25년 11월 1주차 그래프 오마카세
Verifying Chain-of-Thought Reasoning via Its Computational Graph
Verifying Chain-of-Thought Reasoning via Its Computational Graph
Current Chain-of-Thought (CoT) verification methods predict reasoning correctness based on outputs (black-box) or activations (gray-box), but offer limited insight into why a computation fails. We introduce a white-box method: Circuit-based Reasoning Verification (CRV). We hypothesize that attribution graphs of correct CoT steps, viewed as execution traces of the model’s latent reasoning circuits, possess distinct structural fingerprints from those of incorrect steps. By training a classifier on structural features of these graphs, we show that these traces contain a powerful signal of reasoning errors. Our white-box approach yields novel scientific insights unattainable by other methods. (1) We demonstrate that structural signatures of error are highly predictive, establishing the viability of verifying reasoning directly via its computational graph. (2) We find these signatures to be highly domain-specific, revealing that failures in different reasoning tasks manifest as distinct computational patterns. (3) We provide evidence that these signatures are not merely correlational; by using our analysis to guide targeted interventions on individual transcoder features, we successfully correct the model’s faulty reasoning. Our work shows that, by scrutinizing a model’s computational process, we can move from simple error detection to a deeper, causal understanding of LLM reasoning.
Meta Researchers Develop AI Reasoning Verification Method | Raphaël MANSUY posted on the topic | LinkedIn
FAIR Meta: Verifying Chain-of-Thought Reasoning via Its
Computational Graph ... When AI Shows Its Work, Can We Trust the Math? Ever watched a student solve a math problem step-by-step, only to spot the exact moment their reasoning goes off track? Researchers at Meta just figured out how to do this with AI models—and the implications are fascinating. 👉 Why This Matters Large language models like GPT and Claude can now “think out loud” through chain-of-thought reasoning, showing their step-by-step work. But here’s the problem: sometimes their reasoning looks convincing while being completely wrong. Current verification methods can only tell us IF something went wrong, not WHERE or WHY. 👉 What They Built The team created Circuit-based Reasoning Verification (CRV)—a white-box method that analyzes the actual computational pathways inside AI models during reasoning. Think of it as creating a “brain scan” of the AI’s thought process. Their approach: - Replaces standard model components with interpretable “transcoders”
- Maps how information flows between different parts during each reasoning step
- Extracts structural fingerprints that reveal computational patterns
- Trains classifiers to spot the signatures of faulty reasoning 👉 Key Discoveries Testing on boolean logic, arithmetic, and math word problems revealed three crucial insights: Different types of reasoning failures create distinct computational signatures. A logic error looks completely different from an arithmetic mistake at the neural level. These signatures aren’t just correlational—they’re causal. The researchers successfully corrected errors by targeting specific features identified through their analysis. The method significantly outperformed existing approaches, achieving 92% accuracy on synthetic tasks compared to 76% for the best baseline. 👉 The Bigger Picture This work opens a new window into AI reasoning. Instead of treating models as black boxes, we can now examine their internal “thought processes” and understand not just when they fail, but how and why. While computationally intensive for now, this research points toward AI systems that can self-diagnose their reasoning errors and potentially self-correct in real-time. The paper: “Verifying Chain-of-Thought Reasoning via Its Computational Graph” by Zhao et al.

- 최근 링크드인에 게시된 "계산 그래프를 이용한 CoT 추론 검증" 이름의 논문을 접하고 재밌게 읽어보았습니다. 메타에서 진행된 해당 연구에서는 논문 이름에서 알 수 있듯이, 계산 그래프(Computational Graph) 구조를 활용하여 추론의 정확성을 검증할 수 있는 방법을 소개하고 있습니다. 다음의 인사이트를 간추려서 이번 주 오마카세로 가볍게 전달해드려보고자 합니다. 링크드인 글에 핵심을 잘 요약하고 있으니 참고해보셔도 좋을 것 같아 링크 공유드립니다.
- 최근 대규모 언어 모델(LLM)의 사고의 흐름(Chain-of-Thought, CoT) 추론은 복잡한 문제 해결 능력을 향상시켰지만, 그 과정이 투명하지 않아 검증 가능성의 해결 방안에 대해 열어두고 있습니다.
- 기존의 CoT 검증 방법들은 특정 연산이 실패하는지에 대한 깊이 있는 통찰을 제공하지 못합니다. 그로부터 검증의 가능성에 대한 의문과 해결 가능성의 어려움이란 꼬리표가 따라붙고 있습니다.
- 본 논문은 이러한 문제를 해결하기 위해 회로 기반 추론 검증(CRV: Circuit-based Reasoning Verification)이라는 새로운 방법론을 제안합니다. CRV는 LLM이 제시한 자연어 형태의 추론 과정을 계산 그래프로 변환하여, 추론의 정확성과 충실성을 동시에 검증할 수 있는 방법으로 소개됩니다.
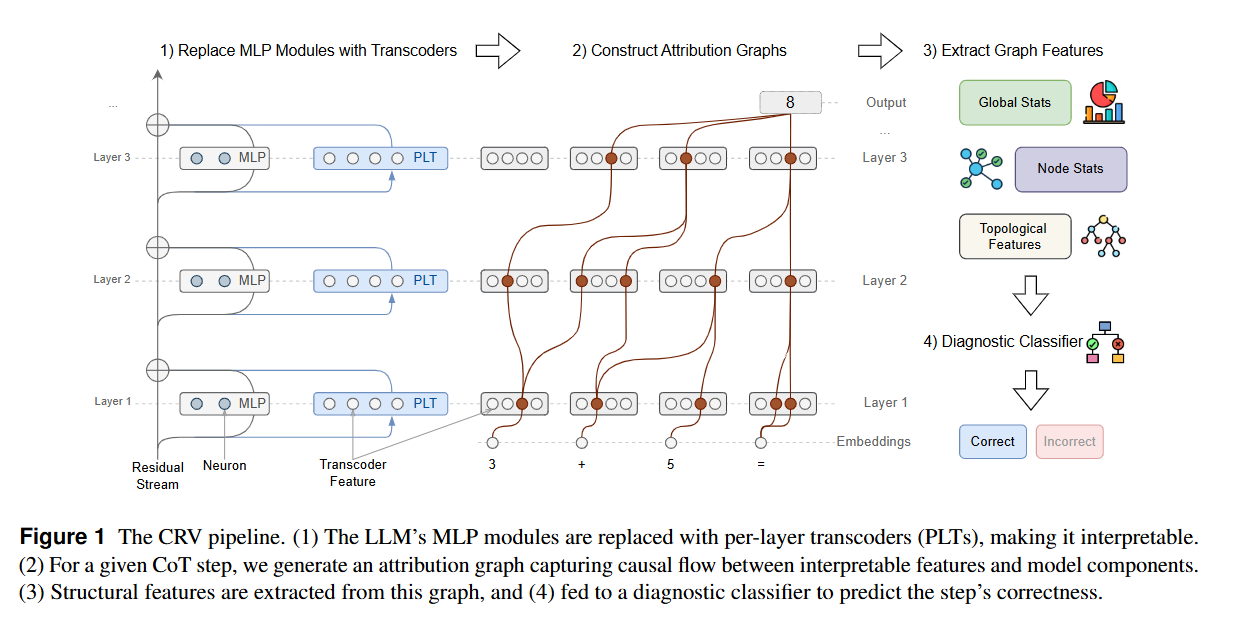
- CRV의 핵심은 CoT의 단계를 그래프의 구조화된 형식으로 변환하여 검증 가능성을 향상시키는 것입니다. 이는 크게 4가지 단계로 구성되어 있습니다.
- 기준 모델의 MLP 모듈을 해석 가능한 Transcoder(Llama 3.1 8B Instruct 모델의 각 MLP 레이어에 해당하는 Per-Layer Transcoder (PLT)를 사용)로 대체하여 계산 그래프의 정형화된 구조로 변환합니다. 다음 그래프는 사칙연산, 비교, 논리 연산 등 추론에 사용된 구체적인 계산 단계들을 표현하는 Functional Primitives와 출력이 최종 답변에 미치는 영향을 나타내는 Attribution Nodes의 요소로 구성되어 있습니다.
- CoT 추론의 각 단계에서 최종 출력 예측값에 대한 인과적 정보 흐름을 추적하는 Attirbution graph를 구성합니다. 그림에서와 같이 해당 노드는 입력 토큰과 활성화된 Transcoder 특징, 그리고 로짓(logits)을 나타내며, 엣지는 노드들 사이의 인과적 영향성을 기반한 가중치를 갖습니다. 그림에서 빨간색으로 표시된 엣지는 초기 레이어에서 이후 레이어 feature 및 최종 로짓간의 높은 attribution path를 구조적으로 표현하게 됩니다.
- 각 Attribution graph에서 계산의 구조적 fingerprint로 사용될 수 있는 고정 크기의 특징 벡터를 추출합니다. 그림에서와 같이 계산 복잡도 및 엔트로피에 대한 요약 정보를 담은 Global stats, 해석 가능한 노드 활성화 값 및 영향력 점수에 대한 통계를 포함하는 Node stats, 그리고 그래프 밀도, 중심성 및 최단 경로 길이 등 정보 흐름의 구조를 분석한 정보를 담은 Topological features를 계층적으로 추출합니다.
- 추론 단계의 정확성을 예측하고, 추론 오류의 유형을 구체적으로 진단하고 분류하는 Diagnostic Classifier를 활용합니다. 논문에서는 테이블 형식의 특징과 오류 회로의 예측적인 구조적 속성을 식별하는 데 강력한 Gradient Boosting classifier를 활용하여 계산 오류 (calculation error), 개념 오류 (conceptual error), 그리고 불충실한 출력 (unfaithful output)에 대한 여부 파악 뿐 아니라, 근본 원인을 파악하여 사용자의 추론 과정 신뢰성을 확보하는 상세한 정보를 제공합니다.
- 변환된 계산 그래프를 실행하면서 CoT 추론의 2가지 핵심 속성을 검증합니다.
- 계산 그래프의 요소를 순서대로 실행시켜 중간 단계의 값과 최종 결과가 수학적으로 또는 논리적으로 올바른지를 검증합니다. 다음 정확성(correctness) 검증 단계로부터 CoT에 포함된 단순 계산 오류나 개념 오류 등을 식별합니다.
- 언어 모델의 최종 답변이 실제로 그래프의 올바른 계산 단계에 완벽하게 의존하고 있는지, 정당한 근거를 기반으로 도출되었는지를 검증합니다. 다음 충실도(faithfulness) 검증 단계에서는 Attribution scores를 활용하여 겉으로 그럴싸한 가짜 추론을 진행한 것의 여부 및 우연히 정답을 맞춘 경우에 대한 판별을 수행합니다.
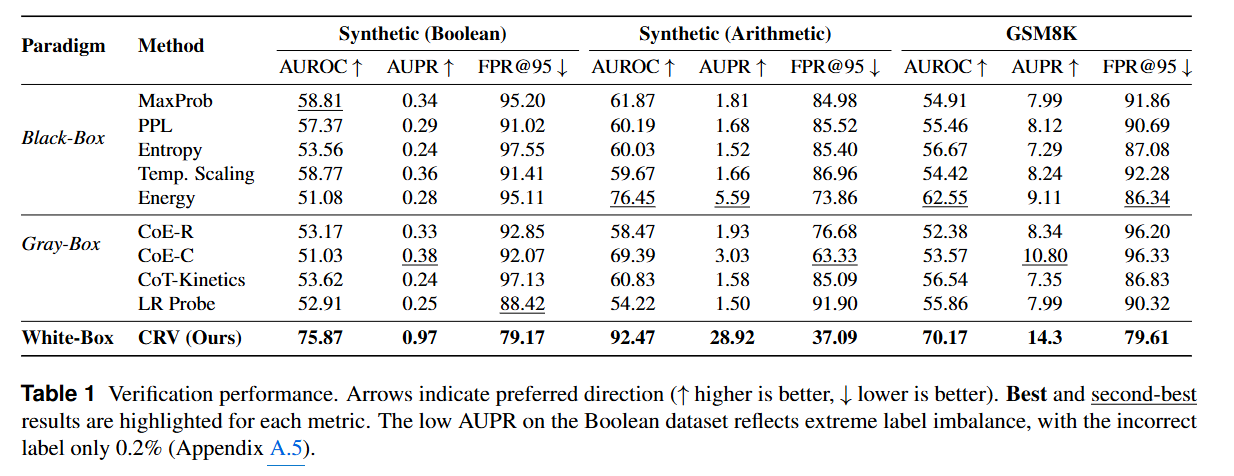
- CRV는 Llama 3.1 8B Instruct 모델과 합성 데이터셋(Boolean, Arithmetic) 및 실제 데이터셋(GSM8K)에서 평가되었습니다. 결과적으로 기존의 검증 방법론 (Black / Graybox)를 뛰어넘는 성능을 보였습니다. AUROC, AUPR, FPR@95 지표에서 일관된 향상 결과를 보이며, 추론 단계에 존재하는 구조적 특징이 정확성을 직접 검증할 수 있는 풍부한 신호를 포함한다는 주장을 뒷받침합니다.
- 또한 Cross-domain generalization 분석 결과를 통해 단순한 최종 답변을 확인하는 것이 아니라, 추론 오류의 유형들을 효과적으로 식별하고 분류할 수 있으며, 올바른 최종 답변을 제시하였더라도 내부 추론 과정에서 문제가 있는 경우를 정확하게 잡아낼 수 있는 prescriptive interventions을 확인하였습니다. 즉, CoT 추론 과정에 대한 신뢰성을 개선하여 추론 언어모델의 안정성을 높힐 수 있는 방법을 소개 및 검증하였습니다.
[Contact Info]
Gmail: jhbae1184@akane.waseda.jp
Twitter (X): @jhbae1184