3월 3주차 그래프 오마카세

Weighted flow diffusion for local graph clustering with node attributes: an algorithm and statistical guarantees
[https://arxiv.org/pdf/2301.13187.pdf]

- graph clustering 방법론들은 노드 , 엣지의 구조만을 활용한 방식들이 대다수입니다. large graph 에서 conductance 라는 서브 그래프간 tightly connected 를 측정하는 지표를 토대로 clustering 이 잘 되었는지 되지 않았는지를 판단하곤 했죠. 하지만, 그래프 구조 정보만을 얻고 , 활용할 수 있었던 이전과 다르게 현재는 node , edge attributes 과 같은 정보또한 얻고 활용할 수 있기에 그래프 구조만을 토대로 Clustering 하는 기존 방법론들은 old-fashioned 한 경향을 보입니다.
- 제안 방법론에서는 attribute 를 활용하기 위해 flow diffusion model 을 차용합니다. 노드간 전달되는 load를 weighted graph 형태로 적용하며, 노드간 proximity 를 반영해주는거죠.
- 방법론 세부 과정은 다음과 같습니다. 1. edge 간 weight 를 적용 2. edge flow 를 통해 mass(attributes) 전달. 3. 특정 loss(최적화) 를 만족할 때 까지 1,2 과정 반복진행. 이때, final mass 를 기준으로 반복진행 유무를 판단합니다. 4. 이렇게 최적화된 mass 를 proximity 라 가정하고 그에 기반하여 clustering 을 해줍니다.
- 그럼 여기에서 의문이 하나 드실텐데요. 바로 degree계수가 높고 적음 (edge 연결이 많고 적음)에 따라 mass 의 편차가 클텐데, 이 편차가 결국 mass flow 에 dominant 하지않을까요? 라는 의문을요! 그 점을 해결하기 위해 본 논문에서는 Sink capacity 라는 파라미터를 추가해줍니다.
- 쉽게 말씀드려보자면 해당 노드가 타 노드에게 재전달할 수 있는 정보의 양 이라고 보시면 되겠습니다. 이를 통해 모델 정보 전달 시, mass 와 sink capacity 를 balance 하게 맞추어줌으로써 degree dominant 를 해소한다 라고 보시면 되겠습니다.
- 실험 결과가 흥미롭습니다. good node attributes 일수록 clustering 에서 좋은 결과를 보인다고 하네요. modularity 지표에 근거하여 clustering 을 진행했던 기존 방법론들에 대해서 과연 그래프의 구조적인 특성만을 가지고 clustering 이 잘 될까?라는 호기심을 가지고 있었는데요. 그 호기심을 본 논문으로 해소할 수 있었습니다.
- clustering + attribute 를 diffusion operator 네트워크 이론 측면으로 접근했다는 측면에서 굉장히 재밌었습니다. good attributes 기준을 어떻게 설정하는지에 대해서도 이야기가 나와있으니, node feature engineering 에 대한 고민이 있으신 분들에게 도움이 될 거라 생각되네요!
LazyGNN: Large-Scale Graph Neural Networks via Lazy Propagation
[https://arxiv.org/pdf/2302.01503.pdf]
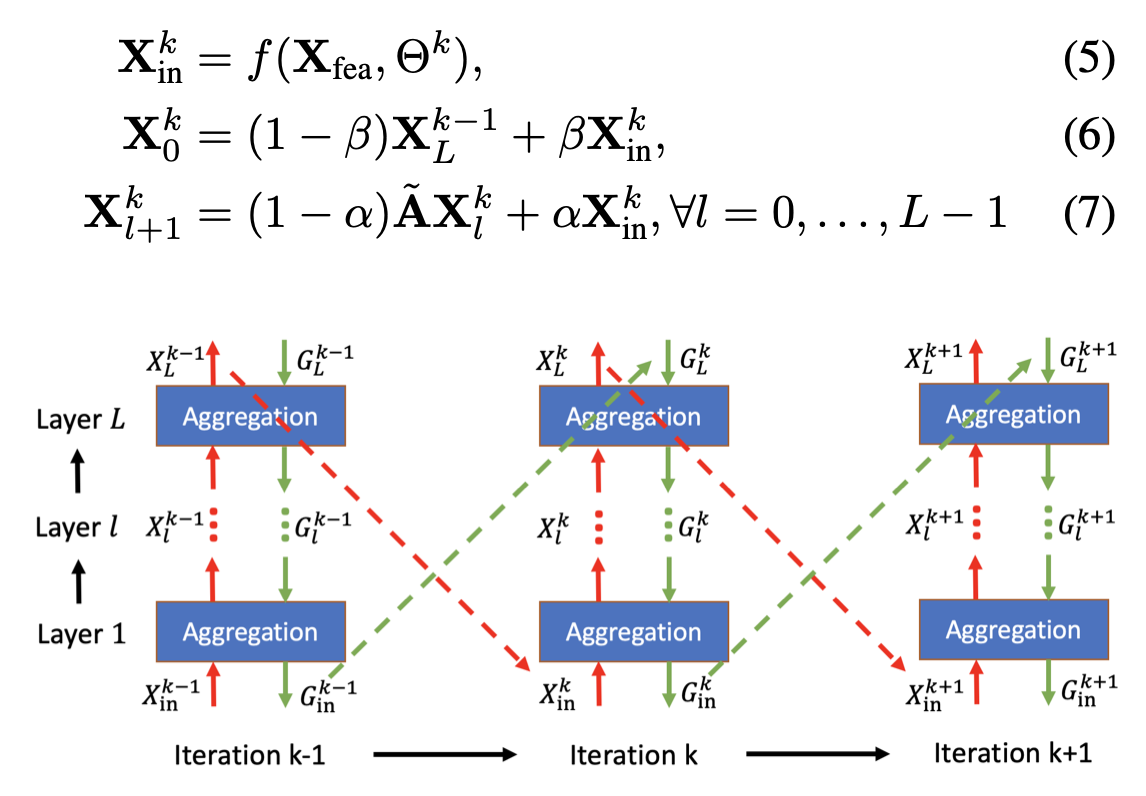
- GNN 은 크게 spectral , spatial 의 방식으로 나누어 적용되곤 합니다. 각각 , signal-decompose 관점과 hop-based 관점으로 나누어진다고 보시면 되겠습니다. spectral 접근방식은 graph 에서 발생하는 정보들을 diffuse 로 접근하여 decompose 하기에 global-pattern 정보를 반영하는데 유리한 반면 spatial 접근방식은 hop 에 따라 node attribute 를 fine-grained 하기에 local-pattern 정보를 반영하는데 유리하다고 보시면 되겠습니다. 각각의 방법론 마다의 장단이 있기에 마주하고 있는 task 에 따라 취사선택하시며 활용하시면 됩니다.
- 서두에 GNN 의 기본에 대해 이야기를 꺼내게 된 이유는 바로 본 논문은 spectral 관점에서 발생하는 Diffusion information 을 효율적으로 다룸으로써, 그래프 임베딩의 고질적인 문제인 ‘over-smoothing’ 을 해결하는 방안을 제시합니다.
- 간단하게 요약해보자면, graph node간 발생하는 load (message)의 기울기 정보를 초기화 하지 않고 재활용하여 layer를 수를 줄이고 그에 따라 load에서의 최적의 정보만을 활용하는게 논문의 아이디어 라고 보시면 되겠습니다.
- 그럼 이 기울기 정보를 어떻게 활용할 것이냐? 라는 의문이 드실텐데요. 기울기 정보에 iteration 태깅을 해주며 Aggregation 시 재활용해줍니다. 이 접근법이 가능하게 된 이유는 spectral 관점인 signal denoising problem 에서 denoising function 의 기능을 하는 Regularization term 에 기울기 정보를 추가해주었기 때문입니다.
- 그런 점에서 논문의 저자도 APPNP 논문의 아이디어에서 모티베이션을 얻게 되었다고 하네요. 다음으로 forward , backward 과정마다(computation graph) 발생하는 기울기 정보를 Implicit function theorem 을 활용해서 근사추정하며 기울기 정보를 재활용합니다.
- 논문의 핵심은 기울기 정보와 그래프 확산 이론을 결합한 아이디어입니다. 따라서 딥러닝의 핵심인 순전파와 역전파의 흐름에 대한 이해와 그래프 정보 이론에 이해가 있는 분들이 이 논문을 쉽게 볼 수 있을 것입니다.
- 또한, 메시지 패싱에서 파라미터가 어떻게 업데이트되는지, 그리고 그 파라미터가 속도와 정확도에 어떤 영향을 미치는지 궁금해하시는 분들에게 이 논문을 추천합니다. 이 논문은 대용량 그래프 데이터에서 발생하는 over-smoothing 문제를 해결하고자 제안되었기 때문에, 현업에서 GNN을 활용하고 싶지만 대용량 데이터 모델로 인해 고민하는 분들에게도 도움이 될 것입니다.
Attending to Graph Transformers
[https://arxiv.org/pdf/2302.04181.pdf]
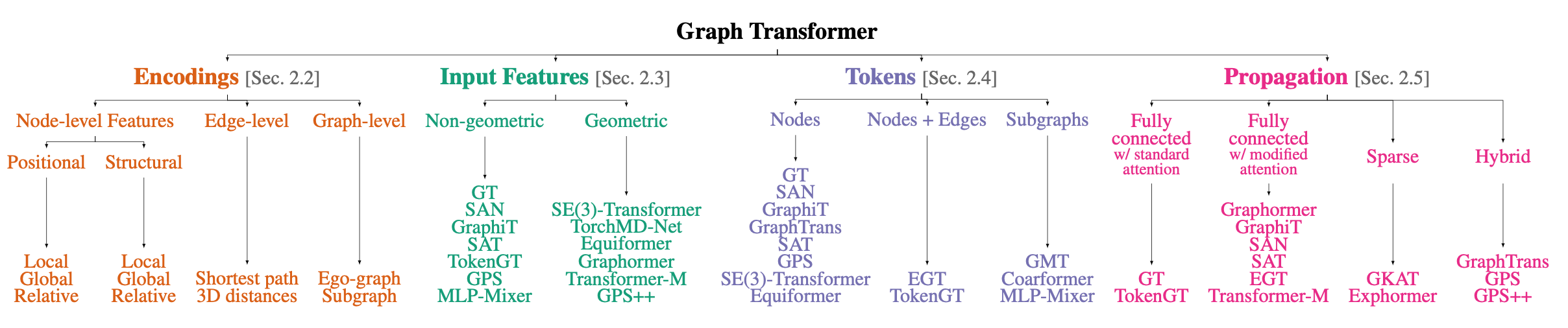
- GNN과 Graph Transformer 과의 차이점을 꼽아보자면 graph data 접근 방식으로 볼 수 있습니다. GNN은 저희가 알고 있는 그래프 노드 엣지로 간주한다면, Graph Transformer은 그래프의 요소들을 개별 토큰으로 간주합니다.
- 자연어처리에서 차용된 구조이기에 마찬가지로 그래프의 정보를 multi-attention 로 계산해주고, positional encoding 로 업데이트 해 줄 그래프 위치정보를 추출한 뒤 토큰 by 토큰으로 업데이트 합니다. GNN 의 message passing 과정이 multi-attention 으로 대체되었다고 말씀드리면 이해하시기에 수월하실거라 생각되네요. 또한 구조적인 정보를 반영하기 위해 GNN 은 equivalent check 방식을 활용했다면, GT는 positional encoding을 활용하여 임베딩을 feature로 추가 적용해줍니다.
- 이처럼, GT는 GNN과 비슷해보이지만 미묘하게 다른 구조를 가지고 있습니다. 특히 그래프 요소들을 ‘토큰’으로 간주하기 때문에, 이를 어떻게 다룰지가 핵심이며 벡터 공간상에서 토큰의 식별을 위한 structural , positional encoding 개선 연구가 많이 이루어지고 있습니다.
- 본 논문에서는 GT 의 Encoding , input feature , tokenize , propagation 4가지 요소들에 따라 각 task들에 어떤 영향을 미치는가에 대한 Research question 을 answering 합니다. 뿐만아니라, globally , locally attention 을 진행하기 때문에 over-smoothing 과 over-squashing 문제에 직면하게 되는데 이를 어떻게 해결하는지?에 대한 실험과 실험결과에 대한 해석도 잘 나와있습니다.
- Graph Transformer 구조를 베이스로 삼고 발명된 모델들이 OGB leader board 상위권에 속해있는걸보면, 머지않아 Graph 데이터 에서도 Transformer의 시대가 오지않을까 하는 생각이 드네요. Graph Transformer 모델 활용전, 시행착오를 줄이기에 좋은 지침서가 될 논문이라 판단되어 추천드립니다!
Why (Graph) DBMSs Need New Join Algorithms: The Story of Worst-case Optimal Join Algorithms
[https://kuzudb.com/blog/wcoj.html]
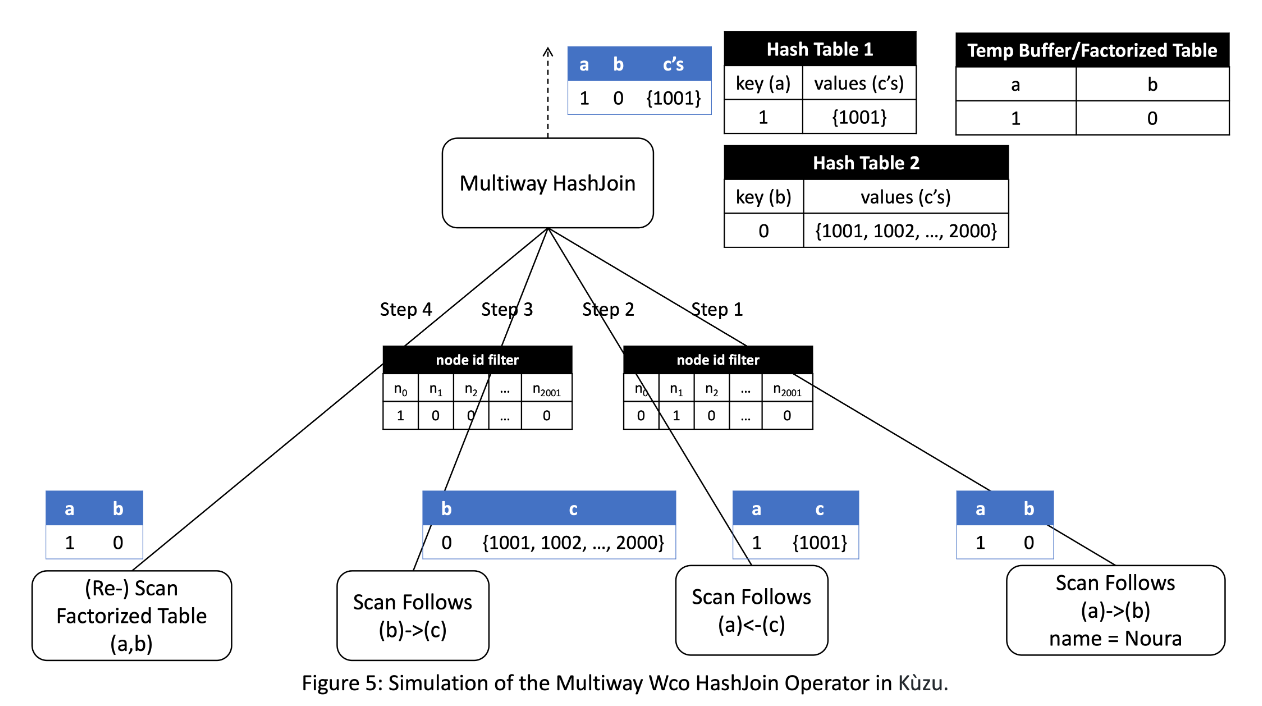
- "wcoj " 이라는 단어를 들어보셨나요? worst-case optimal join algorithm의 줄임말입니다. 이는, 입력 데이터가 frequently cyclic 이 반복되는 요소와 multi-intersection 을 갖는 최악의 상황에서도 효율적으로 수행될 수 있도록 설계된 알고리즘을 가리킵니다.
- 이러한 상황은 전통적인 조인 알고리즘에 대비해서 상당히 도전적이며, 쿼리 처리 시간이 상당히 증가할 수 있습니다. 알고리즘 효율화를 위해 필터링, 가지치기 및 샘플링과 같은 고급 기술을 사용하여 조인 연산을 최적화하고 처리해야 할 데이터 양을 최소화합니다.결론적으로 wcoj 는 복잡한 데이터 구조와 대규모 데이터셋이 있는 시나리오에서 더 빠른 쿼리 처리 시간과 더 나은 전체 성능을 제공할 수 있습니다.
- 결국 wcoj 는 cyclic , multi-intersection 의 특성이 반영되어 있는 데이터를 분석 및 가공할 때 유용하다고 볼 수 있습니다. 이 데이터들은 graph 에서 흔히 활용되는 FDS 와 recommenation 에서 그 진가를 발휘합니다.
- directed graph 형태로 누가 누구에게 무슨 행동을 하는지에 대한 정보를 추적해야하는거죠. 허나 이 모두 multi joint , 그리고 cyclic 하기에 많은 조인 연산이 필요합니다. 그 조인에 대한 최적화를 wcoj 를 통해 진행한다고 보시면 되겠습니다. 이 아이디어의 핵심에는 ‘factorized table’이 있습니다. 테이블 정보를 decompose 해주어 scan computation cost 를 줄여주는게 골자인 기술이죠.
- 그래프 데이터 베이스 효율성은 결국 Join speed , large dataset handling 이라고 볼 수 있습니다. 결국 실시간성 데이터가 많아지는 요즘 그 데이터들을 어떻게 잘 소화시키는지가 핵심인데요. 그 효율성의 기조가 되는 기술들에 대해 궁금하셨던 분들에게 좋을 자료라고 생각되네요.