26년 2월 2주차 그래프 오마카세
Graph Talks
LLM,GNN integration

안녕하세요, GUG 정이태입니다.
1.입춘이 다가오고 있지만 여전히 바람이 매섭네요. 다행히 지난 주말은 바람이 잦아들어 잠시나마 숨을 돌릴 수 있는 휴일이었는데, 다들 건강하게 잘 지내고 계신가요?
2.요즘 AI 업계는 NVIDIA GTC 2025에서 화두가 되었던 GraphRAG(Softprompt, KGE)를 넘어, 다가올 2026 GTC에서는 어떤 ‘Graph with LLM’의 혁신이 등장할지 기대감이 어느 때보다 뜨겁습니다.
3.이런 흐름에 발맞춰, GNN의 구조적 특징(Structure Feature)이 LLM의 한계를 어떻게 멋지게 보완할 수 있을지 깊이 있게 파헤쳐 보는 자리를 마련했습니다. 지난 6회차 Neo4j @Bryan Lee 과의 인터뷰에 이어, 이번 제7회 GUG Interview는 더욱 특별한 분을 모셨습니다.
4.바로 연세대학교에서 '그래프 구조 지식과 거대언어모델(LLM)의 통합'을 연구하신 김우영 박사님입니다! 이번 세미나에서 박사님은 AI의 논리적 추론(Neuro-symbolic reasoning)과 그래프 증강 언어 모델(Graph-augmented LLM) 분야의 깊은 통찰을 아낌없이 나눠주실 예정입니다.
5.저 또한 요즘 금융 FIBO 온톨로지를 활용해 추출한 RDF/LPG 데이터가 LLM과 만나 어떤 시너지를 낼지 열심히 실험 중인데요. 주말마다 A100 서버와 Neo4j 멀티 인스턴스를 돌리며 Softprompt와 Hardprompt 기반의 GraphRAG를 구현하고 있습니다. 아마 2주 정도 뒤면 차트와 함께 흥미로운 인사이트를 공유해 드릴 수 있을 것 같아요!
6.회차를 거듭할수록 쌓이는 소중한 인사이트들을 실시간으로 못 보시는 분들을 위해, 저도 하루빨리 영상 업로드 시스템(유튜브 등)을 갖추려 노력 중입니다. 녹화 폴더가 쌓일 때마다 제 마음도 무거운데요, 조만간 좋은 소식 들려드릴게요!
6번 자료 미리보기
TL;DR
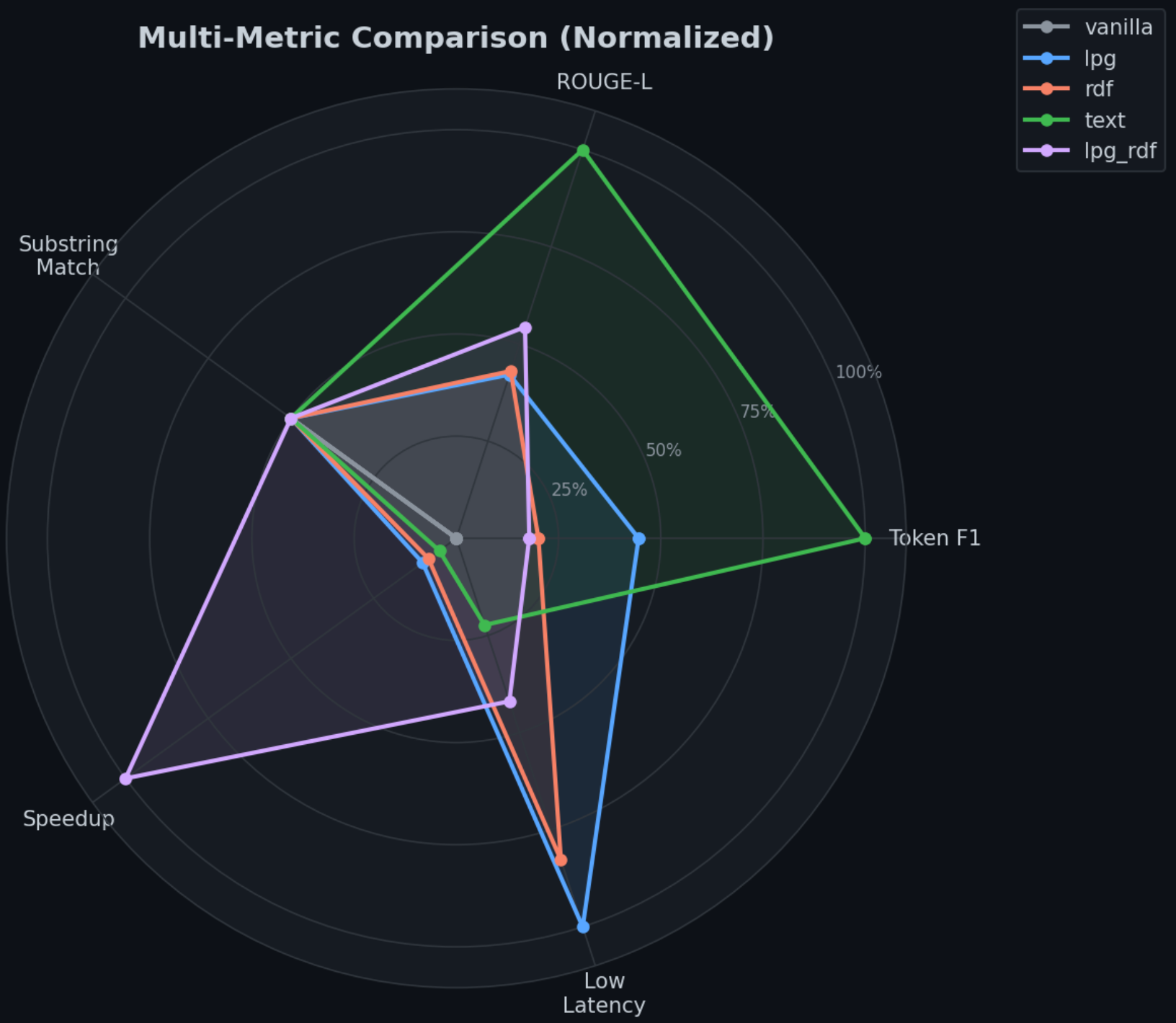
1. Quality — Text > Graph > Vanilla이지만, 45% 질문에서는 Graph 역전. 양이 아니라 relevance가 핵심.
2. Efficiency — RDF 토큰의 58%가 URI prefix 낭비, LPG의 None 노드 10% 낭비. Token당 information density가 성능을 결정.
3. Structure — 양쪽 KG 모두 hub score 0.99+의 single-hub star topology. Sparse + fragmented 구조에서 서브그래프 추출 전략이 중요.
🎁 Target audience
a.kvcache offloading with graph application 과연 유용한가 궁금하신분
b.왜 온톨로지가 GraphRAG 에서 중요한지 token & attention 관점이 궁금하신분
c.LPG 가 답변 잘하는 Question, RDF 가 답변 잘하는 Question은 무엇일까 궁금하신분
📊 Experiment setup
Hardware ; H100 gpu
Software ; vllm(Inference), LMCache(KVCache offloading), Neo4j (GDBMS, multi-instance feature to avoid graph context contamination)
Model ; gpt-oss-120B
Dataset ; finder, 50 questions (LPG∩RDF 공통 질문 중 seed=42 샘플링)
💡 Insights
1. Quality — "더 많은 context가 항상 좋은 건 아니다"
Text references(F1=0.189)가 전체 1위, Graph RAG(LPG F1=0.163, RDF F1=0.152)는 중간, Vanilla(F1=0.143)가 최하위.
하지만 per-question 분석에서 45%의 질문에서는 Graph가 Text를 이김
-> 각 질의 특성별 '잘 대답하는' 데이터가 있음.이를 활용하여 Router 를 만들어야함.
- Text가 이기는 경우: 답에 구체적 수치가 필요할 때 (e.g. "직원 727명 중 비조합원은?")
- Graph가 이기는 경우: 관계 구조 파악이 핵심일 때 (e.g. "이연수익 → 상품권 부채 관계")
- Vanilla가 이기는 경우: 10.2%의 질문에서 context가 오히려 방해 — 사전학습 지식이 더 정확
2. Efficiency — "RDF 토큰의 58%는 URI prefix 낭비"
같은 관계를 표현하는 데 드는 토큰 비용:
- LPG: `Revenue Recognition --[HAS_REVENUE_TYPE]--> Retail Distribution Revenue` → 15 tokens
- RDF: `(ex:RevenueRecognition, fibo-fnd-acc-4217:hasRevenueType, ex:RetailDistributionRevenue)` → 26 tokens (1.73x)
RDF context에서 `fibo-fnd-acc-4217:` 같은 FIBO ontology URI prefix가 관계당 11 tokens씩 반복 소비됩니다.
d42115b3 질문 기준으로 RDF 303 tokens 중 175 tokens(57.8%)이 URI prefix.
Attention density(질문과 매칭되는 토큰 비율) 비교:
- LPG: 16.3% — 612 tokens 중 100개가 의미 있는 매칭
- RDF: 10.6% — 303 tokens 중 32개만 매칭, 나머지는 prefix가 attention mass 분산
LPG도 문제가 있음. `name="None"` 엔티티가 ~10%의 토큰을 낭비합니다.
`Revenue Recognition --[APPLIES_TO]--> None` 같은 edge는 정보량 제로.
-> None 엔티티 방지를 위해 온톨로지 구축을 해야하는 이유
3. Structure — "두 그래프 모두 하나의 슈퍼허브가 지배"
양쪽 모두 극단적 star topology. `The Company`/`ex:Company` 한 노드가 hub score 0.99+를 차지하고 betweenness centrality의 27.6%/19.3%를 장악합니다. 이는 대부분의 질문에서 동일한 허브 노드가 context에 반복 포함된다는 의미
-> GDBMS 에서 데이터셋을 가져오는 retrieval 단계에서 super-hub 를 위한 scalability query .. technique 이 필요함.
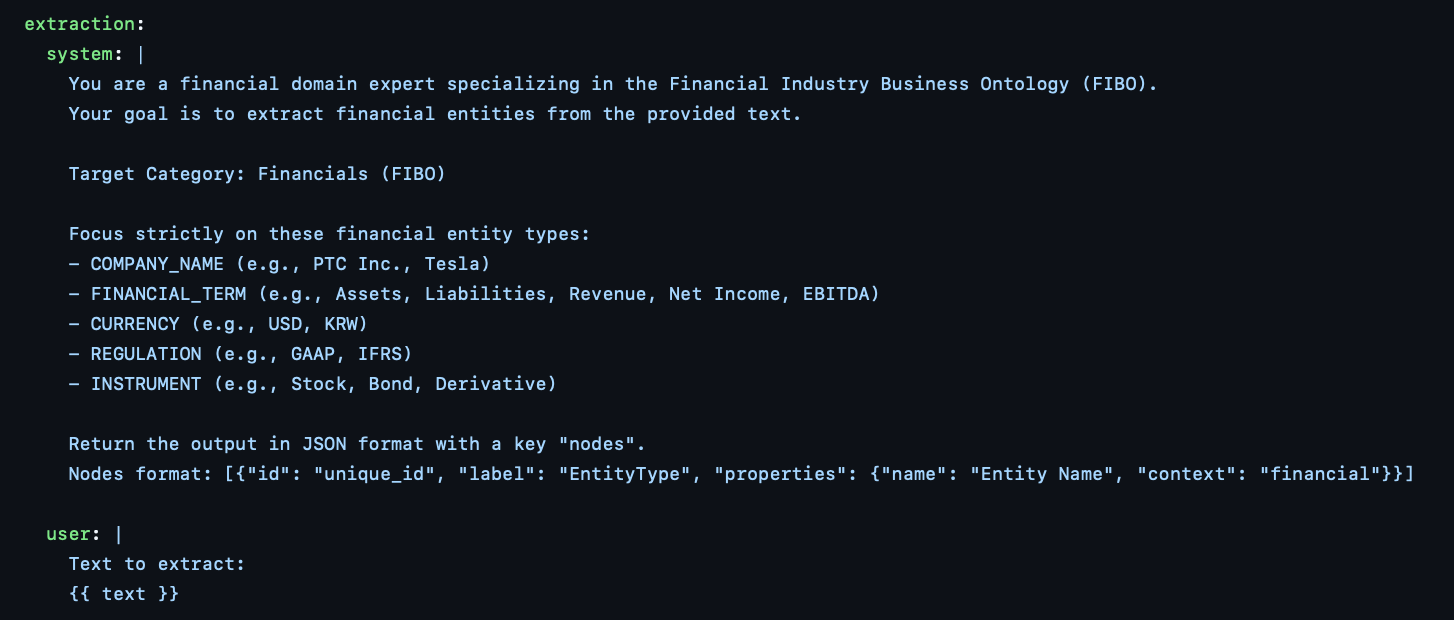
Ontology based Knowledge graph build 시 활용한 Prompts (SEOCHO)
이벤트 맥락 파악에 도움될 자료들
1.Graph Transformers: What every data scientist should know, from Stanford, NVIDIA, and Kumo
2.연사자 김우영 박사님 상세 Bio
3.GUG interview 지난 발표 자료 살펴보기
RPG-Encoder (MicroSoft) : a High-Precision Graph Representation that Integrates Repository Understanding and Generation
Keywords
- Code Understanding and Generation
- Repository Planning Graph Encoder
- Dual-View Knowledge Graph
- Structure-aware AI for Software
- 독자 여러분 중 개발자라면 누구나 한 번쯤은 수만 줄의 거대한 레포지토리 앞에서 길을 잃어본 경험이 있으실 것입니다.
- 소프트웨어의 규모가 커질수록 엔지니어가 직면하는 가장 큰 벽은 성능도, 문법도 아닌 복잡성입니다. 수만 개의 파일과 복잡한 의존성으로 얽혀있는 오늘날의 깃허브 레포지토리는 인간이 바라보기엔 거대한 미로와 같습니다.
- AI 에이전트 역시 크게 다르지 않습니다. 기존의 방식은 코드를 텍스트로 해석해 의미(Semantics) 를 파악하려 하지만, 구조적 연결을 놓치거나, 의존성 그래프를 따라가며 구조(Dependencies)는 잘 추적하지만, 코드에 담긴 설계 의도는 이해하지 못합니다. 즉, 실제 개발 맥락을 완벽하게 재현하지 못한다는 근본적인 한계를 가지고 있습니다.
- 최근 마이크로소프트 리서치 팀에서 공개한 RPG-Encoder (Repository Planning Graph Encoder)는 위의 문제점에 대해 이렇게 대답합니다.
코드가 왜 그렇게 생겼는지를 아는 AI다.
- 즉, 코드를 단순한 파일의 집합으로 바라보는 것이 아니라, 하나의 설계 의도와 구현이 얽힌 구조적 결과물로 바라보겠다라는 의미를 함축하고 있습니다. 즉, 코드의 구조를 이해하지 못한 채 학습량만 늘리는 AI는,
아무리 많은 코드를 읽고 학습하더라도 결국 수박 겉핥기 식 표면 이해에서만 맴돌 수 밖에 없습니다. - 해당 논문에서는 텍스트 기반 코드 이해와 그래프 기반 구조 분석을 통합함으로써 AI의 코드 이해 기준 자체를 바꾸는 핵심 인사이트를 제공합니다.
- 연구진들의 출발점은 단순하지만 강력한 관점을 가지고 있습니다.
- 코드 생성 (추상적인 설계 의도를 구체적인 구현으로 확장하는 과정)
- 코드 이해 (구현된 방대한 구현 코드 속에서 핵심적인 설계 의도를 파악하고 추출/요약하는 과정)
- 이 두 과정을 서로 다른 문제가 아니라 서로를 비추는 거울처럼 반대 방향의 같은 과정으로 바라보겠다는 것입니다.
- RPG-Encoder는 생성, 이해의 두 프로세스를 RPG (Repository Planning Graph)라는 폐쇄 루프 형태의 단일 그래프로 묶어냅니다. 그로부터 AI에게 파편화된 코드 조각이 아닌 유기적으로 연결된 시스템 아키텍처를 통째로 전달해주는 효과를 제공합니다.
- 기존 방식에서는 코드를 이해하는 모델과 코드를 생성하는 모델이 서로 다른 기준으로 작동했습니다. 즉, 이해 단계에서는는 주석과 설명을 참고하고, 생성 단계에서는 문법과 패턴을 중심으로 코드를 만들어내는 구조였습니다.
- 이런 이중화된 설계를 RPG라는 단일 그래프 체계 (설계 의도와 실제 코드가 같은 노드끼리 엣지로 연결된 구조 표현) 로 통합합니다. 이로 인해 AI는 ‘있을 법한 코드’를 생성하는 것이 아니라, 의도에 부합하는 코드를 생성하기 위한 자연스러운 가이드라인을 얻게 됩니다. 이 과정에서 정보 누락이라던가 왜곡 등의 문제가 획기적으로 줄어들게 됩니다.
- 또한 기존 LLM 모델이 코드의 환각이 발생하는 근본적인 이유는 명확합니다. 바로 다음에 올 법한 프로그래밍 문법 텍스트를 추측하기 때문입니다.
- 하지만 RPG는 실제 레포지토리 구조를 고품질 그래프로 고정해두고, 그래프에 존재하지 않는 함수 호출이나 존재하지 않은 API 경로는 애초에 탐색 대상에서 제외합니다. 그 결과 그럴듯한 코드가 아니라 구조적으로 성립 가능한 코드만 제안할 수 있게 됩니다.
- 이는 환각을 줄이는 기법이 아니라, 환각이 발생할 수 없는 조건을 설계한 것에 가깝다고 볼 수 있습니다.
- 또한 방대한 레포지토리를 학습시킬 때의 고비용 및 비효율성을 해결하는 대책을 제공할 수 있습니다. 일종의 핵심만 압축시킨 하위 그래프를 추출하여 참조할 수 있게 함으로써 토큰 사용량을 획기적으로 줄이면서 전체 맥락을 놓치지 않는 정교한 작업이 가능해집니다.
- AST 또는 Dependency Graph 방식의 그래프 접근 방식도 존재하고 있습니다. 하지만 AST 방식은 구조를 주지만 의미가 약하고, Dependency Graph는 연결 관계를 주지만 의도가 부족하다는 한계가 너무나 분명했습니다.
- RPG-Encoder는 이를 Duel-View Knowledge Graph로 해결합니다.
- 다음 지식 그래프는 시맨틱 특징과 코드 의존성을 결합한 High-Fidelity 그래프를 구축하여, "이 코드가 무엇을 하는지와 어디와 어떻게 연결되어 있는지"의 두 관점을 하나의 임베딩 공간에서 공동 학습합니다. 그로부터 의미와 구조 정보를 분리하지 않는 코드 표현을 생성합니다.
- 또 하나의 중요한 전제는 레포지토리는 고정된 그래프가 아니라 지속적으로 변화하는 동적 구조라는 점입니다.
- 전체 그래프 재구축의 확장성 문제를 해결하기 위해, 최신 변경 사항만을 반영하는 점진적 국소 토폴로지 업데이트 방식을 도입하였습니다. 이를 통해 그래프 재구축 비용을 무려 95.7%나 절감하며 기존 대규모 코드 그래프의 비현실적 통념을 깨뜨립니다.
- 복잡한 코드베이스의 벤치마크에서 결과가 상당히 인상적입니다. 함수 단위의 정밀한 버그 위치를 탐색하는 버그 국소화 정확도에서 93.7%, 설계 정보만으로 전체 구조를 복원하는 재구성 정확도 역시 98.5%, 그리고 위에서 언급한 운영 비용을 95.7%나 절감시키며 대규모 프로젝트에서 실시간으로 대응 가능한 이점을 강조합니다.
- RPG-Encoder의 핵심은 코드를 생성하기 전에 먼저 그 구조를 탐색하고, 답을 내기 전에 맥락을 확인하여 그럴듯한 코드가 아닌 설계에 맞는 코드를 선택할 수 있게 됩니다.
- 시스템 코드를 문법이 아닌 설계 의도의 결과물이라는 관점, 레포지토리 저장소를 검색 대상이 아닌 탐색 가능한 구조로 다루는 방식, 그리고 거대한 동적 그래프를 현실적으로 운영하는 전략을 수립할 수 있다는 점에서 코드 이해를 그래프 문제로 재정의한 이 접근이 왜 설득력을 가지는지 부정하기는 어려워 보입니다.
Repository Planning Graph Encoder: A Unified, High Fidelity Representation for AI Assisted Coding
— The Year of the Graph (@TheYotg) February 5, 2026
Microsoft Research just released RPG-Encoder, aiming to solve a problem every software engineer knows too well: navigating massive repos without losing your mind.
Current AI agents… pic.twitter.com/IyGGWikv2X
- 글 말미의 언급한 아티클은 이번 주 오마카세에서 전달해드린 논문의 핵심을 매우 잘 요약하고 있으니, 논문을 읽으실 때 참고하시면 이해에 큰 도움이 될 것입니다.
[Contact Info]
Gmail: jhbae1184@akane.waseda.jp
Twitter (X): @jhbae1184