3월 5주차 그래프 오마카세

The dynamic nature of percolation on networks with triadic interactions
[https://www.nature.com/articles/s41467-023-37019-5]
“preliminary”
percolation effect
그들은 3차 상호 작용의 역학을 고려한 모델을 제안하고 이것이 개인 간의 쌍방향 상호 작용만 고려하는 모델과 비교하여 다른 결과를 초래할 수 있음을 보여줍니다.
네트워크 과학에서 퍼콜레이션(percolation)은 노드 또는 에지가 제거되거나 추가될 때 네트워크의 동작을 참조하는 개념입니다. 특히, 침투 이론은 네트워크에서 노드 또는 에지를 제거하는 것이 네트워크에서 가장 큰 연결 구성 요소의 크기와 연결에 어떻게 영향을 미치는지 연구합니다.
단순 네트워크에서 퍼콜레이션은 네트워크에서 노드 또는 에지를 제거하고 네트워크 연결에 미치는 영향을 관찰하는 프로세스를 말합니다. 예를 들어, 소셜 네트워크에서 노드를 제거하는 것은 네트워크를 떠나는 개인에게 해당하는 반면, 가장자리를 제거하는 것은 우정이 끝나는 것에 해당할 수 있습니다. 침투 이론은 노드 또는 에지 제거가 네트워크의 전체 연결에 어떤 영향을 미치는지 예측하는 데 도움이 됩니다.
다중 네트워크에서 침투는 네트워크의 다른 계층에서 특정 유형의 에지 또는 노드를 제거하는 것을 의미할 수 있습니다. 예를 들어, 멀티플렉스 소셜 네트워크에서 모든 전문적인 협업 에지를 제거하는 것은 모든 우정 에지를 제거하는 것과 다르게 네트워크의 전체 연결에 영향을 미칠 수 있습니다.
고차 네트워크에서 침투는 삼각형이나 다른 기하학적 모양과 같은 고차 구조를 제거하는 것을 의미할 수 있습니다. 이러한 구조를 제거하면 가장자리에 의해 직접 연결되지 않은 노드의 연결이 끊어질 수 있으므로 네트워크 연결에 상당한 영향을 미칠 수 있습니다.
“summary”
[We find that triadic percolation on real network topologies reveals a similar phenomenology. These results radically change our understanding of percolation and may be used to study complex systems in which the functional connectivity is changing in time dynamically and in a non-trivial way, such as in neural and climate networks.]
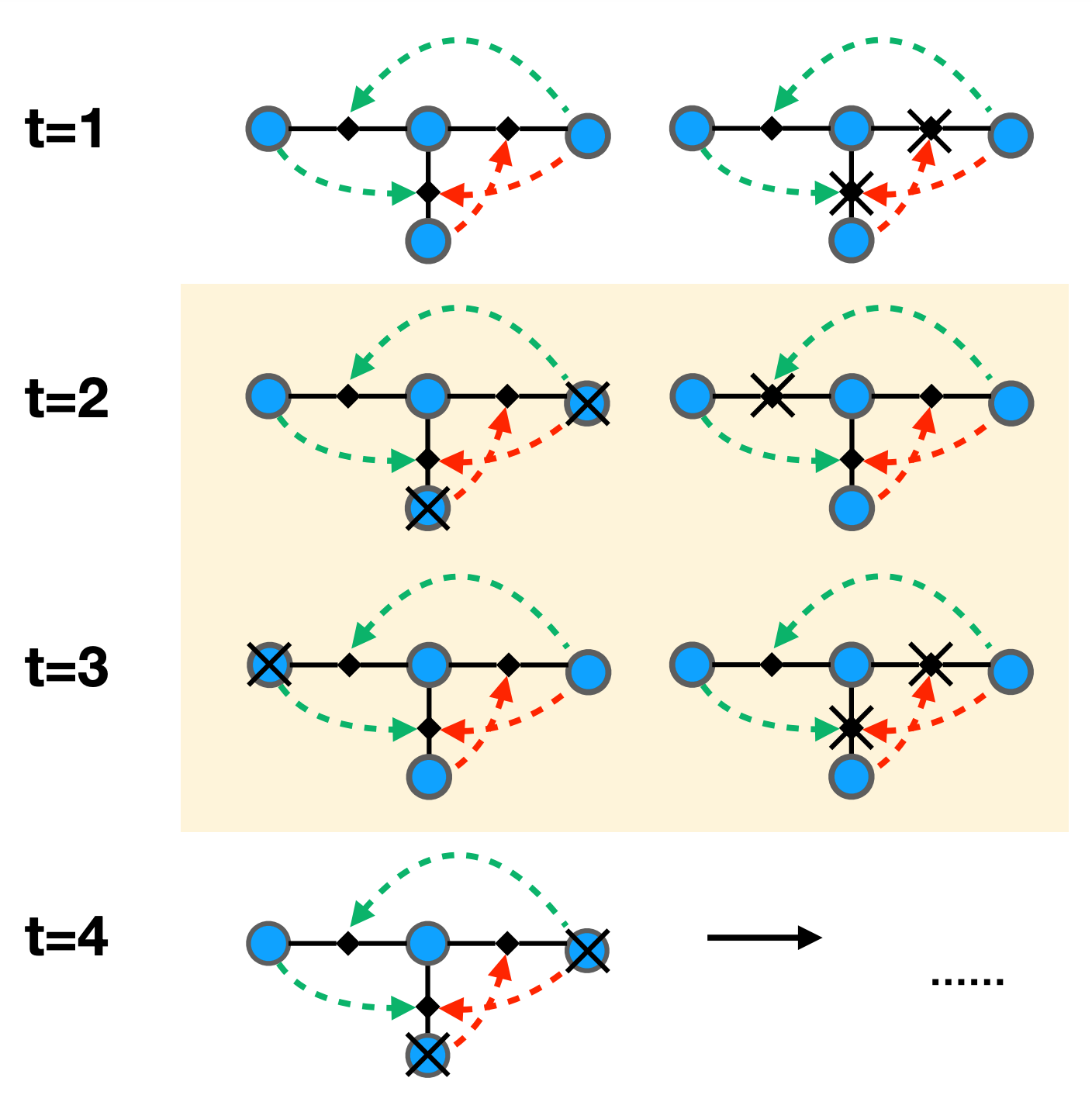
- triadic 에 대해 들어보신분들 계실까요? 저는 이 개념을 Triadic closure 로 처음 접했는데요, social network 에서 A,B,C 유저들의 관계를 예시로 들어 설명해보겠습니다. B와 C는 서로 관계가 존재하지 않지만 A가 B,C 유저 각각 친밀한 관계를 가지고 있을때, B와 C는 A를 기반으로 연결될 가능성이 높다. 라는 이론입니다. triadic 에 대해 이야기를 꺼낸 이유는 바로 본 논문의 핵심 아이디어가 시간에 흐름에 따라 triadic가 어떻게 변하며 그 변함이 최종적으로 네트워크에 어떤 영향을 미치는가에 대해 새로운 관점으로 접근했기 때문입니다. 이 변함에 대해 측정하는 정량화 지표는 percolation 을 활용했구요.
- triadic 설계가 궁금하실텐데요. 노드와 노드간 링크에 positive , negative 를 넣어줌으로써 시간이 변함에 따라 노드간의 관계가 +가 될수도 있고, -가 될수도 있습니다. 이때, 시간마다 관계가 변하지만 노드의 위치들은 일정하기 때문에 이를 high-order network 관점으로도 볼 수 있습니다. 최종적으로 시간마다의 Percolation이 어떻게 변하는지 cobweb 을 통해 결과를 확인하며, 링크 regulator 마다 어떤 영향을 미치는지 분석 및 해석하게 됩니다.
“insight”
- percolation 에 regulator 개념을 접목한 percolation 인 triadic percolation 이 과연 어느 영향을 미치는가에 대한 인사이트
- Scale-free , Poisson 분포를 지닌 네트워크에서 percolation 시뮬레이션을 진행한 결과 과연 triadic 의 관계들이 유의미한 영향을 미치는가에 대한 인사이트
- real-world 네트워크에서도 과연 triadic percolation이 유의미할까에 대한 인사이트
“Future works”
- percolation 하면 떠오르는 분야가 다양하겠지만, 저는 그 중 이커머스가 가장 먼저 떠오르네요. 필수재인 휴지 물 등과 같은 물품들은 수요공급이 일정하다고 볼 수 있는 반면, 유행에 많이 좌지우지 되는 물품 같은 경우에는 수요공급 변동성이 크기에 이를 빠르게 파악해서 준비하는게 기업의 핵심 역량이라 볼 수 있습니다. 이 흐름을 이커머스 그리고 추천시스템에 적용을 해본다면, 유저들의 언급이 많아지는 아이템(percolation 이 높은 아이템)을 가중치로 딥러닝 계층에 추가해준다면 성능 개선이 도움이 되지 않을까 하는 생각이 드네요.
Creating generalizable downstream graph models with random projections
“preliminary”
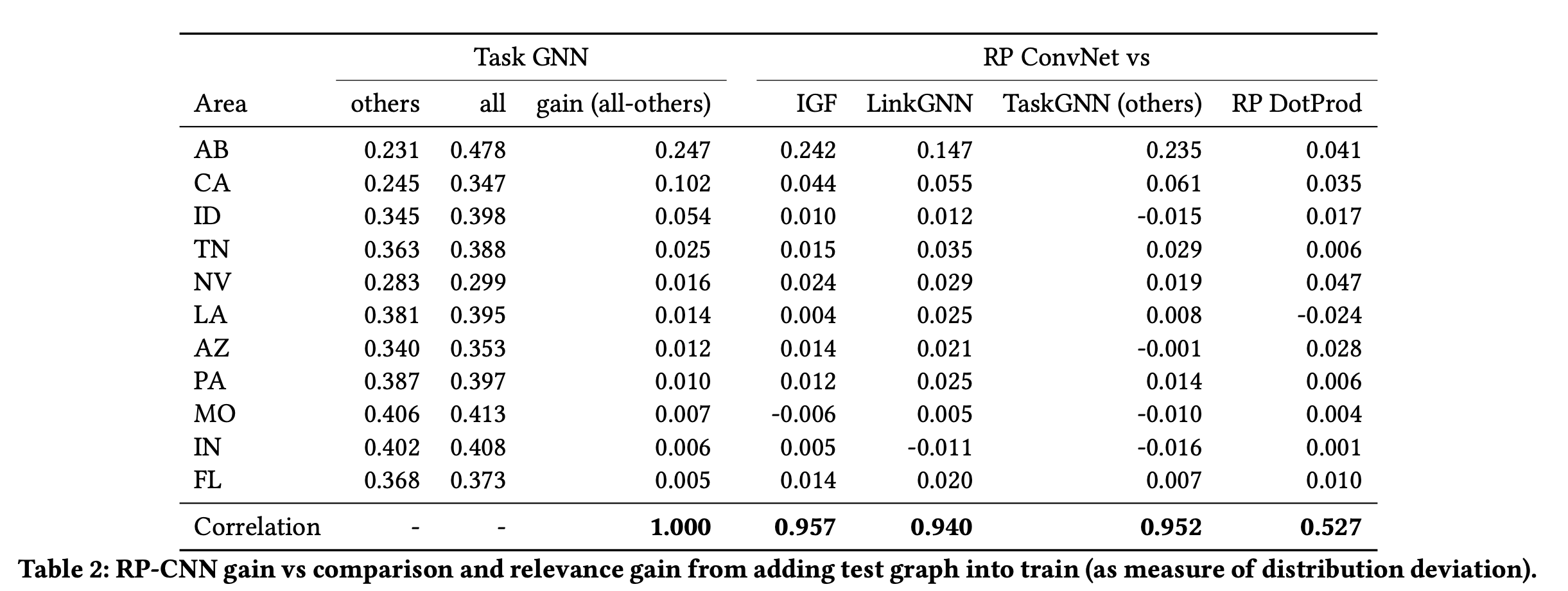
dot product 가 독일수도 있는 generalize methodology trial.
- the dot product, which is commonly used in the loss function of many graph embedding models, is invariant to rotations of the embedding space. This means that if we rotate the embedding space by some angle, the dot product between any two vectors in the embedding space will remain the same.
- This can be a problem when we want to compare or combine embeddings from different models or trainings because the orientation of the embedding space can differ between these embeddings. In other words, even if two embeddings represent the same underlying graph, they might have different orientations, which can make it difficult to compare or combine them.
“Summary”
- 과연 task-agnostic 한 그래프 알고리즘들이 존재할까요? pre-training 을 한다고 하더라도, 각기 다른 도메인에 속한 데이터셋의 feature들을 모두 일치하기에는 한계가 존재합니다.결국, 성능향상을 위해 필수 요소였던 feature 들이 특정 도메인에는 존재하고, 존재하지 않고와 같은 dependent 한 상황이 발생하기에 오히려 generalization에서는 방해물이 된다고도 볼 수 있습니다.
- 그럼, 처음으로 돌아가서 feature를 고려치 않고 그래프 구조만을 가지고 임베딩을 하게 된다면 앞서 말씀드린 task-agnostic available 이 가능할까요? 본 논문에서는 그 질문에 대해 답해보고자 1.graph structural algorithm 2. graph invariant feature 3. graph neural network 각각 세가지 관점으로 접근합니다.
- 결과는 1. graph structural algorithm 이 task 에 독립적임을 다양한 실험으로 입증해냅니다. 그 독립성의 핵심에는 random projection 이라는 알고리즘이 존재합니다. 쉽게 말씀드리자면, node 간의 이동확률인 transition matrix 을 활용하여 그 matrix 의 확률분포를 기반으로 임베딩을 합니다. 확률분포는 데이터셋마다 비슷하게 분포가 되어있으므로, 그 분포에 트릭을 가하여 각 도메인마다의 context 를 최대한 일치시킵니다. 최종적으로 도출된 값을 기반으로 dot-product 그리고 conv1d network 를 활용합니다.
“Insight”
- 데이터 분석대회에서 베이스라인으로 활용하던 node2vec의 성능을 향상시킬수 있는 방안이 담겨있습니다.
- graph task 에서 graph neural network가 만능일것인가 라는 의문을 떠오르게하는 논문입니다. feature 가 많을수록 성능이 향상될 가능성도 있으나, over smoothing over squashing 등 과 같은 부가적인 에러들 또한 발생할 가능성 또한 농후하기에 연산량 측면에서 훨씬 저렴한 shallow embedding 을 베이스라인으로 현업에서 활용해보면 어떨까 싶네요.
- conv1d Network 의 재발견, 기존에는 shallow embedding 이 후 도출된 feature을 random forest 계열의 예측기를 활용하여 task 를 수행해나아갔다면, 본 논문에서는 conv1d 의 장점을 활용하여 clssifier 로써 활용해보았습니다. signal processing classifier 에서 주로 활용되던 conv1d 를 invariant , spectral 관점에서 접근하면 좋은 성능을 보일것이라는 상상이 현실로 되는 논문이였다고 생각합니다.
“Future works”
- FastRP는 자연스럽게 양의 가중치가 있는 방향 그래프 및/또는 그래프로 확장될 수 있습니다. 또 다른 가능한 연구 분야는 이질적인 그래프에 이 기술을 적용하는 것입니다. 후자의 경우, 우리는 노드를 하나가 아니라 서로 다른 메타 경로를 나타내는 행렬 집합과 연결할 수 있습니다.
Efficiently Leveraging Multi-level User Intent for Session-based Recommendation via Atten-Mixer Network
[https://arxiv.org/pdf/2206.12781.pdf]
“preliminary”
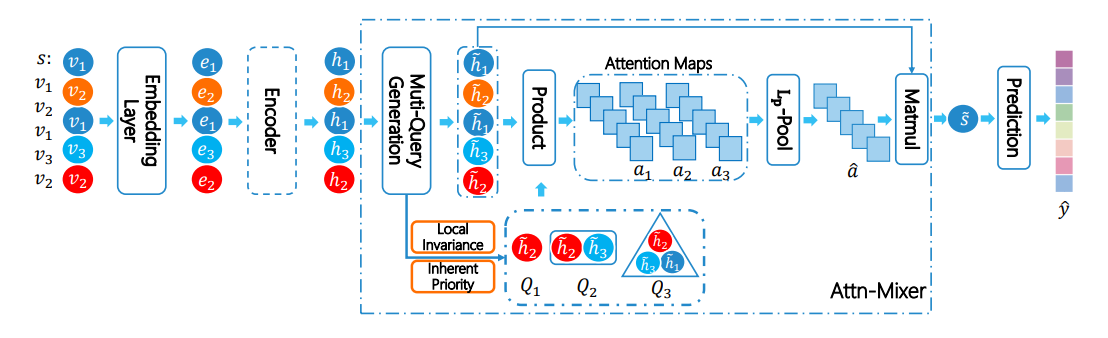
Session permutation invariant 를 위해 활용한 Deepset algorithm.
- "DeepSet" is an algorithm that was introduced in a 2017 paper by Manzil Zaheer, Satwik Kottur, Siamak Ravanbakhsh, Barnabas Poczos, Ruslan Salakhutdinov, and Alexander Smola.
- The algorithm is designed to process sets of inputs, where each input is a vector of features, and produce a single output. DeepSet is a modification of the more general neural network architecture known as a "sequence-to-sequence" model.
- The key innovation of the DeepSet algorithm is that it adds a permutation-invariant function to the sequence-to-sequence architecture. This function ensures that the output of the algorithm is invariant to the order in which the inputs are presented. In other words, the algorithm treats sets of inputs as unordered collections, rather than sequences.
- The DeepSet algorithm achieves this by using a pooling operation over the inputs. Specifically, the algorithm computes a feature vector for each input, then applies a permutation-invariant pooling operation (such as max pooling or average pooling) to these feature vectors to produce a single output.
- The authors of the paper demonstrate the effectiveness of DeepSet on a range of tasks, including predicting properties of molecules and classifying sets of images. They show that DeepSet outperforms several alternative methods for processing sets of inputs, including those based on convolutional neural networks (CNNs) and recurrent neural networks (RNNs).
- In summary, DeepSet is an algorithm that is designed to process sets of inputs, where each input is a vector of features, and produce a single output. The algorithm uses a permutation-invariant pooling operation to ensure that the output is invariant to the order in which the inputs are presented. The algorithm has shown promising results on a range of tasks, and could be useful in a variety of machine learning applications.
“Summary”
- we intuitively propose to remove the GNN propagation part, while the readout module will take on more responsibility in the model reasoning process.
- Session-based GNN 알고리즘의 주 특성이라 볼 수 있는 module by module weight flow 에 대해 실증분석 한 후, 그 분석으로 부터 얻은 인사이트를 기반으로 Atten-Mixer 라는 아이디어를 구현하게 됩니다.
- 문제는 다음과 같습니다. Session 마다의 유저가 노드를 바라보는 관점이 모두 다를텐데, 이 관점들이 다양하게 볼 수 있으나, 대다수 알고리즘들은 최근에 근접할수록 더욱 큰 가중치를 주게 됩니다. 이때, 가중치가 편향되는 현상이 발생할 수도 있기에, 레이어의 마지막에 가중치들을 종합적으로 판단하기 위한 용도의 pooling 역할을 하는 레이어를 추가로 적용해주곤 합니다.
- 여기에서 발생하는 문제는 바로, 그래프 데이터 특성인 Sparsification으로 부터 발생합니다. 노드와 엣지가 density 하게 구성되어 있다면, propagation 이 잘 진행되어 weight 자동 미분과 학습까지 일사천리로 진행되겠으나, sparse 한 데이터에서는 그 propagation 이 도중에 끊기기에 weight 가 극단적으로 바뀌게 됩니다. 중요한 parameter 라고 판단되는 것들만 살아남기 때문에 propagation density 가 상대적으로 낮은거죠. 이 증상은 recommender system 에서 자주 발생합니다. 간단하게 생각해보면, 유저가 교류한 아이템의 수와 플랫폼에 전시되어있는 아이템의 수를 나누어 수치로 표현해보면 대략 상황이 떠오르실텐데요. 유저가 관심을 보인 아이템 대비 새로이 발생하는 아이템의 수가 너무나도 많으니 그 차이가 엄청난거죠. 더군다나, 이 관계들을 저희가 알고있는 static 도 아닌 session by session으로 구현하게 된다면 그 sparsity 는 더할거라 생각이 듭니다.
- 핵심 문제인 Sparsification 를 완화시켜보고자 ‘Atten-Mixer’ 를 제안합니다. 요지는 다음 두 가지 아이디어로 정리할 수 있을거 같습니다. 첫 번째는 유저의 의도를 지속적으로 기억하고 학습하기 위해 a pool of attention maps with multi-level user intent information based on the inductive biases를 활용하는 것이고, 둘째로는 attention map 으로 부터 발생한 임베딩 값들을 순서에 주의를 기울일 수 있도록 permutation invariant 방식을 적용해주는 겁니다. 초반에 언급드린 바와 같이 최근에 근접할수록 유저의 의도가 더욱 명확해지니깐요.
“Insight”
- 실험을 위해 Session-based 알고리즘에서 자주 사용되는 방법론들을 대조군으로 두고 관찰합니다. recommender system competition 에서 session-based task 가 빠지지않고 나올만큼 화두인데요, 대회 진입 전 참고하면 좋을 컨닝 페이퍼로 활용해도 좋을거라 생각이 드네요.
- component 를 하나씩 빼면서 실험하는 Ablation Study 섹션을 집중해서 보신다면, session 에서 attention pooling 이 중요할지, local invariance 가 중요할지 , user-intention 이 중요할지에 대해 간접적으로 파악하실수 있겠습니다.
- session length 를 어떻게 잡아야 할지에 대해 오마카세 주방장도 늘 고민이 많았는데요. session length 에 비례하여 성능이 개선되지 않는 결과 보고나서 그 고민에 대해 많이 배웠다고 생각이 듭니다.
- session-based recommender system 관련해서 다들 궁금해하셨을만한 주제들에 대해 잘 다루어놓은 논문이라 생각이드네요. 서베이 논문을 보기보다 본 논문을 보며 session GNN에 관해 접근하시면 훨씬 방향성 잡기에 수월하지 않을까 싶습니다.
“Future works”
- 저는 Session based task 에 static 알고리즘이 dynamic 알고리즘보다 좋은 성능을 냈었던 WSDM2022 Cup top 3 solution 이 떠오르네요. 과연 최근에 가중치를 많이 주도록 유도하는게 옳은것인가 아니면 가중치를 자연스럽게 degree-based로 flow하는게 맞는가에 대해서는 아직 명확한 답이 없다고 생각듭니다. 이 두 관점에서 task마다 어떤 방식이 잘 작동할지에 대한 indicator 혹은 bridge 과 같은 무언가가 향후 recommender system 연구 이슈가 되지 않을까 싶네요.