25년 9월 1주차 그래프 오마카세
No Metric to Rule Them All: Toward Principled Evaluations of Graph-Learning Datasets
No Metric to Rule Them All: Toward Principled Evaluations of Graph-Learning Datasets
Benchmark datasets have proved pivotal to the success of graph learning, and good benchmark datasets are crucial to guide the development of the field. Recent research has highlighted problems with graph-learning datasets and benchmarking practices -- revealing, for example, that methods which ignore the graph structure can outperform graph-based approaches. Such findings raise two questions: (1) What makes a good graph-learning dataset, and (2) how can we evaluate dataset quality in graph learning? Our work addresses these questions. As the classic evaluation setup uses datasets to evaluate models, it does not apply to dataset evaluation. Hence, we start from first principles. Observing that graph-learning datasets uniquely combine two modes -- graph structure and node features --, we introduce Rings, a flexible and extensible mode-perturbation framework to assess the quality of graph-learning datasets based on dataset ablations -- i.e., quantifying differences between the original dataset and its perturbed representations. Within this framework, we propose two measures -- performance separability and mode complementarity -- as evaluation tools, each assessing the capacity of a graph dataset to benchmark the power and efficacy of graph-learning methods from a distinct angle. We demonstrate the utility of our framework for dataset evaluation via extensive experiments on graph-level tasks and derive actionable recommendations for improving the evaluation of graph-learning methods. Our work opens new research directions in data-centric graph learning, and it constitutes a step toward the systematic evaluation of evaluations.
- 한 주 쉬고 돌아온 그래프 오마카세의 전달 논문은 "No Metric to Rule Them All: Toward Principled Evaluations of Graph-Learning Datasets" 입니다. 제목부터 알 수 있듯이 그래프 학습을 위한 데이터셋에 대한 지적 및 향상 메세지를 담고 있으며, 많은 그래프 연구자 및 실무자들에게 그래프 데이터 품질 평가 측면에서 좋은 인사이트를 제공할 수 있을 것 같습니다.
- 최근 머신러닝 분야에서 중요하게 다뤄지고 있는 '데이터 중심 AI (Data-centric AI)' 흐름과 재현성 및 평가 방법에 대한 비판적 고찰이 늘어나는 추세맞추어서, 그래프 학습의 기술적인 발전을 너머 해당 연구의 환경적 지속 가능성과 책임감 있는 AI 개발이라는 더 주요한 목표에 기여하고자 합니다. 즉, 데이터를 더 효율적이고 엄격하게 평가함으로써, 불필요한 모델 개발 및 학습에 드는 컴퓨팅 자원과 에너지를 절감할 수 있으며, 이는 곧 환경 부하를 줄이는 데 기여한다는 논리입니다.
- 다음 내용은 이전의 그래프 AI의 문제점을 지적한 내용과 일맥상통하는 부분이며, 현재 그래프 연구자들이 바라보는 시야를 적극 반영하고 있다고 생각합니다.
- 해당 저자들은 그래프 학습 데이터셋의 품질을 평가하는 데 있어 단일한 '만능' 지표는 존재하지 않으며, 그러한 지표가 바람직하지도 않다는 논문의 주장을 바탕으로, 현존 데이터셋의 단순히 모델의 성능을 비교하는 것을 넘어 "좋은 그래프 학습 데이터셋이란 무엇인가?"와 "그래프 학습에서 데이터셋의 품질을 어떻게 평가할 수 있는가?"라는 근본적인 질문에 답하고자 합니다.
- 그 답변으로, 저자들은 그래프 학습 데이터셋의 품질을 평가하는 데 있어 단일한 '만능' 지표는 없으며, 보다 원칙적이고 체계적인 평가 방식이 필요하다는 핵심 메시지를 독자들에게 전달하고 있습니다. 그로부터, 그래프 데이터셋이 가지는 고유한 두 가지 정보 모드(그래프 구조와 노드 특성)를 분리하여 평가하는 새로운 프레임워크 및 새로운 2가지 측정 지표(Performance separability, Mode complementarity)를 제안합니다.
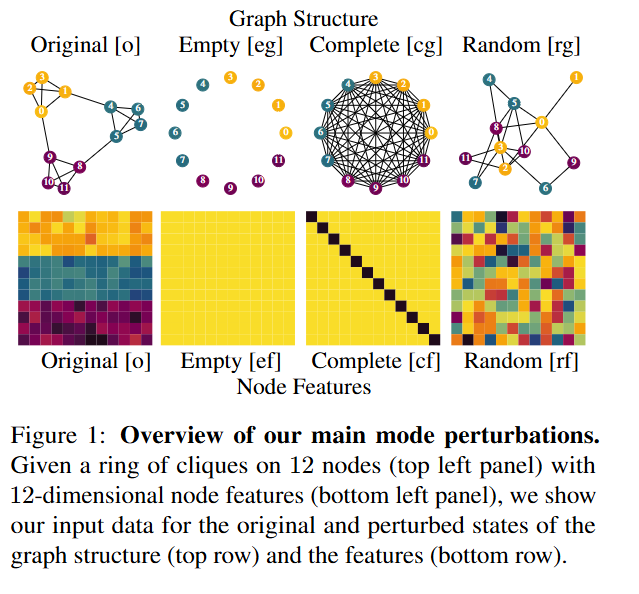
- 기존 그래프 학습 연구에서는, 그래프 구조를 무시하는 방법이 그래프 기반 접근 방식보다 더 나은 성능을 보이는 경우도 있었고, 인기 있는 데이터셋들이 가능한 모든 그래프 공간에서 매우 특이한 부분만을 차지한다는 지적도 있었습니다. 다음을 보완하기 위해, 기존의 모델 평가 방식과는 달리, 평가의 주체를 '데이터셋'으로 전환하는 접근 방식의 RING 프레임워크를 제안합니다.
- Mode perturbation : 좋은 데이터셋이란, 그래프 구조 및 노드 특징의 두 모드가 상호 보완적인 정보를 담고 있어야 합니다. 이 두 모드를 독립적으로 변경하여 본래 데이터셋과 섭동된 데이터셋 간의 매핑 함수로 정의되어, 이들의 표현 차이를 정량화하는 mode-perturbation 개념을 도입하였습니다. 그래프 데이터셋의 그래프 구조와 노드 특성 중 어떤 부분이 특정 학습 작업에 더 중요하게 기여하는지, 또는 두 모드 간에 정보가 얼마나 상호 보완적인지를 정량적으로 평가할 수 있습니다.
- 위 그림은 제안 프레임워크의 핵심 구성 요소인 'mode perturbation'의 주요 유형을 시각적으로 보이고 있습니다. 빈 그래프 및 특징, 완전 그래프 및 특징, 그리고 랜덤 그래프 및 특징을 비교하여, 예를 들어, 빈 그래프로 섭동을 가했을 때 성능이 크게 떨어지지 않는다면, 원래 데이터셋의 그래프 구조가 해당 태스크에 중요하지 않다는 것을 시사합니다.
- 1. Performance separability : 특정 데이터셋 변형에서 학습된 모델의 성능 분포가 다른 변형에서 학습된 모델의 성능 분포와 얼마나 다른지를 측정함으로써 그래프 구조와 노드 특징이 모두 작업 관련 정보를 담고 있는지 평가합니다.
- 원본 데이터셋을 섭동 시킨 후, 원본 데이터셋에 잘 튜닝된 파라미터를 갖는 모델(A)와, 동일한 아키텍처 및 파라미터를 사용하지만 섭동 데이터셋으로 튜닝된 모델 (B)를 기준합니다.
- 평가 메트릭을 사용하여 A, B 모델의 성능을 측정하고, 초기화 조건을 다양하게 설정하여 경험적 성능 분포를 얻습니다. 해당 분포 간의 거리를 측정하기 위해, Kolmogorov-Smirnov 또는 Wilcoxon rank-sum test 방법을 사용합니다.
- 통계적으로 유의미한 차이가 발견되지 않으면, 해당 모드가 태스크 관련 정보를 담고있지 않다고 판단하게 됩니다.
- 2. Mode Complementarity : 그래프 구조 및 노드 특징 모드가 서로 얼마나 보완적인 정보를 제공하는지 평가하기 위해, 각 모드에서 생성된 메트릭 공간 사이의 거리를 측정합니다.
- 각 모드의 메트릭 공간을 생성하는 lift 함수를 정의하고, 다음 함수를 또한 섭동 모드에도 적용하여 섭동 메트릭 공간을 정의합니다. 다음 두 공간을 비교하기 위해 L-norm을 사용합니다. (Def 2.11 참고)
- 그래프 구조에서 파생된 구조적 메트릭과 노드 특징에서 파생된 특징 메트릭 간의 정규화된 거리로 'Mode Complementarity'가 정의됩니다. (Def 2.12 참고)
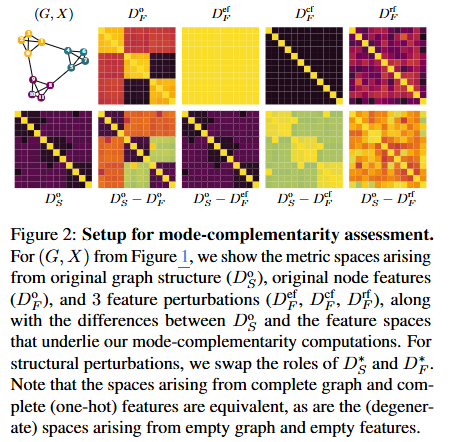
- 위 그림은 mode complementarity를 평가하는 방법을 시각적으로 설명합니다. 상단 행은 노드 특성으로부터 섭동되어 파생된 다양한 메트릭 행렬을 나타냅니다.
- 하단 행은 노드 특성 기반의 다양한 메트릭 행렬과 본래 그래프 구조의 차이를 통해 상호 보완정도를 시각적으로 나타냅니다. 밝을 수록 차이가 크다는 것을 의미하며, 즉 두 모드가 상호 보완적인 정보를 많이 가지고 있음을 의미합니다.
- 하단 2번째의 본래 구조와 특징 사이의 차이는 부분적으로 다른 정보를 제공하여 상호 보완적 관계를 잘 유지한다는 것을 보이며, 마지막의 본래 구조와 랜덤 특성 사이의 차이는 서로 의미 있는 관계를 갖지 않을 가능성이 높으므로 본래 구조의 정보를 더 강조하는 경향을 보일 수 있음을 암시합니다.
- 서로 다른 각도에서 제안된 두 지표는 주어진 태스크 관련 정보의 필요성 및 적합성을 평가하고 데이터셋 자체의 구조적, 특성적 정보가 얼마나 조화롭게 연결되어 있는지의 상호성을 기반으로 그래프 데이터셋의 품질을 측정합니다.
- 제안 프레임워크는 데이터셋 평가 외에도 그래프 학습 모델의 해석 가능성을 높이는 데 활용될 수 있음을 언급합니다. mode complementarity의 변화를 연구하거나, 데이터셋 분할 (train-val-test)에 미치는 영향 등을 분석하여 내부 작동방식 및 성능 간 관계를 밝힐 수 있을 것을 전망합니다. 하지만, 포괄적인 이론적 분석이 충분치 않은 점과 노드 및 엣지 레벨에서의 작업에 대한 확장성은 추가적인 발전이 필요하다고 언급하며, 향후 데이터셋 검증의 방향성을 가볍게 제시합니다.
[Contact Info]
Gmail: jhbae1184@akane.waseda.jp
Twitter (X): @jhbae1184