25년 11월 4주차 그래프 오마카세
NodeRAG: Structuring Graph-based RAG with Heterogeneous Nodes
NodeRAG: Structuring Graph-based RAG with Heterogeneous Nodes
Retrieval-augmented generation (RAG) empowers large language models to access external and private corpus, enabling factually consistent responses in specific domains. By exploiting the inherent structure of the corpus, graph-based RAG methods further enrich this process by building a knowledge graph index and leveraging the structural nature of graphs. However, current graph-based RAG approaches seldom prioritize the design of graph structures. Inadequately designed graph not only impede the seamless integration of diverse graph algorithms but also result in workflow inconsistencies and degraded performance. To further unleash the potential of graph for RAG, we propose NodeRAG, a graph-centric framework introducing heterogeneous graph structures that enable the seamless and holistic integration of graph-based methodologies into the RAG workflow. By aligning closely with the capabilities of LLMs, this framework ensures a fully cohesive and efficient end-to-end process. Through extensive experiments, we demonstrate that NodeRAG exhibits performance advantages over previous methods, including GraphRAG and LightRAG, not only in indexing time, query time, and storage efficiency but also in delivering superior question-answering performance on multi-hop benchmarks and open-ended head-to-head evaluations with minimal retrieval tokens. Our GitHub repository could be seen at https://github.com/Terry-Xu-666/NodeRAG.
GitHub - Terry-Xu-666/NodeRAG: The official repository of NodeRAG
The official repository of NodeRAG. Contribute to Terry-Xu-666/NodeRAG development by creating an account on GitHub.
- 이번 주 오마카세에서도 GraphRAG에 대한 논문 내용을 기반으로 어떻게 RAG 시스템의 성능 향상을 목표하고 있는지에 대해 핵심 구성요소 및 내용들만 뽑아서 전달해드리고자 합니다. 자세한 내용 설명이 궁금하신 분들께서는 논문을 직접 읽어보심을 추천드립니다.
- 기존 RAG는 단편화된 콘텐츠와 중복된 정보로 인해 어려움을 겪는 경우가 많습니다. 다양한 GraphRAG 방식들은 이러한 문제를 개선하기 위해 제안되어오고 있으나, 해당 논문에서 저자들이 개선하고자 하는 부분은 단순한 그래프 구조로 인해 복잡한 의미를 포착하는 데는 부족한 성능적 결함 문제입니다. 특히 Multi-hop 수준에서의 추론 및 요약 수준에서 질의 처리에 한계점이 있음을 지적합니다.
- 위의 문제를 해결하는 데 NodeRAG 라는 이름의 프레임워크를 제안합니다. Fig. 1에서 다른 RAG, 기존 GraphRAG와 제안하는 NodeRAG의 비교를 나타내고 있습니다. 가볍게 짚어보면,
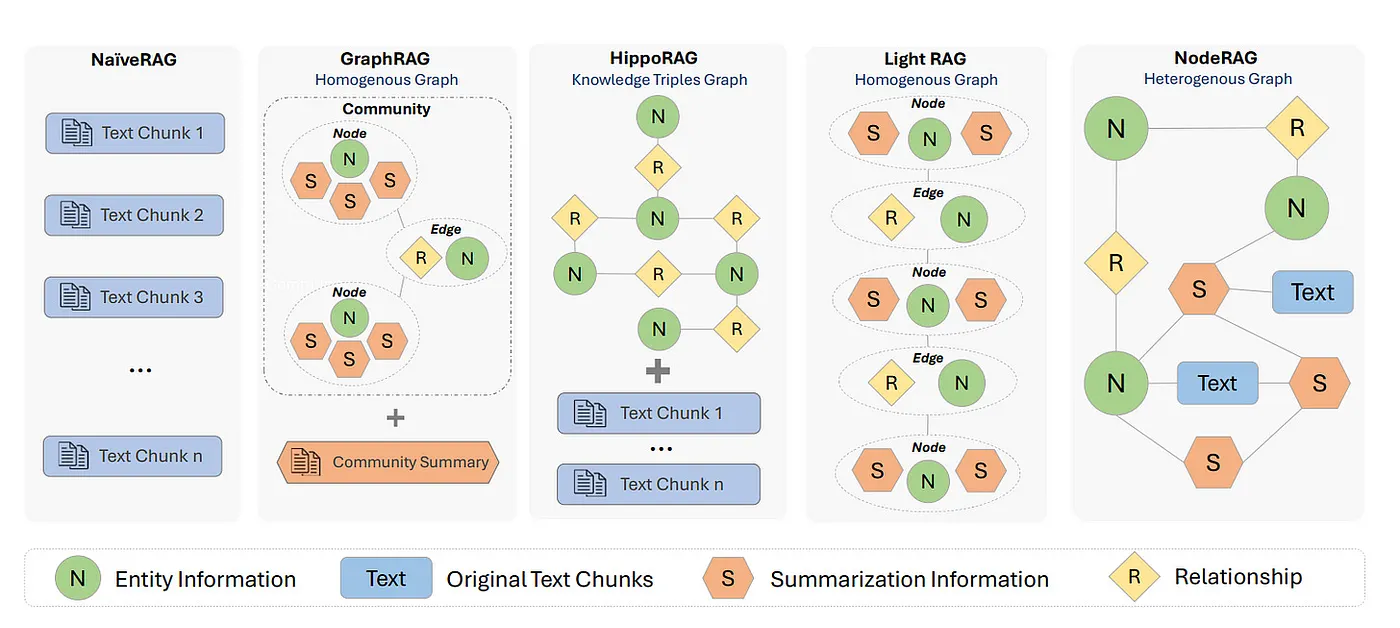
- NaiveRAG : 종종 중복된 정보로 이어지는 단편화된 Text Chunk를 검색합니다.
- HippoRAG : 지식 그래프 기반의 접근 방식이지만 고수준 차원의 요약 문제에서 약점을 드러냅니다.
- GraphRAG : 특정 도메인에서 사실적으로 일관된 응답을 제공하기 위한 접근 방식이지만, 결과가 여전히 너무 광범위하게 느껴질 수 있습니다.
- LightRAG : 문맥적으로 도움이 되는 단일 홉 이웃을 통합할 뿐만 아니라 중복 노드도 검색합니다.
- NodeRAG : 위의 방식들과 다른 접근 방식을 취합니다. 상위 요소, 의미 단위, 관계와 같은 여러 유형의 노드(Heterogeneously)를 사용하여 관련 없는 정보를 줄이는 동시에 보다 정확하고 계층적인 검색을 가능하게 합니다.
- 즉, NodeRAG의 핵심은 Heterogeneous한 그래프 구조를 도입하여 RAG 시스템에 더욱 원활하게 통합 가능한 그래프 중심 프레임워크를 제안하는 것입니다.
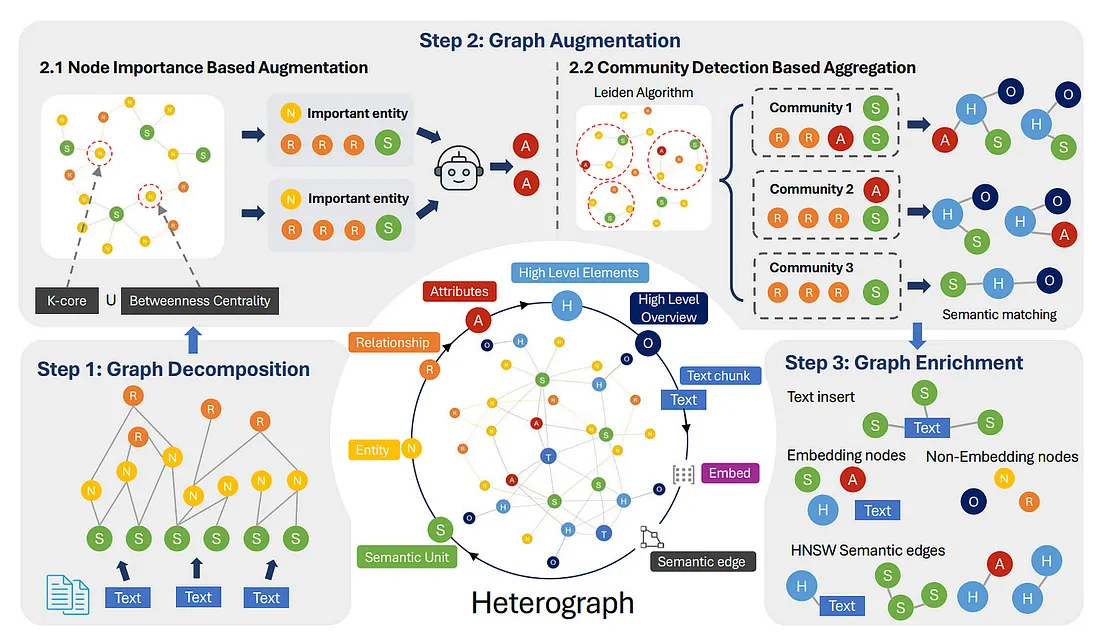
- 위의 Fig. 2는 명확하게 세 가지 단계로부터 Heterogeneous graph index를 구축하는 방법을 보입니다.
- 그래프 분해 (Graph Decomposition) : LLM을 사용하여 텍스트를 세 가지 핵심 노드 유형, 즉 Semantic Unit(S), Entity(N), Relationship(R)로 분할하는 것으로 시작됩니다.
- 그래프 증강 (Graph Augmentation) : 핵심 엔티티와 같은 주요 노드를 식별하고, 그 중요성을 강조하기 위해 Attribute Node(A)를 생성합니다. 또한 커뮤니티 감지를 통한 고수준의 인사이트를 포착하고, High-level Elements (H)와 High-level Overview (O)를 생성합니다.
- 그래프 강화 (Graph Enrichment) : 마지막으로 세부 정보를 보존하기 위해 원본 Text(T)를 가져오고 (H,N,S,W)를 사용하여 의미적 유사성 에지를 추가하여 검색을 위해 그래프를 더 강력하고 정확하게 만듭니다.
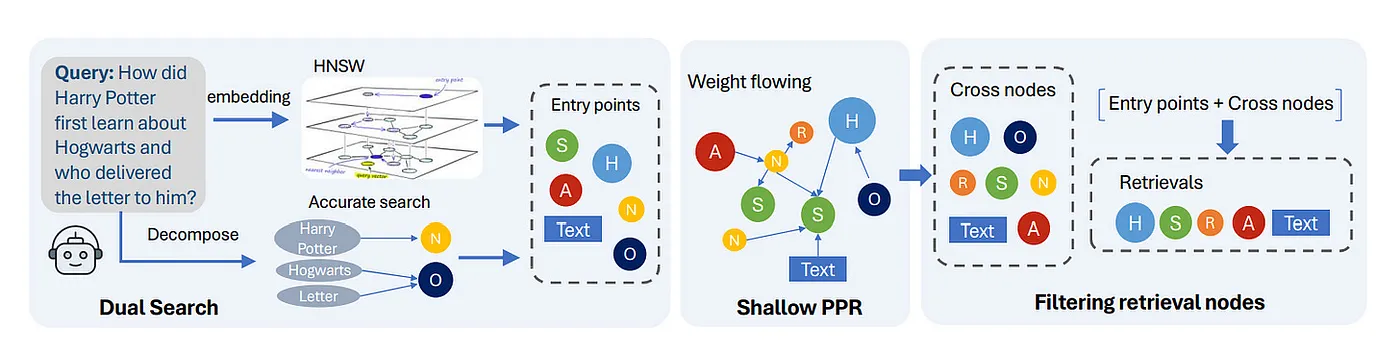
- 그림 3은 NodeRAG가 간소화된 3단계 프로세스를 통해 쿼리를 처리하는 방식을 보여줍니다. 이 프로세스는 구조 인식 검색과 의미 검색을 결합하여 더욱 관련성 있고, 세분화되어 있으며, 노이즈가 적은 결과를 제공합니다.
- 이중 검색(Dual Search) : 쿼리에서 Entitiy와 Semantic cues를 추출하는 것으로 시작합니다. 그런 다음, (N,O) 노드에서 정확한 일치를 검색하고 (S,A,H) 노드에서 벡터 유사성 검색을 결합하여 가장 관련성 높은 항목 노드를 정확하게 찾아냅니다.
- 얕은 PPR(Shallow PPR) : Entry points에서 NodeRAG는 가벼운 그래프 확산(biased Random Walk)을 시뮬레이션하여 그래프 전체에서 의미적으로 관련된 노드를 찾아냅니다. 여기에서 반복 횟수를 제한하여 더욱 관련성이 높은 주변에 확산 과정이 국한될 수 있도록 설계합니다.
- 검색 노드 필터링(Filter Retrieval Nodes) : 마지막 단계에서는 관련 없는 노드를 걸러내고 의미 있는 노드(T, S, A, H, R)만 유지하여 최종 결과 세트를 형성합니다.
- 결과적으로 Multi-hop 벤치마크 (HotpotQA, MuSiQue, MultiHop-RAG) 및 RAG-QA Arena의 open-ended head-to-head 평가에서 Fig 1의 기존 RAG, GraphRAG 방법론보다 좋은 성능을 보임을 확인합니다. 또한 Ablation study를 통해서 적은 검색 토큰을 사용하며 시스템 수준에서의 효율성도 입증합니다.
- 전체적으로 NodeRAG는 기존 방법들과 다른 그래프 구조 개선, 특히 정보의 종류와 역할에 따라 노드를 Heterogeneous하게 구조화함으로써, 기존 RAG의 문제점이었던 정보의 비일관성, 조잡한 검색 과, 그리고 그래프 알고리즘(PPR, K-core 등) 통합의 어려움을 해결하고자 했습니다. 다시 말해, NodeRAG는 그래프 자체를 시스템의 중심에 두고, 그 구조를 단순한 특징의 저장소(Storage) 형식이 아닌 지식 이해의 열쇠로 간주합니다.
- 물론 NodeRAG는 기존 RAG를 기반으로 그래프 알고리즘을 훨씬 더 심도 있게 활용하기 때문에 자연스럽게 복잡성이 증가하고 새로운 과제가 발생합니다. 특히 그래프 구조와 견고성 측면에서, "LLM을 사용하여 의미 구조를 구축하는 방식"과 "그래프 확산 알고리즘이 의미적으로 얼마나 잘 유지되는가"에 대한 두 영역은 더욱 엄격한 제어와 검증이 필요할 것입니다.
- 이는 단순한 기술적인 세부 사항이 아니라 발전해나가는 GraphRAG 기술들이 실제 응용 프로그램에 더 집중되어져서 적용 가능성을 논의하기 시작하는 때에 반드시 해결해야 할 실제적인 장애물이 될 것입니다. 그에 대한 실마리를 NodeRAG가 기존과 차별화된 아이디어를 제공함에 있어서 그 기여성이 크게 느껴졌습니다.
- LLM 중심 전략에 최근 회의적인 입장을 보이고 있는 얀 르쿤의 주장에 따르면, 여전히 GraphRAG 관련 방법론들은 LLM의 높은 의존성과 이와 관련한 비용 및 평가 문제, 그리고 그래프 구조의 복잡성 및 그로부터 오버헤드 문제 등등 해결해야 할 고려사항들이 많이 있는 것 같습니다. 조만간 다음을 모두 타파할 수 있는 강력한 GraphRAG 기술 및 그와 접목된 더욱 강력하고 범용적인 지식 기반 LLM 시스템이 구축될 수 있을 지 관심이 높아질 것 같습니다.
[Contact Info]
Gmail: jhbae1184@akane.waseda.jp
Twitter (X): @jhbae1184