이프라인 설계의 불필요성을 제거하였다고 합니다. 또한 GNN에 torch.complie 모듈을 활성화하여 학습 속도를 대략 30% 향상시키는 방법에 대한 보다 기술적인 방법을 작성해두었습니다. 이는 이 게시글을 확인해보시면 좋을 것 같습니다.
- 해당 게시글에서는 관계형 그래프 변환기의 작동 원리, 관계형 그래프 변환기가 기업 데이터 과제에 특별히 적합한 이유, 그리고 관계형 그래프 변환기가 고객 분석 및 추천 시스템부터 사기 탐지 및 수요 예측에 이르기까지 다양한 애플리케이션을 어떻게 혁신하고 있는지를 설명해주면서, 관련 기업에서 종사하시는 선생님들께 좋은 인사이트를 제공하고 있습니다.
- 자세한 이해를 위해, 해당 게시글을 읽으시기 전에 그래프 트랜스포머란 무엇인가에 대한 이전 게시글을 참고하신다면 더욱 유익할 것으로 생각됩니다. 많은 지식과 실업무 등에서 도움이 되셨으면 좋겠습니다.
FutureHouse Platform: Superintelligent AI Agents for Scientific Discovery
Blog link : https://www.futurehouse.org/research-announcements/launching-futurehouse-platform-ai-agents

- 과학 연구를 자동화하고 발견의 속도를 가속화하여 인류가 질병에 대한 치료법, 기후 변화에 대한 해결책, 그리고 종 성장을 가속화하는 다른 기술을 찾을 수 있도록 하는 AI 과학자를 양성하는 목표를 갖는 AI 비영리 연구 기관인 FutureHouse에서 재밌는 게시글을 작성해둔 것을 발견하여 공유드립니다.
- 제목 그대로 과학적 발견 과제를 위한 (화학 분야쪽의) 슈퍼인텔리전트(?) AI 에이전트 플랫폼을 발표하였는데요. 실제로 다음 플랫폼은 Crow, Falcon, Owl, Phoenix의 4가지 조류 이름을 갖는 서로 다른 멀티모달 에이전트를 결합하여 간결 검색(Concise research), 심층 검색(Deep search), 선례 질문 (Precedent question) 및 분자 합성(Molecular Synthesis)를 담당하는 역할을 단번에 수행할 수 있음을 언급합니다.
- 해당 에이전트는 사용자가 보유한 모든 텍스트 및 이미지를 입력받아 화학 분야의 워크플로를 자동화하고 방대한 전문적인 과학 데이터베이스에서 정보를 검색할 수 있습니다. 검색된 문서 및 정보들의 퀄리티는 지속적인 평가를 통해 뛰어난 결과를 보장할 수 있을 정도라고 합니다.
- 연구자의 워크플로우를 원활하게 하기 위해 웹 인터페이스 외에도 API를 제공하고 있습니다. 이러한 에이전트들을 유용하게 연결시켜 활용함으로써 더욱 인상적인 과학적 발견과 발전의 속도를 향상시킬 수 있을 것을 기대한다고 하네요.
- 다음 데모 영상을 같이 참고해보시면서 해당 플랫폼에 관심 있으신 화학 분야 종사자 선생님들께서는 확인해보면 좋을 것 같습니다.
The best usage of network science of 2025, Bocconi Univ in Millan
Blog link : https://www.unibocconi.it/en/news/network-conclave
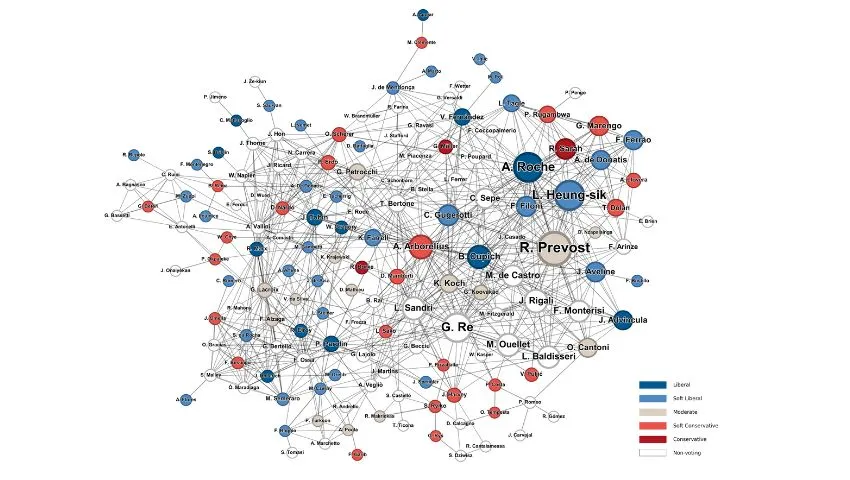
- 이탈리아 밀라노의 보코니 대학교 연구진들은 2025년 네트워크 과학을 가장 효과적으로 활용한 사례를 해당 게시글로 발표하였습니다. 주제는 `In the Network of the Conclave', 즉 교황 선출을 위한 중심성 측정값 기반 예측 문제에 포커스를 맞추었는데요.
- 해당 연구진들은 바티칸 추기경들의 직무, 비공식적 관계, 영적 계보(Spiritual genealogies) 등의 복합적인 관계성에 따른 그래프를 분석하고, PageRank와 같은 그래프 고유벡터의 중심성(Eigenvector centrality), 소규모 네트워크에서 적용 가능한 매개 중심성(Betweenness centrality), 그리고 몇 가지 클러스터링 지표 등 다양한 중심성 측정값을 계산하여 예측 결과를 내놓습니다.
- 결과적으로 실제 선출된 교황이 예측 결과의 상위권에 놓인 것을 토대로 지식 그래프의 네트워크 과학 분야에 있어서 그래프 분석 도구의 유용성이 두드러진 사례로 바라보면 좋을 것 같습니다.
[Contact Info]
Gmail: jhbae1184@akane.waseda.jp
Twitter (X): @jhbae1184

안녕하세요 정이태입니다. 엊그제 시작했던거 같은데, 벌써 2주 가량 남았네요. 시간 정말 빨리 가는거 같습니다. 저번주차부터 멘티분들간 본격적인 교류가 이루어져 있고, 각 팀별로 결과물들이 나오고 있습니다. 이럴때 제가 기여할 수 있는 부분은 두 가지 정도라고 우선 생각을 했네요.
첫번째는 문제 발생했을 때 어떤식으로 접근하면 좋을지 조언을 드리는 것 두번째는 멘토링 팀내에서 확장하여 팀외에 있는 인원분들로부터 멘토링을 받는 것입니다. 그래서 이번주에는 방금 말씀드린 두 가지를 공유드려보려고 합니다.
각 팀별 디스커션 및 진행상황 공유
Team1
지식그래프 구축이 주 역할인 Team1 은 이번주에 엔티티의 일관성에 대해 고민이 많았어요. 각 entity prompt 마다 추출되는 entity 가 결과값이 대동소이하나, 가끔은 달라지는 부분이 있기에 이를 어떻게 핸들링하면 좋을지를요. 저는 그래서 entity prompt 전에, 추출되는 chunk size 와 entity 갯수들을 비례해보며 entity extraction 을 점검해주는 LLM prompt까지 만들어보면 어떨까 하는 제안을 드렸어요.
chunk 사이즈가 너무 크다고 해서 좋은 entity 들이 나온다는 보장이 없고, 너무 적다고 해서 나쁜 entity 들이 나온다는 보장 또한 없거든요. 각 문서마다 성격과 양이 모두 다르기 때문에, 이를 Team3 의 페르소나와 chunk 사이즈를 500, 1000, 1500 으로 나누어 실험을 해보면 결과가 다를 것이다 라는 이야기를 나눴어요.
LightRAG issue 에도 Team1과 유사한 고민인 Entity extraction을 가진 유저가 있었어요. 여기에서는 Chunk similarity 기반으로 knowledge graph를 만드느냐, SPO Triple 관점으로 만드느냐 두 방법 중 하나를 고민하고 있던거 같아요. 이런 부분을 해소하며 자발적으로 오픈소스에 기여하는게 본 멘토링 진행 취지 중 하나이기에 이슈를 전달드리고, 우리의 방식을 한 번 여기에 기재해보면 좋겠다 라는 피드백을 드렸어요.
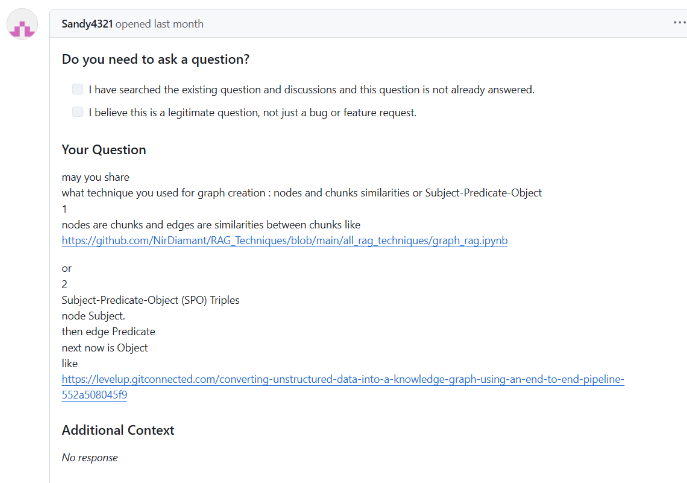
덤으로, 위 유저가 공유해준 링크 게시물에서 Entity Resolution 에 대한 관점이 있어서 도움이 될것 같다 생각해서 공유드립니다.

Team2

Team2 속해있는 민우님께서 DozerDB에 있는 데이터를 MCP 연동하여 Agent를 구현하였고, 그 결과물을 공유해주셨어요. 우선 supply chain graph만 진행하였고, USTR graph를 연동해야할 차례인데 LightRAG 코드에 해당 모듈을 구현하기엔 시간이 촉박한지라 multi-agent 를 생각하고 있어요.
USTR agent 의 결과물을 supply chain agent 에게 전달해서 특정 발언이나 공식 정책 발표가 supply chain에 어떤 영향을 주었는지를 살펴보는 선/후 관계를 지닌 multi-agent design을요. 이때, 그럼 중요한게 무슨 기준으로 hand-off 하는지인데요. 이 내용은 흡사 routing과 유사합니다.
특정 기준 없이 정보를 전달하다보면 오히려 노이즈로 인지할 경우가 있거든요. 또한 해당 시점 기준으로 전후 몇일을 가져다주면 좋다던지 혹은 공급망 내에서도 전체 공급망 데이터가 아닌 특정 데이터와의 연관성을 분석하는 데이터가 필요하다던지요.
이러한 기준에 따라 Agent 퀄리티가 좌우될 거라고 생각되기에, 고민해보면 좋겠다 라는 이야기를 나눴어요.
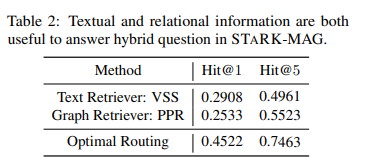
Router Given a question q, the LLM router performs question routing to determine the selection and usage of the retrieval module. More specifically, the router first identifies the relational aspect, i.e., topic entities Eˆ and useful relations Rˆ based on the types of entities TE and the types of relation TR using few shot examples (Brown, 2020). The router then makes the selection st , determining whether to use a text or a hybrid retrieval module. IdentifyingEˆ and Rˆ before determining st improves the quality of st . For example, if there is no entity extracted Eˆ = ∅, a text retrieval module is a better option.
Team2에서 고민하고 있는 부분인 Agent Routing 관련해서 다룬 논문이 있어 공유드렸어요. 여기에서도 optimal routing 을 중요시 여기고, 실험한 결과 Text , Graph Retrieval 대비 최소 20% 가까이 성능이 향상됨을 보여주었어요. 그 routing 기준은 위 인용문에 나와있구요.
Team3

Team3에서는 그래프 기획이 어느정도 완료가 되었고, 이제 GraphRAG를 활용하는 페르소나기반 Text Query 와 Graph Query 를 만드는 중입니다. Team3 분들이 각각 supply chain (domain graph) 와 USTR (lexical graph) QA 데이터셋을 만들고 이 데이터셋을 검수하는 역할까지 배분이되어 진행되고 있는중입니다. 위 그림은 Graph Evaluation 에서 포함되어야할 내용들인 Multi-hop Question 대상 vector vs. graph가 진행된 내용입니다. Team 3 지민님께서 구현해주신 내용이구요. 그림 살펴보신 바와 같이 Graph가 힘을 못내고 있는 상황입니다. 이때, 눈치 채신분들이 계실거라 생각되네요. 바로, 설계된 Knowledge Graph 와 Graph Retrieval 이 당연하게도 서로 영향을 줄것이다 라는 점을요. 때문에, 저는 오히려 지금 이 상황이 당연하고 개선할 부분이 보여서 더욱 멘티분들에게 동기를 부여하지 않을까 하는 생각입니다. Team 1에서 만든 entity extraction 퀄리티와 Multi hop 퀄리티를 비교해보는 것만으로도 실력이 많이 상승되기 때문이죠.
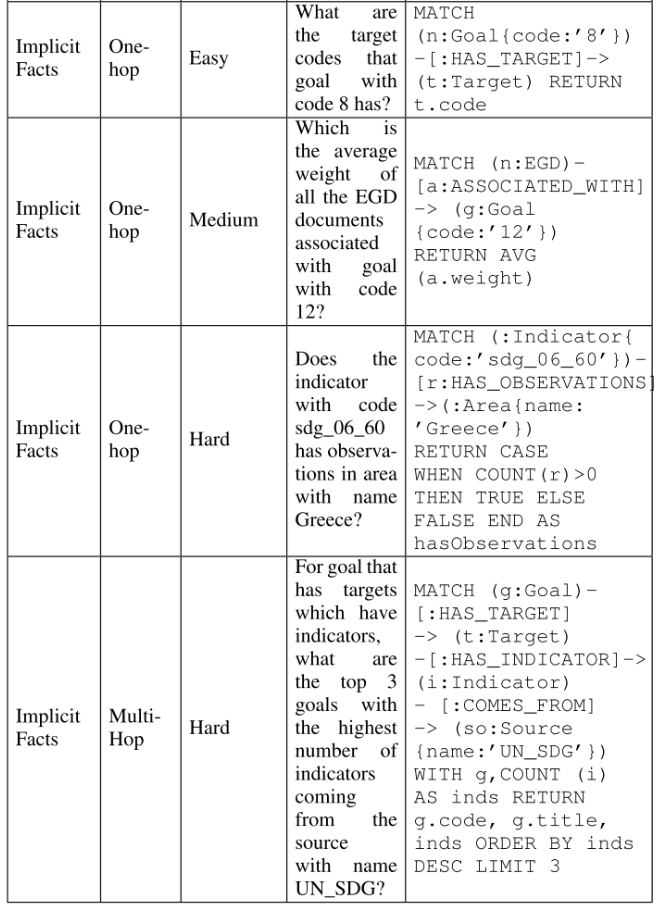
위와 유사하게 sublevel(Retrieval 개체), difficulty, text query 기반으로 각각 Explicit Fact, 그리고 이를 조회하기 위한 Cypher query 로 구성되어 있는 논문을 참조하시면 좋을거라 생각되어 전달드렸어요. (위 논문은 이외에도 Text2cypher 와 LLM model 퀄리티 관계등 중요하고 흥미로운 내용이 많아서 한 번 꼭 정독해보시는걸 추천드려요.)
송채은 박사님 리뷰
멘토링 제목이 온톨로지 based LLM 개발 이지만 아쉽게도 저는 온톨로지 전공을 하지 않았습니다. 실무를 위해 온톨로지 관점을 활용할 뿐, 온톨로지 이론에 대한 깊이가 얕습니다. 또한, 엔지니어링 과 GDBMS 관점으로 접근하기에 제가 놓친 부분이 많을거라 생각되어 온톨로지를 전공하신 박사님을 어렵사리 모셨어요. 핵심이라 생각되는 피드백 몇 가지를 말씀드려보자면 다음과 같습니다.(자세한 내용은 GUG 세미나에서!!!)
1.Ontologist인 송채은 박사님은 어떻게 프롬프트 엔지니어링을 하시는지?
-> .rdf 파일을 entity extraction에 넣는다 혹은 필요하다라고 생각되는 구조체를 ontology example 라고 간주하고 넣는다. (이 부분에서 저는 이 생각을 왜 못했지 감탄했습니다. token 수는 )
2.Cypher 와 SPARQL 차이를 어떻게 생각하시는지?
-> GDBMS , Graph data model 의 차이. 즉 LPG 와 RDF를 질의하는 언어 관점으로 접근하는편. LPG는 그래프 모델을 신속하게 구축하는데 유리하고 RDF 는 데이터 표준들을 가져와서 customization 하기에 편리하다. from scratch 이느냐, data standard 부터 시작하느냐 의 차이라고 생각함.
3.Entity prompt 로부터 추출된 Entity들이 과연 잘 추출된 Entity인가를 어떻게 판단하시는 편이신지?
-> SKOS 데이터 모델을 표준으로 삼아서 내부에 instance / class 를 정량화해보고 그 정량화된 기준으로 Entity (ontology) 품질을 평가하는 편이다.
맛있는 그래프 인사이트 였을까요? 이번 주도 다들 고생많으셨습니다. 다가오는 주도 좋은일만 가득하시길 바라겠습니다. 그럼 다음주에 뵙겠습니다.