2월 2주차 그래프 오마카세

그래프 임베딩 하실 때 데이터에 대해 고민해보신 경험 있으실까요? 오늘 이 시간에는 임베딩 결과에 도움이 될만한 네트워크 지표를 가져왔습니다. 바로 degree 뿐만 아니라, clustering coefficient , path length 등에 대한 요소들입니다. 그럼 이 요소들이 어떻게 도움이 되는가? 라는 의문이 드실텐데요. 활용 사례를 말씀드려볼게요.
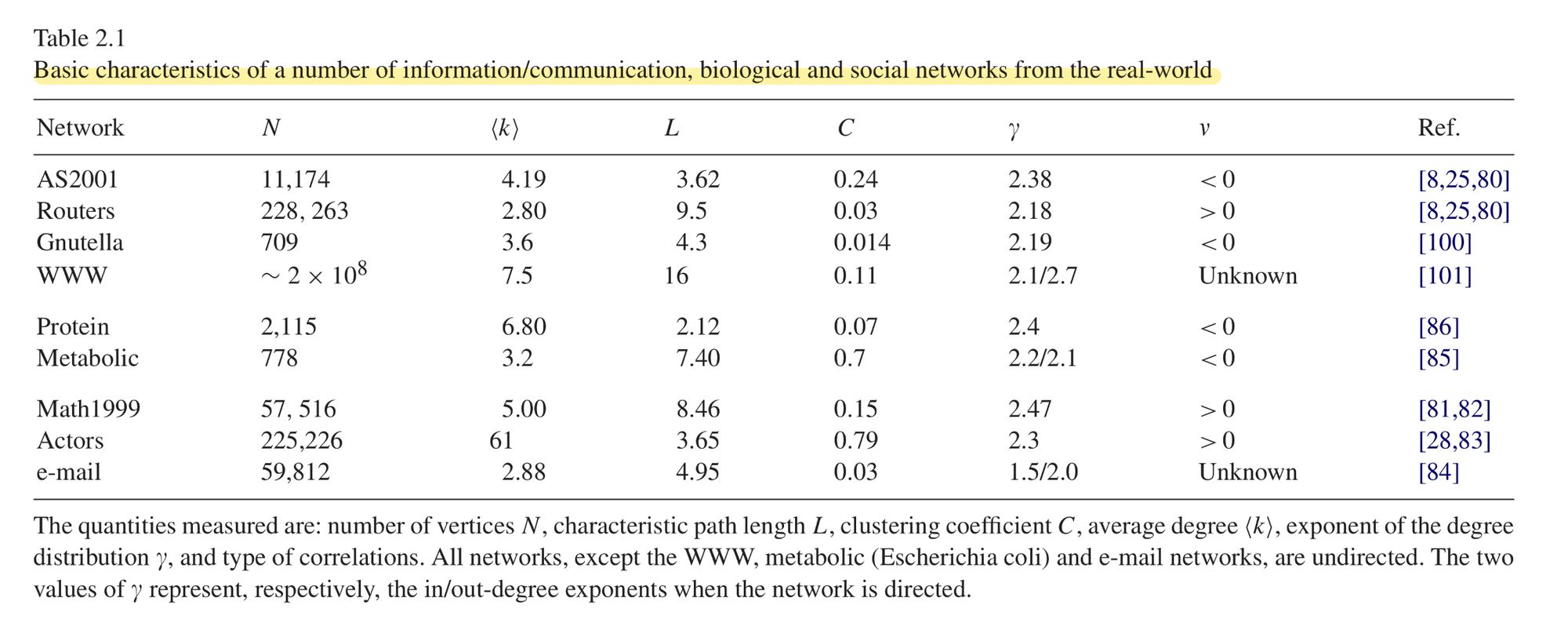
Table 2.1. 에서 나온 지표들을 모두 고려하면 최종적으로 네트워크는 대체적으로 scale-free , random graph 으로 분류됩니다. Scale-free 는 power-law 분포를 띄고 random graph 는 가우시안 분포를 띄는 그래프입니다. 네 바로 high-connected 인지 아닌지를 구별하게 되는거죠. 단적인 예로 power-law 분포를 띄는 scale-free network 면 over-squashing , 꼬리에 속해있는 노드의 정보량이 적음 과 같은 경우가 발생함을 추측할 수 있기 때문에 rewiring , virtual node 와 같은 요소들을 모델링에 대입해주면 좋은 결과를 얻을 수 있을것이다. 라는 식의 아이디어가 적용이 가능하다는 거죠.
이처럼 네트워크의 topological feature 를 고려한 모델링을 해보시면 어떨까요? 데이터의 분포에 기반한 모델링을 하기에 더욱 합리적인 접근이 될 것이고, 만약 성능이 개선되었다면 그 근거로서 제시하기에도 용이하실거라 생각이 되네요.
Tip 네트워크 지식을 직접 활용해보시는걸 추천드립니다. Graph Representation learning(GNN) 은 네트워크의 분포를 잘 학습시키기 위해 미분을 활용하며 대표값을 정량화 하는게 목적이고, 복잡계 네트워크는 네트워크 데이터의 특성을 물리학 관점에서 정량화 해보자 라는 맥락을 가지기 때문에 유사한 목적을 가집니다. 두 학문의 접근방식만 다를뿐이죠. 결국 두 방법론들이 상호보완이 될 수 있음을 의미합니다. (ChatGPT 를 적극 활용해보세요!)
Unleashing ML Innovation at Spotify with Ray
[https://engineering.atspotify.com/2023/02/unleashing-ml-innovation-at-spotify-with-ray/]
- Graph learning 을 recommendation system 에 어떻게 적용하고 있는지 궁금하고 계셨을 분들에게 도움이 되겠네요. RAY + PyG 의 형태로 활용됩니다.
- Production level 에서 GNN 이 활용되기 어려울거라 생각했던 이유들인 subgraph sampling , batch training 이 Ray 를 통해 해결해서 실제 배포까지 된다는 사실이 너무 신기해서 더욱 와닿은 포스팅이였습니다.
- 참고로 , Graph learning 2022 에서 발표한 세션에서 자세한 내용이 담겨 있으니, 관심있으신분들은 참고해보셔도 좋을거라 생각됩니다.
Search behavior prediction: A hypergraph perspective
[https://www.amazon.science/publications/search-behavior-prediction-a-hypergraph-perspective]
- 고객이 쇼핑을 하며 무슨 행동을 하는지 표현할 때 효과적인 구조. 바로 bipartite graph 구조입니다. 아이템과 유저간 발생하는 로그들을 엣지로 표현하게 된다면 0,1 과 같은 feature가 아닌 관계로써 맵핑되기에 직관적이고 효율적이라는 거죠.
- 허나, 이런 좋은 장점들이 많음에도 불구하고 역시 단점 또한 존재합니다. 바로 Disassortative , Long-Tail Distribution 문제입니다. 간단히 말씀드리면, e-commerce graph 는 power-law 형태를 띄는게 일반적이라고 합니다. 너무나 당연하지만, 저희가 주로 사용하는 휴지 , 물 등 생필품같은 요소들은 주기적으로 꾸준히 구매해야 하기때문이죠. 그 결과, 대다수 유저와 아이템간 관계들을 보면 생필품에 치우쳐져 있다고합니다. 이 관계들이 결국엔 noise 가 될 수 있기에, 유저가 진정 원하는 아이템을 제공할 때 불편함을 초래한다고 합니다.
- 앞서 언급한 두가지 문제를 해결하기 위해 hypergraph 를 활용합니다. item-item 간의 공통 속성 , higher-order 속성을 활용해서 다양한 context 를 반영해서 문제들을 해결해보고자 시도하는거죠.
- 곧 진행될 WSDM 23 에 억셉된 논문입니다. 추천시스템에서 hypergraph를 도입하는 추세들이 곳곳에서 보이네요. bipartite 의 문제점부터 시작해서 네트워크 데이터 분포를 연계지어 hypergraph로 해결하려는 시도. 앞으로의 트렌드가 되지 않을까 조심스레 추측해봅니다.
Kumo - why graph is advantage in FDS industry
[https://kumo.ai/ns-newsarticle-using-graph-learning-to-combat-fraud-and-abuse]
- PyG 컨트리뷰터들이 설립한 회사죠. Kumo , FDS 에서 왜 Graph가 적절한지에 대해 이야기합니다. Rule based → traditiaonl ML → Graph 까지 기술이 잘 되어있습니다. 뿐만아니라, FDS 의 배경과 시스템 설계 시 주의할 점에 대해서도 언급하고 있기에, 게시글의 이해를 위해 따로 FDS를 공부하실 필요까지는 없을만큼 친절하게 설명이 잘 되어있습니다.
T2-GNN: Graph Neural Networks for Graphs with Incomplete Features and Structure via Teacher-Student Distillation
[https://arxiv.org/pdf/2212.12738.pdf]
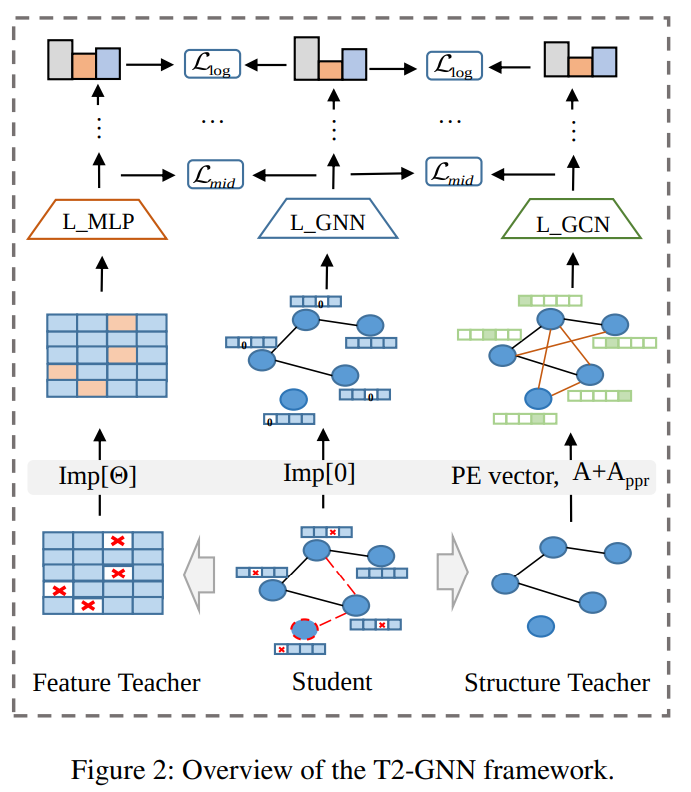
- 현업 엔지니어링 측면에서 여러 task 가 존재할텐데요. 모델의 성능과 추론속도를 모두 고려하며 최적화하는 작업이 엔지니어링의 주 목적이지 않을까 싶네요. 소개드릴 논문에서는 경량화 엔지니어링 스킬 중 Knowledge distillation 를 GNN 에 어떻게 대입하는지에 대해 이야기합니다.
- Node feature가 모두 온전히 존재하는 best 상황이 있는 반면, missing value 들이 node feature에 존재하는 순간도 존재합니다. 주로 0 , medium value 등 missing imputation technique 를 활용합니다. 본 논문에서는 technique 중 node distribution 를 고려해서 missing value 를 채워주는 방식을 언급하며 문제를 제기합니다. 바로, real-network 은 더욱 복잡하며 다양한 분포들이 존재하기에 데이터 분포만을 고려한 방식이 적절치않다는거죠.
- 그래서 본 논문에서는 node feature을 MLP로 , graph structure feature을 pagerank 로 적용한 뒤 , dual distilliation(joint learning)방식을 활용합니다. 비어있는 node feature는 mlp 로 학습시키며 통상적인 값으로 대체하고 , graph feature는 페이지 랭크를 활용해서 그래프의 중요성을 반영한다는거죠.
- 결과적으로 모든 베이스라인에서 성능이 향상됨으로 논문의 노벨티를 주장합니다. 유심히 보면 좋을부분은 ablation study 입니다. Feature Teacher , structure feature w/o 등 여러 제한조건을 걸고 각각의 성능을 비교한 그림을 보시면 teacher frame 의 유무에 따라 성능의 변동이 큼을 확인할 수 있습니다. 이를 기반으로 추측해보자면 결국 knowledge distillation task 에서는 node feature을 잘 나타내는게 중요하다라는 사실을 실험 결과를 근거로 알 수 있습니다.
Complex systems in the spotlight: next steps after the 2021 Nobel Prize in Physics
[https://iopscience.iop.org/article/10.1088/2632-072X/ac7f75/pdf]
- 재미로 보시면 좋을거 같네요. 복잡계 네트워크의 next step 에 대해 물리학계에서 저명한 분들이 언급하신 내용입니다. 향후 학계가 어떤식으로 흘러갈지 유추할 수 있는 힌트들이 마구마구 적혀있기에, 연구 방향성을 잡으실 때 유용하실거라 생각되네요.
Big graph with 리소스
확실히 PyG 를 기반으로 extension version 들이 많이 제작되고 있는 추세인 것 같네요.
Quiver
[https://github.com/quiver-team/torch-quiver]
[https://www-fourier.ujf-grenoble.fr/~mbrion/notes_quivers_rev.pdf]
- PyG base performance 를 대폭 향상시킨 프로젝트입니다. 그 뒤에는 1. GPU accelerated(NVIDIA 네트워크 통신 최적화) 2. torch-Quiver 만의 그래프 데이터 구조 3. 효율적인 aggregation 을 위한 알고리즘 4. 최적화된 그래프 알고리즘 등이 그 성능 향상의 비법이라고 합니다.
- 링크 두번째는 Quiver 백서로 연결됩니다.저도 생소한 분야이다보니 ChatGPT 에게 물어봤습니다. 다음과 같이 답변해주네요.
- Q) what is the Quiver ? A) Quiver is a data structure for efficiently representing and manipulating graph-structured data. It is specifically designed to be used in graph-based deep learning applications, and provides a compact representation of graph-structured data that is optimized for GPU-accelerated computations.
- Q)why the Quiver structure is useful in graph? A) The Quiver structure is a sparse matrix representation of a graph, where the rows and columns represent nodes and edges, respectively. This representation allows for efficient computations on graph-structured data, even when the graph is very large.
PyG-lib
[https://pyg-lib.readthedocs.io/en/latest/modules/ops.html]
- PyG 는 기존에 torch-scatter , torch-gather 라이브러리에 굉장히 의존성이 강했습니다. entity 간 발생하는 연산을 흩뿌리고 모아주는 작업이 결국에 message passing , aggregation 과 같이 그래프 임베딩의 핵심 요소였으니깐요.
- pyg-lib 와 torch-scatter , gather 은 모두 pip install 로 설치하면 적용되는 low-level module 입니다. 허나 pyg-lib를 활용하게 된다면 더욱 gpu 친화적인 low-level 로써 성능향상을 기대할 수 있습니다. 지금은 nightly 단계같아서 안정화까지는 조금 더 기다려봐야할 것 같습니다. github 에 star alert 를 설정해두시고 시의적절할 때 활용해보시는걸 추천드립니다.
Memory-Efficient Aggregations
[https://pytorch-geometric.readthedocs.io/en/latest/advanced/sparse_tensor.html]
- dense-graph 나 large-graph 에서 gather-scatter 은 물리적으로 메모리 공간을 많이 차지합니다. 이를 sparse-tensor[https://arxiv.org/abs/1803.08601] 활용해서 해결합니다.
EXACT: Scalable Graph Neural Networks Training via Extreme Activation Compression
[https://openreview.net/forum?id=vkaMaq95_rX]
[code , https://github.com/warai-0toko/Exact]
- Quantized 를 통해 데이터를 압축시켜줌으로서, 성능 개선을 이끌어냅니다. 핵심은 데이터를 mixed precision 과 같이 부동소수형 데이터를 통해 최대한 가볍게 만든 후, low dimensional 로 projection 하는것이라고 볼 수 있겠습니다.