2월 3주차 그래프 오마카세

Graph Neural Networks Go Forward-Forward modeling
[https://arxiv.org/pdf/2302.05282.pdf]
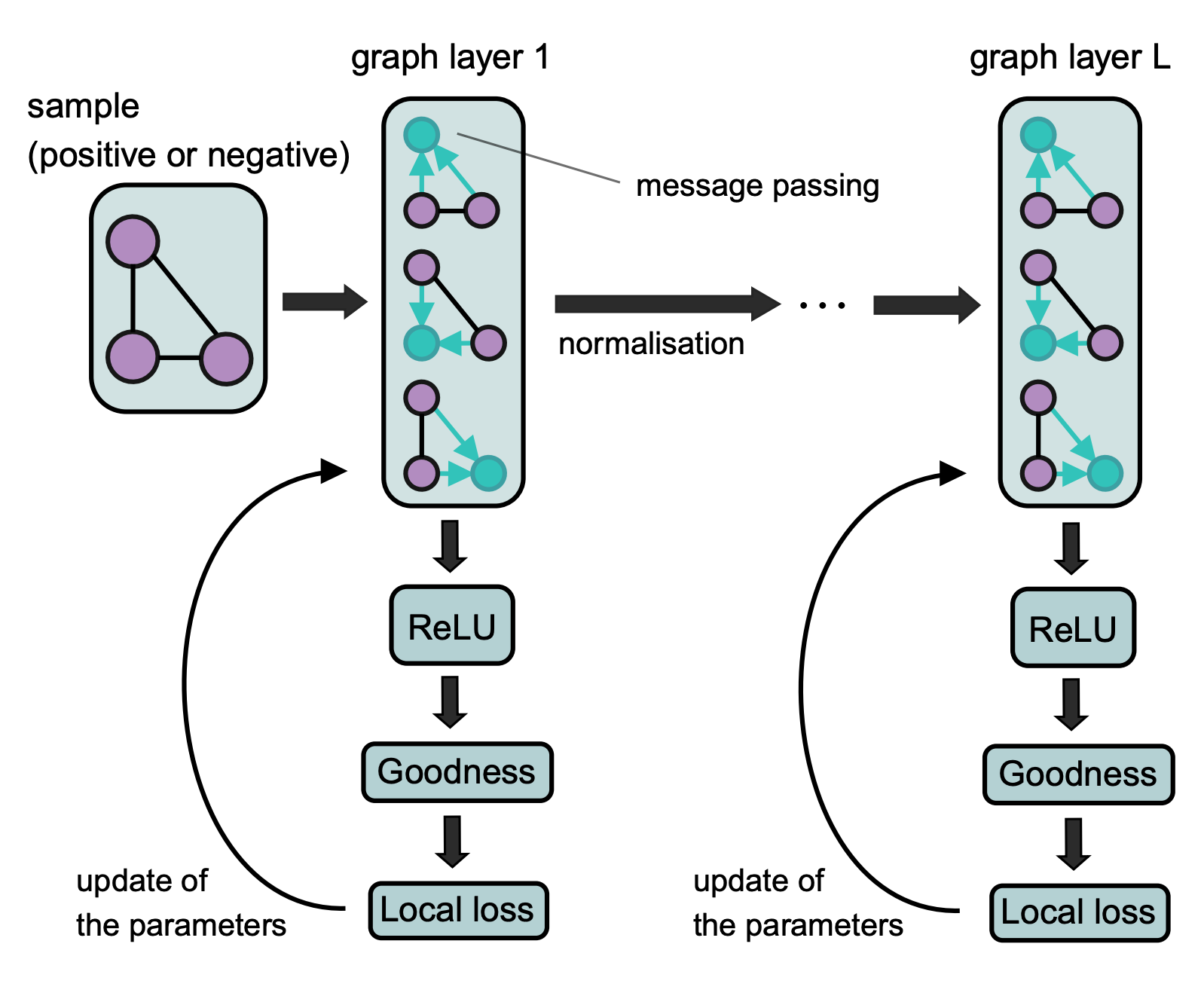
- ‘Backward 를 Forward 로 대체한다’라는 참신한 아이디어를 적용한 논문입니다. 레이어를 거듭하며 파라미터가 갱신되는 기존 학습 방식과 다르게, 오직 한 레이어에서 파라미터가 갱신되는 방식입니다. 그럼 자연스레 체인룰 과정이 생략되며 cost 가 간소화되는 효용을 얻을 수 있습니다.
- 본 논문의 핵심은 다음 세가지로 볼 수 있습니다. 1. label encoding 2. Goodness function of a graph 3. Inference without backprop
- label encoding
- 그래프 pos / neg label 을 어떻게 입력 할지에 대한 이야기입니다. 기존 방식은 label 를 ground truth 로 지정해줘서 레이어를 거치며 도출된 벡터값과 비교하며 학습 최적화가 될 텐데요. 본 논문에서는 backprop 방식을 사용하지 않기 때문에, label 정보를 ground truth가 아닌 feature 로 활용합니다.
- 이 때 feature 를 node 에 concat 해줄지, virtual node를 생성해서 적용할지 두가지 방식으로 나뉘게 됩니다. 연결된 local node 들을 활용할 것인가, 연결 관계없이 global node 를 활용할 것인가 관점으로 보시면 되겠습니다.
- local-loss
- label encoding 된 값들을 message passing , aggregate 해줍니다. 그렇다면, label 정보가 반영된 vector 나 도출되겠죠? vector 품질 향상을 위해 pos 값은 높게 , neg 값은 낮게 학습해주는 Local loss 를 활용합니다.
- 이 때, 드시는 의문은 아마 backprop 를 생략하며 optimization cost 를 줄인게 본 논문의 novelty 인데 여기에서 그 Cost 를 다 잡아먹는게 아닐까? 라고 생각하실텐데요. 기존은 forward , backward prop 에서 발생하는 chain rule 이 여기에선 발생하지 않는다. 즉, one-layer optimization 이기 때문에 효율적이다 라고 주장합니다.
- inference
- 이렇게 학습된 label vector 를 기존 node feature 와 append 해주고, argmax 를 하는 방식으로 추론합니다.
- chain-rule 의 cost 를 contrastive learning 로 풀어내는 관점이 흥미로웠던 논문입니다. large , big 같은 대용량 학습 트렌드에서 새로운 관점을 제시할 수 있는 논문이라 생각되네요.
On the Connection Between MPNN and Graph Transformer
[https://arxiv.org/abs/2301.11956]
- 그림이 보이지않고, 수학에 대한 증명이 한가득 담겨 있는 논문입니다. Why graph transformer? 라는 질문에 답할 수 있는 여러 테크닉들이 담겨있습니다. 더불어, Graph Transformer 관점들을 적용한 GPS , Graphhormer 등 sota 들과 비교한 부분이 흥미롭습니다.
- 또한 1 - O(1) depth O(1) width , 2- O(1) depth O(n^d) width , 3 - O(n) width O(1) depth 등 연산량이 방대한 graph transformer를 어떤식으로 최적화하고 그에 따라 한계가 무엇인지 이야기합니다. (performer , linear transformer)
- graph transformer 를 기반으로 논문을 작성하고 싶으시거나 , 왜 Transformer 에서 positional encoding , self attention 가 중요한지 궁금하거나 수학적으로 음미하고 싶으신 분들께서 보시면 좋을 논문입니다.
A GENERALIZATION OF VIT/MLP-MIXER TO GRAPHS
[https://arxiv.org/pdf/2212.13350.pdf]
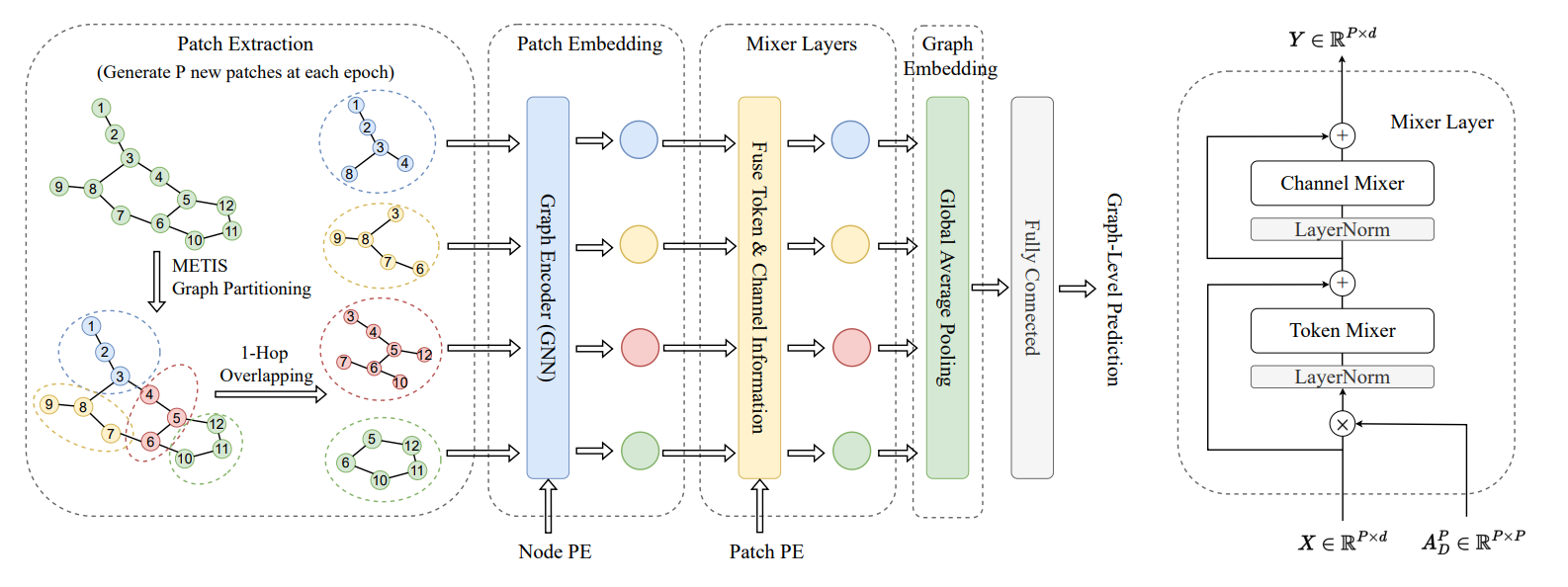
- Mixer , MLP 와 같은 simple MLP 가 복잡한 모델보다 성능이 좋은 경우들이 종종 보이고 있습니다. 본 논문에서는 graph 분야에서 중요하게 생각되는 over-squashing , long-range dependency 두가지 문제를 MLP mixer 기술로 해결해보고자 시도합니다.
- 심플하고 가벼운 아키텍쳐인 MLP 를 사용했기에 속도, 메모리 측면에서 좋은 결과가 나왔다 라는것은 당연하게 받아들일 수 있지만, isomorphism (expressive power) 측면에서도 성능 개선 결과를 보입니다.
- Path embedding 과 Mixer Layer 에서 사용한 Positional encoding 가 핵심이라 생각되네요. VIT 의 관점을 차용하기 위해 patch extraction phase 에서 그래프 파티셔닝 기술인 METIS 를 활용한 생각도 너무 기발하다고 생각됩니다. 여기에 발생하는 overlapping 문제를 역으로 diffusion 측면으로 적용하는 측면도 재밌어보이구요.
- 여러모로 기발한 기술들이 많이 들어간 논문이라 생각됩니다.
An Introduction to Topological Data Analysis: Fundamental and Practical Aspects for Data Scientists
[https://www.frontiersin.org/articles/10.3389/frai.2021.667963/full]
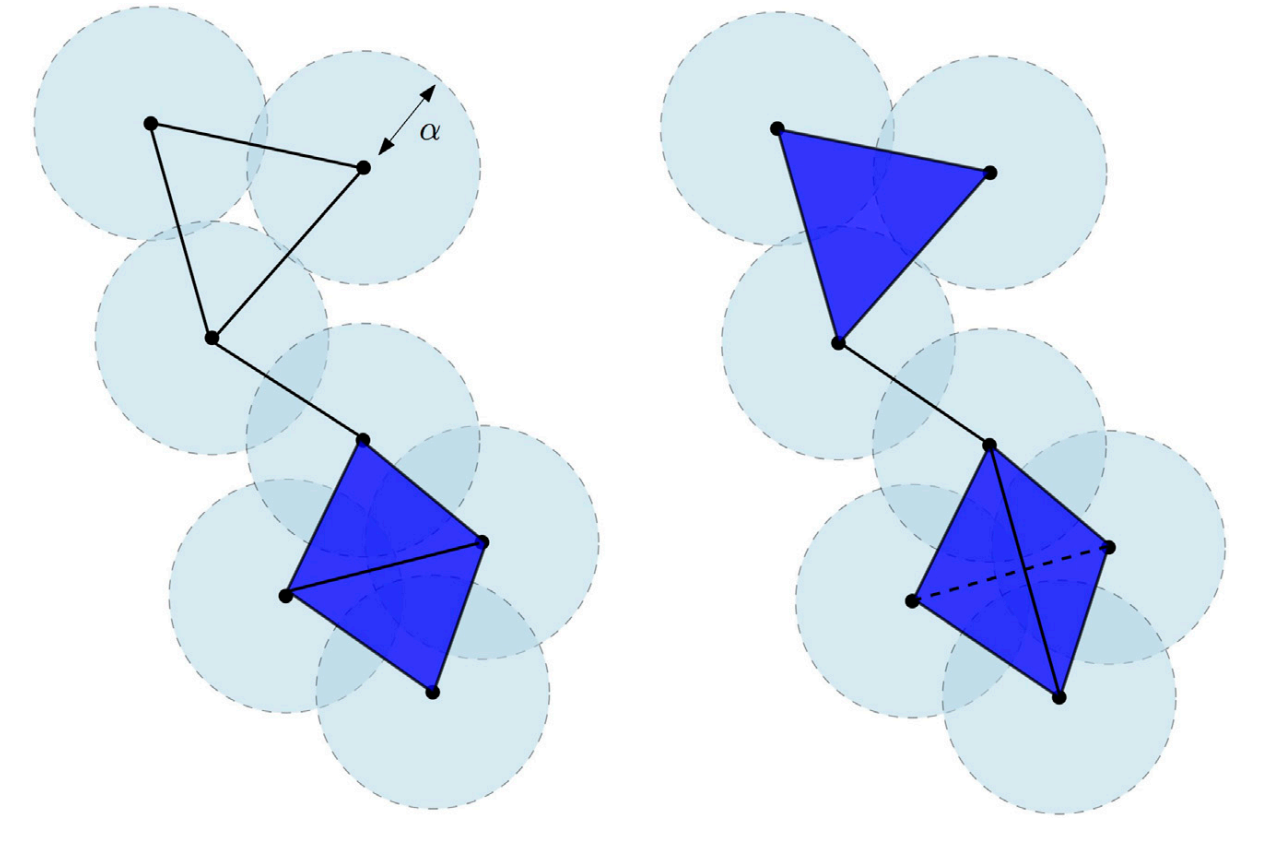
- 위상 수학을 공부하신분들께선 익숙하신 그림이라 생각되네요. 오늘은 네트워크 분석을 통해 topology 를 해석하는 방식이 아닌 위상 수학 topology analysis 를 통해 topology 를 어떻게 접근하는지에 대한 자료를 가져왔습니다.
- 간단한게 위상분석과 네트워크 분석의 차이에 대해 말씀드려보자면, 위상 분석과 네트워크 분석은 복잡한 시스템을 연구하기 위한 두 가지 다른 접근법입니다. 둘 다 상호 연결된 시스템의 분석을 포함하지만, 위상을 각각 다른 측면으로 접근합니다.
- 위상 분석은 네트워크의 구조를 연구하는 수학적 접근법이다. 네트워크의 노드가 연결되고 배열되는 방식과 이러한 연결에서 나타나는 패턴과 관계에 초점을 맞춘다. 토폴로지 분석의 목표는 네트워크의 전체 구조를 이해하고 네트워크 내의 주요 노드, 클러스터 및 경로를 식별하는 것입니다.
- 반면에, 네트워크 분석은 네트워크를 통한 정보, 자원 또는 신호의 흐름에 초점을 맞추는 것 보다 더욱 실용적인 접근법이다. 정보 또는 리소스를 전송하기 위한 가장 효율적인 경로를 식별하고 노드 장애 또는 섭동이 네트워크 성능에 미치는 영향을 이해하는 것을 목표로 합니다. 구체적으로는 중심성, 모듈성 및 연결성과 같은 네트워크 속성을 정량화하고 이러한 측정을 사용하여 네트워크 동작에 대한 예측을 수행하는 것을 포함한다.
- 요약하자면, 위상 분석은 네트워크의 구조와 관련이 있는 반면, 네트워크 분석은 네트워크의 행동과 기능에 관련이 있다. 두 접근법 모두 복잡한 시스템을 이해하는 데 중요하며, 종종 네트워크 시스템에 대한 포괄적인 이해를 제공하기 위해 결합하여 사용됩니다.
- 아티클 제목을 보시면 아시다시피 데이터 사이언티스트를 위한 Topology analysis 입니다. 아마도 3D + graph 를 공부하시는 분들에게 많은 도움이 될 것 같네요 !