8월 2주차 그래프 오마카세


DRew: Dynamically Rewired Message Passing with Delay
[https://arxiv.org/pdf/2305.08018.pdf]
Introduction
MPNN(message passing neural network) , life-science 에서 주로 활용되는 그래프 딥러닝 아키텍쳐입니다. Message passing aggregation 을 변형시켜 task에 맞는 정보들을 update 할 수 있단 점에서 타 아키텍쳐들과 차이점을 보입니다. 다시 말해 , message passing function 을 유연하게 활용할 수 있다는거죠. 하지만, 멀리있는 타겟노드에게 정보를 전달하는 부분에선 유연하지 않습니다. 바로 over-squashing 현상 때문인데요. Node receptive field 차원이 aggregation 정보를 모두 반영하고 업데이트 될 정도로 고차원이라면 괜찮으나, 상대적으로 적은 차원일 경우에는 중요한 정보들이 희석되어 유용한 정보대비 잡음이 많이 발생해 유효정보가 적어지는거죠.
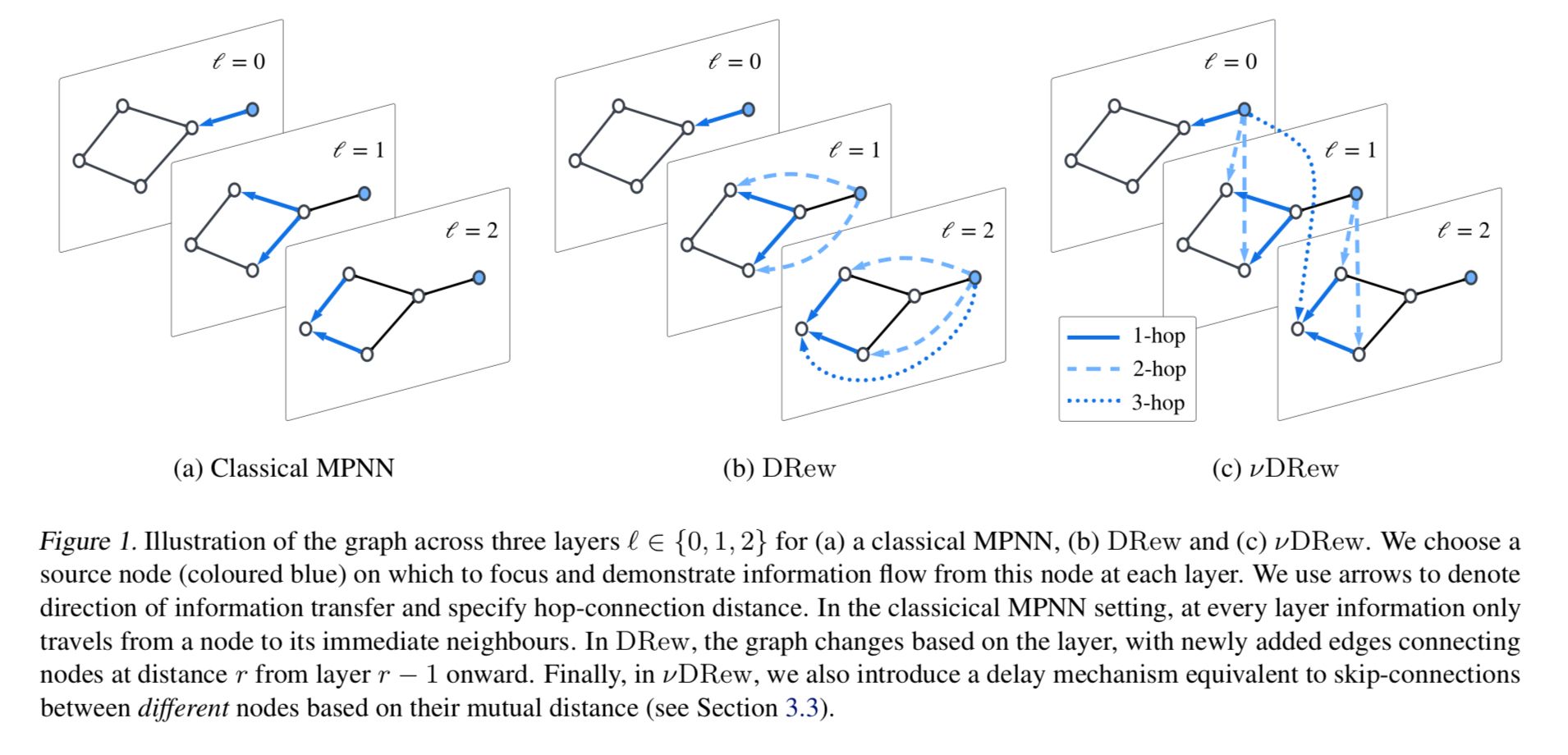
이를, 극복하기 위해 여러 방안들이 제안되고 있습니다. 병목 현상이 있을만한 노드(receptive field가 큰 노드)를 추출하여 rewiring technqiue 를 적용해 특정 노드에만 정보 쏠림현상을 완화시키는 기술이 대표적일 수 있는데요. 본 방법론에서는 이와 다르게 delay mechanism 을 활용합니다.
Delay mechanism 은 말 그대로 정보가 흐른 시점 t 이후인 t+delay 에 출발 노드의 정보를 추가로 반영해주는겁니다. 딥러닝 기술 중 하나인 skip-connection 이 graph 에 적용되었다 라고 생각하셔도 무방합니다.
Preliminary
[what difference between GCN and MPNN?]
Message Passing Mechanism:
- GCN: In a GCN, information is propagated through the graph using a fixed local neighborhood aggregation scheme. Each node aggregates information from its neighbors and itself, applying a convolutional operation similar to those used in image convolutional networks.
- MPNN: MPNNs generalize the message passing concept. They define a message function that sends and receives messages between nodes and edges in the graph. This allows for more flexibility in how information is exchanged during propagation.
- Message Aggregation:
- GCN: GCN uses a simple aggregation approach where node features are summed (or averaged) with the features of neighboring nodes. It operates on a fixed neighborhood around each node.
- MPNN: MPNNs allow for various types of aggregation functions beyond simple summing or averaging. Different aggregation functions can capture more complex relationships between nodes and edges.
Expressiveness:
- GCN: GCNs are limited in their expressive power due to the fixed aggregation function. They may struggle to capture certain higher-order graph structures.
- MPNN: MPNNs provide more expressiveness by allowing different types of message functions and aggregation strategies. This enables them to capture a wider range of graph patterns.
Graph Isomorphism:
- GCN: Traditional GCNs work well for graphs with a fixed structure, as they assume all nodes have the same neighborhood.
- MPNN: MPNNs are more flexible and can handle graphs with varying structures, making them suitable for a wider range of applications.
Applications:
- GCN: GCNs are often used for node classification, semi-supervised learning, and tasks where the graph structure remains relatively stable.
- MPNN: MPNNs are more versatile and can handle more dynamic graph scenarios, making them suitable for tasks like graph classification, predicting molecular properties, and more.
In summary, while both GCNs and MPNNs are designed for graph-based data, MPNNs provide more flexibility and expressive power due to their generalized message passing mechanism. MPNNs are better suited for handling dynamic graph structures and capturing more complex relationships in the data. However, the choice between GCNs and MPNNs depends on the specific characteristics of the problem and the nature of the graph data you are working with.
Summary
논문 저자는 다음 2가지 문제점을 동기로 삼아 본 논문 아이디어를 도출했는데요. 1. Distant nodes can only communicate by exchanging information with their neighbours.2.Distant nodes always interact with a fixed delay given by their distance.
정리해보면, 먼거리에 있는 노드들로부터 정보를 받고 싶으나 주변 이웃들이 먼거리에 있는 노드들과 연결이 되어 있지 않거나, 먼거리 노드들을 포함한 다른 노드들이 너무 많을 경우 그 먼거리 노드의 정보를 반영하기에 한계점이 존재함. 또한 ‘먼거리’를 지칭하는 파라미터 레이어가 고정되어있기에, 그 ‘먼거리’ 정보를 반영하려면 임의의 파라미터조정이 필요함.
위 두가지를 해결하기 위해 동적으로 정보가 전달되는 delay 메커니즘을 적용한 rewiring 방식을 제안합니다.
[Delay parameter]
기존에는 특정 노드로부터 정보를 전달받기 위해서는 특정 노드와 해당 노드간 연결된 hop layer 개수가 iterative 반복 시행되었습니다. 때문에, layer 가 내 노드까지 오기를 기다려야 한다는 단점이 있었는데요. 이 방식을 개선하고자 delay 라는 수치를 통해 information flow speed 를 조정해줍니다.
[Why delay?]
Delay 는 information flow 를 expressive control 할 수 있는 파라미터로써 활용할 수 있습니다. 다시말해, 기존 layer 에 종속된 정보교류에 유연성을 더하고자 특정 layer 갯수까지의 정보를 추가로 적용할수 있는 보조수단을 붙인거죠. 그렇기에, delay (layer로부터 이전에 정보를 받았으나 n번 다시 그 정보를 update)할 수 있게 됩니다.
[How mitigating over-squashing?]
Delay parameter 미만의 타 노드와 정보를 교류하게 되면서 receptive field 가 그대로이나 , ‘연결’되어 있는 이웃 뿐만아니라, 타 노드 정보 또한 지속적으로 업데이트할 수 있기에 ‘decaying to zero exponentially with the distance’라고 저자는 말합니다.
Takeaway
Skip-connection , 한때 딥러닝을 풍미했던 방식이였는데, 어느샌가 사람들로부터 잊혀진 방식이죠. 이렇게 또 마주할줄은 몰랐네요. GNN 하시는분들은 Jumping knowledge net 라는 layer로 익숙하셨을 겁니다. 그와 유사한점은 많으나, delay parameter 과 layer information flow를 수평수직 방향으로 활용하며 정보흐름을 조정할 수 있다는 점에서 논문 차별성을 인정받아 억셉됬지 않았을까하네요.
Path-enhanced graph convolutional networks for node classification without features
[https://journals.plos.org/plosone/article?id=10.1371/journal.pone.0287001]
Introduction
GNN을 적용하고 싶은데 feature 가 없을때 feature를 만들어 내기에 애매모호한 상황들이 있으셨을 겁니다. 정답이 없는 상황이긴 하지만, 되도록 원래 부여된 정보를 최대한 보존한채 학습을 하는게 정석으로 알려져 있습니다. 정석이라는 것을 건드려보고 싶은게 사람 심리인지라, 저 개인적으로 랜덤 난수 128차원 vs. 기존 node feature 128차원을 비교대조해 본 결과 랜덤 난수 성능이 우수한 케이스를 발견한 경험이 있었는데요. 이 경험 이 후 저는 늘 해당 노드 feature가 타당한지에 대해 의구심을 품고 간단한 당위성 검증 이후에 feature를 적용하곤 합니다.
소개시켜드릴 논문도 마찬가지로 node feature가 없을시, 어떤식으로 feature를 생성해 적용하면 좋을지 고민으로부터 시작된 연구입니다. 저와 다르게 랜덤 난수가 아닌, 특정 노드간 shortest-path 를 추출해 edge-feature로 활용했는데요. Shortest-path 가 결국엔 노드간 관계를 반영하기에 그렇지 않았을까 싶습니다.
Preliminary
[shortest-path in graph theory]
In graph theory, a graph consists of nodes (also called vertices) connected by edges. Each edge may have a weight or a cost associated with it, which represents the "cost" of moving from one node to another along that edge.
The concept of a shortest path arises when you want to find the most efficient way to travel from one node to another in the graph. This could represent various scenarios, such as finding the shortest route between two locations on a map, the least expensive way to transfer data in a computer network, or even the quickest path to solve a puzzle.
To find the shortest path, you can use algorithms that explore different paths in the graph while keeping track of the cumulative weights of the edges. The aim is to find the path with the lowest total weight.
Two commonly used algorithms for finding the shortest path are:
- Dijkstra's Algorithm: This algorithm starts at the source node and iteratively selects the node with the lowest cumulative weight, expanding outward until it reaches the target node. It guarantees finding the shortest path in graphs with non-negative edge weights.
- Bellman-Ford Algorithm: This algorithm can handle graphs with negative edge weights (as long as there are no negative weight cycles). It iteratively updates the estimated shortest distances until convergence.
These algorithms help identify the optimal path based on the weights of the edges. Keep in mind that the "shortest path" might not necessarily be unique; there could be multiple paths with the same shortest length. It's also important to consider whether the graph is directed (edges have a specific direction) or undirected (edges have no direction).
Summary
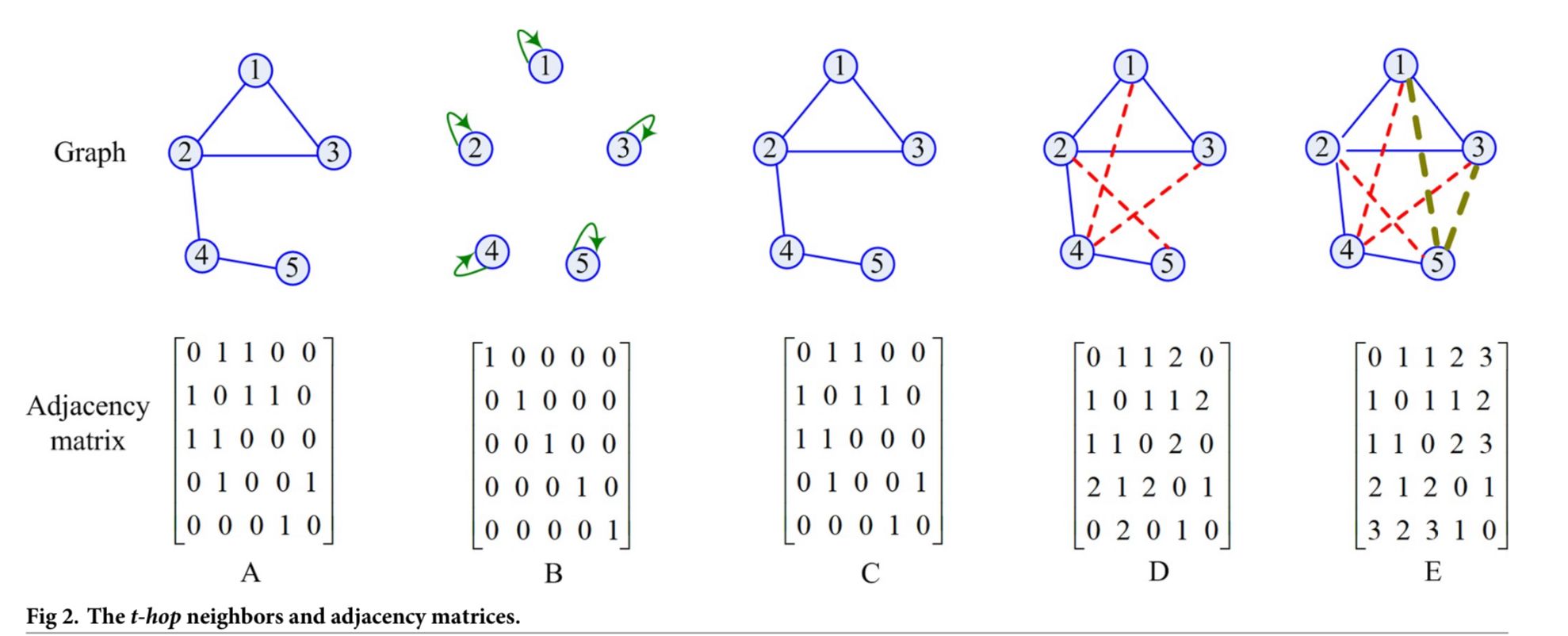
방법론 요약이 되게 간단합니다. 각 노드들간 shortest-path adjacency matrix 를 feature 로 간주하여 gnn에 태웁니다. Hop 이라 하여 edge weight가 반영되는 등 여러 요건들이 있을거라 생각할 수도 있지만 앞서 말한것과 같이 심플합니다. 3hop 이라면 adjacency matrix 에 3으로 표현합니다. 만약 2hop 떨어진 노드라면 2로 채워져 있구요. 기존에 알던 인접행렬에 hop count 가 대신들어가 있다고 보시면 되겠습니다.
Takeaway
T-hop 마다 성능 변동사항이 section 5 에 나와있습니다. 여기에선 t-hop의 t를 파라미터로 간주하여 지정시마다 어떻게 성능이 좌지우지 되는지를 관찰했네요. 유념하면서 보면 좋을 부분은 pubmed(life-science)데이터셋에서 t가 5에서 6으로 전환되는 순간 성능이 대폭 하락합니다. 이외에도 hop마다 성능이 어떻게 달라지는지에 대해 작성해두었는데요. 이 실험결과를 기반으로 논문에서는 특정 diameter 이상, 이하에 따라 어떻게 t를 적용하면 좋을지에 대해 이야기 합니다. 이 부분을 중점적으로 보시면 여러분들께서 많은 인사이트를 얻어가실 수 있을거라 생각합니다. 단순 GCN 뿐만아니라, 다양한 GCN 계열들 그리고 여러 diameter 특성을 가진 그래프 데이터셋들을 기반으로 실험했기에, 이와 비슷한 연구주제를 고려하시는 분들이시라면 실험설계에 많은 도움이 되겠네요.
chef blahblah
요즘들어, path specific paper 들이 많이 나오는거 같습니다. 그만큼, gnn 에서 topological feature 가 굉장히 중요한 분야이고 많이 연구되는 분야임을 반증한다고 생각합니다. 모두들 잘 아시다시피, shortest-path 는 np-hard 문제이기에 실시간성 문제에 적용하기에는 과도한 연산이 발생하기에, 현업에서 문제를 적용할때에는 한계점이 명확해보입니다. 하지만, 한계점을 개선하고 새로운 솔루션을 개발하는게 연구자들의 숙명이기에 여러분들께서 도전해보는건 어떨까요?
Can Directed Graph Neural Networks be Adversarially Robust?
[https://arxiv.org/pdf/2306.02002.pdf]
Introduction
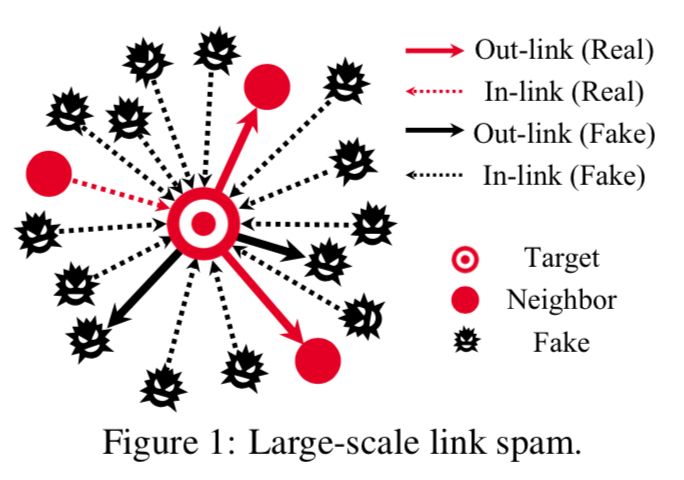
세미나 때 받았던 여러 질문들 중 가장 흥미로운 질문은 바로 ‘FDS’에서 그래프 형태를 어떤식으로 고려했는지 였습니다. 실제 금융 거래에서 발생하는 입/출금은 누구로부터 주고, 받는지에 대한 능/수동 관계이기에 이를 표현하기 위해 최적의 데이터구조는 바로 그래프인데, 저는 그 정보를 반영치 않고 undirected 로 고려해서 연구를 진행했던거죠. Direct 정보는 굉장히 중요합니다. 실제 사례를 예로 들어 이야기해보면, 요즘 피싱에 연관된 계좌를 고의적으로 만들어, 특정 계좌의 금융거래를 정지 시키고 싶을때 의도적으로 해당 계좌에 송금한다고 합니다. 재화를 받는 상대는 꼼짝없이 타게팅되어, 거래로부터 연관성이 없다는 소명을 끝낸후에야 비로서 거래가 재작동되는거죠.
이처럼, 실생활에는 누구로부터 금액을 받았는지에 대한 방향성을 대표하는 관계가 의도를 판별하기에 굉장히 중요한 요소라고 할.수 있습니다. GNN 분야에서 기존에는 관계를 undirected 로 모두 간주하였기에, 능/수동을 반영치않았기에 해당 거래에 대해 모두 동등한 의도를 가지고 있다 라는 전제를 기반으로 학습이 되는거죠. 앞서 언급한 사례처럼 관계를 반영치 않았을시에는 그 의도가 명확치 않기에 이러한 디테일을 gnn이 발견하고 적용하기엔 한계가 존재합니다.
본 논문에서는 이를 반영하고자, directed 에 특화된 attack setting 하여, 정말 방향성이 fraud 의도를 잡아내는거에 대해 유의미한지에 실험합니다. 이를 실험 결과를 토대로 당위성을 도출하고 directed 를 반영한 기법인 BBRW(biased birectional random walk message passing)을 제안합니다.
Preliminary
[UGA(undirected graph attack method overview]
- Graph Structure: Consider an undirected graph, where nodes represent entities (e.g., users, products) and edges represent relationships between them (e.g., friendships, interactions).
- Node Classification Task: Let's say you're using this graph for a node classification task, where the goal is to predict the category or label of each node based on its connections and attributes.
- Adversarial Attack: To simulate an adversarial attack in the UGA experiment, an attacker might intentionally modify a small number of edges in the graph. These modifications are carefully chosen to disrupt the graph's structure while aiming to maintain the graph's undirected nature.
- Evaluating Robustness: After the adversarial attack, the GNN model's performance on the node classification task is evaluated. If the model's accuracy or performance significantly drops after the attack, it suggests that the GNN is not robust against the specific type of attack applied. On the other hand, if the GNN continues to perform well despite the attack, it indicates a higher level of robustness.
- Comparative Analysis: Researchers often compare the GNN's performance before and after the UGA experiment. Additionally, they might compare the GNN's performance against other adversarial attack methods to understand which attacks the model is more resilient against.
Overall, the UGA experiment provides insights into how well a GNN can handle adversarial manipulation in an undirected graph scenario. It helps researchers assess the model's vulnerabilities and strengths in maintaining accurate predictions despite intentional disruptions to the graph's structure.
Summary
다음 2가지가 본 논문의 핵심이라고 할 수 있습니다.
[Direct graph 가 효율적이라는 것을 입증하기 위한 attack setting]
UGA(traditional) 와 RDGA(our approach) 를 비교하여 undirected vs. directed 를 입증해냅니다. RDGA는 mask 와 perturbation 을 추가하여 in-links 와 out-links 에 budget 가 적용된 matrices 를 generation 하고 그 내에서 link selection 를 하는것이 목적입니다. 이를 통해 이전(UGA)과 다르게 , 링크의 종류 그리고 비중에 따라 어떻게 성능이 바뀌는지에 대해 반복 시행을 통한 검증을 하는게 핵심이라고 할 수 있습니다.
[BBRW]
BBRW.. 음.. node2vec 알고리즘을 아시는분이라면 익숙하실거라 생각합니다. p,q 하이퍼 파라미터를 통해 randomwalk 를 어떻게 수행할지에 대해 지정해주는게 node2vec 이라면 BBRW 에서는 이를 유방향 그래프에서 편향된 랜덤 워크를 수행하며, 인-링크 및 아웃-링크 노드 임베딩을 별도로 계산한 다음 이를 편향 가중치 β와 함께 결합하여 인-링크와 아웃-링크 그래프 토폴로지 정보를 모두 활용한다는점이 차이점이라고 할 수 있습니다.
Takeaway
FDS 에서 direct graph 설계가 왜 중요한지에 대해 basic reference 로 활용해도 좋을 논문이라 생각합니다. NOSQL 이라는 데이터 관리방식이 FDS 에서 중요하다는 것은 알고 있지만, 그 내부에 그래프 이론 및 분석을 적용하면 어떤 이점이 있을지에 대해 아직까지는 애매모호한 부분이 많은데요. 그 점을 보완해줄 논문이라 생각합니다. 관계에 정보를 더하여 관리 및 분석을 할 수 있다는 점이 기존 tabular 관점에서는 어려운 부분이 많기때문이죠.
chef blahblah
세미나 때 발표를 함께하셨던분들은 들으셨겠으나, future work 로 남겨둔 부분을 본 논문에서 적용했습니다. Setting 을 기반으로 당위성을 검출하는 부분에 대해서는 생각치도 못했던터라, 너무나도 반가운 논문이였습니다.
The Power of Ontologies and Knowledge Graphs: Practical Examples from the Financial Industry
knowledge graph real-world case.
실제 세계에서 과연 지식그래프가 어떻게 활용될까요? 늘 허구와 실제 사이에서 거론되는 주제인거 같네요. 지식을 그래프로 표현한다고 한들 얻어지는 이점이 있을까? 구현이 복잡하니 차라리 자연어처리를 활용하는게 좋지않을까? 등등의 고무적인 입장들이 자주 보이곤 하는데요. 지식그래프 DB로 유명한 Ontotext에서 작정하고 글을 작성했습니다. 단발성 자료가 아닌, 지속성이 있는 자료로써 지식그래프 접근장벽을 낮추기 위해 기술 마케팅의 일환으로 작성되는거 같네요.
본 포스팅에서는 금융 분야에서 지식그래프 활용 방안 그리고 케이스 스터디를 통해 지식그래프의 가치를 전달합니다. 검색기능향상, 리스크 관리 , 지식 추론 , 데이터 상호운용성 , 지식 표현 등 여러 케이스에 대한 짧고 구체적인 오버뷰와 함께 글이 작성되어 있으니, 지식그래프에 대해 심도있는 기반지식이 없다 하더라도, 읽기에 별 무리가 없어보이네요.