26년 2월 3주차 그래프 오마카세
RAG-ANYTHING: ALL-IN-ONE RAG FRAMEWORK
RAG-Anything: All-in-One RAG Framework
Retrieval-Augmented Generation (RAG) has emerged as a fundamental paradigm for expanding Large Language Models beyond their static training limitations. However, a critical misalignment exists between current RAG capabilities and real-world information environments. Modern knowledge repositories are inherently multimodal, containing rich combinations of textual content, visual elements, structured tables, and mathematical expressions. Yet existing RAG frameworks are limited to textual content, creating fundamental gaps when processing multimodal documents. We present RAG-Anything, a unified framework that enables comprehensive knowledge retrieval across all modalities. Our approach reconceptualizes multimodal content as interconnected knowledge entities rather than isolated data types. The framework introduces dual-graph construction to capture both cross-modal relationships and textual semantics within a unified representation. We develop cross-modal hybrid retrieval that combines structural knowledge navigation with semantic matching. This enables effective reasoning over heterogeneous content where relevant evidence spans multiple modalities. RAG-Anything demonstrates superior performance on challenging multimodal benchmarks, achieving significant improvements over state-of-the-art methods. Performance gains become particularly pronounced on long documents where traditional approaches fail. Our framework establishes a new paradigm for multimodal knowledge access, eliminating the architectural fragmentation that constrains current systems. Our framework is open-sourced at: https://github.com/HKUDS/RAG-Anything.
GitHub - HKUDS/RAG-Anything: “RAG-Anything: All-in-One RAG Framework”
“RAG-Anything: All-in-One RAG Framework”. Contribute to HKUDS/RAG-Anything development by creating an account on GitHub.
- LLM이 빠르게 발전하고 있지만, 여전히 모델이 학습한 범위 밖의 최신 지식이나 사내 문서에 대해서는 답하지 못한다는 한계가 있습니다. 이를 해결하기 위한 방법으로 RAG가 사실상 표준 아키텍처로 자리 잡았습니다.
- 하지만 우리가 실제로 사용하는 문서는 텍스트만으로 구성되어 있지 않습니다. 보고서에는 표와 그래프가 있고, 논문에는 수식과 도식이 있으며, 매뉴얼에서는 이미지와 레이아웃 자체가 중요한 의미를 가집니다. 기존 RAG는 이러한 요소를 충분히 활용하지 못했습니다.
- 자연스럽게 멀티모달 RAG의 필요성이 대두하였습니다. 멀티모달 RAG가 중요한 이유는 단순히 기능적 확장이 아니라, 문서의 의미가 형성되는 방식 자체를 보존한 채 이해하려는 시도라는 점에서 의미가 있습니다. 즉, 정보의 내용뿐 아니라 정보가 표현된 형태까지 지식으로 취급하는 방향으로 RAG가 진화하고 있는 것입니다.
- 이번 주 오마카세에서는 기존 RAG 시스템이 멀티모달 정보를 처리하는 과정에서 겪었던 한계를 새로운 프레임워크, RAG-Anything가 어떻게 구조적으로 해결하였는지 그 핵심만을 간추려보고자 합니다.
- 실제 환경의 지식 저장소는 텍스트, 시각적 요소, 구조화된 표, 수학적 표현이 복합적으로 얽혀 있는 멀티모달 구조입니다. 그러나 기존 RAG 프레임워크는 주로 텍스트 데이터에만 집중되어 있어 이미지나 표에 담긴 핵심 정보를 텍스트로 변환하는 과정에서 정보 손실이 발생하거나, 아예 검색 대상에서 제외되는 경우가 많았습니다. 이러한 한계는 학술 연구, 재무 분석, 기술 문서처럼 비텍스트 정보의 비중이 큰 분야에서 특히 크게 드러납니다.
- 멀티모달 RAG의 핵심은 기능의 확장이 아니라 문서의 의미 구조를 보존하는 지식 표현 방식의 변화에 있습니다. 이를 위해 RAG-Anything은 세 가지 기술적 접근을 제안합니다.
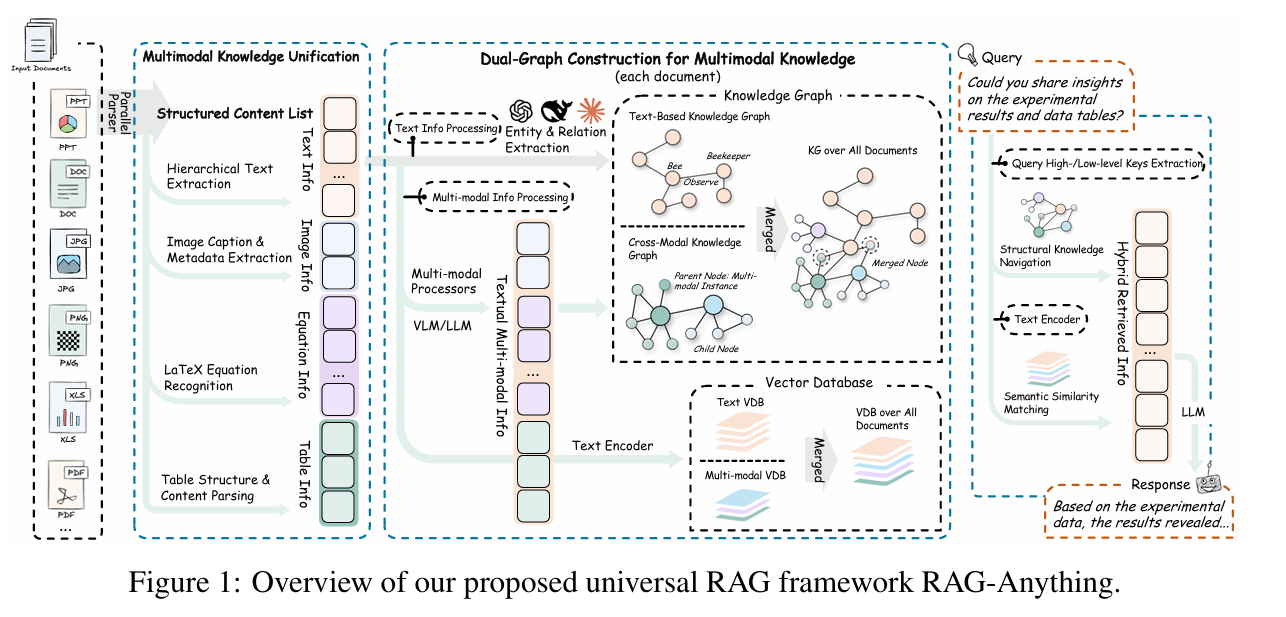
- 멀티모달 지식 통합 (Multimodal Knowledge Unification): 첫 단계에서는 문서를 단순한 텍스트 조각이 아니라 의미 단위인 Atomic Unit으로 분해합니다. 예를 들어 하나의 그림은 캡션과 함께 묶이고, 수식은 이를 설명하는 문장과 연결됩니다. 이렇게 구성된 단위는 서로 독립된 데이터가 아니라 상호 연결된 지식 엔티티로 재정의되며, 문서의 구조적 맥락이 그대로 유지됩니다.
- 이중 그래프 구조 (Dual-Graph Construction): 다음으로 이중 그래프 구조를 통해 두 가지 지식 표현을 동시에 구축합니다. 하나는 모달리티 간 관계를 표현하는 교차 모달 지식 그래프이고, 다른 하나는 텍스트 의미를 중심으로 한 그래프입니다. 이 두 그래프를 통합하면 특정 표가 어떤 문단을 설명하는지, 특정 그래프가 어떤 실험 결과에 해당하는지를 맥락 속에서 탐색할 수 있습니다.
- 교차 모달 하이브리드 검색 (Cross-modal Hybrid Retrieval): 검색 단계에서는 그래프 기반의 구조적 탐색(Structural Navigation)과 밀집 벡터 기반의 의미론적 매칭(Semantic Similarity Matching)이 결합됩니다. 그 결과 사용자가 텍스트로 질문하더라도 모델은 이미지나 표에 포함된 정보까지 정확하게 찾아낼 수 있습니다.
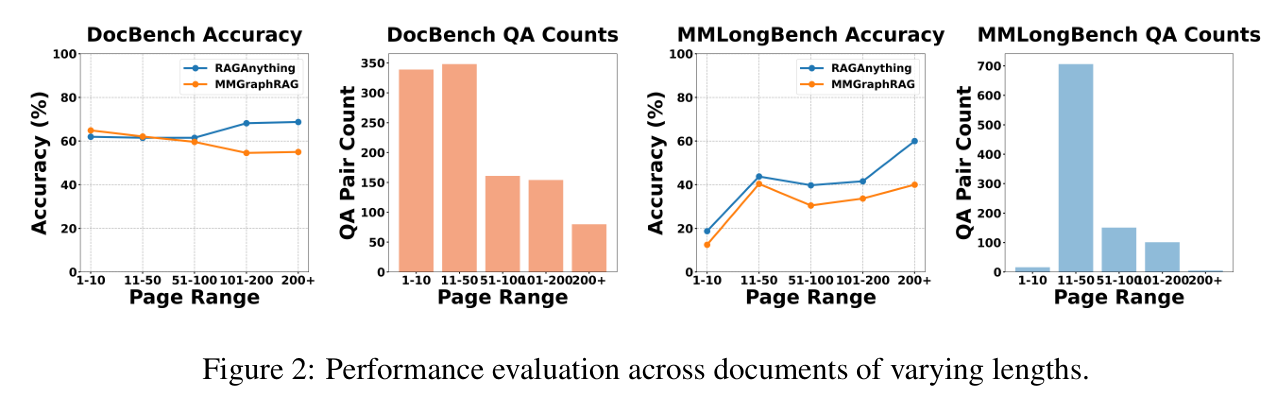
- 이 접근의 강점은 문서의 길이가 길어질수록 더욱 분명하게 나타납니다. 수십 페이지를 넘어 수백 페이지에 이르는 문서에서는 기존 RAG가 필요한 정보를 놓치는 경우가 많았지만, RAG-Anything은 문서 전체의 구조를 유지한 상태로 탐색하기 때문에 성능 저하가 상대적으로 적습니다. 실제로 DocBench와 MMLongBench 벤치마크에서 기존 최신 기법 대비 우수한 성능을 보이며 이를 입증했습니다.


- 또 하나 주목할 점은 위치 인식의 정확도입니다. 복잡한 레이아웃에서 동일한 용어가 반복되더라도 서로 다른 표나 그림에 속한 경우 이를 구분할 수 있으며, 여러 패널로 구성된 시각화 자료에서도 필요한 정보를 정확히 찾아냅니다. 기존 모델들이 어려움을 겪었던 복잡한 차트와 표 분석에서도 공간적 관계를 구조적으로 모델링해 정답을 도출했습니다.
- 이 흐름은 RAG의 발전 방향이 단순한 LLM 튜닝을 넘어 지식 표현 방식의 문제로 이동하고 있음을 보여줍니다. 앞으로는 텍스트 임베딩 성능만으로는 충분하지 않으며, 문서의 구조를 어떻게 모델링할 것인지가 핵심 경쟁력이 될 가능성이 큽니다. 이러한 측면에서 기술 문서 검색, 특허 분석, 금융 리포트 QA, 의료 문서 이해처럼 길고 복잡한 문서를 다루는 업무에서는 특히 높은 활용 가치가 기대됩니다.
- 물론 여전히 해결해야 할 과제도 남아 있습니다. 텍스트 중심으로 검색이 편향되는 문제와 레이아웃이 극도로 자유로운 문서 처리 문제는 추가적인 연구가 필요합니다. 그럼에도 불구하고 RAG-Anything은 멀티모달 지식을 통합적으로 모델링함으로써 진정한 의미의 멀티모달 지식 접근을 위한 기반을 마련했다는 평가를 받고 있습니다.
[Contact Info]
Gmail: jhbae1184@akane.waseda.jp
Twitter (X): @jhbae1184