25년 10월 1주차 그래프 오마카세
Topology of Reasoning: Understanding Large Reasoning Models through Reasoning Graph Properties
Topology of Reasoning: Understanding Large Reasoning Models through Reasoning Graph Properties
Recent large-scale reasoning models have achieved state-of-the-art performance on challenging mathematical benchmarks, yet the internal mechanisms underlying their success remain poorly understood. In this work, we introduce the notion of a reasoning graph, extracted by clustering hidden-state representations at each reasoning step, and systematically analyze three key graph-theoretic properties: cyclicity, diameter, and small-world index, across multiple tasks (GSM8K, MATH500, AIME 2024). Our findings reveal that distilled reasoning models (e.g., DeepSeek-R1-Distill-Qwen-32B) exhibit significantly more recurrent cycles (about 5 per sample), substantially larger graph diameters, and pronounced small-world characteristics (about 6x) compared to their base counterparts. Notably, these structural advantages grow with task difficulty and model capacity, with cycle detection peaking at the 14B scale and exploration diameter maximized in the 32B variant, correlating positively with accuracy. Furthermore, we show that supervised fine-tuning on an improved dataset systematically expands reasoning graph diameters in tandem with performance gains, offering concrete guidelines for dataset design aimed at boosting reasoning capabilities. By bridging theoretical insights into reasoning graph structures with practical recommendations for data construction, our work advances both the interpretability and the efficacy of large reasoning models.
GitHub - gouki510/Topology_of_Reasoning
Contribute to gouki510/Topology_of_Reasoning development by creating an account on GitHub.
- 이 연구는 최근 성능이 크게 향상된 대규모 추론 모델(large reasoning models)의 성공 뒤에 숨겨진 내부 메커니즘을 이해하기 위해 '추론 그래프(reasoning graph)'라는 개념을 도입하고 이를 체계적으로 분석합니다. 언어 모델의 내부 메커니즘을 그래프 기반으로 해석하려는 접근의 도쿄대 연구진들이 보인 성과로써 상당히 흥미로운 내용이 많이 포함되어 있습니다. 영상으로도 정리되어 있으니 논문과 더불어 참고해서 보시면 도움이 많이 되실 것 같습니다.
- 대규모 추론 모델의 내부 메커니즘을 이해하기 위해 Transformer 레이어의 hidden state 표현을 클러스터링하여 추론 그래프를 정의하고, 순환성(Cycle), 지름(diameter), 스몰-월드(small-world) 지수와 같은 그래프 이론적 특성을 분석했습니다. 이러한 발견은 LLM의 "aha !(깨달음) moment"와 "overthinking" 또는 "underthinking" 같은 행동을 그래프 특성으로 설명하는 새로운 인사이트를 제공합니다.
- 순환성(Cycle) : 자체 루프(self-loops) 및 인접 중복을 제외하고 동일한 노드를 반복적으로 방문하는 경우를 사이클로 정의합니다. 사이클 감지 비율은 하나 이상의 사이클을 포함하는 추론 그래프의 비율이며, 사이클 횟수는 단일 노드에 대한 최대 반복 방문 횟수입니다.
- 지름(Diameter): 도달 가능한 임의의 두 노드 간의 최단 경로의 최대값 거리로 정의되며, Dijkstra's algorithm을 사용하여 계산됩니다. 지름이 크다는 것은 더 넓은 추론 노드 범위를 탐색한다는 것을 의미합니다.
- 스몰 월드 지수(Small-World Index): 네트워크가 국소적으로는 밀집된 클러스터를 형성하면서도 전역적으로는 짧은 경로로 연결되어 효율적인 정보 전파를 가능하게 함을 나타냅니다.
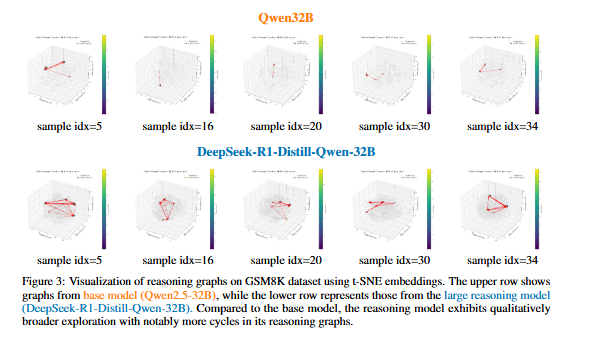
- 수학적 추론 과정(GSM8K)에서 제안하는 추론 그래프의 개념을 시각적으로 보여주는데, Qwen 베이스 모델보다 대규모 Deepseek R1 추론 모델의 내부 상태 차이를 t-SNE로 시각화하여 나타내었습니다.
- 베이스 모델의 추론 그래프 구조는 비교적 단순하고 주로 비순환적(acyclic)인 구조를 보입니다. 즉, 모델이 추론 과정에서 이전에 방문했던 상태로 다시 돌아오는 경우가 적습니다. 탐색하는 노드의 범위도 제한적입니다.
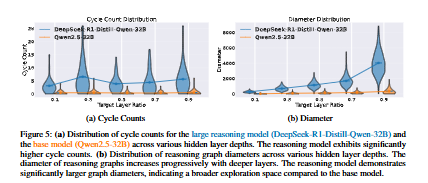
- 대규모 추론 모델의 경우, 노드들 사이에 많은 루프(loop)나 사이클(cycle)이 관찰됩니다. 다음은 중간 답변을 재검토하거나, 다른 추론 경로를 탐색하기 위해 이전 상태로 돌아가는 'aha moment'와 같은 반복적인 사고 과정을 거친다는 사실을 시사합니다. 정량적으로, 베이스 모델보다 사이클 감지 비율이 현저히 높았으며, 태스크 난이도에 따라 감지된 사이클 수는 증가하였습니다. 평균적으로 5개의 사이클을 포함하였음을 실험적으로 확인하였습니다.
- 또한 그래프의 노드들이 더 넓은 공간에 분포되어 있으며, 이는 모델이 추론 과정에서 더 다양한 사고 상태를 탐색한다는 것을 의미합니다. 논문에서는 이를 '더 큰 지름(larger diameter)' 특성과 연결하여 설명합니다. 그래프 지름은 깊은 hidden layer에서 점진적으로 증가하는 경향을 보였습니다.
- 대규모 추론 모델의 그래프는 더 높은 클러스터링 계수와 더 긴 평균 경로 길이를 갖는 스몰 월드 지수가 일관되게 높게 나타났으며, 이러한 구조로부터 잘못된 경로를 빠르게 감지하고 회복하는 데 강력한 성능을 갖는다는 사실도 시사합니다.
- 다음 결과는 실제 뉴로사이언스 분야에서 이론적으로 분석된 결과와 실험적으로 파악된 사실들과 비슷한 양상을 띕니다. 실제로 인간 뇌 네트워크는 고차원적 인지 추론 과정에서 수많은 사이클(루프) 구조를 형성함으로써 뇌 영역들의 복합적인 커뮤니케이션을 통한 정보를 안정적으로 전달합니다.
- 특히 인지 능력(언어 인지 포함)과 관련한 영역들의 정보 전달루트를 연결해보면 대다수의 루프 구조를 형성하고 있음이 확인되었습니다. 다음 루프(사이클)를 이루는 엣지들은 중복성 (Redundancy)이 강한, 즉 반복(증폭)된 정보 전달을 담당하여 멀리 떨어진 영역까지 정보의 누수를 방지하고 안정적인 커뮤니케이션 프로세스를 형성합니다. 또한 루프를 가로지르는 엣지들도 발견되는데, 다음은 다른 네트워크 간 넘어오는 정보들을 직접적으로 통합하고, 피드백 역할을 담당하며 시너지(Synergy) 프로세스를 형성합니다.
- 대규모 언어 모델의 추론 능력은 실제 인간 뇌 네트워크의 복합적인 인지 추론 프로세스와 꽤나 유사한 경향을 띄고 있음을 알 수 있습니다. 즉, 위 이미지에서의 시각적 차이를 통해 대규모 추론 모델이 베이스 모델에 비해 훨씬 더 정교하고 반복적인 추론 전략을 사용한다는 것을 정성적으로 보여줍니다.
- 저자들은 이러한 구조적 특징(순환성, 지름, small-world 특성)이 대규모 추론 모델의 향상된 수학적 추론 성능의 핵심 요인이라고 주장하며, 특히 순환 구조는 모델이 자신의 추론을 재검토하고 오류를 수정하는 능력을 반영하며, 넓은 탐색 범위는 복잡한 문제 해결에 필요한 다양한 경로를 고려할 수 있게 합니다.
- 이러한 구조적 장점은 작업 난이도와 모델 용량에 따라 증가할수록 사이클 횟수 및 그래프 지름이 증가하는 경향을 보임으로써 정확도와 양의 상관관계를 가집니다.
- 다음 사실들을 바탕으로 대규모 언어 모델의 추론 능력 향상을 위한 효과적인 SFT (Supervised Fine-Tuning) 데이터셋 설계에 실용적 지침을 제공합니다.
[Contact Info]
Gmail: jhbae1184@akane.waseda.jp
Twitter (X): @jhbae1184