4월 4주차 그래프 오마카세

미리보기
[ESN(Echo State Network) , spatio-temporal GNN 에서 큰 한계점이였던 spatio-temporal feature training 에서 발생하는 막대한 연산량을 절감하기 위해 접목한 방식 ESN. 속도와 성능 측면에서 결과를 의심할 정도로 좋은 결과를 보입니다. 그 원리는 무엇인지에 대해 다루어봅니다. ]
[Graph 종류는 굉장히 다양합니다. 주로 관계(edge)에 따라 많이 나뉘곤하는데요. 그때마다 task, modeling 등 다양한 접근방식이 존재합니다. 그 접근방식들에 대해 간결하게 정리해둔 서베이 논문에 대해 알아봅니다.]
[Higher-order assortativity, 네트워크 내 노드들이 Degree(연결계수)가 비슷한지 비슷하지않은지 분포에 대해 정량화하는 Assortativity. 그간 동종그래프의 전유물로만 생각되어왔는데요. 본 논문에서는 Higher-order graph에서도 적용할 수 있는 지표를 제안합니다. ]
[IPU(Intelligence Processing Unit) , Machine Learning 을 위해 발명된 Processor. GNN에 활용하면 얼마나 빠를까요? wrapping 함수 하나면 활용할 수 있을만큼 간단합니다. 지금 free-plan으로 활용이 가능하니 이참에 한번 시도해보시는건 어떨까요?]
Scalable Spatio-temporal Graph Neural Networks
[https://arxiv.org/pdf/2209.06520.pdf]
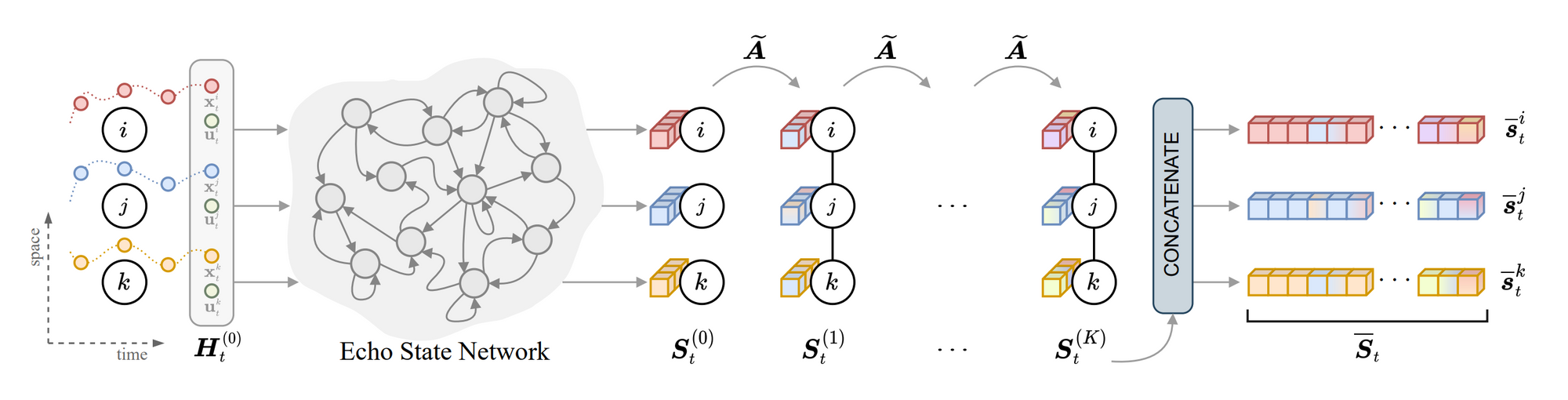
Introduction
static graph 와 다르게 spatio-temporal는 시간이 변해감에 따라 feature 이 어떻게 변해가는지를 추가로 관리하고 예측해야하기에 task 측면에서 더욱 어렵다고 볼 수 있습니다. 당연하게도 연산량 , 발생하는 정보들 또한 최소 static graph manner 보다는 많겠죠. 본 논문에서는 그러한 요소들을 효율적으로 관리하기 위해 Echo State Network 개념을 도입해서 pre-compute 를 한 뒤, task 를 수행합니다.
Preliminaries
[본문 읽을 때 도움이 될 내용을 적어두었기에, Summary만 보신다면 스킵하셔도 무방합니다.]
An Echo State Network is a type of recurrent neural network that uses a reservoir of interconnected neurons with fixed, randomly assigned weights. The reservoir is designed to have certain desirable dynamical properties, such as a large range of possible states, and the ability to quickly and easily converge to a new state in response to an input signal.
One key advantage of ESNs is that the training process is relatively simple and fast, since only the readout layer, which maps the reservoir state to the output, needs to be trained using supervised learning. This is in contrast to traditional recurrent neural networks, which require training of the entire network, including the recurrent weights.
To create the reservoir, we randomly assign fixed weights to the connections between the neurons. These weights are typically drawn from a Gaussian distribution with zero mean and a small variance. We then choose an activation function for the neurons, such as the sigmoid or hyperbolic tangent function, and simulate the dynamics of the reservoir using a recurrent equation, such as the following
Summary
Echo State Network 본 논문을 보며 처음볼만큼 생소한 개념이였습니다. 왜 그간 딥러닝 책에서 한번도 마주치지 못했는지, 아직도 공부할게 많구나 아직 우물안개구리 라는 생각이 들었던 순간이네요. 간단히 말씀드려보자면, reservior layer 에 temporal state 가 담긴 뉴런들을 셋팅해주고, 노드들을 해당 뉴런에 각각 대입합니다. 이렇게 설정된 Entire network 에 randomized weight 를 부여합니다. 이후 Readout 을 통해 해당 signal 중 유의한 weight 들만을 추출합니다.
그럼 여기서 잠시, ‘유의한 weight’란 무엇일까 라는 생각이 드실텐데요. 특이하게도 Echo State Network 는 training 시 initalizied weight 를 fix 해두고, readout layer 에서 유의값을 추출합니다. 그 과정은 다음과 같습니다. reservoir 에서 나온 state 값(fixed random intialized value) , node temporal 값을 concat 하여 target 값과 비교하는거죠.
이렇게되면 결국 동일한 nosie(reservoir)를 두고, 노드의 상태(t)들이 지속적으로 변하며 어떤 노드들이 유의미한 노드들인지를 필터링할 수 있습니다. 이 방식이 다른 RNN계열(LSTM,GPU) 대비 연산효율적인 이유는 바로 gated update function 에서 소요되는 리소스가 적다는 점입니다. 단순하게 noise filter 여과 기능을 가진 reservoir 만 잘 셋팅이 된다면 앞서 언급한 function을 생략하게 되므로, 속도측면에서 훨씬 빠릅니다.
Insight
기존에 알고있던 RNN 계열과 다르게 node update 가 아닌 entire node(network)를 한번에 주입해서 유용한 weight를 추출한다는 개념이 되게 신기했습니다. 논문 끝자락에 저자가 말했듯이, temporal graph 측면에서 가장 큰 한계였던 scalability를 ESN(echo state network) 관점을 다양한 관점으로 도입할 수 있음을 시사합니다. temporal 관점이 중요한 Real-time inference 추천시스템과 같은 부분에서도 접목할 부분이 많아보이네요.
접목할 부분이 많다는 측면에서 ESN 개념을 공부하기에 유용한 supplement 를 추가해 놓겠습니다.
Supplement for ESN
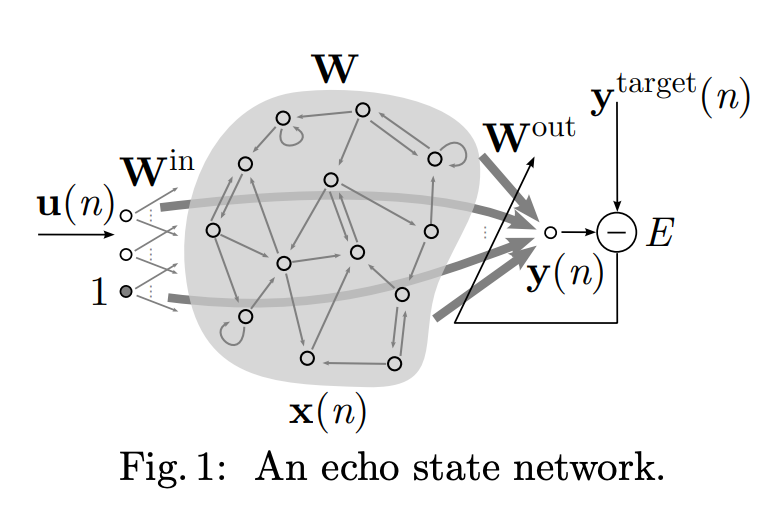
A Practical Guide to Applying Echo State Networks
1.generate a large random reservoir RNN (W^in, W, \alpha) 2.run it using the training input u(n) and collect the corresponding reservoir activation states x(n);
- compute the linear readout weights W^out from the reservoir using linear regression, minimizing MSE between y(n) and y^target(n);
- use the trained network on new input data u(n) computing y(n) by employing the trained output weights W^out.
Reservoir concept[https://en.wikipedia.org/wiki/Reservoir_computing]
Practical guide to applying ESN[https://www.ai.rug.nl/minds/uploads/PracticalESN.pdf]
Graph Neural Networks Designed for Different Graph Types: A Survey
[https://openreview.net/pdf?id=h4BYtZ79uy]
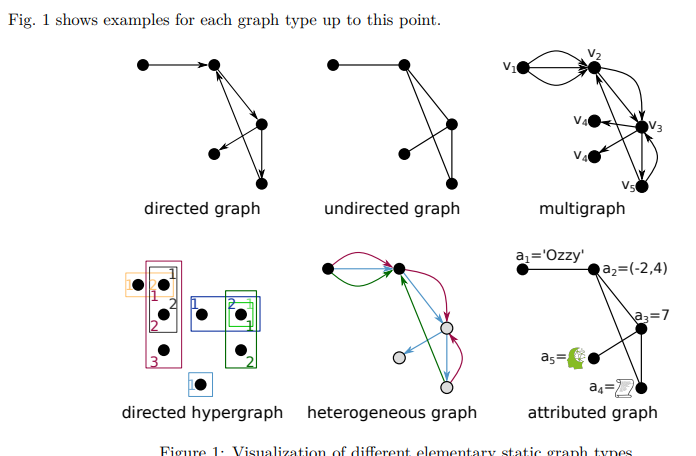
GNN , Graph data를 연계하여 연구하실 분들에게 꼭 추천드리고 싶은 서베이 논문입니다. 시간이 지날수록 GNN , Graph data에 대해 체계적으로 작성하는 게 추세라고 생각될 만큼 양질의 자료들이 우리 주변을 맴돌고 있는데요.
그 양질의 자료들 중에서도 단연 독보적인 논문이라고 생각되는 자료입니다. 군더더기 없이 1. 그래프 데이터 개요부터 시작해서 2. GNN에 대한 개요, 3. 각 그래프 카테고리마다 적용할 시나리오 4. 그래프 데이터에 걸맞은 GNN 모델 모든 게 체계적으로 정리되어 있습니다. 특히, Graph Model Problem Data category 4가지 필수적인 요소들만 잘 간추려놓은 테이블을 보고 이번 주 오마카세에 꼭 실어야겠다.라는 마음이 들었네요.
무조건이란 표현을 많이 자제하는데, 본 논문은 GNN, Graph data 연구 개요를 잡거나 Graph recap에 관심 있는 분들에게 무조건 도움이 되리라고 생각되네요.
Higher order assortativity for directed weighted networks and Markov chains
[https://arxiv.org/pdf/2304.01737.pdf]
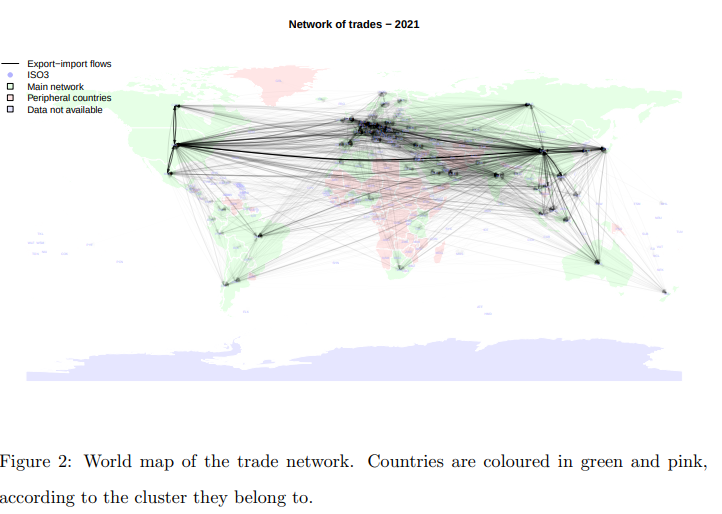
Introduction
공급사슬망(Supply Chain Management) 에서 자주 활용되는 개념이죠. higher order graph(hypergraph) 로 가정한 상황(trade network)에서 어떤 식으로 assortativity 를 측정하는지에 대해 이야기한 논문입니다.
higher order & direct , weighted network 상황에서 assortativity 측정 지표가 부재한 상황에 대해 문제를 제기하며, 그 부재를 채우기 위해 새로운 assortativity 를 제안합니다. 여기에서, assortativity 란 그래프 특성을 측정하는 지표 중 하나로써 연결 관계가 많은 노드끼리 연결이 되어있는지 반면에 없는 노드는 없는 노드끼리 연결이 되어있는지를 파악하기 위해 주로 사용됩니다.
그럼 higher order , directed weighted , assortativity 가 어떻게 조화를 이루며, 어디에서 활용할 수 있을까라는 의문이 드실 텐데요. 이를 무역 네트워크에 접목해 이야기해 보자면 다음과 같습니다.
- higher order는 시간이 흐름에 따라 국가 간 관계가 어떻게 바뀌었는지 표현할 때
- directed는 국가 간 수/출입과 같은 능동 수동과 같은 관계를 표현할 때
- weighted는 얼마나? 수출입 했는지에 대한 숫자를 weight로 표현할 때
- assortativity는 수출입 관계가 많았던 노드들이 시간이 흐름에 따라 지속적으로 관계가 많았는지 표현할 때
그럼 다시 처음으로 돌아가서, higher order , directed , weighted라는 요소들은 많이 활용되고 있었으나 언급한 3가지 요소들을 결합했을 때, 어떤 식으로 assortativity를 측정할지에 대한 지표가 없었기에, 논문 저자는 assortativity를 측정하기 위한 지표를 제안합니다. 그뿐만 아니라, 실제 4가지 요소를 무역 네트워크에 도입했을 때, 도출되는 지표에 따라 어떤 해석을 할 수 있는지에 대해서도 이야기합니다.
Preliminiaries
[본문 읽을 때 도움이 될 내용을 적어두었기에, Summary만 보신다면 스킵 하셔도 무방합니다.]
노드 간 다른 관계를 표현한다는 점에서 이종 그래프(heterogeneous-graph)와 유사하다고 생각이 드실 수 있는데요. 실제로 이종 그래프와 하이퍼 그래프를 다른 그래프로 구분합니다. 다른 관계를 표현한다는 의미에서 유사한 기능과 맥락을 지니고 있는데 다르게 구분하는 이유는 무엇일까요? 차이점은 다음과 같습니다.
higher-order graph는 노드 간 다차원 관계를 표현하는데 집중하기 위해 그래프 데이터를 incidence matrix로 표현하며, 다차원 관계를 hyperedge라고 명명하며 관리 및 분석합니다. 반면에, heterogeneous graph는 노드, 에지 각각의 다양성을 표현하기 위해 entity , relationship를 각각 adjacency matrix 형태로 표현하여 관리 및 분석합니다.자세한 내용은 위키피디아 를 참조하시는걸 추천드립니다.
Summary
직관적이고 간단한 방식으로 assortativity를 측정합니다. directed 특성을 2가지 in 과 out으로 구분 지어 그래프로 표현한다면 관계 각각마다의 경우의 수를 종합해 보면 out-in , in-out , in-in , out-out 4가지를 고려할 수 있습니다. 이를 정량화하여 pearson correlation를 측정하여 나온 결과를 higher-order assortativity 라 제안합니다.
Insight
실제 수요 공급 관리 측면에서 수출입에 대한 비중을 모니터링하는 개념이 향후 기업 전략을 좌지우지할 만큼 굉장히 중요한 요소이기에, 기업 측에서도 굉장히 관심이 많은 분야입니다. 예를 들어, 특정 업체(국가)로부터 생산재를 입고 받기로 했는데 돌발 상황이 발생하여 기존 생산재 수입에 차질이 발생했을 때, 최종생산물 과정에서부터 소비자 전달까지 기간이 딜레이 되기 때문에 단기적으로는 생산라인 정지, 장기적으로는 기업 신뢰도 감소까지 발생하기에 민감한 부분이라고 볼 수 있겠습니다. 이를 그래프로 표현한다면 ‘수출’, ‘수입’이라는 간단한 관계로 표현하여, 그 전체 흐름을 파악할 때 직관적이라는 면에서 용이하고, 효율적인 수급 계획을 세우기에 좋다는 측면에서 많이 활용되고 있습니다. 본 논문을 보며 앞서 언급 드린 이야기를 어떻게 접근하지?라는 호기심에 기반하여 보시면 좋을 것 같네요.
Getting started with PyTorch Geometric (PyG) on Graphcore IPUs
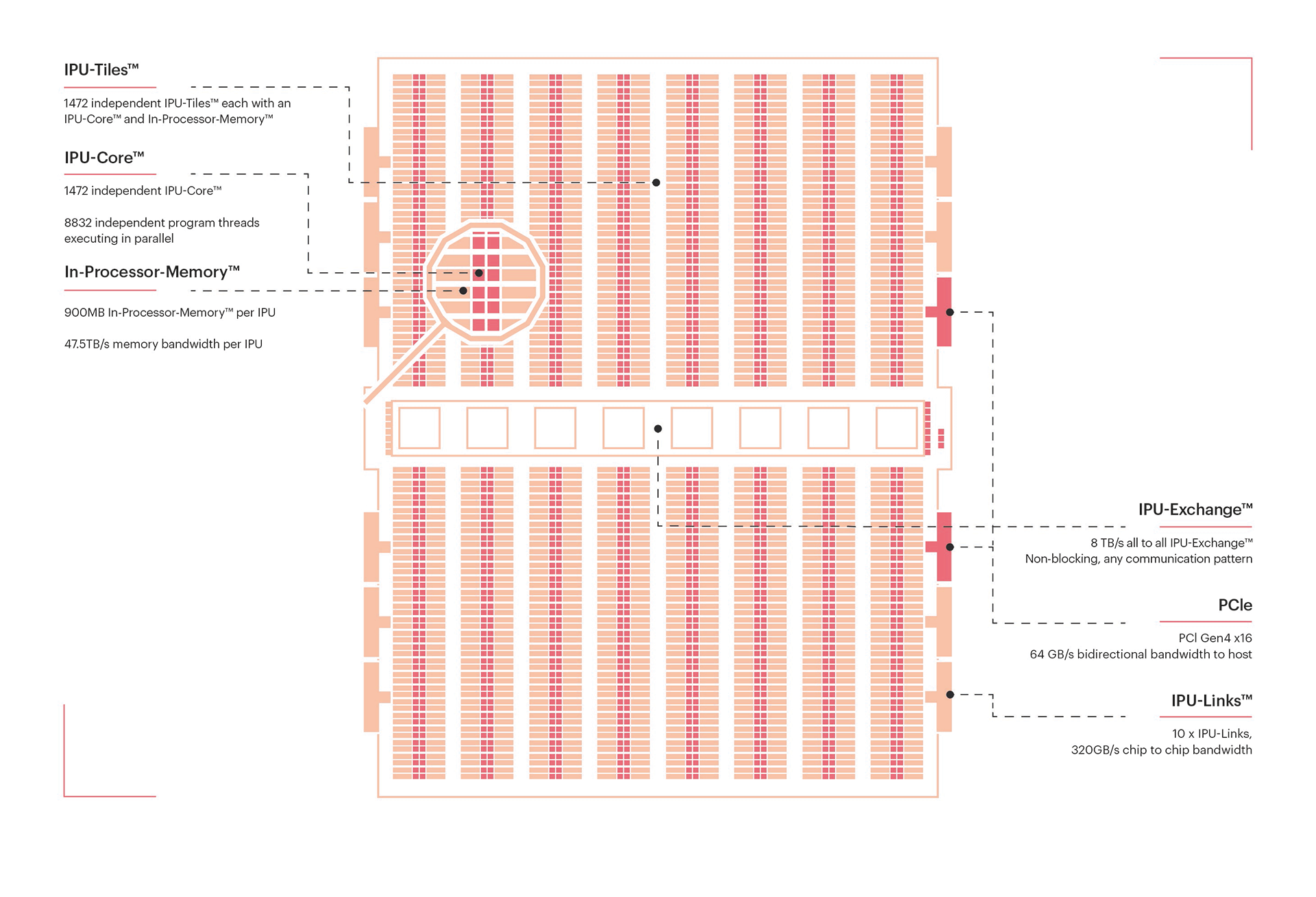
https://www.graphcore.ai/products/ipu
Introduction
Large Language Model 과 같은 대용량 모델이 대세가 되면서 pre-trained model weight를 기반으로 본인의 모델에 어떻게 모델에 적용할 수 있을까라는 고민이 많이 보이곤 합니다. 다양한 종류의 대용량 데이터를 학습했기에 당연하게도 성능이 좋을 수밖에 없을 거란 생각이 듭니다. 하지만, 대용량 모델의 가중치조차 리소스 제한 때문에 적용하기에 제한이 발생할 상황 또한 종종 존재하는데요. 그 상황에서 주로 2가지 선택지를 마주하게 됩니다.
1.데이터 엔지니어링 최적화 2. 리소스 추가, 1번과 같은 경우는 비용이 적으나 진입장벽이 높다는 점이 주요 특징입니다. 모델 최적화 이외에도 데이터에 대한 근본적인 이해부터 시작해서 공부해야 할 요소들이 많기에 다소 부담이 크기 마련입니다. 반면, 2번은 비용이 많이 드나, 진입장벽이 낮다는 점을 특징으로 생각할 수 있습니다.
그렇다면, 리소스 (TPU, GPU)를 활용할 수 있는 플랫폼을 찾아본다면 TFRC , Kaggle, Colab 과 같은 공간이 대표적인데요. 이마저도 세션이 자주 끊기거나, 메모리가 너무 적다 등의 문제를 내포하고 있습니다. 그렇다면, 여기에서 다른 선택지는 없을까요? 이때 생각해 볼 요소가 하나 더 추가되었습니다. 바로 IPU입니다.
Preliminiaries
- CPU (Central Processing Unit): It is the main processor in a computer system that carries out the instructions of a computer program. It performs general-purpose computing tasks such as arithmetic and logic operations, data movement, and control flow.
- GPU (Graphics Processing Unit): It is a specialized processor designed to handle the complex mathematical and graphical computations required for rendering images and videos. GPUs are often used in high-performance computing applications such as gaming, scientific simulations, and machine learning.
- TPU (Tensor Processing Unit): It is a custom-built ASIC (Application-Specific Integrated Circuit) designed by Google specifically for machine learning tasks. TPUs are optimized for processing tensor operations and are typically used for training and inference in deep learning models.
- IPU (Intelligence Processing Unit): It is a specialized processor designed for artificial intelligence and machine learning tasks. IPUs are optimized for performing large-scale parallel computations on neural networks and are typically used for training and inference in deep learning models.
Summary
GPU를 사용했던 것과 굉장히 유사합니다. 동일하게 torch_geometric에서 레이어 구조를 가져와서 활용합니다. 다만, training 전 poptorch library로 한번 wrapping 을 해준다는 점이 눈에 띄는 차이점이라고 할 수 있습니다. 이외에는 눈에 띄게 다른 점은 없습니다. 굉장히 간단하게 IPU라는 고성능 자원을 활용해 볼 수 있는 거죠.
추가적으로 molecular GNN에서 한 획을 긋고 있는 GPS++ 모델 또한 IPU를 활용해서 연구가 진행되었는데요. 그 진행된 코드를 https://www.graphcore.ai/ipu-jupyter-notebooks 에서 동일하게 사용할 수 있다고 하네요. 제한된 자원으로 연구하는 분들에게 도움이 되길 바라는 마음에서 공유드리는 콘텐츠입니다. 많은 도움이 되었으면 하네요.