4월 2주차 그래프 오마카세

Neural Graph Databases
[https://towardsdatascience.com/neural-graph-databases-cc35c9e1d04f]
Completeness. Query engines assume that graphs in classical graph DBs are complete.
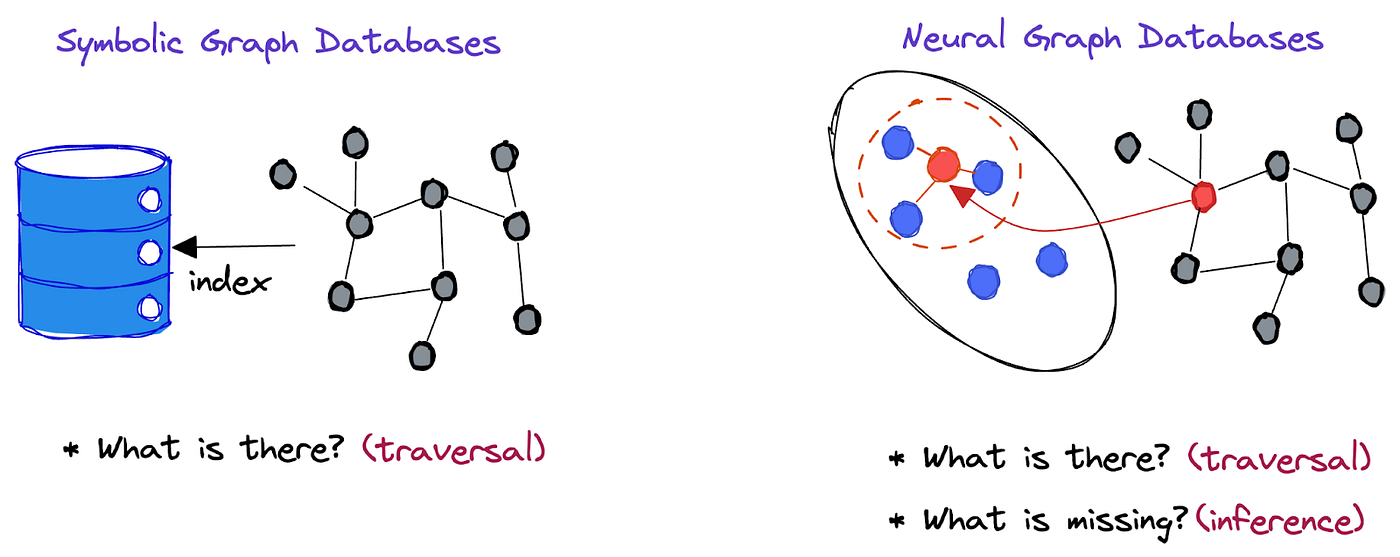
Preliminary
Why useful knowledge graph in question answering task?
- Structured representation: Knowledge graphs represent information in a structured way, using nodes to represent entities and edges to represent relationships between entities. This makes it easy to query the knowledge graph and find relevant information.
- Semantic relationships: Because knowledge graphs represent relationships between entities, they can be used to answer questions that require understanding of the semantic relationships between entities. For example, a knowledge graph could be used to answer a question like "Which actors have starred in movies directed by Steven Spielberg?"
- Multilingual support: Knowledge graphs can be created in multiple languages, which means that they can be used to answer questions in different languages. This is particularly useful for multilingual question answering systems.
- Scalability: Knowledge graphs can be scaled up to include a large number of entities and relationships, which makes them useful for answering complex questions that require knowledge from multiple domains.
Completeness & Incompleteness
In the context of a knowledge graph, "completeness" and "incompleteness" refer to the degree to which the knowledge graph represents all the information that is relevant to a particular domain or topic.
A "complete" knowledge graph contains all the relevant information about a topic or domain, and all the relationships between different entities in the domain. This means that the knowledge graph can answer any question related to that topic or domain.
An "incomplete" knowledge graph, on the other hand, may be missing some important information, or may not have all the relationships between entities represented. This means that the knowledge graph may not be able to answer certain questions, or may provide incomplete or inaccurate answers.
In summary, completeness refers to the degree to which a knowledge graph represents all the relevant information and relationships in a particular domain or topic, while incompleteness refers to the degree to which a knowledge graph is missing important information or relationships.
Summary
- 추상적인 지식들을 텍스트로 표현해놓은 지식베이스. 방대한 지식들을 체계적으로 관리하기 위해 그래프 형태로 변환한 지식그래프. 그래프를 보관하기에 적합한 공간 그래프 데이터베이스. 그래프 데이터를 컴퓨터가 이해하기 쉽게 정량화하는 기술 그래프 딥러닝. 언급드린 모든 요소들이 결합되면 어떨지 상상해보셨나요? 그 요소들이 결합된 형태인 Neural Graph Database(NGDB)에 대해 이야기하고 있습니다.
- 지식그래프 하면 어떤 생각이 드실까요? 방대한 지식들이 담겨있기에 이를 잘 활용해보면 좋겠다. 라는 생각이 드실텐데요. 실제로 지식그래프를 잘 살펴보면, 곳곳에 비어있는 노드와 관계들이 존재하기에 데이터 일관성 유효성 측면에서 부족하다는 한계점이 존재합니다. 즉, 많은 데이터들이 있더라도 정작 실제 활용할 때에는 그림의 떡 이라고도 볼 수 있습니다. 좀 더 나아가면, 그래프 데이터 베이스에 이를 적재하여 사용하더라도 그 결과에 대해 우수한 품질을 기대하기는 어렵습니다. 그렇다면 이 ‘비어있음’을 보완하기 위해 그래프 딥러닝을 활용하면 어떨까요? 해당 아티클 및 논문은 ‘비어있음’을 link prediction task 라고 문제정의를 하여 그래프 데이터베이스 조인 인덱싱과 그래프 머신러닝을 결합한 시너지에 대해 이야기합니다.
Insight
- 고차원 질문에 대해 답변을 할 수 있는 데이터 베이스 시스템. 지식그래프 임베딩에 대한 연구가 더욱 많아질거라 생각되네요. 그에 따라, 지식그래프 형태인 (h,r,t) 에 대한 가중치를 어떻게 두고 닫힌가정 열린가정을 적재적소에 어떻게 활용할지에 대해서도 논의가 많이 필요해보입니다. 즉 연구 및 개선의 여지가 많은 부분이기에 블루 오션이지 않을까 싶네요.
ChatGPT versus Traditional Question Answering for Knowledge Graphs: Current Status and Future Directions Towards Knowledge Graph Chatbots
[https://arxiv.org/pdf/2302.06466.pdf]
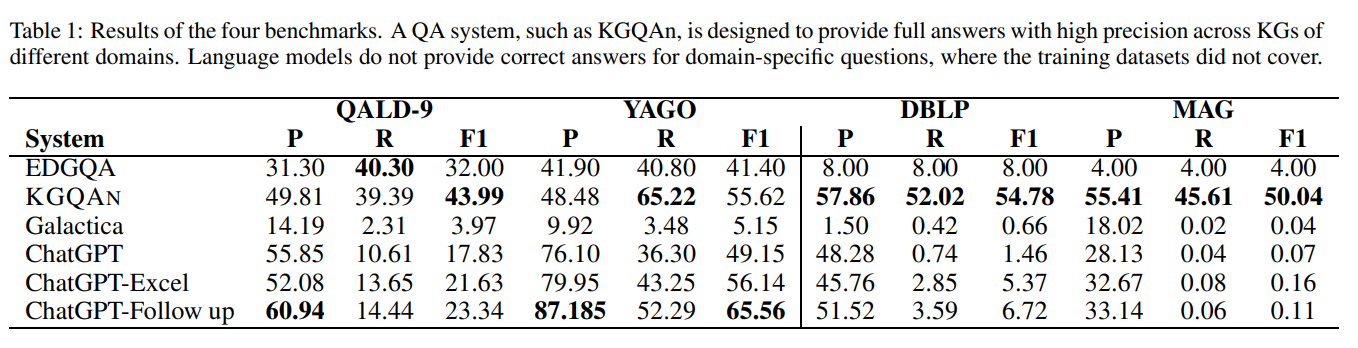
Summary
- ChatGPT 를 어떤식으로 성능평가할까요? 그리고 앞서 이야기나눈 Knowledge graph with QA 가 과연 효과가 있을까요? 라는 의문에 해답을 찾을 수 있는 논문입니다. 연구 시작 전, 기획을 위해 특정 분야에 대해 알기 위해 해당 분야에 대한 얼개와 트렌드가 적혀있는 survey paper를 보곤합니다. 본 논문은 그 survey를 목적으로 작성되었기에, ChatGPT 와 Knowledge graph를 결합해서 활용해보고 싶으신 분들에게 많은 도움이 될거라 생각되네요.
Insight
- 지식그래프가 빛을 발할 수 있는 시대가 도래하고 있다 생각합니다. 대량의 데이터가 학습된 모델(ChatGPT)에서 ‘가치’있는 정보를 추출하기 위해선 뚜렷한 목적과 방향이 필요하다 생각하는데요. 그 목적과 방향에 도움을 줄 수 있는 도구로써 지식그래프가 최적이지 않을까 싶네요.
CPU Affinity for PyG Workloads
[https://pytorch-geometric.readthedocs.io/en/latest/advanced/cpu_affinity.html]
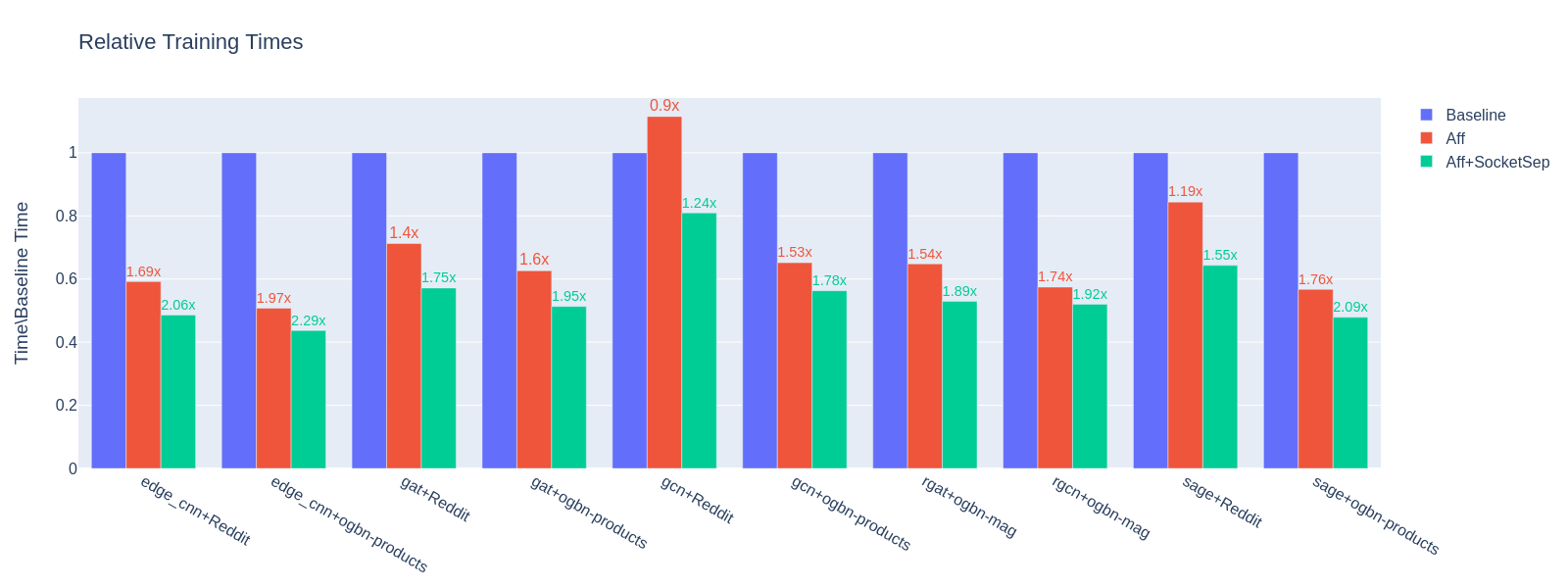
preliminary
Affinity mask is a term used in computer science that refers to a bitmask that is used to associate a set of resources or processing units with a particular task or process. In the context of operating systems, an affinity mask is used to specify which processors or cores are eligible to execute a particular thread or process.
Summary
딥러닝을 하기전 필수품이라 생각되었던 GPU, 필수가 아닐수도 있습니다. CPU를 통해 그래프 딥러닝을 하는 방식에 대해 알아보겠습니다.
Execution bind 와 Memory bind 를 통해 core 와 memory 를 관리하며 효율성을 증진시키는게 핵심입니다. core stall 과 memory bound 를 최소화 함으로써 그 효율성을 증진시킨다고 합니다. 코어 스톨(core stall)은 프로세서 또는 코어가 메모리에서 데이터를 가져오기를 기다리고 있기 때문에 명령을 계속 실행할 수 없을 때 발생하는 현상을 의미합니다. 결국 데이터 core stall는 메모리 바운드와 영향이 있기때문에 메모리 캐싱에 소요되는 worker 를 잘 배분해주며 그 burden 을 최적화 한다 라고 보시면 되겠습니다.
실질적으로 backward 역전파 계산과 같은 computation 측면으로 접근하기보다, Dataloader 에서 어떻게 데이터를 불러와서 모델에 inject 해주는지를 다룬다고 보시면 되겠습니다.
Insight
Feature store, Graph store 를 구현한 Database 들이 자주 보이고 있습니다. 물론 저희가 자체 Database 를 가지고 있으면 좋지만, 그렇지 못할 경우도 물론 발생하기에 cpu 를 통해 데이터를 효율적으로 load 하고 남은 자원을 통해 gpu 연산을 진행하게끔 파이프라인을 디자인해준다면 더욱 최적화에 근접한 아키텍쳐가 되지 않을까 싶네요.
Choose Your Weapon: Survival Strategies for Depressed AI Academics
[https://arxiv.org/pdf/2304.06035.pdf]
AI 분야에서 자주 회자되는 말이죠. “No free lunch” 공짜 점심은 없다. 특정 데이터에 최적화된 모델이 다른 데이터에서 최적화되었다는 보장은 없다. 라는 이야기가 핵심인 theorem 입니다. 이를 극복하기 위한 시도 즉 모델 일반화를 위해 최대한 많은 데이터를 수집하여 학습시키는 패러다임인 Large model training이 등장합니다.
그렇게 도출된 공식이자 현상은 바로 “데이터가 많을수록 모델 성능 또한 좋아진다” 인데요. 물론, 데이터 또한 양질의 데이터여야겠죠. 허나, 데이터 모수가 많으면 많을수록 양질의 데이터 또한 많을 확률이 높기에 다다익선 이라 볼 수 있습니다. 그렇다면 결국 많은 데이터를 잘 조리할 수 있는 ‘자원’이 필요합니다. 여기에서 자원은 GPU,데이터 저장소,CPU 등을 의미합니다.
개인 혹은 학계에서 활용할 수 있는 ‘자원’과 산업계 에서 활용할 수 있는 ‘자원’을 비교해보면 너무 당연하게도 산업계 자원이 더 풍부할 거라는 생각이 먼저듭니다. 그렇다면 결국 개인 혹은 학계 차원 입장에서 어떻게 ‘자원’을 효율적으로 활용하며 contribution 을 발견할 수 있을까요? 라는 의문이 듭니다.
그 의문에 대한 답을 체계화해서 글로 적어둔 논문입니다. 연구를 어디서부터 시작해야할지 고민이신 연구자분들에게 추천드립니다. 추가적으로, 본 논문과 [https://www.cs197.seas.harvard.edu/] 를 함께 보시면 그 효과가 배가될것으로 생각되니 여유가 있으시면 추천드립니다.
[pseudo-lab gathering with HP]

평일 퇴근 후, HP 에서 지원받아 가짜연구소에서 주최한 Data Science Social Gathering 행사에 참여해서 다양한 분들과 인사이트를 교류하며 배움의 시간을 가졌습니다. 3~4여년전, 저를 그래프라는 분야에 입문하게 만들어주신 스승님도 간만에 만나서 더욱 뜻깊은 시간이였습니다. 그때 아마 제가 그래프라는 분야를 알지 못했다면 지금은 무엇을 하고 있을까 싶네요.당시 목적성없이 공부만 진행했던터라, 성장이 더딤을 느꼈었던차에 참여하게 되었는데 정말 지금봐도 후회없는 선택이라 생각되네요.
이처럼, 성장이 정체되거나 공부에 대한 목적성이 결여되신 분들이 계시다면 다양한 분들과 함께 성장함을 느끼는 공간인 가짜연구소에 참여해보시는건 어떠실까요? 커뮤니티 핵심 모토가 바로 “비영리” 이기에 공부하는데 있어 어떠한 비용이 들지 않다는 점이 좋습니다. “무료”여도 되나 싶을정도로 체계적인 커뮤니티 시스템들이 잡혀있고, 다양한 분들께서 성장할 수 있게끔 서포트해주시기에 참여 전/후가 명확히 비교될 정도로 실력이 상승됨을 체감하실 수 있습니다. 오마카세 분들도 함께해보시면 어떨까요? :)