3월 2주차 그래프 오마카세

Graph Rewiring: From Theory to Applications in Fairness
[https://github.com/ellisalicante/GraphRewiring-Tutorial]
- 3월 2주차 그래프 오마카세의 시작은 GNN 고질적인 문제인 ‘over-smoothing , over-squashing and under-reaching 을 어떻게 네트워크 이론으로 해결해볼것인가’라는 관점이 담겨있는 튜토리얼 소개로 시작해보겠습니다.
- 기존에는 graph rewiring 이라는 기술을 활용해서 노드간 정보 흐름을 적절하게 조절해주곤 했습니다. 여기에서 ‘적절하게’란 연결이 적은 노드는 정보가 받는 양이 적을텐데 그 정보량을 증폭해주고, 연결이 많은 노드는 정보 받는 양이 많을테니 거기에 규제를 부여하는등의 밸런스를 맞추는 행위를 의미합니다.
- 이를 위해 노드간 새로운 관계를 랜덤하게 만들어주는 랜덤 샘플링을 활용했습니다. 전혀 관계가 없던 노드들끼리 엣지를 연결해주는 방식입니다. 랜덤 샘플링은 구현이 간단하다 그리고 성능이 어느정도 보장되어있다 장점이 존재하여 많이 활용되곤 하였으나, 샘플링된 관계가 랜덤하듯이 효과 또한 랜덤하기에 효과가 좋거나 나쁘거나하는 결과를 낳는 등 한계점이 존재했습니다. 이 한계점을 극복하고자, 샘플링 전 노드간의 비슷함(relevance) 을 측정하여 적절하게 rewiring 을 해주는 function이 등장합니다.
- 본 튜토리얼에서는 해당 graph rewiring function들을 어떤식으로 구성할지에 대해 기초지식(spectral theroy) 부터 transductive , inductive sampling 관점으로 접근합니다. 뿐만아니라, graph fairness 까지 이론부터 실무적용 관점까지 올인원으로 다룬 튜토리얼이라고 보시면 되겠습니다.
- SAGE 계열과 같이 sampling 을 통해 노드 정보를 랜덤으로 passing 그리고 aggregation하는 아키텍쳐에서 유용할 것으로 판단됩니다. 마냥 랜덤하게 샘플링하던 방식에 의구심을 품고, 과연 그 랜덤 샘플링이 타당할것인가? 라는 관점으로 접근하시면 많은 배움이 있으실거라 생각이 드네요.
On Generalized Degree Fairness in Graph Neural Networks
[https://arxiv.org/pdf/2302.03881.pdf]
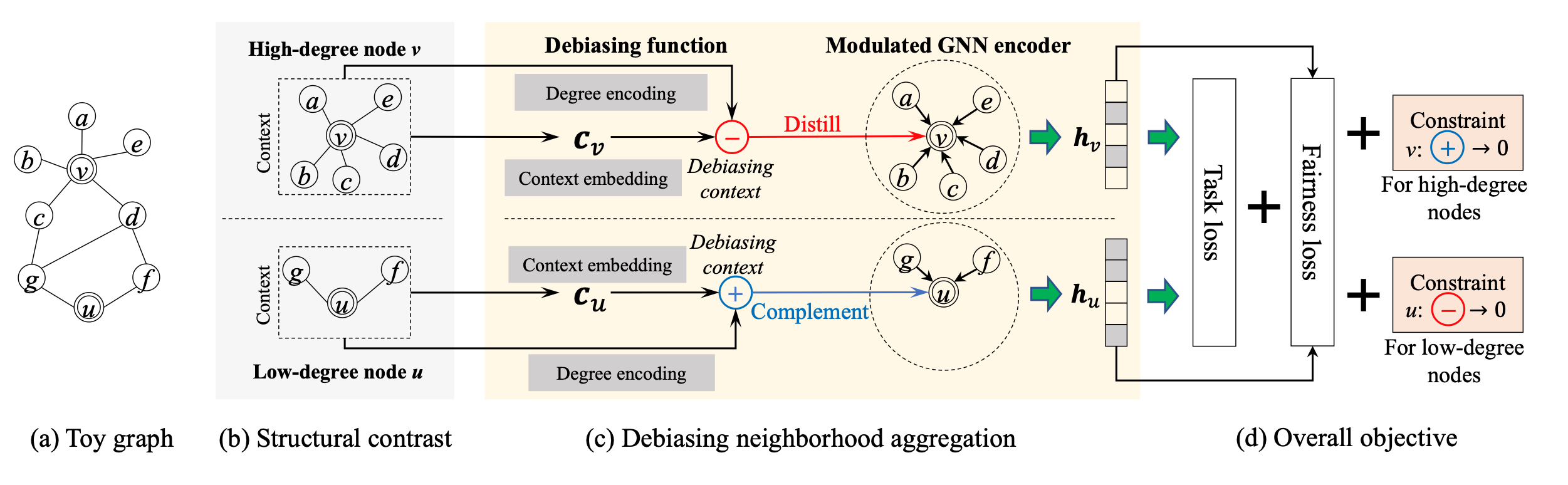
- degree fairness 에 대해 들어보셨나요? 논문에서는 그 현상에 대해서 다음과 같이 이야기합니다. Generally, a node of larger degree is more likely to possess crucial advantages and thus receives more favorable outcomes than warranted. ****GNN는 degree 에 따라 정보의 전달량이 달라지고 그 정보의 전달에 따라 node의 smoothness가 달라지기 때문에, 이를 어떻게 적절히 배분하는지가 중요합니다. 배분을 어떻게 해주는지 여러 영역들이 존재하는데요.
- 여기에서는 degree fairness 관점으로 접근합니다. 구체적으로 말하자면, ****debiasing function to generate different debiasing contexts 를 통해 높은 degree 를 가진 노드에겐 distill 반대로 낮은 degree 를 가진 노드에겐 complement 를 적용해주는 learnable function 을 적용시키는거죠. 그 얼개는 다음과 같습니다.
- 먼저 degree 가 높고 낮음에 대한 기준(하이퍼파라미터)를 설정해주고 그에 따라 두 그룹으로 나누어줍니다. 이후, debiasing 을 위해 1. Comprehensiveness structure 과 context 정보를 담기 위한 Pooling 2. Adaptiveness node 별로 가지고 있는 degree 를 반영(fine-grained adpation)하기 위한 degree-specific encoding 두가지 과정을 거칩니다. 이때, 노드별로 비슷한 degree 를 가지고 있으면 벡터가 비슷해지기에 over-smoothing 현상이 발생하므로 이를 방지하기 위해 추가로 positional encoding 을 반영해줍니다.
- 최종적으로 도출된 벡터를 학습하기 위해 두 가지 objective function를 활용합니다. 1. Node classification 을 위한 Loss, 2. degree fairness 를 위한 Loss 두 가지를 활용합니다. 후자인 degree fairness가 DSP-based loss 를 활용합니다.이때 fairness Loss는 두 개의 그룹(high degree group , low degree group) 간에 예측 분포가 유사해지도록 제한하는 것을 목표로 합니다.
Learning Stance Embeddings from Signed Social Graphs
[https://arxiv.org/pdf/2201.11675.pdf]
wsdm2022 best awards
- 3월초부터 일주일 간 진행했던 WSDM2023이 성황리에 마무리되었습니다. 이번 컨퍼런스 역시 재밌는 튜토리얼과 논문들 워크샵 등 콘텐츠 한가득 이였는데요. 이번에 탭에서 공유드릴 논문은 그 중 best awards paper 입니다.
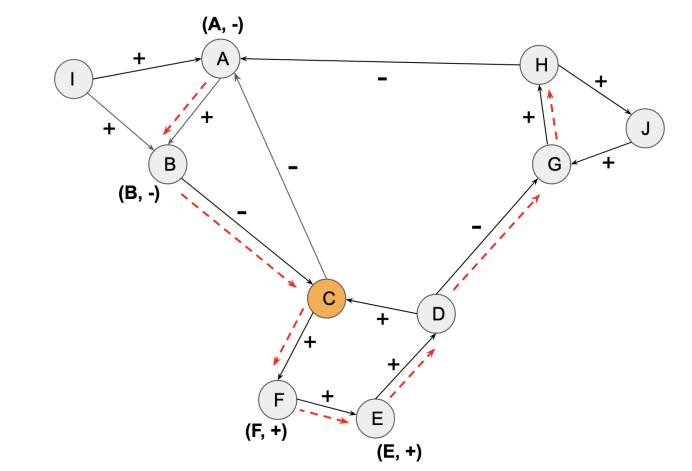
- 흔히 저희가 알고 있는 그래프의 종류에는 가중치/비가중치 , 동종/이종 , 유향/무향 이 대표적입니다. 이외에도 노드간의 관계의 긍/부정을 직접 명시하기 위한 그래프가 존재하는데요. 바로 ‘singed network’ 입니다. 주로 사람간의 관계를 분석하기 위해 활용하기에 소셜네트워크 분석에서 자주 보이곤 합니다. 대표적인 예로는 트럼프 대통령의 트윗을 기반으로 사람들간의 관계 분석이 있겠습니다.이 논문에서는, 'singed network'에서 긍정/부정 관계를 분석하는 것을 넘어서, 각 트윗이 어떤 주제에 대한 긍정/부정을 포함하는지를 고려하여 임베딩하는 방법을 제안합니다.
- 주제를 기반으로 특정 현상에 대해 합의한다면 긍정, 합의하지 않는다면 부정으로 볼 수 있습니다. 그렇다면, 합의하는지에 대한 여부를 저희는 어떻게 파악할 수 있을까요? 주제에 대해 의견을 표시하지 않는 사람도 있을 수 있기 때문에, 이러한 상황을 처리하기 위해 "Heider's social balance theory"를 사용합니다. 이론은 사람들 간의 균형을 유지하려는 경향이 있다는 것을 제안하며, 긍정적인 관계와 부정적인 관계를 유지하기 위해 각각의 사람들이 자신의 태도를 조정하거나 다른 사람과의 관계를 조정하는 것을 포함합니다. 따라서 이 이론을 적용하여, 주제에 대한 의견을 표시하지 않는 사람들도 고려하여 합의 여부를 파악할 수 있습니다.
- Heider’s social balance theory 에 대한 설명은 다음과 같습니다. “Heider's social balance theory is a psychological theory that explains how individuals perceive and evaluate relationships between people. The theory proposes that individuals strive for balance in their social relationships and that they actively work to achieve this balance.” 그 이론을 기반으로 설립된 여러 규칙 중 다음 3가지 규칙을 본 논문에서 활용합니다. [1] 내 친구(+)의 친구(+)는 친구(+)다. [2] 내 친구(+)의 적(-)은 나의 적(-)이다. [3] 내 적(-)의 적(-)은 나의 친구(+)다. 와 같이 [1][2][3]의 룰을 반영해줍니다.
- 그럼 이 규칙을 어떻게 반영할까요? 그것은 우리가 잘 알고 있는 랜덤 워크 알고리즘의 결과물인 순회 확률(transition probability)을 통해 + 와 - 에 대한 signed 정보를 전달합니다. 이 일련의 과정을 통해 source, context and topic 3가지 벡터가 도출되고, 이 벡터들을 최적화하기 위해 skip-gram 을 활용합니다. 핵심은 Context (singed) 벡터를 잘 반영한 임베딩 모델을 도출하는 것이기 때문에, 이를 예측하기 위해 유저와 토픽에 대한 정보를 기반으로 context를 학습해가는 방식으로 skip-gram 을 적용해준다 라고 보시면 되겠습니다.
- 알고리즘 뿐만아니라, 어떤식으로 signed graph 로 설계할지 그리고 실험결과까지 부차적인 요소 또한 흥미롭습니다. 특정 토픽을 기반으로 유저간의 관계를 Projection하는것 뿐만아니라, 토픽이 ‘유저 signed 에 어떤 영향을 줄 지’와 같은 실험까지 등의 콘텐츠들이 논문의 마지막 부분을 아름답게 마무리 합니다.
- 그래프 기술의 기초인 random-walk 와 societal practical perceptive 가 잘 어울러진 논문이라 생각되네요. 처음 접했을 당시 best-award 를 수상한 논문이라, 잔뜩 긴장했었지만 재밌고 쉽게 읽었던 주방장을 보니 섣부른 판단이였던 것 같습니다. 어떻게 소셜관점과 그래프관점을 잘 접목했는지에 대한 호기심을 기반으로 보시면 굉장히 재밌을 논문이라 생각되네요. 사회과학쪽에서 그래프를 활용하실 분들께 추천드립니다.
DemoMotif: Demographic Inference from Sparse Records of Shopping Transactions based on Motif Patterns
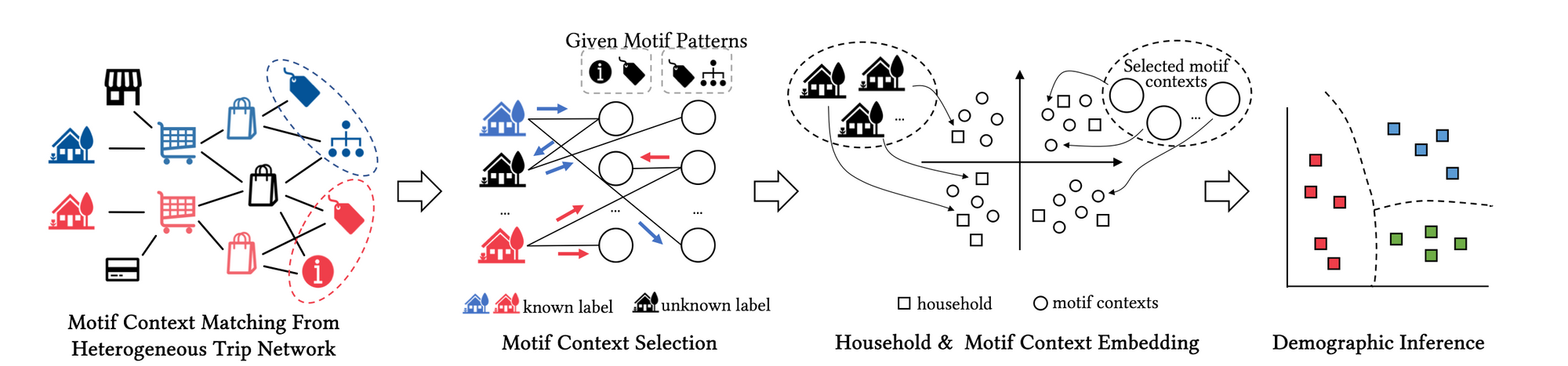
- 개인적으로 굉장히 흥미로웠던 논문이기에 여러분들과 꼭 공유하고 싶다. 라는 생각이 introduction 을 읽는 순간 떠올랐네요! 논문의 요지를 간단하게 말씀드리면, 고객들의 영수증과 같은 일련의 구매 행위들을 기반으로 고객의 인구통계학적정보를 유추하는 논문이라고 보시면 되겠습니다. 기존에는 행위들을 유저-아이템 이분그래프(bipartite)로 모델링하여 정보를 파악하고 예측하는 형식이였다면, 본 방법론은 행위들을 heterogeneous graph motif로 구성하여 motif 패턴 임베딩 최적화에 초점을 둡니다.
- heterogeneous 그래프 모델링 이 후, 유용한 motif 를 도출하기 위해 importance , concentration 라는 지표를 조합하여 scoring 을 해준 뒤, top ranking 에 속한 motif 를 해당 고객의 대표 패턴이라고 간주 한 뒤 임베딩 해줍니다. 이 후 임베딩값을 SVM classifier 를 통해 예측해주는게 제안 모델 시퀀스라고 보시면 되겠습니다.
- 제안 모델이 트랜스포머와 같은 트렌디한 모델들보다 성능이 뛰어난걸 보면, 성능 관점에서 모델의 파라미터다다익선과 같은 알고리즘 개발이 만능이 아닌, 목적에 맞게 그래프(데이터)를 모델링 하는 방식이 중요할 수 있다 라고 볼 수 있기에 이 점에서 시사하는 바가 큰 논문이라 생각합니다.
- 기존에는 모든 정보들을 심플하게 노드의 feature로 담아서 parameter update 하는 맥락이였다면, 이를 행위 노드로 간주하여 그래프로 모델링 한 후 motif embedding 하는 맥락. 그래프 모델링에 휴리스틱이 들어가겠으나 목적에 걸맞게 디자인한다면 그 핸디캡은 충분히 감안할 수 있지 않을까 라고 시야를 넓혀준 좋은 논문이였기에 일독 하시는걸 추천드립니다!
Engineering
Some Techniques To Make Your PyTorch Models Train (Much) Faster
[https://sebastianraschka.com/blog/2023/pytorch-faster.html]