25년 11월 3주차 그래프 오마카세
When to use Graphs in RAG: A Comprehensive Analysis for Graph Retrieval-Augmented Generation
When to use Graphs in RAG: A Comprehensive Analysis for Graph Retrieval-Augmented Generation
Graph retrieval-augmented generation (GraphRAG) has emerged as a powerful paradigm for enhancing large language models (LLMs) with external knowledge. It leverages graphs to model the hierarchical structure between specific concepts, enabling more coherent and effective knowledge retrieval for accurate reasoning.Despite its conceptual promise, recent studies report that GraphRAG frequently underperforms vanilla RAG on many real-world tasks. This raises a critical question: Is GraphRAG really effective, and in which scenarios do graph structures provide measurable benefits for RAG systems? To address this, we propose GraphRAG-Bench, a comprehensive benchmark designed to evaluate GraphRAG models onboth hierarchical knowledge retrieval and deep contextual reasoning. GraphRAG-Bench features a comprehensive dataset with tasks of increasing difficulty, coveringfact retrieval, complex reasoning, contextual summarization, and creative generation, and a systematic evaluation across the entire pipeline, from graph constructionand knowledge retrieval to final generation. Leveraging this novel benchmark, we systematically investigate the conditions when GraphRAG surpasses traditional RAG and the underlying reasons for its success, offering guidelines for its practical application. All related resources and analyses are collected for the community at https://github.com/GraphRAG-Bench/GraphRAG-Benchmark.
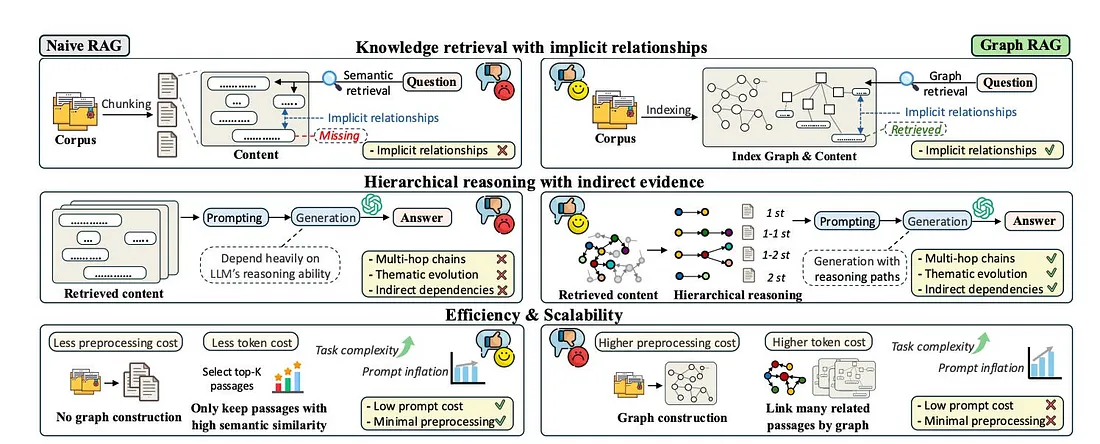
- 텍스트 상의 지식을 검색하여 LLM의 지식 집약적 작업에서 환각을 생성하는 경향을 억제하는 RAG는 정확한 답변을 위한 기술적 발전에 있어서 빠질 수 없는 부분이라고 생각합니다.
- 자연스럽게 GraphRAG는 대규모 비정형 도메인 상의 코퍼스를 처리할 때 컨텍스트 정보 손실을 방지하기 위해 그래프 구조를 활용하여 LLM의 컨텍스트 이해 능력을 향상시킬 수 있다는 부분에서 큰 관심을 받았습니다. 하지만 최근 연구들은 GraphRAG가 실제로 RAG보다 성능이 떨어지는 경우가 잦다는 사실을 보고하며, GraphRAG가 정말 효과적인지, 어떤 시나리오에서 이점을 갖는지에 대한 의문을 제기합니다.
- 현재 벤치마크 데이터셋은 그래프 구조가 RAG 기술에 있어서 장점을 충분히 제공 및 평가하지 못하고 있기 때문에, 위 논문에서는 GraphRAG 모델의 포괄적인 평가가 가능하도록 설계된 포괄적 벤치마크 셋, GraphRAG-Bench를 소개합니다.
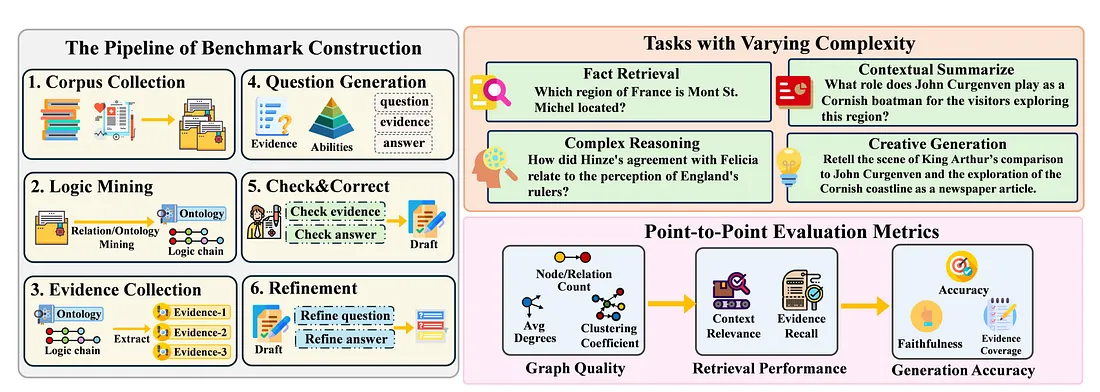
- 논문의 다음그림은 GraphRAG-Bench를 크게 세 가지 핵심 구성 요소로 나누어 보여주고 있습니다.
- 벤치마크 구축 (왼쪽) : 6가지 단계로 구성되어 있습니다.
- 1. 비정형적인 실제 모호성과 도메인별 계층 구조 간의 균형을 이루어, 검색 견고성과 추론 깊이를 엄격하게 평가하는 데이터셋 생성 (Medical, Novel datasets)
- 2, 3. LLM 기반 텍스트의 온톨로지화를 통한 원본 텍스트의 개념들이 어떻게 상호작용을 하는지 그 논리적 관계를 명시적으로 표현하고, 추론의 복잡성을 정량화하여 실제 태스크의 인지적 요구 사항과 일치할 수 있도록 증거를 추출.
- 4. 내재된 증거의 구조적 속성 및 인지적 요구 사항을 일치시켜 질문 생성.
- 5. 검증 및 수정 과정을 수행하여 증거 및 답변의 정확성을 보장.
- 6. 관련 배경 지식을 통합하여 더욱 풍부한 질문을 생성 및 정제.
- 다양한 복잡성에 따른 태스크 분류 : 검색 난이도와 추론 복잡성을 확장하는 4가지 태스크를 설계합니다.
- 사실 검색
- 복잡한 추론
- 컨텍스트 요약
- 창의적 생성
- 인덱싱, 검색, 생성을 포괄하는 다단계 평가 프레임워크를 구성합니다 : 그래프 품질, 검색 성능, 생성 정확도의 각 단계별로 특화된 측정 지표를 사용하여 GraphRAG 시스템을 평가합니다.
- 벤치마크 구축 (왼쪽) : 6가지 단계로 구성되어 있습니다.
- 구축된 GraphRAG-Bench 데이터셋을 GPT-40-mini 및 Qwen2.5-14B를 사용하여 7가지 GraphRAG( GraphRAG (local/global), LightRAG, HippoRAG, HippoRAG2, Fast-GraphRAG, RAPTOR) 및 기본 RAG를 비교 분석하였습니다. 주요 연구 결과는 아래와 같습니다.
- (생성 정확도) GraphRAG는 해당 벤치마크에서 RAG와 비교하였을 때 어떤 성능을 보이는가?
- 기본 RAG는 단순 사실 검색 작업에서 GraphRAG와 유사합니다. 단순 사실 검색의 경우, 연결된 개념에 대한 복잡한 추론이 필요하지 않을 때 기본 RAG는 GraphRAG와 유사하거나 더 나은 성능을 보입니다. 더 간단한 작업에서는 추가적인 그래프 처리로 인해 중복되거나 노이즈가 있는 정보가 추가되어 답변의 질이 저하될 수 있습니다.
- GraphRAG는 복잡한 작업에 탁월합니다 . GraphRAG는 복잡한 추론, 상황에 맞는 요약, 창의적인 생성과 같은 작업에서 두각을 나타냅니다. 이러한 작업은 모두 여러 개념 간의 관계를 탐색하는 데 의존하기에, 본질적으로 다음에 적합한 그래프의 장점이 두드러졌습니다.
- GraphRAG는 창의적인 과제에서 더 높은 사실적 신뢰도를 보장합니다 . RAPTOR는 Novel 데이터셋에서 가장 높은 성능(70.9%)을 기록했습니다. RAG와의 차이는 GraphRAG가 정보를 검색하는 방식에서 비롯될 가능성이 높습니다. 하지만, GraphRAG의 단편화된 접근 방식은 광범위하고 포괄적인 답변을 생성하기 어렵게 만들 수 있습니다. 즉, GraphRAG는 정밀성 측면에서는 뛰어나지만, 그 집중도는 더 넓은 범위를 포괄하는 데에 어려움이 내재되어 있습니다.
- (검색 성능) GraphRAG는 검색 과정에서 더 높은 품질과 덜 중복된 정보를 검색합니까?
- RAG는 추론이 크게 필요하지 않은 간단한 질문에 대한 개별적인 사실들을 효과적으로 검색하여 , Novel dataset에서 컨텍스트 관련성에서 HippoRAG2의 최고 점수를 능가하는 83.2%의 컨텍스트 재현율을 달성했습니다. Medical dataset에서도 동일한 패턴이 관찰됩니다. 대개 한 구절에서 정답을 찾아내는 간단한 질문(난이도 레벨 1)의 경우, GraphRAG의 지식 그래프 사용은 실제로 필요하지 않은 관련 추가 정보를 가져오는 경향이 있습니다.
- GraphRAG는 질문이 복잡해질수록 빛을 발하기 시작합니다 . Novel dataset의 난이도 레벨 2와 레벨 3 질문에서 HippoRAG는 인상적인 증거 재현율(87.9–90.9%)을 제공하는 반면, HippoRAG2는 컨텍스트 관련성(85.8–87.8%)에서 우위를 점했습니다. Medical dataset에서도 동일한 추세를 확인할 수 있는데, GraphRAG의 강점은 더욱 분명해집니다. 특히 텍스트의 여러 부분에 분산된 정보를 연결하는 데 매우 효과적이며, 이는 멀티홉 추론과 포괄적인 요약에 필수적입니다.
- RAG와 GraphRAG는 광범위한 지식 합성을 요구하는 창의적인 작업에 있어 각각 강점을 가지고 있습니다 . Global-GraphRAG는 높은 증거 재현율(83.1%)로 두드러지며, RAG는 컨텍스트 관련성(78.8%)에서 우위를 점하고 있습니다. GraphRAG는 전반적으로 더 관련성 있는 정보를 표면화하는 경향이 있지만 검색 방식이 다소 중복성을 더하는 반면, RAG는 더 간결하고 집중적인 경향을 보입니다.
- (그래프 복잡도) 구성된 그래프가 기본 지식을 올바르게 구성하고 있습니까?
- GraphRAG의 다양한 버전은 구조가 눈에 띄게 다른 인덱스 그래프를 생성합니다 . HippoRAG2는 다른 프레임워크에 비해 노드와 에지 모두 훨씬 더 밀도 있는 그래프를 생성합니다. Novel dataset에서는 평균 2,310개의 에지와 523개의 노드를, Medical dataset에서는 3,979개의 에지와 598개의 노드를 생성합니다. 이러한 추가적인 밀도는 정보의 연결 및 포괄성을 향상시켜 HippoRAG2가 콘텐츠를 더욱 효과적으로 검색하고 생성하는 데 도움이 됩니다.
- (효율성) GraphRAG는 검색 중에 상당한 토큰 오버헤드를 발생시키나요?
- GraphRAG는 검색 단계가 추가되고 그래프 기반 집계가 이루어지기 때문에 기존 RAG보다 훨씬 긴 프롬프트를 생성하는 경향이 있습니다. Global-GraphRAG는 최대 약 40,000개 토큰까지 LightRAG도 약 10,000개 토큰으로 늘리며 상당히 긴 프롬프트를 생성합니다. 반면 HippoRAG2는 약 1,000개 토큰으로 훨씬 더 간결하게 유지하여 효율성이 훨씬 뛰어납니다. 다음을 바탕으로, GraphRAG의 구조화된 파이프라인에는 실질적인 토큰 비용이 따라붙습니다.
- 작업이 복잡해지고 더 많은 지식이 요구됨에 따라 GraphRAG의 프롬프트 길이는 눈에 띄게 증가합니다. 예를 들어, Global-GraphRAG의 프롬프트 크기는 작업 난이도가 높아짐에 따라 7,800개에서 40,000개로 증가합니다. 하지만 이러한 증가에는 단점이 있습니다. 토큰이 많을수록 중복성이 증가하여 검색 시 컨텍스트 관련성이 저하될 수 있습니다. 이는 전형적인 상충 관계입니다. GraphRAG는 더 나은 구조와 더 광범위한 적용 범위를 제공하지만, 특히 복잡한 작업에서 프롬프트 길이의 증가하는 경향성으로 인해 중복 정보 도입 및 컨텍스트 관련성 저하 등의 비효율성이 발생할 수 있습니다.
- (생성 정확도) GraphRAG는 해당 벤치마크에서 RAG와 비교하였을 때 어떤 성능을 보이는가?
- GraphRAG 모델들의 체계적으로 평가 및 최적화를 위해 구축되어진 GraphRAG-Bench 벤치마크로부터 얻어낼 수 있는 이러한 분석들은 RAG 대비 GraphRAG 접근 방식의 상대적 이점 및 특성들을 재확인할 수 있게 도와줍니다. GraphRAG-Bench 데이터셋과 같은 벤치마크는 실제 GraphRAG의 효율적인 적용을 극대화할 수 있는 지침을 제공하고, 실용적인 단점을 보완하여 활용도를 높히고, 궁극적으로 LLM에서의 시너지를 더욱 강화할 수 있을 것입니다.
- 최근 몇 년 동안 복잡한 추론과 지식 집약적인 작업에 있어 GraphRAG가 진정한 이점을 제공하는지의 의문점은 다음을 평가할 체계적인 방법이 없었기 때문에 불분명했습니다. 이러한 격차를 직접적으로 해소하기 위한 맞춤형 벤치마크를 도입하는 것은 매우 중요한 과제라고 생각됩니다.
- 전반적으로 GraphRAG는 단순한 작업에서는 종종 프롬프트를 어지럽히는 중복 정보 때문에 기존 RAG보다 성능이 떨어지는 경향이 있습니다. 허나 멀티홉 추론이나 심층적인 컨텍스트 통합과 같이 더 복잡한 작업에서는 GraphRAG가 분명한 우위를 보입니다. 모든 GraphRAG 모델들이 동일한 목적과 설계도로 만들어진 것이 아니기 때문에, 그래프 구조의 밀도와 품질은 검색 범위, 생성 정확도, 그리고 다양한 작업에 대한 적응력에 상당한 영향을 미칠 것입니다.
- 그래프 기반 개선은 정보 구성과 추론을 향상시키지만, 토큰 비용도 많이 듭니다. 결국 성능과 효율성 사이에서 균형을 맞추는 것의 필요성이 대두될 것으로 생각됩니다. 이러한 관점에서 GraphRAG-Bench의 기여점은 정말 크게 느껴집니다.
[Contact Info]
Gmail: jhbae1184@akane.waseda.jp
Twitter (X): @jhbae1184