25년 3월 4주차 그래프 오마카세

GFM-RAG: Graph Foundation Model for Retrieval Augmented Generation
https://arxiv.org/pdf/2502.01113
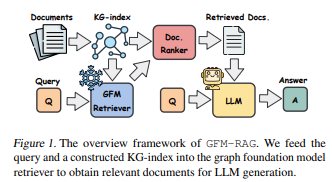
GFM-RAG 리뷰입니다. GraphRAG 개념이 익숙하신 분들이라면, 본 논문 컨셉을 이해하기에 수월하실거라 생각됩니다. GraphRAG의 초반부인 Knowledge graph 만드는 부분과 후반부 Retrieval 결과를 Prompt 에 넣어 Decoding 하는 것은 유사하나 가운데 retrieval 단계에서 GDBMS를 활용하는게 아닌, GNN을 이용한다는게 가장 큰 차이입니다.
핵심은 다음 세 가지라고 할 수 있겠습니다.
1.Retrieval stage에서 Graph Foundation Model를 활용한 방식과 그 이유
2.Document 로부터 Entity를 추출하고, 유저 질의와 매칭하는 방식
3.엔지니어링
이 세 가지는 참고로 논문저자가 언급한 contribution은 아닙니다. 제 관점에서 보는 핵심인데요. 그 이유는 요새 GraphRAG가 관심을 많이 받으며, 많은 분들께서 시도 하고 계시는 와중에 발생하는 Entity 관리를 본 논문에서 잘 해냈다 라고 생각했고, 잘 했다 라고 생각한 3가지 요소를 핵심으로 봤기 때문입니다.
실무에서 활용하기 가장 합리적인 방식이라 생각하는 Neo4j 방법론을 잠시 언급하자면, entity 개별 text 정보를 embedding 하고 해당 feature 기반으로 연결 그리고 clustering . 여기에서 동일 clustering에 속해있는 entity끼리 text distance 연산 후 unifying. 이렇게 진행됩니다. Neo4j Cypher문과 함께인지라, 구체적으로 어떻게 진행되는지가 궁금하시면 링크를 참고해보시면 좋을거 같아요.
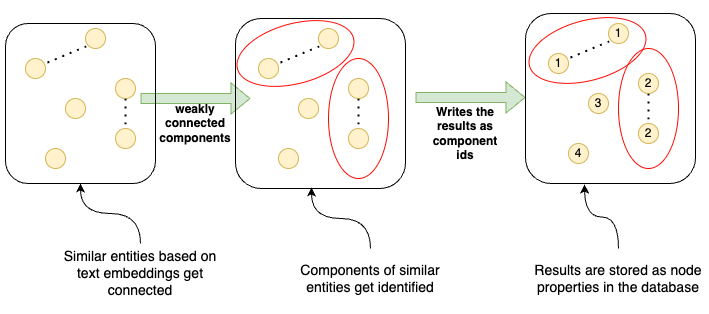
이외에도 Entity Resolution 개괄부터 각 분야마다 어떻게 적용하면 좋을지를 다룬 Neo4j Complete Guide 가 있으니 참조해보시면 좋을거 같네요.
다시 돌아와서, Figure1을 보면, 직관적으로 느껴집니다. GNN 이외에 LLM prompt, Doc Reranking, Entity Extraction & Linking 등 과 같은 부분들에서 관리해야할 포인트들이 많이 있겠음을요. 이 포인트들을 Config에 각기 다른 Parameter를 입력해주며 튜닝과 타 모델들과 연결하며 End2End로 answer까지 만들어줘야할텐데 이를 어떻게 할지 막막하셨을거라 생각되네요.
이 논문에서는 해당 flow 들을 hydra 와 bash 조합으로 깔끔하게 관리해줍니다. 때문에, 마지막 3번째 Entity를 잘 추출하고 이를 answer까지 갈 때 과연 어떻게 갈지 힌트를 줄 수 있는 엔지니어링 스킬이 담겨 있기에 본 논문을 추천드립니다.
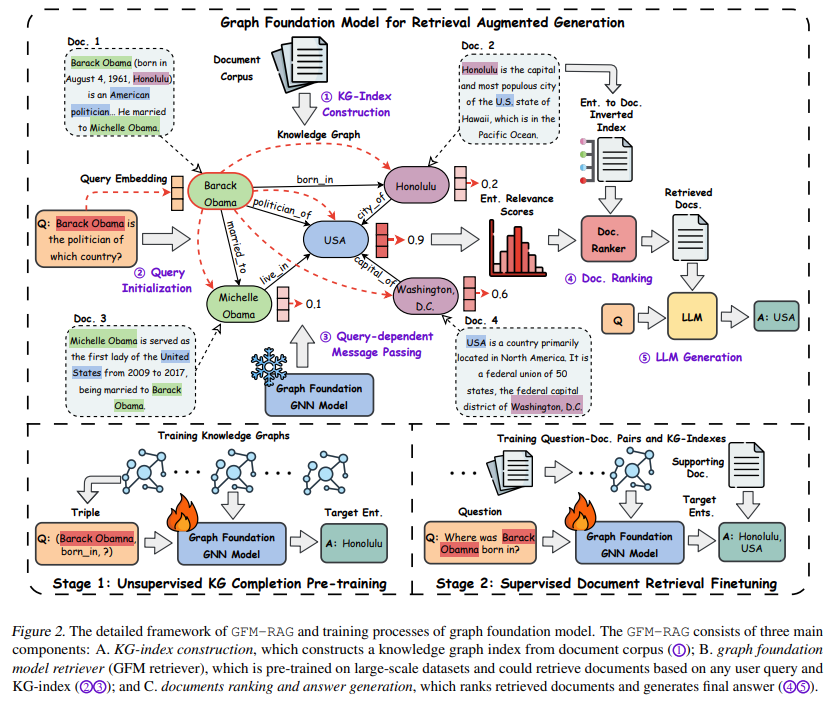
Figure2에 나와 있는 5가지 단계를 각각 풀어보겠습니다. 위쪽 dashed line은 GFM-RAG 개요 아래쪽 dashed line은 GFM pretraining 과 Finetuning 하는 과정이 그려져 있습니다.
1.KG-Index Construction
Document Corpus 에서 Entity 를 추출하고 이를 Indexing 하는 단계입니다.
간단해보이지만, 내부에는 세부 3단계로 구성되어 있습니다.
- Document의 Passage(chunk와 유사) 를 넣고 Entity를 추출
- 추출된 Entity 가 무슨 객체인지 라벨링하는 단계
- 라벨링 되어있는 엔티티들끼리 무슨 Link가 있는지를 인지하고 라벨링하는 단계
이로써, Triple 데이터셋 이 완성됩니다. 다시말하면, Knowledge graph가 만들어진거죠. 여기에서 대부분 고민하는 부분인 Entity resolution을 어떻게하는지가 궁금하실텐데요. 그 부분은 다음과 같습니다.
# gfm-rag/gfmrag/kg_construction
logger.info("Adding synonymy edges")
for phrase, neighbors in tqdm(sim_neighbors.items()):
synonyms = [] # [(phrase_id, score)]
if len(re.sub("[^A-Za-z0-9]", "", phrase)) > 2:
phrase_id = kb_phrase_dict[phrase]
if phrase_id is not None:
num_nns = 0
for neighbor in neighbors:
n_entity = neighbor["entity"]
n_score = neighbor["norm_score"]
if n_score < self.threshold or num_nns > self.max_sim_neighbors:
break
if n_entity != phrase:
phrase2_id = kb_phrase_dict[n_entity]
if phrase2_id is not None:
phrase2 = n_entity
synonyms.append((n_entity, n_score))
graph[(phrase, phrase2)] = "equivalent"
num_nns += 1간단하게 말해보면, threshold와 최대 이웃 제한을 걸어둡니다. entity 별 score가 있고, 너무 많은 중복을 막기 위해 max sim neighbor 2가지를 condition으로 걸어둔거죠. 자세한 코드는 맨 위 주석 경로에서 볼 수 있습니다.
2.Query Initialization
이 부분은 간단합니다. 유저의 질의가 들어오면 이 질의를 sentence-transformer 를 활용해 임베딩해주는 단계입니다.
3.Query-dependent Message Passing
만들어진 GFM-Retrieval을 활용해 앞 단계에서 추출된 Embedding , Document 그리고 Knowledge graph 3개의 input을 넣어줍니다.
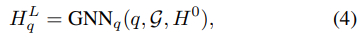
q 는 query , G는 Knowledge Graph (indexed) , H^0 은 entity intial feature입니다. initial feature는 sentence-transformer의 결과물입니다.
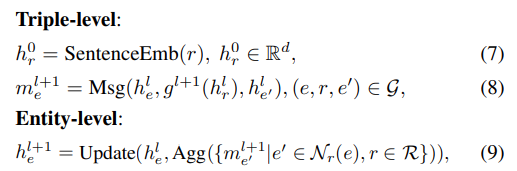
각 layer를 거치며, 초기에 만들어둔 document로부터 추출한 knowledge graph의 head , relation , tail (triple) embedding 값들이 message passing 되고, 최종적으로 entity-level 딴에서는, 각각의 entity 들이 연결되어 있는 neighbor entity 들의 weight를 aggregation 해서 structural 와 semantic 정보를 가지게 되는거죠. 이 값들이 결국 query 와 entity 값의 관련성을 비교하는 매체가 되고, 관련성이 높은 엔티티가 있는 document들을 추출해서 reranking stage 로 보냅니다.
4.Doc Ranking
위 Retrieval 결과로 top-k 개의 document가 추출됩니다. 주의할점은, Document마다 자주 언급되는 Entity가 있을것이고,반대로 그렇지 않은 Entity가 있을텐데 '자주' 언급된다하여 해당 문서와 쿼리가 연관성이 높다라고 할 수 없기에 이를 조정해주는 장치가 필요합니다. 이를 위해 IDF를 활용합니다. 기존에 저희가 자주 이용하던 TF-IDF와 동일합니다.
5.LLM Generation
Reranked Document와 Query를 LLM 에 주입하여 decoding 하는 단계입니다.
위에 이것저것 작성해놓았지만, 사실 아래 3개의 notation으로 이 논문을 정리할 수 있습니다. 인덱싱하고, Retrieval 하고, LLM에게 query와 Retrieved document를 prompt로 입력해줘서 답변 도출.
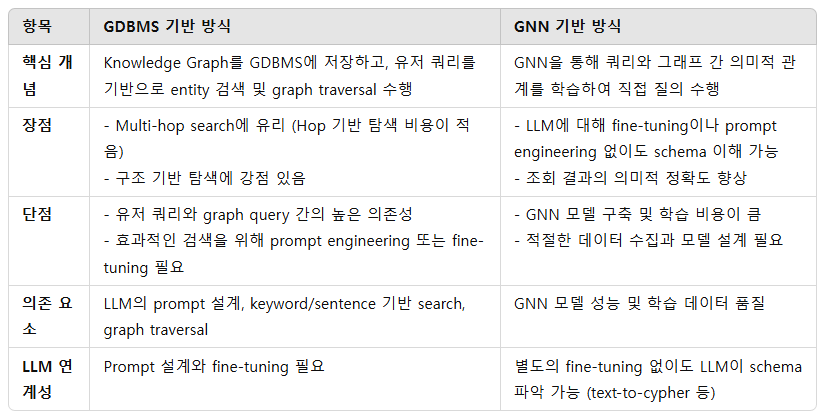
RAG에 굳이 Graph Foundation Model를 활용한 이유
- Graph Semantic & Structure 을 Retrieval에 적용하기 위함. 이 부분을 기존과 비교해보면, GDBMS에 적재해놓은 Knowledge graph와 Query 유사도를 비교하기 위해 Query에서 Keyword & Sentence search 한 뒤, 도출된 entity 기반 graph traverse 가 발생하는것이라고 할 수 있습니다.
- 각각 장단이 뚜렷한데요. 본 논문의 방법론은 GNN 의 구축 비용이 많이 드는것에 비해 text2cypher과 같은 schema 를 LLM에게 인지하기 위해 fine-tuning 이나 prompt engineering 을 하지 않아도 된다.
- 즉, 조회에 대한 불확실성을 줄일 수 있다. 이고, 반면에 주로 활용하는 방식은 GNN 구축 비용이 적어지는 대신, GDBMS의 Search를 활용하기 위해 유저 Query 그리고 Graph Query 의존성이 높아진다 라는 점을 들 수 있겠습니다. GDBMS vs. GNN이라고 봐주시면 될 거 같아요.
- 만일 multi-hop 쿼리가 중요한 상황이라면 GDBMS, 그렇지않고 entity resolution & query matching이 중요한 상황이라면 GFM을 활용하는게 좋을거 같아요.
Document 로부터 Entity를 추출하고, 쿼리와 매칭하는 방식
- Query와 Entity를 비교하기 위해선 결국 Document 에서 Entity를 추출해야하고, 그 Entity 들간 관계를 만들어줘야합니다. 여기에선 기존 OpenIE를 활용했던 걸 LLM 를 활용했구요. 그렇게 Entity 추출을 하고, Entity Linking 이 되었으면
엔지니어링.
- Foundation Model 하면 생각나는 키워드가 몇 개 있죠? 그 중 제가 어렵다고 생각되는 키워드 두 개는 바로 대용량 데이터 전처리 및 모델에 올리기 입니다. 1에서 언급된 General 한 지식을 토대 삼아 RAG specific inference 를 하기 위해선, 우선 General dataset을 학습시켜야겠죠. 여기에서는
- 참고로 학습을 위해 A100 8대 (80G), 총 파라미터는 8M 라고 합니다. 데이터셋은 총 700k document로부터 60 개의 KG를 만들었고, 총 14M triple를 학습했다 라고 합니다.
- 뿐만아니라, Retrieval tool로 colbert, dpr(dense passage retrieval) 를 활용한 코드, Node state update 발견할 수 있습니다. 이외에도 엔지니어링 측면에서 레퍼런스 삼을만한 부분이 많은 논문입니다. 꼭 코드도 함께 보시는걸 추천드립니다.
요즘 GPT 덕분에 논문 읽기가 이전대비 수월해졌습니다. 논문을 리뷰하는 형태보다 제가 논문을 보며 GFM-RAG 와 연관성 있는 부분을 질문 형태로 바꾸어 봤습니다. 질문에 해당하는 내용들이 궁금하면, 논문을 GPT attach 로 넣어 답변을 얻는게 효율적인지 않을까 하여 새로운 방식으로 접근해봤네요. 저희의 시간은 소중하니깐요.
Position: Graph Foundation Models are Already Here (research)
https://arxiv.org/pdf/2402.02216
GFM 만들때 발생하는 negative transfer을 방지하기 위해 고려해야하는 것들 부터 시작해서 node, link , graph prediction 할 때 알아두면 좋을 principle 들이 좋음.
- 핵심은 ‘across different domains and tasks‘ 임. 이를 Network analysis, expressiveness, and stability 원리를 활용해서는 어떻게할것인가? 특히, expressiveness 와 stability 차이는 ?
- Graph vocabulary 가 핵심이라 하는데 어떻게 이를 구축하면 좋을지?
- 대표적인 GFM 모델들은 무엇이 있고, 그 중 GFM-RAG 에서 활용한 ULTRA 라는 모델은 무엇일까? 어떻게 흥행의 주역이 되었을까?
- 성공적인 GFM 구축을 위해 고려해야할 것들 새로운 relationship 이 등장할 때 이를 인지하고 어떤 노드와 연결이 되는지를 판단하는 알고리즘이 필요하다. 이때, 무엇이 필요할까?
- Node prediction (entity resolution - 여러개의 entity 가 종합되어 있을때, 이를 구하기)
- Graph vocabulary 를 구축했다고 한들, 이를 활용해서 추론하는 GFM 이 적절하게 작동한다라는걸 판단하기 위해 Homophily , Heterophily 라는 지표가 존재한다는데 이는 과연 무엇일까?
- Link prediction (온톨로지를 구축해서 Knowledge graph 까지 만들었으나, 새로운 관계가 발생할 수 있다.이때, 어떻게 추론하면 좋을까)
- 평소에 link prediction 시, 성능 개선이 어려운 부분들이 많았었다. 여기에서는 node similarity 를 local side 뿐만아니라, global side 로도 접근한다는데 어떻게 접근한다는 걸까?
- 준지도학습 방법론으로 유명한 GNN, 연결되어 있는 Node pair 간의 의존성을 기반으로 labeling 을 할 수 있는 방식들이 존재하는데, 이 방식들이 GFM 과 어떤 연관성이 있을까?
- 분명 GNN task들간의 연관관계가 존재할 것이고, 이 연관관계를 활용해서 학습을 하면 유리할 부분이 있을거 같은데 과연 무엇일까?
- Foundation Model 신에서 자주 언급되는 Neural Scaling Law , Graph Foundation Model에서는 언제 어떻게 등장할까? (개인적으로 4.1. 모두 읽어보셨으면 하네요.) ‘The key concern is whether graphs can strictly follow those principles. Uncertainty can be found on the human-defined graph construction criteria. For instance, the construction knowledge relying on expert knowledge may lead to uncertainty in edges.' 라는 부분이 현재 저희들이 겪고있는 가장 큰 문제를 잘 짚어주었기 때문입니다. 논문 저자들은 위 부분과 GFM을 어떤 관점으로 문제 정의하고 해결할 수 있었는지를 음미해보시죠.
- Data / Model scaling 을 위해 각각 graph generation , Vanila gnn vs. graph transformer 등 접근 방식이 다르다는데 그 접근 방식이 왜 다르고, 왜 그렇게 접근하는걸까?
Graph Foundation Models: Concepts, Opportunities and Challenges
https://arxiv.org/pdf/2310.11829
GFM(Graph Foundation Model) 개념잡기 좋다. 기존 서베이 논문들은 Text 관점이 배제된채 GFM 을 언급했다면, 본 논문은 두 관점을 잘 작성해두었음. 톮아보기에 좋은 논문.
- 텍스트에서 Foundation Model 과 그래프에서 Foundation Model 이 무슨 차이인지.
- Graph Foundation Model 좋아보이는데 과연 어떤 한계점이 있는지.
- Massage Passing 그리고 Graph Transformer의 차이점.
- Graph Pre-training 모델을 만드는건 어려우니, Fine-Tuning 이나 Prompt Tuning (pre,post)를 하는게 합리적임. 과연 GraphRAG 를 위해 만들어놓은 그래프 스키마를 여기에 어떻게 적용할 수 있을까?
- LLM 접근 방식은 어떻게 될까. GraphRAG에서 자주 언급되는 Graph-to-token(soft prompt) , Graph-to-text(hard prompt). 만일 위 방식들을 활용해야한다고 할때, 주의해야할 점들이 무엇일까.
- 위 prompt 분류해서 LLM inject & alignment 활용하는거도 벅찬데 만일, hard prompt 를 활용했을때 일일이 prompt 를 만들어서 해야하는건가? 혹은 그렇지 않은 방식도 존재하는 걸까? Manual / Automatic Prompting 관점이 존재한다는데 어떻게 활용하는걸까?
- GNN + LLM based Model - 서로 조화롭게 활용하는 방식은 없을까? GNN-based model은 직접 텍스트를 처리하고 예측할 수 없고, LLM-based model은 multi-hop logical reasoning 과 같이 특정 개체간의 관계를 연속적으로 탐색해서 답변을 내놓는데 제한이 있는 등 …