8월 3주차 그래프 오마카세


On the initialization of graph neural networks
[https://www.amazon.science/publications/on-the-initialization-of-graph-neural-networks]
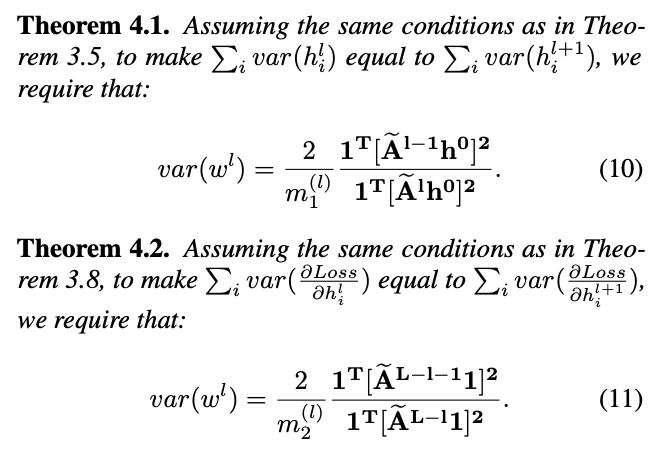
Introduction
딥러닝의 핵심은 label 이 학습됨에 따라, 그 변동되는 weight 를 어떻게 잘 관리하느냐 라고 할 수 있습니다. 이 관리하는 방법을 살펴보면 다양한데요. Epoch, intilization function, activation function, learning rate, optimizer 등 여러 파라미터들이 복합적으로 작용하며 weight를 업데이트합니다. 그런데 여기에서, graph data는 타 데이터들과 다르게 edge , path 를 통해 weight 가 전달되는 message passing 이 있기에 상호작용에 좀 더 유념하여 weight가 업데이트 되는데요. 그렇다면 이것에 적합하게 업데이트되는 적절한 파라미터 설계가 필요하지 않을까? 라는 생각이 한두번씩 들었을 겁니다.
본 논문은 graph data structure 에 특화된 weight initalization function을 제안하여, 앞서 언급한 graph data에 특화된 파라미터가 필요함을 주장하고, 실험으로 증명해냅니다.
Preliminiary
[what initalization function roles in deep learning?]
In deep learning, an initialization function plays a crucial role in setting the initial values of the parameters (weights and biases) of neural networks before training begins. Proper initialization can significantly impact the convergence speed and overall performance of the network during the training process.
The primary objectives of initialization functions are:
- Avoiding Vanishing/Exploding Gradients: Deep networks are prone to vanishing and exploding gradient problems, where gradients become extremely small or large as they are propagated through layers. Poor initialization can exacerbate these issues, leading to slow convergence or divergence during training.
- Accelerating Convergence: Proper initialization can help gradients flow effectively through the network, leading to faster convergence. When the initial values are well-scaled, the network can start learning meaningful representations from the beginning of training.
- Stabilizing Learning: Initialization techniques can contribute to stable training dynamics. Networks that start with well-initialized weights tend to exhibit more consistent and predictable learning behavior.
Some commonly used initialization techniques include:
- Zero Initialization: Setting all weights and biases to zero is not recommended as it can lead to symmetric activations and gradients, causing the network to learn identical features and suffer from the vanishing gradient problem.
- Random Initialization: Assigning small random values to weights can help break the symmetry problem. However, these values should not be too large or too small, as this can lead to exploding or vanishing gradients.
- Xavier/Glorot Initialization: This initialization method takes into account the number of input and output units in a layer. It sets the initial weights using a Gaussian distribution with mean 0 and a variance that's inversely proportional to the sum of the number of input and output units. This helps balance the scale of activations and gradients.
- He Initialization: Similar to Xavier initialization, He initialization adjusts the variance based on the number of input units. It's specifically designed for networks that use ReLU (Rectified Linear Unit) activation functions.
- LeCun Initialization: This initialization is similar to Xavier but takes into account only the number of input units, making it more suited for networks with specific activation functions like the hyperbolic tangent.
- Orthogonal Initialization: This method initializes the weight matrix with orthogonal or unitary matrices. It's particularly useful for recurrent neural networks (RNNs) to prevent the exploding gradient problem.
Summary
논문을 보시면 수식이 한가득입니다. Figure가 없고, theorem lemma assumption 이 한가득인 논문인데요. 거부감이 들었을수도 있습니다. 하지만, 차근차근 따라가다보면 결국 본 논문에서 핵심은 2가지라고 보면 되겠는데요. 첫번째는, 왜 initalization이 중요한지에 대해 설명하기위해 first variance , seconde variance decomposition 합니다. 여기에서 말하는 variance 는 weight 값에 대한 variance 인데요.
weight layer 통해 정보가 어떻게 흘러가고, 그래디언트가 어떻게 계산되고, 활성화가 어떻게 분배되는지에 영향을 미치기 때문에 variance 분포를 잘 파악하여 weight 업데이트 전략을 수립하는게 굉장히 중요합니다. 가중치의 variance를 제어하는 적절한 초기화 방법을 선택하면 더 빠른 수렴, 안정적인 훈련 및 딥 러닝 아키텍처의 전반적인 성능 까지를 기대할 수 있습니다.
다시 돌아와서, initalization 중요성을 언급하기 위해선 먼저 initalization 대상인 weight 가 GNN 에서 그간 어떻게 업데이트되었는지 살펴볼 필요가 있습니다. 그래서 section 2,3 에서 그 업데이트에 대한 개괄을 설명합니다. 이 후, 결국 graph structure, message passing 를 고려치 않으면 weight 가 불안정하게 업데이트 되므로, gradient explode 혹은 vanishing 이 일어나기에 이를 안정화가 필요하다 라는 문제를 제기합니다.
문제를 해결하기 위해서 본 논문의 저자는 stability 를 위해 3가지 요소 constant , m1 , m2 를 도입합니다. 이를 통해 input feature , graph structure 의 정보를 적절하게 weight 에 반영할 수 있는 variance 를 유도합니다.
Takeaway
딥러닝의 기초인 initalization function에 대해 공부하시는 분들에게 굉장히 유용할거같습니다. 특히, GNN 관점으로 접근한 논문은 처음 보았는데요. 그래프 데이터 특성에 맞게 딥러닝 아키텍쳐 파라미터를 조정하여 성능향상까지 이루는 그 흐름이 너무 재밌었던 논문이였습니다.
Eng version.
How PayPal Uses Real-time Graph Database and Graph Analysis to Fight Fraud
Kor version.
[https://yozm.wishket.com/magazine/detail/1287/]
저번 오마카세에선 Linkedin 에서 social graph 를 위해 graph engine 을 만드는 과정에 대해 다루어보았는데요. 이번엔 PayPal 에서 Fraud detection 을 위해 graph engine 을 만들고, 어떤식으로 활용하는지 case study 까지 다룬 포스팅을 준비해봤습니다.
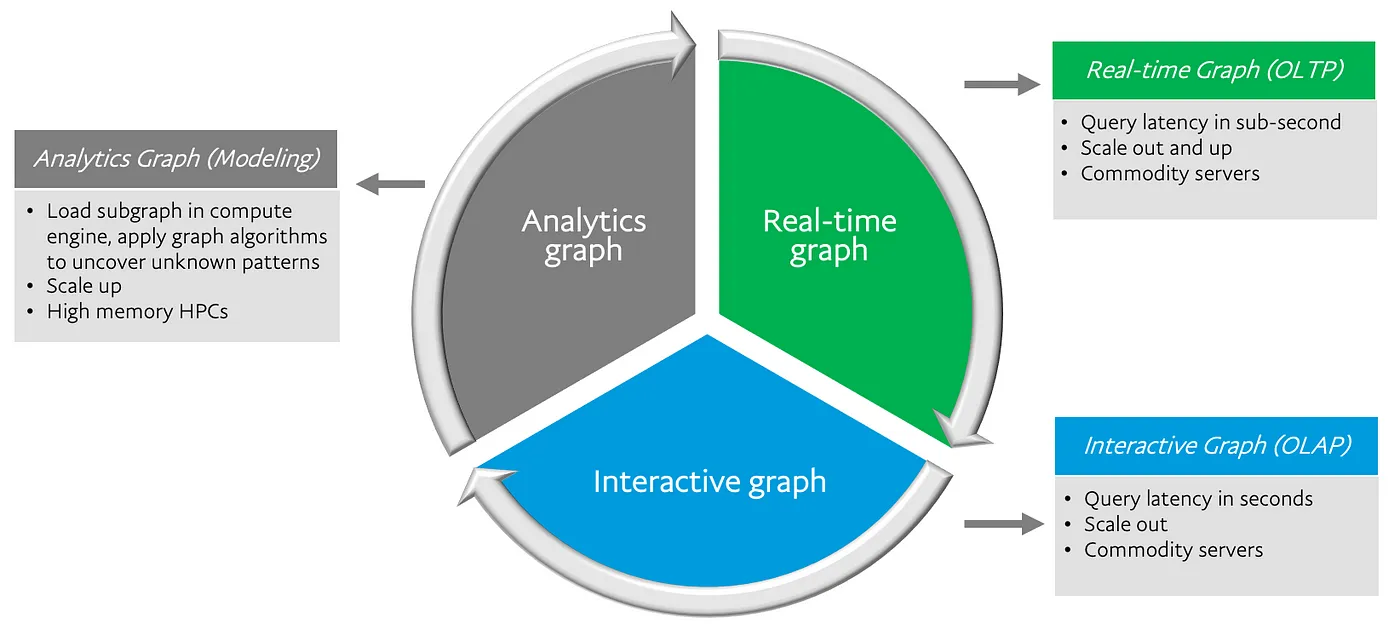
게시물에서는 graph usage 를 크게 Analytics , Real-time, Interactive 3가지군으로 나누어 설명합니다. Subgraph 를 추출해서 분석하여 pattern 을 발견하는 Analytics Graph, 실시간으로 발생하는 데이터를 다루기 위한 OLTP 형태 Real-time Graph, graph pattern 을 시각적으로 표현하여 현상에 대해 직관적으로 이해하는 OLAP 형태 Interactive graph.
그럼 여기에서는 왜 graph 를 접목하려할까요? 그 이유는 다른 GDB 장점 게시물들에서 말한것과 유사합니다. 연결을 효율적으로 디자인해서 분석에 적용할 수 있다 라는게 그 이유라고 포스팅에서 언급합니다. 하지만, 본 포스팅은 여태까지 살펴본 GDB with FDS 주제의 게시물과는 다르게 연결을 효율적으로 디자인하는 그래프 모델링에 대한 중요성을 언급합니다.
바로, OLAP 와 OLTP 모두 query pattern 에 의존하기 때문에 데이터를 조회하고 분석하는 과정에서 조회 분석 대상인 graph 가 어떻게 설계되었는지에 따라 발견하는 인사이트가 다르기에 중요하다 라고 이야기합니다. 제가 여러분에게 본 포스팅을 여러분과 공유하고 싶다 라고 마음을 먹었던 부분인데요. 저희가 흔히 접하는 graph benchmark 데이터들은 대다수가 모델링이 되어 있는 상태에서 ML 을 적용하기 때문에, 그래프 모델링에 대해 고민하지 않아도 됩니다. 하지만, 실제 산업계에서 마주하는 데이터들은 대다수가 정제가 되어있지 않은 상태이기때문에, 어떤식으로 연결을 맺어줄지가 관건인데요. 그 핵심 포인트를 본 포스팅에서 언급합니다.
그래프 모델링이 되어있다면, 2가지 방식으로 분석을 진행하는데요. 1. discrete graph analysis , vertices (node)에 대해 집중하여 해당 노드 기반으로 연결된 여러 노드를 분석하며 연관되어 있는 노드들에 대한 정의를 해가는 것. 2. connected graph analysis algorithm, 빈도가 높은 path 등 path 에 대한 정성적인 현상을 정량화 하는것. 이 두가지 방식을 통해 그래프 분석을 진행합니다.
그래프 분석 하기에 앞서 이러한 분석을 하기 위해 데이터를 저장하고 불러오고 하는 일련의 read write 과정을 하기 위한 DB 가 필요한데요. paypal 에선 다음 요건들을 충족해야한다고 이야기합니다.
- Customizable high performance query APIs
- Sub-second level query latency and optimization
- Seconds level data freshness (near real-time update)
- Horizontal scalability with fault tolerance
- Million QPS (query per second) throughput
- Flexible data backfill from offline to online
- Compliant to PayPal’s data security and privacy requirements
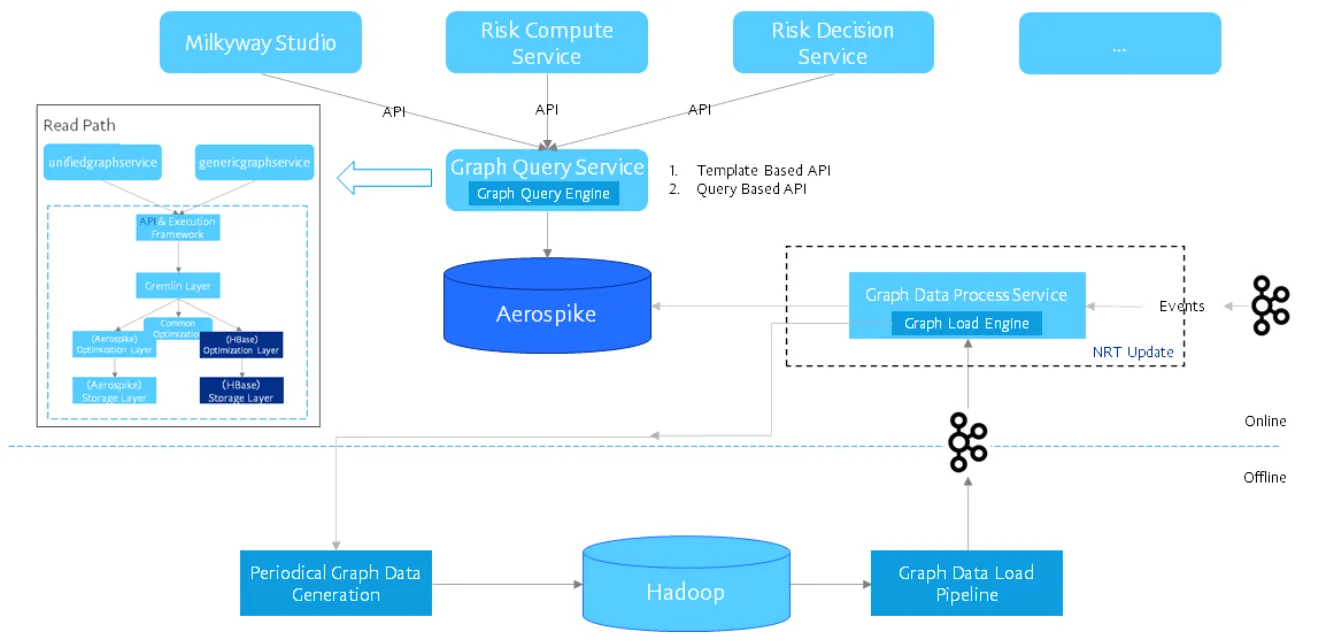
Read & Load Path , Query engine , Aerospike , Hadoop 이 중 Aerospike 에 대해 낯설었던 저였기에, 간단히 리서치해본바로는 , redis 와 동일하게 nosql key-value opensource db 라고 합니다. 여기에서 핵심은 online , offline 간의 data ingestion interaction인데요. Offline 에서는 hadoop 을 , Online 에서는 Aerospike를 사용한다는 것을 유념하시면 좋을거 같습니다. 실시간 graph db를 구축하기 위해 고민하시는 분들에게 많은 도움이 될 아키텍쳐라 생각이 되네요.
끝으로, case study 를 통해 paypal 에서 만든 graph db 가 어떤식으로 작용할지에 대한 이야기를 합니다. 간단하게 fraud ring 을 탐지하는것에 대한 이야기입니다. PayPal risk model 에서도 마찬가지로 graph feature 를 사용하고 이 포스팅 이외에도 어떻게 graph 딥러닝을 scalbility 하게 적용할지에 대해서도 다룬 포스팅이 있는 등 그래프 기술개발에 진심이라는 것을 보고 굉장히 놀랬습니다. 역시, 국가 가릴것없이 어떻게 Fraud 를 detection 하는지에 대해 Graph 를 사용하는게 대세인가보네요.