5월 3주차 그래프 오마카세


Context-Aware Knowledge Graph Chatbot With GPT-4 and Neo4j
[https://medium.com/neo4j/context-aware-knowledge-graph-chatbot-with-gpt-4-and-neo4j-d3a99e8ae21e]
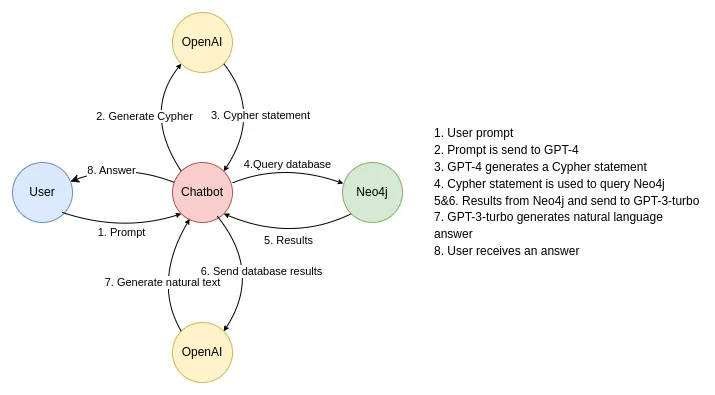
Knowledge graph 를 통해 어떻게 Chatgpt 성능을 향상할 수 있을까요 ? 본 아티클에서는 chatgpt 고질적인 문제 hallucinations , 거짓말을 진실처럼 포장해서 자신있게 대답하는 chatgpt를 어떻게 개선할지에 대한 이야기를 합니다.
chatgpt 를 활용해서 neo4j 에 적재되어있는 knowledge graph를 조회하기 위한 query 를 생성하고, 해당 query 를 통해 도출된 결과물을 기반으로 프롬프트를 chatgpt에 질의합니다. 그럼 여기에서 knowledge graph를 기반으로 프롬프트를 적용하기 때문에, chatgpt로부터 실제 사실에 더욱 근접한 답변을 얻을 수 있습니다.
neo4j는 triple store 가 아닌 native graph store 이기 때문에 knowledge graph 를 사용하기엔 적합치 않은 부분도 존재하나 graph database 의 특성을 가지고 있기에타 db 대비 효율적이긴 합니다.
** knowledge graph engineering 분의 인터뷰에서도 말씀드리겠으나 knowledge graph 를 다룰땐 주로 ontotext 나 neptune 을 활용한다고 합니다. 자세한 이야기는 인터뷰에서 말씀드리겠습니다.
LEARNING ON LARGE-SCALE TEXT-ATTRIBUTED GRAPHS VIA VARIATIONAL INFERENCE
[https://arxiv.org/pdf/2210.14709.pdf]
Introduction
motivation
LLM (local pattern of text)과 GNN (global pattern of text , proximity) 의 장점을 모두 적용하자니 scalbility 문제가 발생해서 어떻게 그 문제를 해결할까 고민하다가 EM(Expectation–maximization algorithm) 을 활용해보자! 해서 탄생한 아이디어 입니다.
idea
E step , M step 마다 LLM , GNN 을 fix or optimization 하는 방식으로 파라미터를 최적화 시키는 아이디어입니다.
Preliminaries
EM algorithm high-level explanation
- initialization: Start by initializing the model's parameters, either randomly or based on some prior knowledge.
- Expectation (E-step): Given the current parameter estimates, calculate the expected value of the missing or latent variables. In this step, you estimate the values of the hidden variables based on the observed data and the current model parameters.
- Maximization (M-step): Using the expected values obtained in the E-step, update the model parameters to maximize the likelihood of the observed data. This step involves finding the parameters that maximize the likelihood or log-likelihood function given the observed data and the expected values of the hidden variables.
- Repeat E-step and M-step: Iterate between the E-step and M-step until convergence. In each iteration, the E-step estimates the expected values of the hidden variables, and the M-step updates the model parameters based on these values. This process continues until the parameters converge to a stable solution.
The EM algorithm is based on the idea of maximizing the expectation of the complete data log-likelihood function, where the complete data includes both observed and latent variables. However, the presence of the latent variables makes the direct maximization of the likelihood function intractable. Therefore, the EM algorithm iteratively estimates the values of the latent variables and updates the model parameters until convergence.
Summary
Procedure
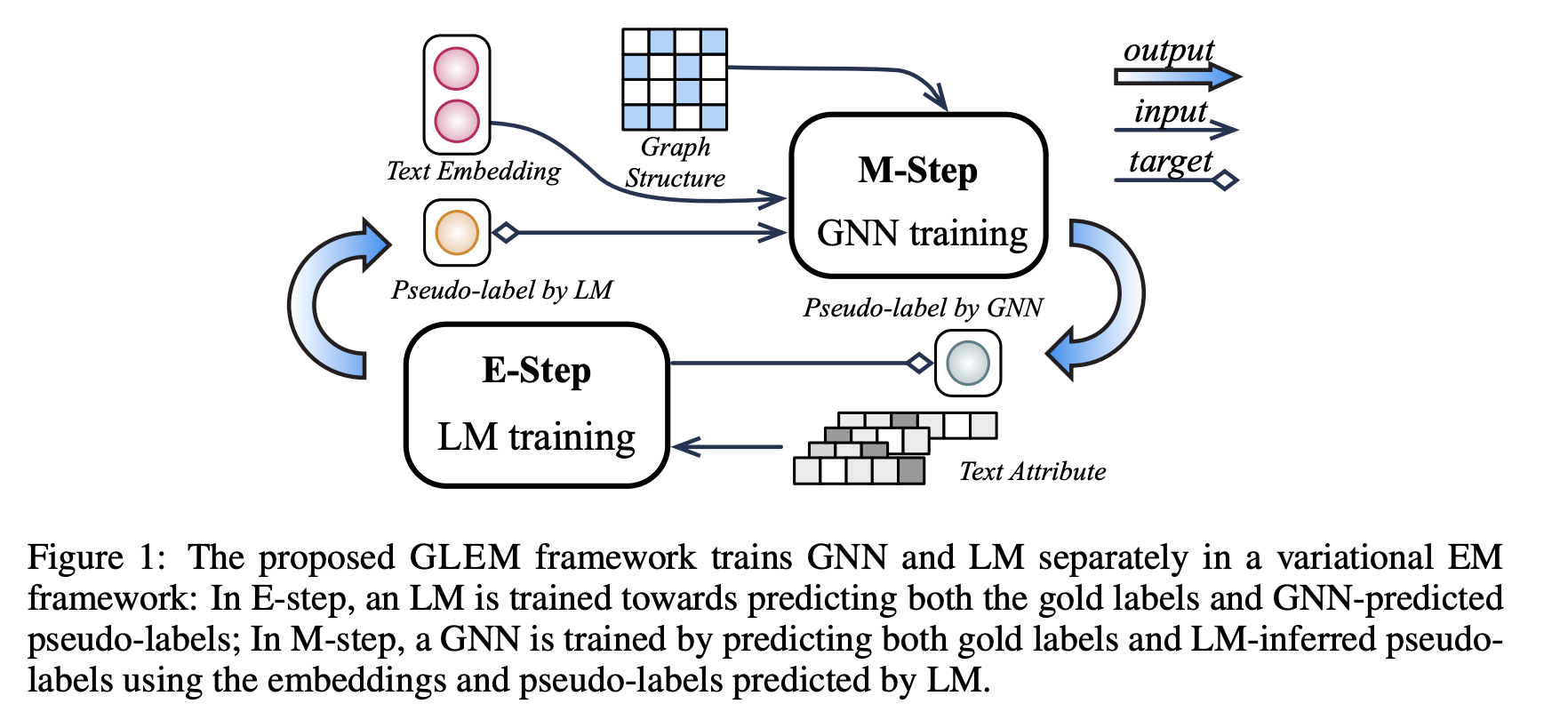
본 논문의 2가지 step 인 E step, M step에 대해 간략히 말씀드려보자면, E step - LM 모듈은 텍스트 속성을 입력으로 사용하고 앞의 단어가 지정된 순서대로 다음 단어를 예측하는 방법을 학습합니다. E step 의 output 은 trained model paramters 입니다. M step - GNN 모듈에 앞서 E step 에서 도출된 paramters 를 node attributes 로 넣어줍니다. 이렇게 도출된 parameters를 가지고 GNN training 합니다. M step 의 output 은 graph structure 이 반영된 trained model parameters 입니다.
결국 E,M step 의 결과인 model parameters 를 optimization 하는게 핵심이라고 할 수 있습니다. 이 optimization 의 기준은 lower bound 인데, 이 bound 는 pseudo-likelihood technique 를 통해 정합니다.
Experiment
transductive , inductive experiment 에서 모두 좋은 성능을 보입니다. OOD(out-of-distribution) 을 체크하는게 주 목적인 이 experiment 에서 본 아이디어가 좋은 성능을 보였다는건 각 model parameters 가 training 시 white noise 로 작용했다 라고 유추할 수 있기 때문에 Large model, data가 만능이 아닌, 모델을 통해 적절한 파라미터를 추출해서 적용하는 방법론이 증명되었다 라는 측면에서 시사하는 바가 크다고 생각합니다.
structure 정보 반영 여부에 따라 실험 성능이 달라지는 부분 또한 인상적입니다. 적게는 10% , 크게는 50% 까지 성능 변동이 발생하는걸로 보아 embedding space , proximity information(correlation) 이 중요한 요소로 작용한다.라고 유추할 수 있습니다. super sub architecture 라고 여겨졌던 gnn 정말 효과있음을 보여주는 실험결과 라고 생각할 수 있겠습니다.
Insight
discrete variable 인 text feature 을 gnn 의 input 으로 어떻게 변경해서 적용한 측면, 그리고 joint learning 을 EM algorithm 측면으로 접근한 측면, 그 두가지 측면이 저에게는 굉장히 흥미롭게 다가왔습니다. 기존 joint model training 그리고 joint loss 패러다임과 다르게 EM algorithm 을 적용했다는점이 되게 색다롭기에 그렇지 않았을까 싶네요.
NeuKron: Constant-Size Lossy Compression of Sparse Reorderable Matrices and Tensors
[https://arxiv.org/pdf/2302.04570.pdf]
Introduction
motivation
To the best of our knowledge, existing lossy-compression methods for sparse matrices create outputs whose sizes are at least linear in the numbers of rows and columns of the input matrix. For example, given an 𝑁-by-𝑀 matrix A and a positive integer 𝐾, truncated.singular value decomposition (T-SVD) outputs two matrices of which the numbers of entries are 𝑂(𝐾𝑁) and 𝑂(𝐾𝑀).
idea
Our key idea is to order rows and columns to facilitate our model to learn and exploit meaningful patterns in the input matrix for compression.
Preliminaries
The Kronecker product of two graphs involves taking every node in the first graph and connecting it to every node in the second graph, resulting in a new graph with a combination of edges and nodes from both original graphs. This operation is denoted by the ⊗ symbol.
Summary
본 논문 제안 알고리즘 순서는 다음과 같습니다.
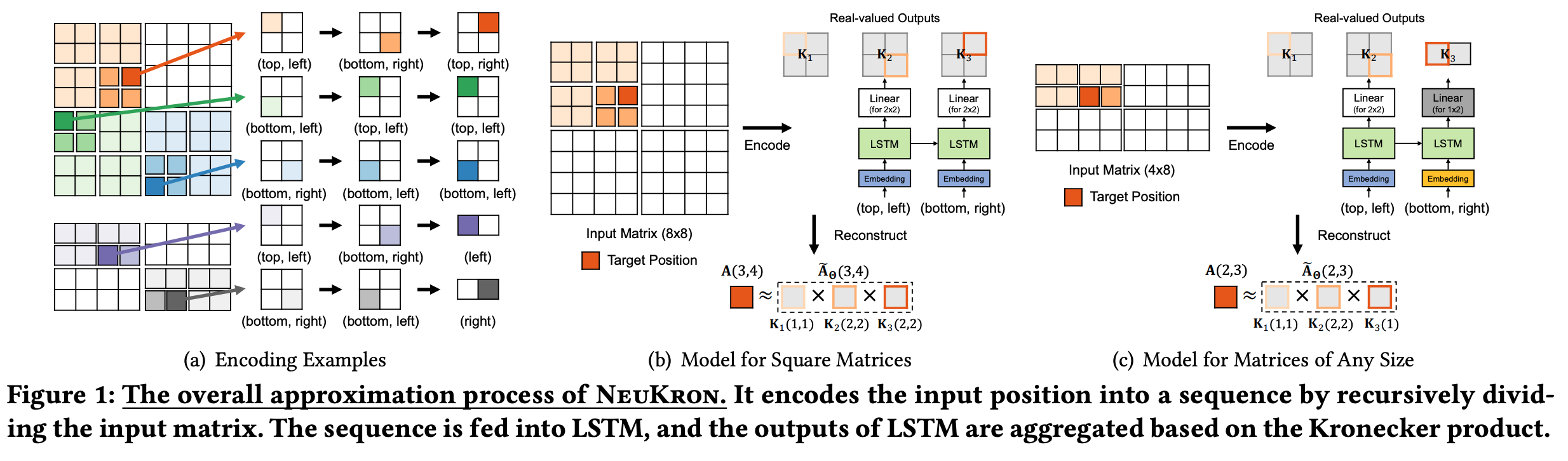
1.reorderable matrix A가 sparse 경우 행과 열을 재정렬하여 더 나은 압축을 위해 활용할 수 있는 패턴을 만듭니다. ** matrix 가 dense 한지, sparse 한지 판단하기 위해 주로 cut-off threshold 를 활용합니다.
2.A에서 각 항목 a_ij의 위치(i,j)를 시퀀스로 인코딩하여 LSTM에 입력합니다.
3.지도 학습을 사용하여 LSTM이 A의 위치(i,j)를 기반으로 각 항목 a_ij의 값을 예측하도록 훈련합니다.
4.LSTM이 훈련되면 항목을 시퀀스로 인코딩하고 예측을 위해 LSTM에 제공하여 새로운 행렬을 압축하는 데 사용합니다.
5.LSTM의 출력을 결합하여 로그 시간 내에 원래 매트릭스를 근사화하여 효율적인 압축을 달성합니다.
간단하게 이야기해보면 sparse matrix 에 positional encoding 을 해주고 그 positional encoding 값을 기반으로 LSTM(ML)을 활용해서 new sparse matrix 를 만듭니다. 그럼 여기에서 갑자기 LSTM 이 나온 이유에 대해 가장 궁금하실거라 생각이 됩니다.
LSTM은 original sparse matrix 에서 위치를 기반으로 값을 예측하도록 훈련되었기 때문에 new sparse matrix의 효율적인 압축에 활용할 수 있는 패턴과 상관 관계를 포착할 수 있습니다. 결과적으로 압축된 희소 행렬 new sparse matrix(LSTM output)는 original sparse의 크기보다 작은 일정한 양의 공간에 저장될 수 있습니다.
Insight
행렬 압축(matrix compression) skill들을 공부하기 좋습니다. 무엇이 좋고 무엇이 나쁜지에 대해 서술하며 아이디어를 이야기하는 형식으로 논문이 전개되었기에, 대표적인 matrix compression skill 들이 가지고 있는 장/단점에 대해 두루두루 공부하기 좋습니다. 데이터 엔지니어링에 대해 관심이 있으신분들에게 추천드립니다.
Google "We Have No Moat, And Neither Does OpenAI"
[https://www.semianalysis.com/p/google-we-have-no-moat-and-neither]
Google Bard, MS Chatgpt 등 빅테크 기업발 LLM 들은 모두 가짜해자를 가지고 있다. 라는 강한 어조를 시작으로 open-source model 의 중요성에 대해 이야기 합니다. 3~4월동안 많은 사건들이 발생했죠.
LLM parameter 노출부터 chatgpt , Bard 대전 등 해당 내용들에 대해서도 언급하며, 결국 현재 중요한 맥락인 Large model training 을 어떻게 효율적으로 할 것인가 에 대한 개괄적인 이야기를 합니다. 산학을 가리지않고 AI , data 에 종사하시는 분들이라면 꼭 한 번 읽으면 좋을 아티클이라 생각되어 공유드립니다.