5월 4주차 그래프 오마카세


A Generalization of Transformer Networks to Graphs
[https://arxiv.org/pdf/2012.09699.pdf]
Introduction
Transformer 의 야성은 어디까지일까요. 가늠하기가 힘드네요. 모든 데이터에서 dominant 한 모델 Transformer, 본 논문에서는 Transformer 구조를 graph 에 활용하기 위한 extended version 을 제안합니다.
** 본 논문은 'CS6208’ 수업을 진행하시는 Xavier Bresson 교수님께서 publish 한 논문입니다. transformer 그리고 graph 조합을 공부하고 싶으신 분들은 링크의 자료가 유익할거라 생각되네요.
Preliminary
NLP transformer vs. Graph transformer
The Transformer architecture has been successfully applied to both graph and natural language processing (NLP) tasks, but there are some differences in their applications. Here's a comparison:
- Input Representation:
- Graph: In graph applications, the input typically consists of a graph structure, represented as nodes and edges, along with their associated features. Nodes can have attributes, and edges can have weights or labels.
- NLP: In NLP applications, the input usually consists of sequential data, such as sentences or documents, represented as sequences of tokens. Each token may have an associated embedding or encoding.
- Attention Mechanism:
- Graph: Graph-based Transformers employ attention mechanisms to capture relationships between nodes in a graph. Attention weights are computed based on the similarity or relevance between nodes, allowing the model to attend to different parts of the graph during processing.
- NLP: NLP Transformers also use attention mechanisms, but they primarily focus on capturing dependencies and relationships between words or tokens in a sentence or document. Self-attention allows the model to attend to different words at different positions, capturing contextual information.
- Task-Specific Layers:
- Graph: Graph-based Transformers often include additional layers or modules designed specifically for graph-related tasks, such as graph convolutional layers or graph pooling operations. These layers help to incorporate graph structure and leverage it for various tasks like node classification, graph generation, or link prediction.
- NLP: NLP Transformers typically include task-specific layers like classification or regression heads on top of the Transformer backbone. These layers are responsible for mapping the learned representations to specific output tasks such as sentiment analysis, machine translation, or question answering.
- Output Interpretation:
- Graph: In graph applications, the output of a graph-based Transformer can vary depending on the task. It could involve node-level predictions, graph-level predictions, or even graph structure modifications.
- NLP: In NLP applications, the output of an NLP Transformer is often focused on tasks like text classification, language modeling, machine translation, or named entity recognition, which typically involve generating predictions or generating text.
Summary
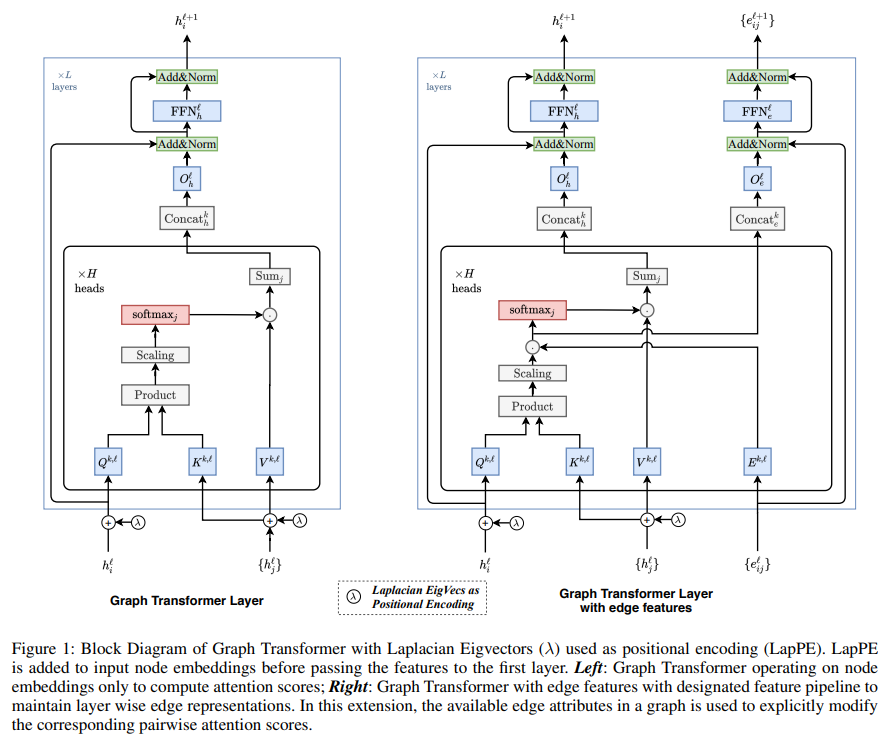
Extend version 특징 중 하나로써, edge feature 을 적용할 수 있는 layer를 제안합니다. graph 의 가장 큰 장점인 Relation design 을 graph transformer 에 적용할 수 있다는 점을 어필하네요. 기존에는 attention 을 통해 도출된 결과물이 dominant 하게 paramter 를 업데이트 했는데, 본 extended version 에서는 그 attention 의 개입을 그래프에 더 적절하게 변형하고자 하는 의도가 보이네요.
isomoprhism issue 를 완화하기 위해 자주 적용하는 기술입니다. positional encoding. 그 관점에 따라 성능이 어떻게 바뀌는지 , 기존 positional encoding(NLP)와 비교 해석이 굉장히 흥미롭습니다. 심플하게 LapPE 를 first layer에 태우기 전 node feature 에 적용해주고 안해주고에 따라 성능, 한 번 확인해보시는걸 추천드립니다.
Insight
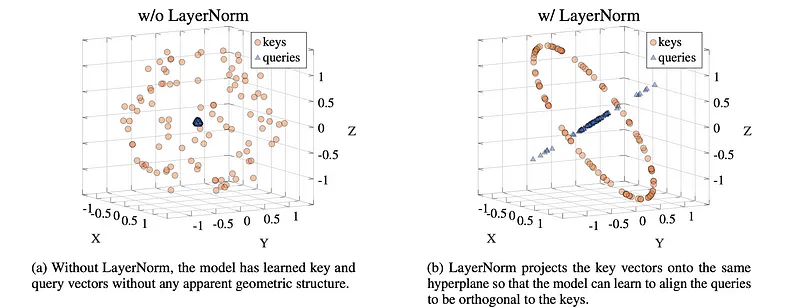
What LayerNorm really does for Attention in Transformers
Blog : [https://lessw.medium.com/what-layernorm-really-does-for-attention-in-transformers-4901ea6d890e]
On the Expressivity Role of LayerNorm in Transformers' Attention
Paper : [https://arxiv.org/abs/2305.02582]
논문에선 batch normalization 이 layer normalization 보다 성능이 좋다 라고 주장한 결과와 상반된 결과를 보이는 자료입니다. Future work 로 적용할 만한 아이디어들이 많아보여서 독자분들과 공유하면 좋겠다 싶어 이번주 오마카세 반찬으로 담아보았습니다.
Smallworldness in Hypergraphs
[https://arxiv.org/abs/2304.08904]
Introduction
유명한 실험이죠. small world experiment, '서로 전혀 모르는 사람을 친구로 두고 있을 확률은 얼마나 될까?’ 라는 호기심을 시작으로 6단계를 거치게 된다면 처음 지정한 모르는 사람에게 정보가 전달된다는 사실을 실험으로 보여줬습니다. 그 이후에도 몇몇 이론들이 지금까지도 발전되며 기여하고 있으나, 본 논문은 이 이론들 모두 small world & pair-wise 한 상황에만 가정되어있다는 점을 한계점으로 지적합니다.
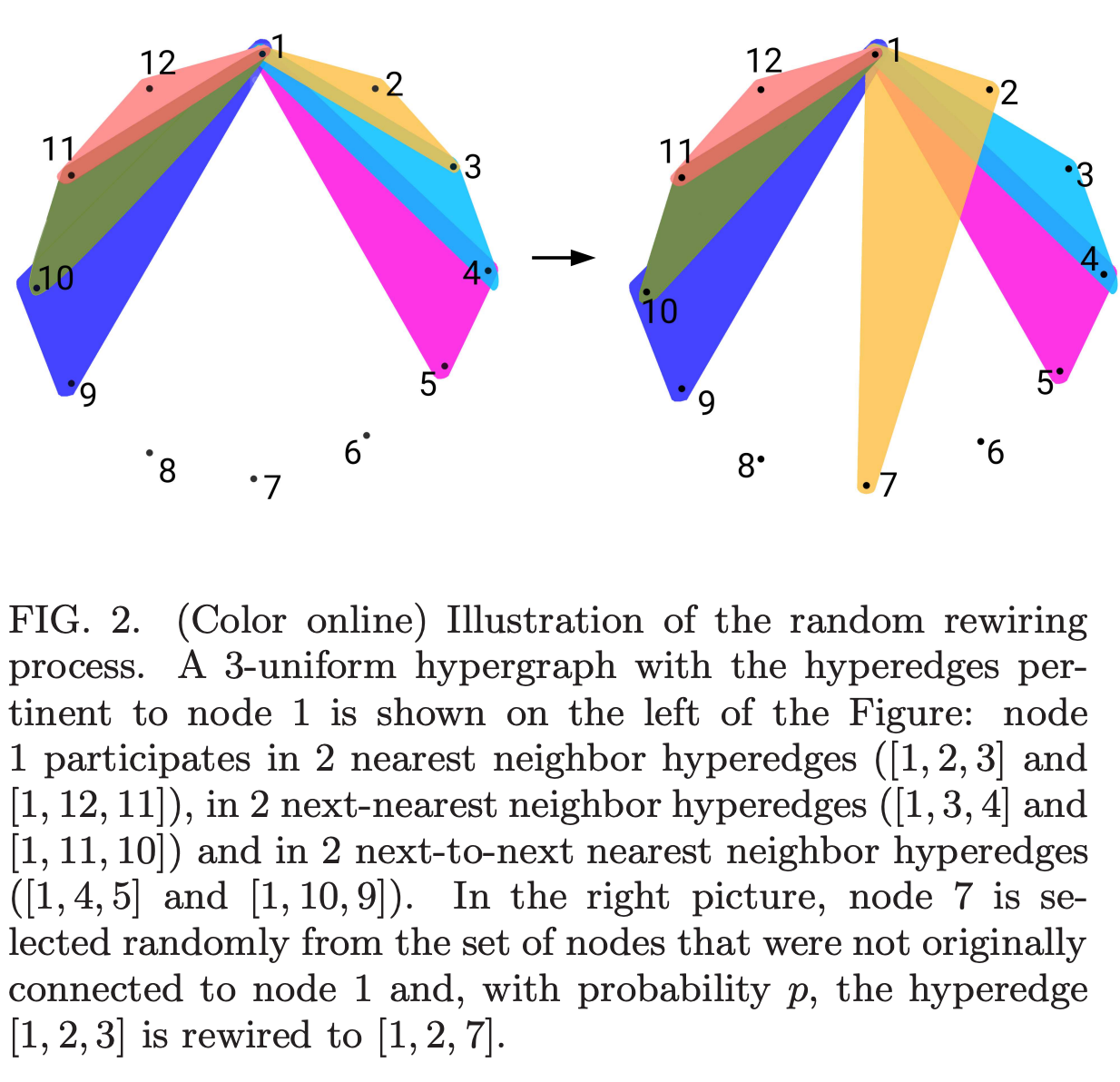
그럼 이 한계점을 어떤식으로 극복해보고자 아이디어를 제안했느냐, 바로 ‘hypergraph’입니다. Pair-wise 가 아닌 gruop-wise(총 3개의 노드가 묶이므로 그룹이라 부르겠습니다.) 인 상황도 발생할텐데, 이 상황이 small world network 에서 발생한다면 small world experiment 와 같이 6단계만으로 모든 사람이 연결될 수 있을까? 6단계가 아니라면, 이상 이하 그 두가지 중 어느 상황에 속할지에 대해 이야기합니다.
** pair-wise 노드와 노드가 1:1으로 연결된 상황.
** group-wise 노드, 노드 그리고 다른 노드가 연결된 1:N으로 연결된 상황. 2개 이상의 노드가 연결되었을 때
Preliminiaries
- Small-world networks: These are networks that exhibit both high clustering and short path lengths. They are neither completely random nor completely ordered but instead have a "small-world" structure.
- Regular lattices: These are networks in which each node has the same number of neighbors, and the connections between nodes are arranged in a regular pattern.
- Random graphs: These are networks in which the connections between nodes are formed randomly, without any specific pattern or structure.
- Watts-Strogatz algorithm: This is a mechanism for generating small-world networks by starting with a regular lattice and randomly rewiring connections with a given probability.
Summary
generated network(regualr lattice, random graph) 에서 하이퍼 그래프가 어떤 영향을 미칠지에 대해 알아보기위해, rewiring algorithm 을 활용합니다. 전후 결과 비교를 위해 네트워크에 얼마만큼 clustering 이 형성되어 있는지 파악하는 지표 그리고 특정 노드와 노드간 최소 거리를 파악하는 지표, 두 지표를 활용합니다.
그 결과 transition 특성은 기존 그래프와 Q-uniform(Q means k hypergraph) 하이퍼그래프에선 비슷하지만, 하이퍼 엣지 순서에 변동이 생기면 transition 발생하는 rewiring 확률의 범위가 축소됩니다. 즉 하이퍼 엣지 순서에 따라 영향이 다름을 알 수 있다고 합니다.
Insight
막연하게만 생각했던, group-wise transition is good or not 애 대한 인사이트를 보여준 논문이라 생각합니다. 예를 들어보자면 모든 사람들이 1:1 로만 이야기하지않고, 1:N 로도 이야기하는 상황이 발생할텐데 이때 이 이야기중 발생하는 정보인 구전 정보가 좋을지 안좋을지로 비교해서 보시면 이해하기 수월하실거라 생각됩니다.
비록 데이터 특성이 generated network 이고 그 내부에 property 를 간주하지 않았다 라는 점에서 여러 한계점이 보이긴하나, 당초 설계한 가장 큰 novelty 에 대해서 그리고 그 novelty proof procedure 은 굉장히 신선했다고 생각합니다.