26년 6월 4주차 그래프 오마카세
Topological Neural Operator
Topological Neural Operators
We introduce Topological Neural Operators (TNOs), a principled framework for operator learning on cell complexes that lifts neural operators (NOs) from functions on points and/or edges to topological domains. TNOs represent data as features defined on cells of varying dimension and model their interactions through Discrete Exterior Calculus, enabling explicit cross-dimensional coupling via gradient-, curl-, and divergence-type operators. The key design principle is to decouple where information flows, as governed by fixed topological operators, from how it is transformed (which is learned), yielding models that respect the geometric support of physical quantities and expose conservation and compatibility structure. We further propose Hierarchical TNOs (HTNOs), which incorporate learned coarse complexes to propagate long-range and topology-dependent information. Our framework subsumes existing NOs as a special case, providing a unified perspective on operator learning across discretizations. Across a range of PDE benchmarks, including irregular-geometry flow problems, TNOs and HTNOs improve accuracy; controlled studies further isolate the benefits of native higher-rank and topological structure. Project page: https://circle-group.github.io/research/TNO
Paper: Topological Neural Operators
— deep Manifold (@BetaTomorrow) June 10, 2026
Authors: Lennart Bastian(@lennart_bastian), Tolga Birdal(@tolga_birdal), Samuel Leventhal and Mustafa Hajij (@HajijMustafa)
From a Deep Manifold view, Topological Neural Operators is valuable because it shows that operator learning improves… pic.twitter.com/fgVbZYRAwZ
Keywords
- Neural Operators
- Discrete Exterior Calculus
- Hodge Decomposition
- 신경 연산자(Neural Operator)는 물리 시스템을 기술하는 편미분방정식(PDE)을 매번 계산으로 푸는 대신, 입력 조건으로부터 해를 직접 예측하는 함수 자체를 학습하는 접근입니다. 덕분에 복잡한 시뮬레이션을 훨씬 빠르게 수행할 수 있으며, 정확도 역시 상당 부분 유지할 수 있어 최적화, 시뮬레이션 등 다양한 분야에서 빠르게 활용 범위를 넓혀가고 있습니다.
- 대표적으로 Fourier Neural Operator(FNO)는 푸리에 변환을 활용해 그리드 데이터 위에서 뛰어난 성능을 보여주었지만, 비정형 메쉬나 복잡한 형상에서는 적용이 쉽지 않았습니다.
- 이를 해결하기 위해 등장한 것이 Graph Neural Operator(GNO) 계열입니다. 그래프는 임의의 연결 구조를 표현할 수 있기 때문에 복잡한 기하학적 도메인으로 Neural Operator를 확장하는 데 중요한 역할을 했습니다.
- FNO와 GNO의 공통적인 한계는 둘 다 점 중심(point-centric) 연산자이므로 모든 물리량을 점 위의 값으로 임베딩하여 표현하고, 학습된 커널이나 메시지 패싱 메커니즘을 통해 물리량들 간 상호작용을 모델링합니다. 하지만 이러한 표현 방식은 실제 이들의 복합적인 기하학적 구조를 충분히 반영하지 못합니다.
- 예를 들어, 전위(potential), 순환(circulation), 자속(flux)과 같은 물리량은 각각 점, 선, 면과 같이 서로 다른 기하학적 차원에 자연스럽게 대응됩니다.
- 그런데 이를 모두 점 위의 값으로 환원해 표현하면, 기울기(Gradient)·회전(Curl)·발산(Divergence)과 같은 미분 연산자가 지닌 방향성이나 보존 법칙이 모델 구조에 명시적으로 반영되지 못합니다.
- 결국 모델은 원래 물리 법칙이 제공하던 구조적 정보를 데이터로부터 다시 학습해야 하는 부담을 떠안게 됩니다.
- 이번 주 오마카세로 소개할 논문은 데이터 표현의 기본 단위를 그래프에서 상위 차수의 셀 복합체(Cell Complex)로 기존 신경 연산자 도메인을 확장합니다. 이를 통해 기존의 점 중심 Neural Operator를 보다 일반적인 위상 공간 위의 연산자(Topological Neural Operators, TNO)로 재해석하며, 모든 물리량이 지닌 기하학적 구조를 보다 충실하게 반영할 수 있음을 시사합니다.
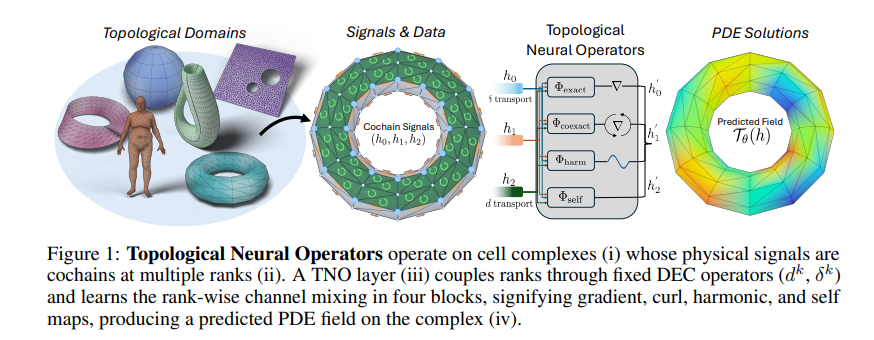
- 셀 복합체는 기존 그래프 구조에서 면, 부피 등의 더 높은 차원 셀을 추가한 구조로 정의합니다. 이 복합체 위에서 각 셀들이 갖는 신호를 부여하는 임베딩 함수를 k차 코체인(k-cochain)으로 부릅니다. 위의 예시를 빗대어, 각 위치에서의 전위를 0-cell(꼭짓점)의 값으로 맵핑하는 함수는 0-cochain입니다.
- 셀 복합체 정의의 핵심은 같은 물리량이라도 그것이 원래 존재하는 기하학적 차원에 맞는 셀 위에서 표현한다는 점입니다. 예를 들어 전기장(1-cell)은 본질적으로 방향을 가진 벡터장이지만, 이를 기존 연산자들과 같이 단순히 꼭짓점(0-cell)의 값으로 환원해 표현하는 순간 방향성이나 경계 정보의 상당 부분이 소실됩니다.
- TNO는 이러한 구조를 점이 아닌 선, 면, 부피까지 확장된 셀 위에 직접 보존하려고 시도합니다. 즉, 정보가 어디로 흐르는지는 위상 구조가 고정하고, 그 정보를 어떻게 변환할지만 학습한다는 원칙을 위의 figure 프로세스를 따라서 구체적으로 구현됩니다.
Discrete Exterior Calculus (DEC) : 셀 복합체 상 정보 흐름 정의
- 셀 복합체에서 가장 중요한 정보는 어떤 셀들이 서로 맞닿아 있는가입니다. TNO는 이러한 연결 관계를 경계 행렬(boundary matrix)로 표현하고, 이를 바탕으로 외미분(exterior derivative) 연산자를 정의합니다. 다음 연산자는 k-cell에 저장된 정보를 인접한 (k+1)-cell로 전달하는 규칙을 정해주며, 그로부터 우리가 익숙하게 알고 있는 미분 연산자와 대응됩니다.
- 점(0-cell)에서 선(1-cell)으로 정보를 보내면 기울기와 유사한 역할을 하고, 선에서 면으로 보내면 회전, 면에서 부피로 보내면 발산에 해당하는 역할을 수행합니다.
- 여기에서 중요한 관찰은 셀들이 어떻게 연결되어 있는지만 알면 정의할 수 있으며, 거리나 각도 같은 기하학적 정보는 필요하지 않는 순수한 위상 기반 연산이라는 사실입니다.
- 반면 k-cell의 정보를 한 차수 아래의 (k-1)-cell로 전달하는 규칙은 codifferential 연산자로부터 정해지며, 두 외미분 및 codifferential 연산자들을 결합하면 위상 신호처리에서 가장 핵심인 호지 라플라시안(Hodge Laplacian)이 만들어집니다.
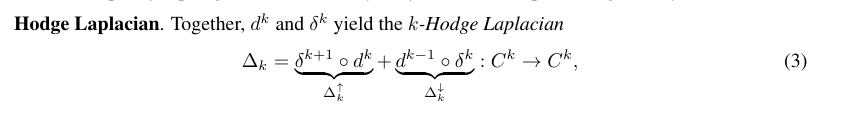
- 직관적으로 보면 호지 라플라시안은 상위 라플라시안 (upper laplacian; 더 높은 차원으로 올라갔다가 돌아오는 경로)와 하위 라플라시안 (lower laplacian; 더 낮은 차원으로 내려갔다가 돌아오는 경로)를 모두 고려해 정보를 전파하는 복합 연산자입니다. (저희들에게 익숙한 그래프 라플라시안은 호지 라플라시안의 0-cell의 경우로 자연스럽게 귀결됩니다.)
Hodge Decomposition : 위상 신호의 구조적 분해
- 그래프 신호처리에서 그래프 라플라시안을 통해 신호를 저주파와 고주파 성분으로 분석하듯, 셀 복합체 위의 신호도 호지 분해(Hodge Decomposition)를 통해 세 가지 독립적인 성분으로 나눌 수 있습니다. 이는 복합 위상 구조 위에서 정보가 어떤 방식으로 흐르고 순환하는지를 해석하는 핵심 도구입니다.
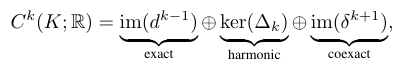
- Exact 성분은 하위 차수로 흘러들어가는 포텐셜의 변화에서 비롯되는 보존적 흐름(conservative flow)을 포착합니다. Coexact는 그와 반대로 높은 차수에서 흘러들어오는 흐름에서 비롯되며, Harmonic은 두 성분으로부터 포착하지 못하는 전역적인 흐름을 포착합니다.
- 이러한 다중 차원의 상호작용을 기존 신경 연산자들은 한꺼번에 처리하지만, TNO는 이 분해 구조를 아키텍처에 직접 반영하도록 세밀하게 설계되었습니다.
TNO Layer : 위상 경로 기반 특징 결합 학습
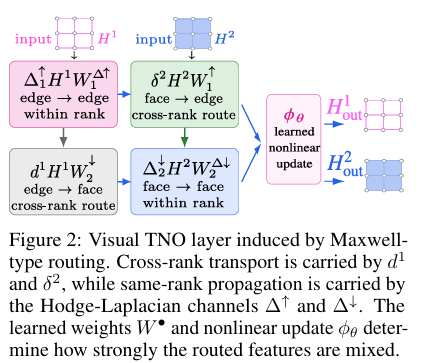
- Figure 2는 TNO Layer가 정보를 전달하는 방식을 보여줍니다. 위에서 정의한 호지 라플라시안을 이용한 동일 차수 전파와 exterior derivative/codifferential을 이용한 차수 간 전파를 동시에 수행함으로써, 그래프의 이웃 관계뿐 아니라 기울기·회전·발산으로 이어지는 물리적 정보 흐름까지 신경망 구조 안에 직접 내장합니다.
- 논문에서는 이러한 구조를 Maxwell-type routing이라고 부릅니다. Maxwell 방정식에서 전기장과 자기장이 미분 연산자를 통해 서로 연결되듯, TNO 역시 셀 복합체 위의 특징들이 외미분과 codifferential을 따라 이동하도록 설계됩니다.
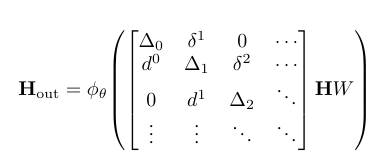
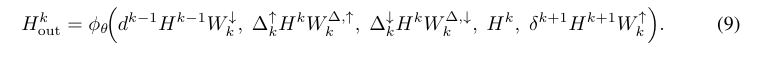

- TNO의 연산자는 엄격한 block-tridiagonal 구조를 가지며, 상위/하위 호지 라플라시안의 조합으로부터 수식 (9)와 같이 정의됩니다. 따라서 k차 셀은 자기 자신과 인접 차수인 k−1, k+1 셀과만 상호작용할 수 있으며, 이는 기울기, 회전, 발산과 같은 미분 연산이 연결되는 방식과 정확히 대응합니다.
- 흥미로운 점은 정보 흐름의 경로 자체가 셀 복합체의 위상 구조(경계 행렬로부터 인코딩되는 인접 연결성)와 DEC에 의해 미리 결정된다는 것입니다. 모델이 학습하는 것은 외미분이나 라플라시안과 같은 전달 연산자가 아니라, 그러한 경로를 따라 전달된 특징들을 얼마나 강하게 결합할지를 결정하는 채널 혼합 행렬(channel-mixing matrix)과 비선형 변환입니다. 다시 말해 TNO는 물리적으로 타당한 정보 전달 구조는 고정하고, 그 위에서 필요한 표현만 데이터로부터 학습합니다.
💡
TNO Layer는 정보가 어디로 흐를지는 물리 법칙과 위상 구조에 맡기고, 그렇게 전달된 정보를 어떻게 활용할지만 학습합니다.
Hierarchical TNO : 계층 간 코체인 정보의 장거리 전달
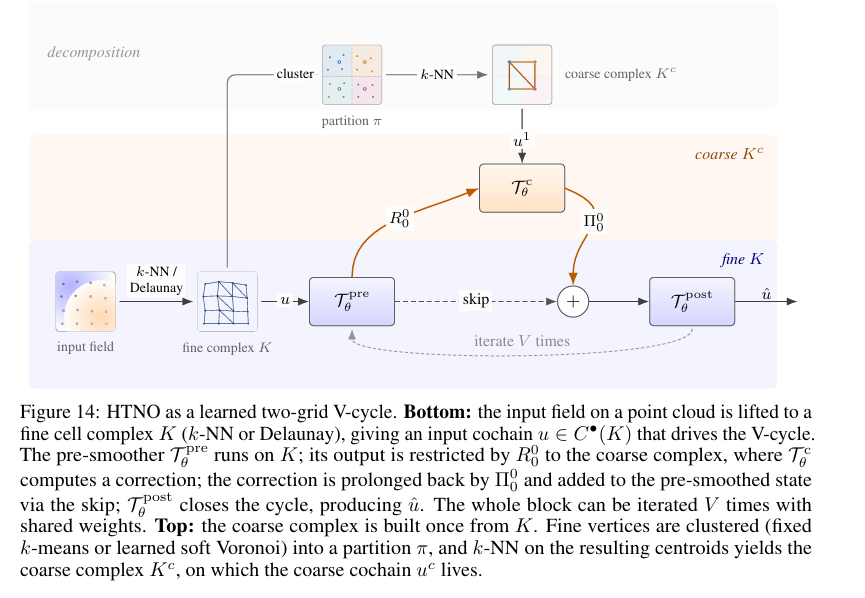
- 하지만 셀 복합체로 표현을 확장하더라도 장거리 정보 전달 문제가 자동으로 해결되는 것은 아닙니다. 기존 그래프 신경망과 마찬가지로, 지역적인 셀 간 상호작용만으로는 멀리 떨어진 영역 사이의 정보를 효율적으로 연결하기 어렵습니다. 특히 수십만 개 이상의 셀로 구성된 대규모 PDE 문제에서는 이 한계가 더욱 두드러집니다.
- 이를 해결하기 위해 저자들은 계층적 구조를 갖는 Hierarchical TNO(HTNO)를 제안합니다. HTNO는 원본 셀 복합체를 점차 단순화한 여러 계층을 만들고, 정보를 계층 사이로 전달합니다. 미세한 계층은 지역적인 물리 현상을 정교하게 모델링하고, 거친 계층은 멀리 떨어진 영역 사이의 정보를 빠르게 전달합니다.
- 단순히 해상도만 낮추는 것으로는 충분하지 않습니다. 예를 들어 어떤 신호가 회전정보를 나타내고 있었다면, 더 거친 계층으로 옮겨가더라도 여전히 회전정보로 남아 있어야 합니다. 이동 과정에서 기울기, 회전, Harmonic과 같은 서로 다른 종류의 신호가 뒤섞여 버리면 원래의 물리적 의미가 사라지기 때문입니다.
- 이를 위해 HTNO는 계층이 달라져도 물리량의 기하학적 의미가 유지되도록 설계합니다. 이는 서로 다른 해상도 사이를 오가더라도 원본 신호의 구조를 보존하는 멀티그리드 기법의 핵심 원리와 연결되어 있습니다. 결국 HTNO는 정보를 멀리 보내는 방법뿐 아니라, 그 정보가 원래 무엇이었는지 잃어버리지 않도록 설계된 결과로 볼 수 있습니다.
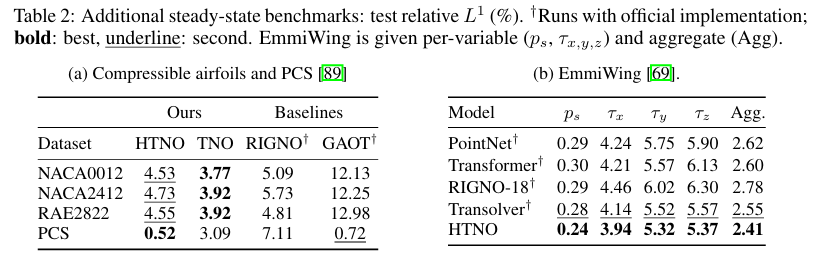
- 기존 비정형 메시 벤치마크(Poisson-Gauss, Airfoil, Elasticity)부터 압축성 airfoil(NACA0012/2412, RAE2822), 그리고 수십만개 포인트 규모의 3D 항공기 날개 표면 데이터셋(EmmiWing)까지 다양한 스케일에서 다양한 베이스라인 신경 연산자들과 정량적 성능을 비교했습니다.
- 그 결과는 인상적입니다. 압축성 벤치마크에서는 TNO가 기존 Neural Operator 계열인 RIGNO와 GAOT를 일관되게 앞서는 결과를 보였습니다. 특히 NACA0012에서는 상대 오차를 5.09%에서 3.77% 수준까지 낮추며 가장 좋은 성능을 기록했습니다.
- EmmiWing에서도 이러한 경향은 유지됩니다. HTNO는 압력, 전단응력 등 대부분의 물리변수에서 가장 낮은 오차를 기록했으며, 종합 지표 역시 기존 Transformer, RIGNO-18, Transolver를 모두 앞섰습니다.
- 비정형 기하를 가진 공기역학 문제부터 산업 규모의 3D PDE 문제까지 일관된 개선이 나타났다는 것은, TNO가 제안하는 위상 기반 표현 방식이 특정 데이터셋에 특화된 트릭이 아니라 보다 일반적인 Neural Operator 설계 원리일 가능성을 보여줍니다.

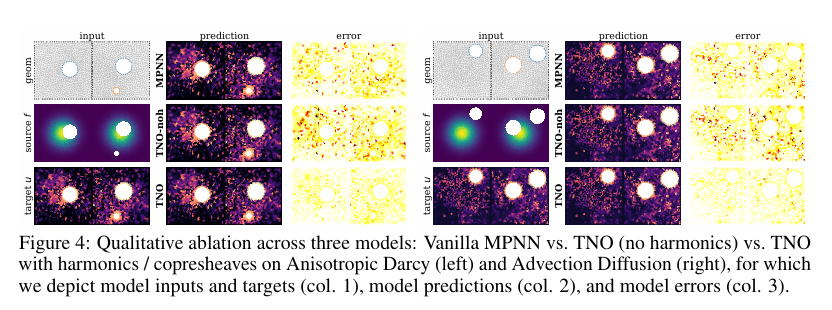
- 여기서 한 걸음 더 나아가 TNO의 성능 향상이 단순한 모델 규모 때문인지, 아니면 실제로 위상적 구조를 활용한 결과인지를 검증한 Ablation 실험들입니다. Figure 3과 Figure 4은 각 조건에서 TNO가 이러한 위상 구조를 실제로 어떻게 활용하는지도 분석하고 그 결과를 시각화합니다.
- Figure 3은 면(face)에 존재하는 방향성 정보를 꼭짓점(vertex)으로 평균내면 완전히 사라지도록 설계하여, 기존 점 중심 Neural Operator들이 원리적으로 해당 정보를 사용할 수 없음을 보여주었습니다. 실제로 TNO가 0·1·2차 셀에 대응하는 물리량을 동시에 복원하면서도 각 차수의 오차 패턴을 비교적 안정적으로 유지하는 모습을 확인할 수 있습니다.
- 이는 서로 다른 차원의 신호들을 하나의 표현으로 섞어 처리하는 대신, 각 차수의 정보를 분리된 상태로 전달하기 때문입니다.
- 결과적으로 경계 주변의 방향성 구조나 국소적인 흐름 패턴도 보다 자연스럽게 복원됩니다.
- Figure 4는 harmonic 채널과 쉬프 전달(sheaf transport)의 역할을 분리해 분석한 실험입니다. 흥미롭게도 두 요소 중 하나만 사용할 경우 성능이 오히려 감소했으며, 둘을 함께 사용할 때 가장 좋은 결과가 나타났습니다. 이는 전역적인 위상 정보를 담는 harmonic 성분과 계층 간 정보 전달을 담당하는 학습형 전달 구조가 서로 보완적으로 작동한다는 것을 의미합니다.
- 결과적으로 저자들은 TNO의 성능 향상이 단순히 모델 규모의 증가가 아니라, 물리량의 위상적 구조를 명시적으로 보존한 설계에서 비롯된다는 점을 실험적으로 뒷받침하고 있습니다.
- 셀 복합체 위에서 물리량을 꼭짓점, 엣지, 면, 부피에 나누어 배치하고, 그 상호작용을 DEC(호지 라플라시안) 연산자로 연결하는 것. 이것이 저자들이 말하는 TNO의 핵심입니다.
💡
고정할 것은 도메인의 구조이고, 학습할 것은 그 위에서의 변환이다.
- 이러한 설계를 바탕으로 저자들은 기하학, 물리학, 계산을 하나의 틀 안에서 통합하여 구조화된 공간 위에서 연산자를 학습하는 과학용 파운데이션 모델로 가는 방향이라고 설명합니다.
- 물론 해결해야 할 과제도 남아 있습니다. 더 크고 복잡한 도메인으로의 확장, 안정성과 수렴성에 대한 이론 구축, harmonic 채널과 sheaf 기반 채널의 역할 규명 등은 앞으로의 과제로 남아 있습니다. 무엇보다 TNO 역시 학습 기반 근사 모델인 만큼, 훈련 분포를 벗어난 상황에서 물리적 정확성이나 수치적 안정성을 보장하지 않으며, 신뢰할 수 있는 수치 솔버와의 검증은 특히 안전이 중요한 응용에서 필수적이라고 저자들은 강조합니다.
- 개인적으로 이 논문을 읽으며 가장 궁금했던 부분은 "기존 Topological Deep Learning 계열의 Cell Complex Neural Network와 무엇이 다른가?"였습니다. 실제로 저자들도 TNO를 Topological Deep Learning 위에 구축된 새로운 Neural Operator로 포지셔닝합니다. 하지만 핵심적인 차이는 무엇을 학습 대상으로 삼느냐에 있습니다.
💡
Cell Complex Neural Networks이 셀 복합체를 신경망의 입력 공간으로 사용했다면, TNO는 셀 복합체를 PDE 해를 생성하는 함수 공간 자체로 다루는 방법에 집중합니다. 즉, 물리 법칙 자체를 어떻게 셀 복합체 구조로부터 학습할 것인지를 고민합니다.
- 저자들은 기존 DEC 기반 위상 학습 모델들이 복합체 표현 학습과 그 신호 예측에 머물렀다면, TNO는 이를 함수 공간 연산자 학습으로 확장하려는 첫걸음이라고 이해해볼 수 있습니다. 여기에서 말하는 함수 공간 연산자와 기존 위상 신경망 사이의 간극이 실제로 얼마나 큰지는 앞으로 검증될 부분이겠지만, 위상 구조로 널리 사용되던 셀 복합체를 신경 연산자로 새롭게 바라본다는 관점이 흥미로웠습니다.
- 그래프 신경망을 넘어 Topological Deep Learning(Cell Complex, Hodge Theory )으로 관심 영역을 확장하고 계신 분 및 PDE 기반 시뮬레이션, Neural Operator, PINN(Physics-Informed Neural Network) 연구를 수행하고 계신 분들께 한번 쯤 권장해드리고 싶은 논문입니다. 참고해보시면 좋을 것 같습니다.
Reference (Blog)
- 저도 아래의 ArXivIQ 블로그를 참고하며 논문을 정독해보고 있습니다. 수식을 하나하나 따라가기에는 부담스럽지만 핵심 아이디어와 직관을 먼저 잡아보고 싶으신 분들께 좋은 참고 자료가 될 것 같습니다.
Topological Neural Operators [no math version]
Authors: Lennart Bastian, Samuel Leventhal, Mustafa Hajij, Tolga Birdal
Topological Neural Operators [deep math version]
Authors: Lennart Bastian, Samuel Leventhal, Mustafa Hajij, Tolga Birdal
[Contact Info]
Gmail: jhbae1184@akane.waseda.jp
Twitter (X): @jhbae1184