2월 4주차 그래프 오마카세

Breaking the Limit of Graph Neural Networks by Improving the Assortativity of Graphs with Local Mixing Patterns
[https://arxiv.org/pdf/2106.06586.pdf]
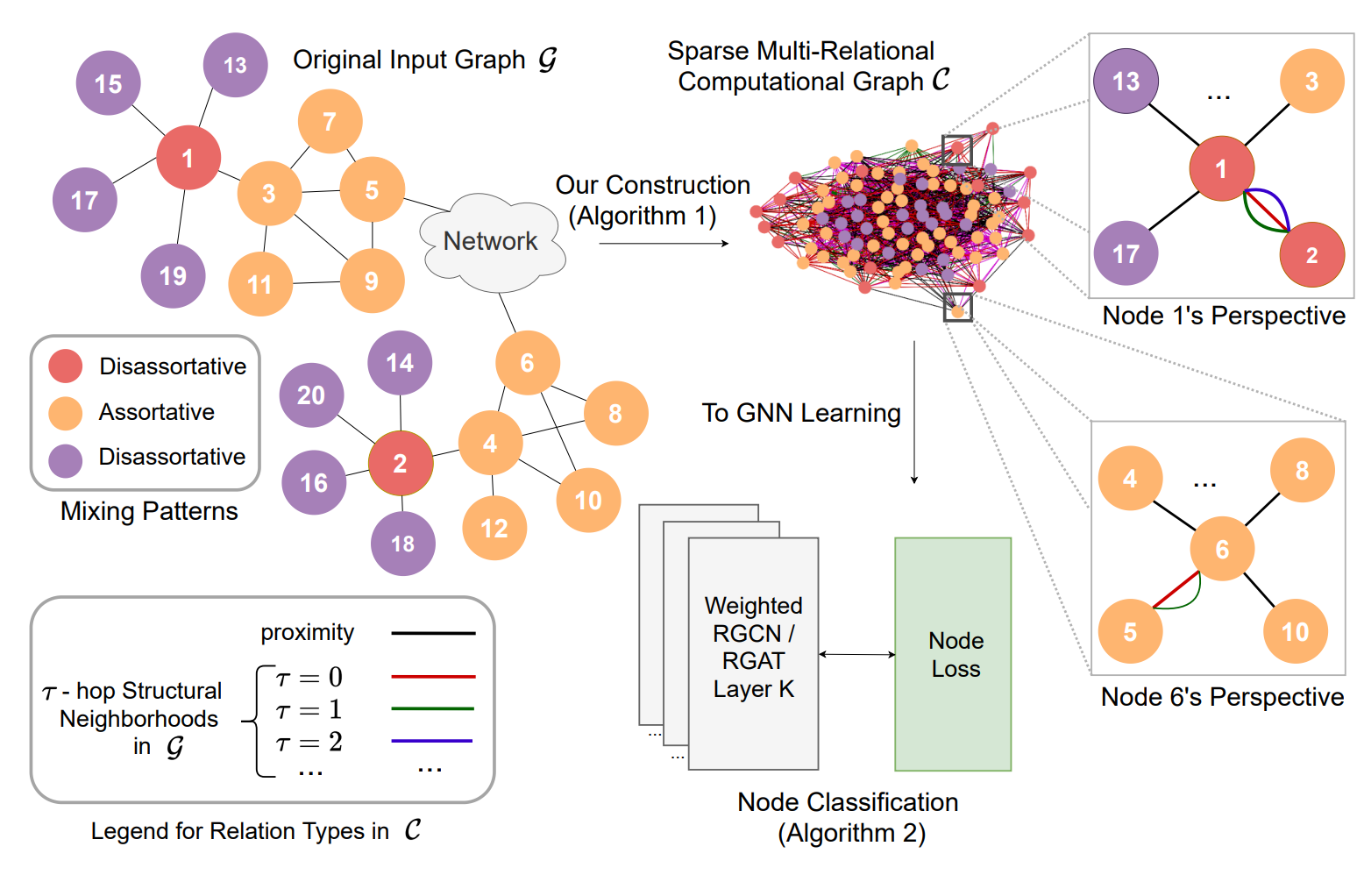
- 오늘 소개해 드릴 네트워크 지식은 동질성(Assortativity)입니다. 먼저 그 정의부터 말씀 드리면 다음과 같습니다. 동질성은 네트워크 내의 노드가 어떤 방식으로든 서로 비슷한 노드에 연결되는 경향을 나타냅니다. 이는 네트워크 내에서 서로 연결된 노드의 차수 간 상관 관계를 계산함으로써 측정할 수 있습니다. 예를 들면, 동질성이 높은 네트워크에서는 많은 연결을 가진 노드는 같은 수준의 연결을 가진 다른 노드와 연결되고, 적은 연결을 가진 노드는 다른 적은 연결을 가진 노드와 연결되는 경향을 정량화 한다고 보시면 됩니다.
- 그렇다면 이 특성을 어떻게 활용할까요?라는 의문이 드실 텐데요. 그 해답은 바로 computation graph입니다. 동질성을 통해 비슷한 구조를 가진 노드들에게 strong weight, 비슷하지 않은 구조를 가진 노드들에게 weak weight를 적용하기 위해 새로운 computation graph를 만들어 주고, 그 graph를 embedding 해줍니다.
- 실험이 굉장히 흥미 롭습니다. 각기 다른 domain의 그래프 데이터로부터 distribution을 추출하고, local/global assortativity를 측정하여, 그래프마다의 structure and proximity를 비교합니다. 간단히 말씀드리면 도메인이 다를지라도 비슷한 동질성을 가진 네트워크가 존재하며, global assortativity mean 값이 0에 근접할수록, 그래프 패턴의 diverse 가 적을수록 node classification task에서 성능이 좋음을 이야기합니다.
- data-centric 관점에서 잘 풀어 놓은 논문입니다. 다 읽어보고 나시면 graph embedding model이 아닌 graph pattern, graph distribution 그리고 graph modeling이 얼마나 중요한지에 대해 체감하시게 될 거라 생각됩니다. 여기에는 언급하지 않았지만, GNN vs. local assortativity라는 섹션에서 모델 vs. 데이터 관점에서 접근한 굉장히 흥미로운 부분도 존재합니다.
- GNN도 좋지만, 학습하는 데이터에 대한 중요성 garbage in, garbage out을 다시 한 번 깨닫게 하는 논문이라 생각됩니다.
Today's network knowledge that I would like to introduce is Assortativity. First, let me explain its definition. Assortativity refers to the tendency of nodes in a network to be connected to similar nodes in some way. This can be measured by calculating the correlation between the degrees of connected nodes in the network. For example, in a network with high assortativity, nodes with many connections tend to be connected to other nodes with similar levels of connectivity, while nodes with few connections tend to be connected to other nodes with few connections.
So how can we make use of this feature? The answer lies in the computation graph. By applying strong weights to nodes with similar structures and weak weights to nodes with dissimilar structures through assortativity, we create a new computation graph and embed it.
The experiment is very interesting. From graph data of different domains, we extract distributions and measure local/global assortativity to compare the structure and proximity of each graph. Simply put, even if the domains are different, there exist networks with similar assortativity, and as the global assortativity mean value approaches 0 and the diversity of graph patterns decreases, the performance in node classification tasks improves.
This is a well-written paper from a data-centric perspective. After reading it, I believe you will realize how important graph patterns, graph distributions, and graph modeling are, not just graph embedding models. Although not mentioned here, there is also a very interesting section on GNN vs. local assortativity, where the paper approaches the issue from both a model and data perspective.
GNNs are great, but this paper serves as a reminder of the importance of the data we train them on: garbage in, garbage out.
GraphPrompt: Unifying Pre-Training and Downstream Tasks for Graph Neural Networks
[https://arxiv.org/pdf/2302.08043.pdf]
- 논문에서도 마찬가지로 흐름을 잘 읽고 빠르게 구현으로 옮기는 실행력이 굉장히 중요합니다. chatGPT 붐으로 인해 프롬프트 엔지니어링이 이전 대비 굉장한 관심을 받고 있는 추세인 가운데 그래프 분야에서도 프롬프트 엔지니어링 스킬을 적용한 논문이 등장했습니다. Pre-training weight를 활용하기 위한 스킬인 fine-tuning 이 자연어 처리 분야에서는 잘 작동하나, 그래프 분야에서는 만족할만한 성능을 이끌어내지 못했음을 한계점으로 언급하며 prompt 컨셉을 제시합니다.
- 잠시 프롬프트 엔지니어링과 파인튜닝의 차이점에 대해 말씀드리자면, 둘 다 사전학습(pre-trained)된 모델을 잘 활용해보겠다는 목적은 동일합니다. 파인튜닝은 사전모델 가중치 기반 특정 task 에 일반화하는 콘셉이라면, 프롬프트 엔지니어링은 특정 task 과 관련된 패턴을 더욱 강조해줍니다. 라고 보시면 되겠습니다. 다만 이때, 강조를 위해 주로 hand-craft 등의 공수가 추가로 투입되긴 합니다..!
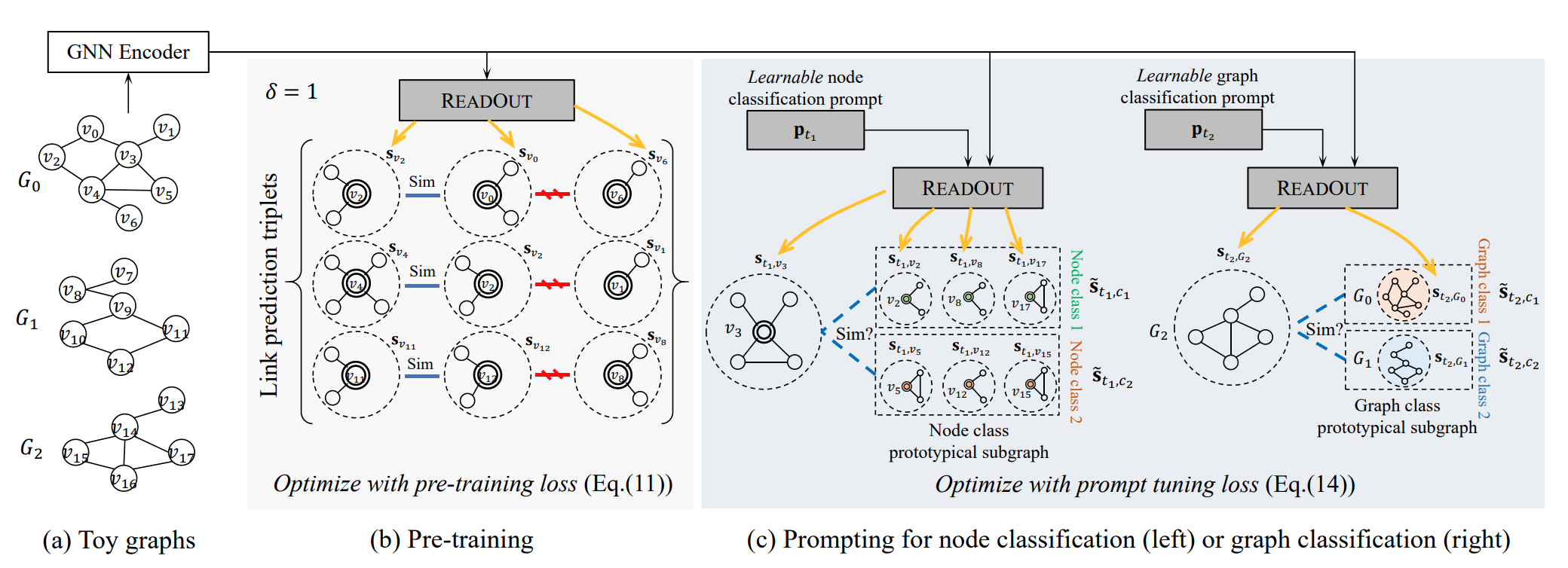
- 소개시켜드릴 논문에서는 사전학습, 프롬프트 엔지니어링이 결국 핵심입니다. 먼저 사전학습 stage에서는 노드 간 link prediction task 를 진행하여 비슷한 노드쌍은 높은 유사도가 나오게 설정하고, 비슷하지 않은 노드 쌍은 낮은 유사도가 나오게 대량의 그래프를 학습시킵니다. 결국 link prediction 으로 학습된 node weight값들이 graph에 반영이 되어있고, 이 때 프롬프트 엔지니어링을 활용하여 특정 패턴에 강조하여 학습한다고 보시면 되겠습니다.
- 프롬프트 엔지니어링이라 해서 되게 어렵게 보일 수도 있겠지만 간단합니다. 특정 노드 중심의 네트워크(ego-network)를 추출하여 값을 종합(readout)해줍니다. 그렇다면 특정 그래프의 종합 값 vector가 나오겠죠? 이 때, 사전학습된 종합값과 새로운 패턴을 학습시킬 종합값의 유사도를 비교하며 학습시켜주신다고 보시면 되겠습니다. 예) A vector 와 1로 라벨링된 패턴의 vector 값의 유사도, A vector 와 2로 라벨링된 패턴 vector 유사도 ...
- link, node, graph task 를 모두 활용한 논문이라 볼 수 있겠습니다. 요약해보자면, 노드간의 유사도를 기반으로 사전학습된 parameter 는 freeze 하고, node & graph classification 때 readout 을 활용해서 prompt tuning 해주는 방식입니다.
- 그래프 분야에서 pretraining 이란 MPNN 모델 기반으로 모든 노드 링크 그래프 3가지 방식을 모두 학습해주는 방식이 정석처럼 여겨지곤 했었는데요. 여기에서도 노드 링크 그래프 structure wise 라는 관점을 동일하나, pattern specific 을 위해 vector similarity 를 활용한 아이디어가 참신하다고 생각되는 논문입니다.
As in papers, it is very important to read the flow well and quickly move it to implementation with execution skills. Prompt engineering is receiving a lot of attention compared to before in the graph field, as chatGPT has created a boom. In this trend, a paper applying prompt engineering skills in the graph field has emerged. Fine-tuning, a skill for utilizing pre-training weights, works well in natural language processing, but mentions its limitations in the graph field for not producing satisfactory performance and proposes the prompt concept.
To briefly explain the difference between prompt engineering and fine-tuning, both have the same goal of utilizing pre-trained models effectively. While fine-tuning is a concept of generalizing to a specific task based on pre-trained model weights, prompt engineering emphasizes patterns related to specific tasks. However, hand-crafting work is mainly added to emphasize.
In the paper being introduced, pre-training and prompt engineering are ultimately the key. First, in the pre-training stage, a link prediction task between nodes is conducted to set similar node pairs to have high similarity and dissimilar node pairs to have low similarity, and a large number of graphs are trained. Eventually, node weight values learned through link prediction are reflected in the graph, and prompt engineering is utilized to emphasize specific patterns during learning.
Prompt engineering may seem difficult, but it is simple. It extracts the ego-network centered around a specific node and aggregates the values. Then, the vector value of the comprehensive value of a specific graph is obtained. At this point, it compares the similarity between the pre-trained comprehensive value and the comprehensive value to be trained with a new pattern and trains it. For example, the similarity between vector A and the vector value labeled as 1, and the similarity between vector A and the vector value labeled as 2...
This paper can be regarded as using all link, node, and graph tasks. In summary, the pre-trained parameters are frozen based on the similarity between nodes, and the readout is used to prompt tuning during node and graph classification.
In the graph field, pre-training is considered the norm, which trains all node-link graphs using the MPNN model-based method. Here, the perspective of structure-wise node-link graphs is the same, but the idea of utilizing vector similarity for pattern specific purposes is considered innovative.
Simplifying Subgraph Representation Learning for Scalable Link Prediction
[https://arxiv.org/pdf/2301.12562.pdf]
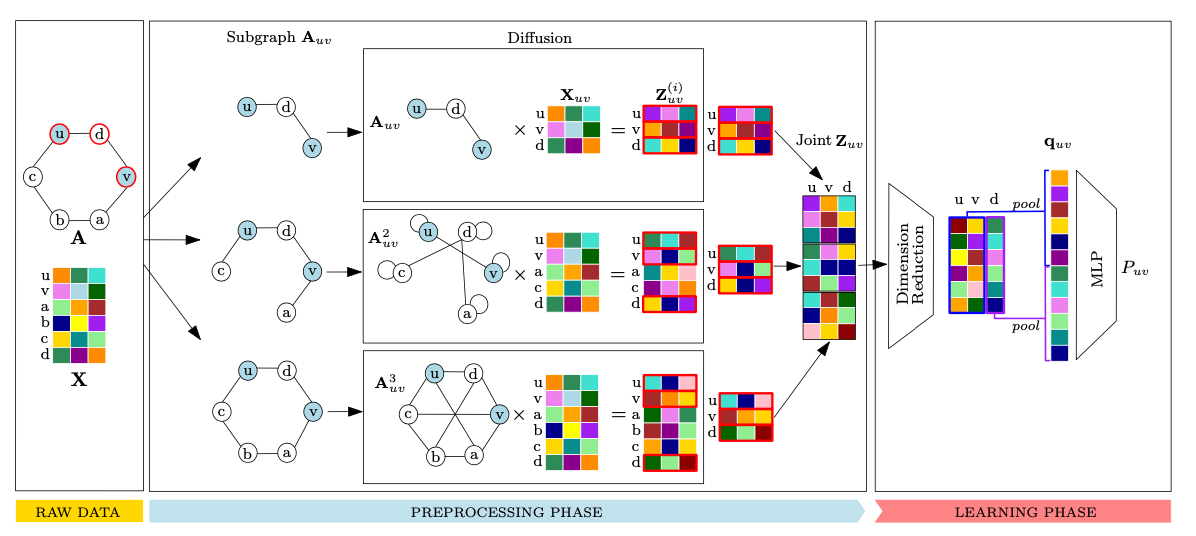
- 링크 예측 작업에서 발생하는 확장성 문제를 해결하기 위해, 서브그래프 및 확산 연산자를 활용합니다. 서브그래프 추출을 통해 예측할 링크가 서브그래프에 존재하는지, 존재하지 않는지 그리고 존재한다면 근처 k-hop과 교류(diffusion)가 발생할 때, 임베딩 값이 어떻게 변화되는지를 중점적으로 확인합니다.
- 임베딩 값의 변화 이후 차원 축소 단계에서는 SGN의 기술을 차용합니다. 비선형 함수는 비용이 많이 들기 때문에 로지스틱이나 소프트맥스 함수로 대체합니다. 이렇게 하면, 선행 계산 임베드 값을 활용할 수 있으므로 비용이 줄어들고 훈련 속도가 빨라집니다. (lightGCN에서 비선형 함수를 제거한 것과 동일한 개념입니다.)
- 최종적으로 서브 그래프와 확산을 통해 도출된 임베딩 값을 풀링을 통해 종합하고 최종값을 MLP에 투입합니다. 메시지 패싱을 확산 연산자로 대체한다는 관점에서 매우 흥미로웠던 논문이었으며, 또한 샘플링 전략에서 PoS(power of subgraph)와 SoP(subgraph of power)를 언급하며 각각의 차이와 장단점에 대해 언급한 부분도 흥미로웠습니다.
To address scalability issues in link prediction tasks, subgraphs and diffusion operators are utilized. Through subgraph extraction, the focus is on confirming if the link to be predicted exists in the subgraph, whether it doesn't exist, and if it does, how the embedding values change when a nearby k-hop and interaction (diffusion) occur. After the change in embedding values, SGN technology is adopted during the dimension reduction phase. Non-linear functions are replaced with logistic or softmax functions due to high costs. This reduces costs and increases training speed as precomputed embed values can be utilized. This is the same concept as removing non-linear functions in lightGCN. Finally, the embedding values derived through subgraphs and diffusion are pooled, and the final value is input to MLP. The paper was interesting from the perspective of replacing message passing with diffusion operators, and also mentioning PoS (power of subgraph) and SoP (subgraph of power) in the sampling strategy and discussing the differences and pros and cons of each.
LINE: Large-scale Information Network Embedding
[https://arxiv.org/pdf/1503.03578.pdf]
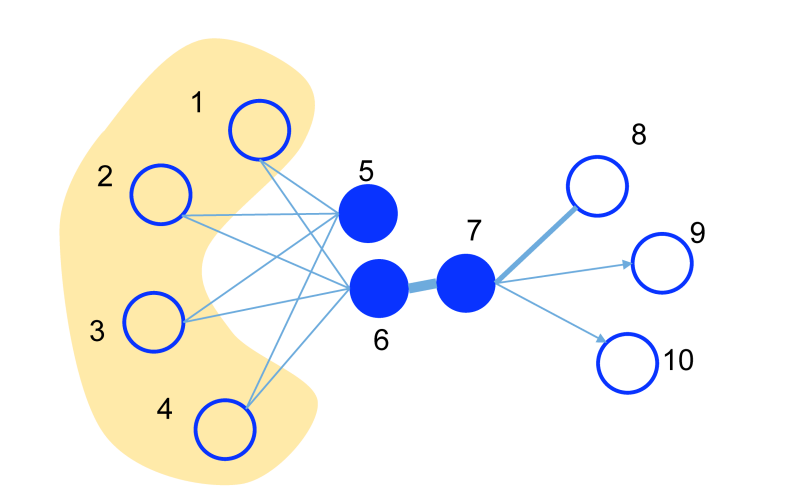
대표적인 large-scale graph embedding 기술인 LINE은 네트워크 내에서 직접적으로 연결되어 있는 노드뿐만 아니라, 공통 이웃을 가지고 있는 간접연결 노드들의 구조적 특성을 모두 임베딩에 담고자 시도한 논문입니다. 논문에서 First-order와 second-order라는 단어를 통해 기술들을 설명합니다.
2015년도에 나온 이 방법론은 대략 8년이 지난 지금에도 recsys 산업분야 종사자들에게 많이 애용되고 있습니다. static 뿐만 아니라 dynamic embedding competition에서 필수로 사용되는 graph 계의 XGBoost로 보아도 좋을 것입니다! 최근 활용 예시로는, WWW2023 recommender competition에서 LINE을 baseline으로 활용한 케이스가 있습니다.
이 논문에서 second-order에서 negative sampling을 적용해서 model optimization까지 어떻게 이루어지는지를 살펴보는 것이 흥미로울 것입니다. optimization시에는 asynchronous stochastic gradient algorithm을 활용하는데, 이때 continuous weight → discrete weight로 전환하는 방식이 굉장히 흥미롭습니다.
LINE, a representative large-scale graph embedding technique, attempts to capture the structural properties of not only directly connected nodes but also indirectly connected nodes with common neighbors within the network. The paper describes the techniques using the words First-order and Second-order.
This methodology, which was introduced in 2015, is still widely used by recsys industry professionals even after about 8 years. As evidenced by the use of XGBoost in graph-based static and dynamic embedding competitions! As a recent example of its use, there is a case of utilizing LINE as a baseline in the WWW2023 recommender competition.
In this paper, it would be interesting to examine how model optimization is carried out by applying negative sampling to Second-order. Asynchronous stochastic gradient algorithm is utilized during optimization, and the method of switching from continuous weight to discrete weight is particularly interesting.