8월 4주차 그래프 오마카세


KHAN: Knowledge-Aware Hierarchical Attention Networks for Accurate Political Stance Prediction
[https://arxiv.org/pdf/2302.12126.pdf]
Introduction
풍요로운 정보속에서 유의미한 정보에 대해 분별하는 기술이 핵심역량으로 되어가고 있는 요즘입니다. 과도한 정보가 오히려 독이 되어 무언가에 대해 판단할 때, 확신이 생길 때까지 정보들을 분석하느라 의사결정이 늦춰지는 경우가 발생하고 있습니다. 주방장 같은 경우도 제가 생각하는 기준에 부합하는 정보들이 연달아 나온다면, 그제서야 그 정보가 맞다 라는 확신을 하고 의사결정을 내리곤합니다.
여기에서 이 ‘연달아 나온다’ 라는 것을 자세히 생각해보면 함정이 있습니다. 바로 정보 검색편의를 위해 만든 ‘알고리즘’이 유저가 원하는 정보만을 제공하기 위해 니즈를 빠르게 분석해, 그에 맞는 결과들을 제공한다는 함정인데요. 말그대로 ‘편의’가 있긴하나, 편향성에 갇힐 위험이 있습니다.
이 편향성 긍정적인 면도 있겠으나, 부정적인 면도 존재하는데요. ‘뉴스’ 도메인에 접목해서 생각해보겠습니다. 특정 정치 성향에 맞는 뉴스정보들만 보게된다면 어느 한쪽 정치 성향에 대한 편향이 극도로 높아지며, 타 정치 성향 관련 이야기에 대해 반감이 생길 가능성이 큽니다. 즉, 다른 정보에 대한 수용성이 낮아지는거죠.
본 논문에서는 이러한 사회과학적인 현상에서 발생하는 문제들을 해결해보고자 지식그래프와 자연어처리 모델을 혼합하여, 특정 뉴스 아티클의 정치성향에 대해 예측하는 알고리즘을 개발했습니다. labeling 을 위해 미국 left, right 정치 성향 커뮤니티에서 대략 50여만건의 포스팅 데이터를 수집 및 정제하여 지식그래프로 만들었다는게 매우 흥미롭습니다.
Preliminary
[Echo Chamber and Filter Bubble, knowledge graph pros in that problem solution]
An echo chamber refers to a situation in which individuals or groups are exposed only to information, opinions, or ideas that align with their existing beliefs or perspectives. In other words, people in an echo chamber are surrounded by content that reinforces their preexisting views, creating a self-reinforcing cycle. This can lead to a narrowing of perspectives, limited exposure to diverse viewpoints, and an overall lack of critical thinking and open dialogue.
A filter bubble, on the other hand, is a phenomenon that occurs when algorithms and online platforms use personalized content recommendations based on an individual's past behavior, preferences, and online interactions. This results in users being exposed primarily to content that reinforces their existing interests and preferences, while other perspectives or information outside of their filter bubble are filtered out. This can lead to a skewed perception of reality, reduced exposure to diverse opinions, and even polarization.
Problems in Society:
Both echo chambers and filter bubbles can contribute to several societal issues:
- Polarization: Echo chambers and filter bubbles can intensify ideological divides by reinforcing existing beliefs and limiting exposure to differing perspectives. This can lead to increased polarization and a lack of understanding between different groups.
- Misinformation: When people are exposed only to information that confirms their existing beliefs, they may be more susceptible to accepting and spreading misinformation that aligns with those beliefs.
- Decreased Critical Thinking: Limited exposure to diverse viewpoints can hinder critical thinking and the ability to engage in meaningful discussions. People may become less open to considering alternative ideas or evaluating their own beliefs.
- Stagnation of Ideas: Echo chambers and filter bubbles discourage intellectual growth and the exchange of innovative ideas, as individuals are less likely to encounter new information that challenges their current understanding.
Advantages of Injecting Knowledge Graphs:
Integrating knowledge graphs into language models like GPT-3 offers several advantages:
- Contextual Understanding: Knowledge graphs provide structured information about entities, their relationships, and attributes. This additional context can help language models generate more accurate and relevant responses by grounding their understanding in real-world facts.
- Improved Fact-Checking: Knowledge graphs enable language models to cross-reference information against a structured database of verified facts, reducing the likelihood of generating or propagating misinformation.
- Diverse Information Sources: By incorporating data from a knowledge graph, language models can access a wider range of perspectives and information, helping to counteract the effects of echo chambers and filter bubbles.
- Enhanced Reasoning: Knowledge graphs can aid in logical reasoning and inference. Language models can use the structured information in the graph to generate more coherent and contextually appropriate responses.
- Personalization with Responsibility: While personalized recommendations can contribute to filter bubbles, knowledge graphs allow for a more responsible approach to personalization. Algorithms can use the knowledge graph to balance personalization with diverse information exposure.
Summary
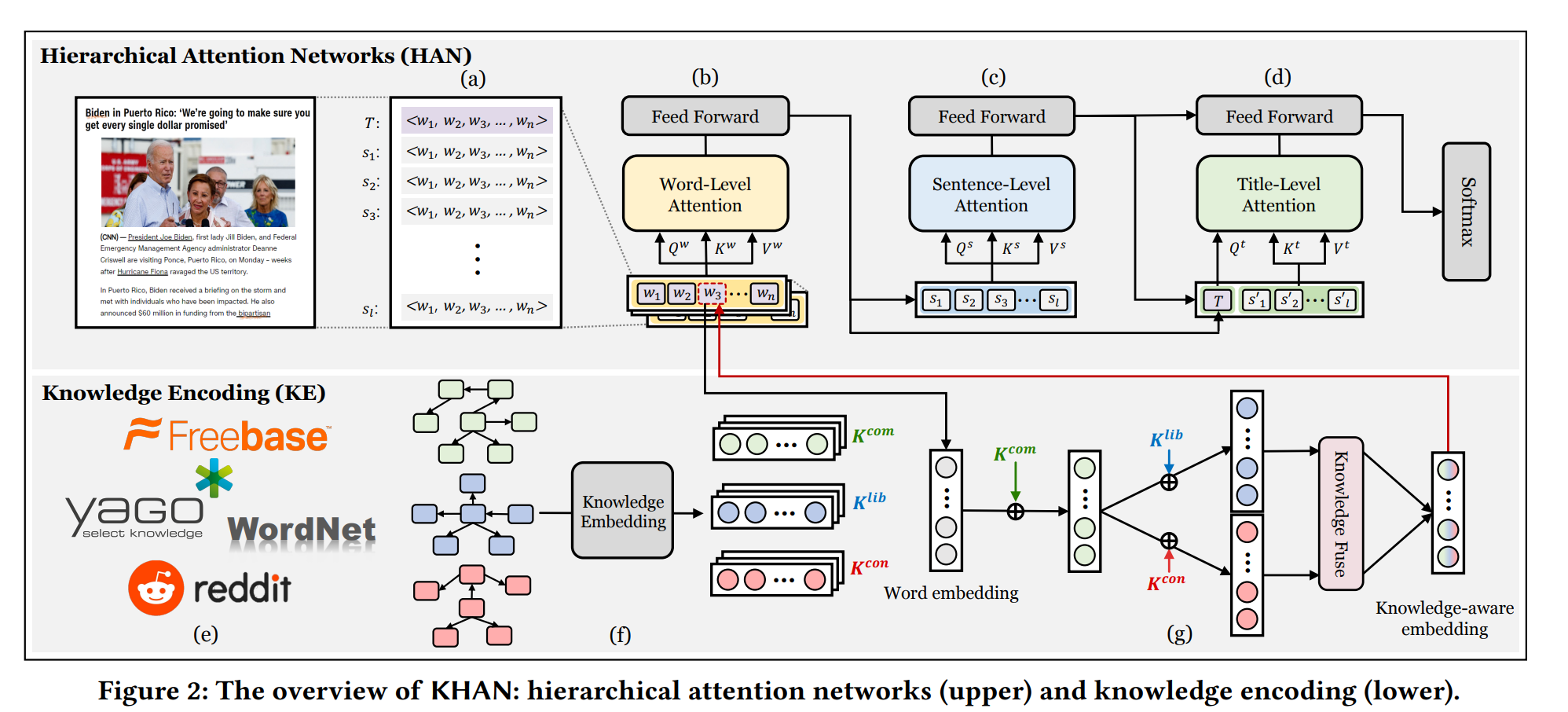
아키텍쳐는 크게 2가지로 나뉩니다. 뉴스 아티클 콘텐츠를 분석하기 위한 HAN 모델, 아티클에 있는 정보가 어떤 정치 성향에 가까운지에 대해 판단 기준에 대한 근거를 정량화해주는 KE 모델. 기존 자연어처리 모델에서는 해당 시점에서 게시물을 기반으로 게시물 성향을 판단하기에, 내생 변수 의존성이 강했습니다. 본 아이디어는 외생 변수인 지식 그래프를 추가하여 그 한계점을 극복한다는데에 의의를 둡니다.
Hierarchical Attention Networks(HAN) : Hierarchy level embedding ( word, sentence and title)
기사 콘텐츠는 크게 3가지 요소로 분리할 수 있습니다. 단어, 문장 그리고 기사 콘텐츠의 제목.여기엔 위계가 존재합니다. 단어들이 모여 문장이 되고, 문장들이 모여 문단이 되고, 문단을 대표하는 핵심 메세지가 기사 콘텐츠의 제목이 됩니다. 이처럼 위계가 존재하는 포스팅에 대한 현상을 정량화 하기 위해 HAN을 활용합니다.
Knowledge Encoding(KE) : Knowledge graph build and injection.
앞서 언급한 HAN 에서 ‘단어’들에 대한 표현에 지식 그래프의 임베딩 값을 입히는 단계입니다. ‘아’ 다르고 ‘어’ 다르다 라는 말이 있듯이, 각기 다른 정치성향의 커뮤니티에서는 특정 단어를 긍정적 혹은 부정적으로 보곤합니다. 이를 NER(Named-entity recognition) 기술을 활용하여 , 관계를 발생한 후, 지식그래프로 만들어줍니다. 이후 지식그래프 임베딩 모델을 활용하여 도출된 정량화 값을 HAN word embedding layer 보완재로 씁니다.
Takeaway
지식그래프가 자연어에 어떤 방식으로 정보를 증가할 수 있는지를 중점적으로 보시는걸 추천드립니다. 추가로, ablation study3의 결과를 보면 지식 그래프를 단어, 문장 그리고 타이틀 각각에 적용했을때, 모두 적용한 것 보다 ‘단어’에만 적용한 값이 오히려 성능이 가장 높음을 확인할 수 있습니다. 이를 통해, 정보가 많다고 좋은것이 아닌, 즉 지식그래프를 모두 활용하는게 만능이 아니라 특정 문제에 맞게 조정하여 적용하는게 중요하다 라는 인사이트를 가져가시면 좋을거 같네요.
Designing Highly Scalable Graph Database Systems without Exponential Performance Degradation
[https://dl.acm.org/doi/pdf/10.1145/3579142.3594293]
Introduction
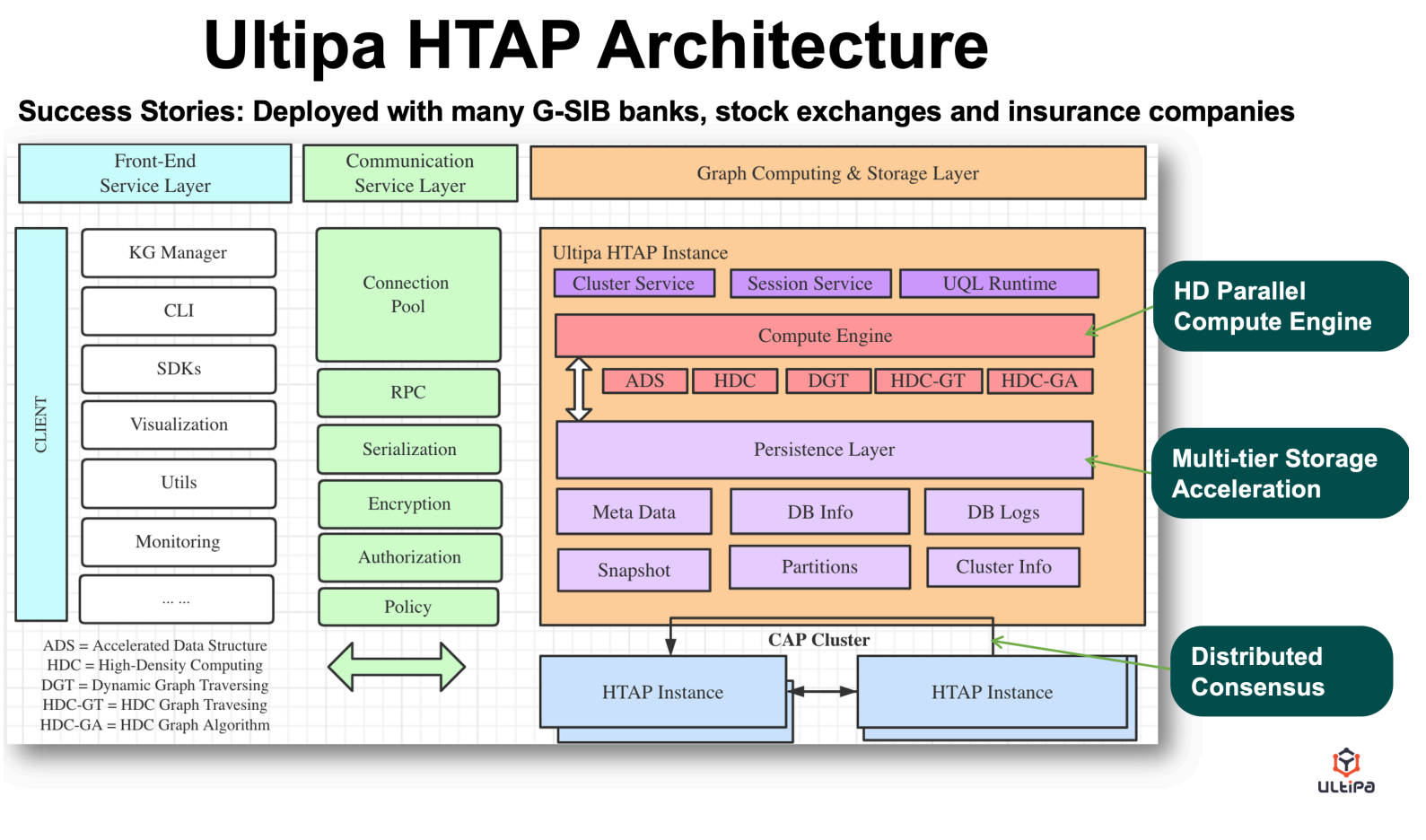
Ultipia 라는 회사에서 작성한 논문을 소개합니다. ‘GDB 불가침영역이였던, Scability 그리고 real-time query 모두 다 된다.’ 라는 느낌 Table1에 3개의 school로 나누어 표현해놓았어서 굉장히 인상깊었습니다.
High-density Parallel Computing , Vector Computing , Dynamic Pruning 그리고 Super-linear performance 4가지 특징이 핵심인 GDB 입니다. 가장 눈에 띄는 특징은 Vector Computing 입니다. 기존 GDB storage 에서 사용하고 있는 linked list , adjacency matrix 구조가 meta-data 를 표현하는데엔 너무 늦으니, 이를 vector 데이터 구조를 차용하여 적용합니다.
K-hop query search 시, 분할정복을 구현하여 initialized node 부터 hop을 거쳐가며 concurrency 를 활용한다고 합니다. 그 결과 K-hop experiment에서 타 GDB (tigergraph, neo4j JanusGraph, ArangoDB) 에 비해 월등한 성능을 보여줍니다. 이런 성능 실험표를 볼 때마다, 실험에 과연 튜닝이 적용되었을까?라는 의문이 들긴합니다. 이외에도 Proxy/Nameserver/Grid or Federation , Automated Shard 아키텍쳐에 대해 예시와 함께 작성해두었습니다. 굉장히 흥미로운 내용이 가득하기에, GDB에 관심있으신분들은 꼭 일독해보시는걸 추천드립니다 🙂
GUG 2nd Seminar에서는 Ultipia GDB 세션이 기획되어 있습니다. GDB에 대한 궁금증이 있는 분들께는 이번 기회를 놓치지 마시길 추천드립니다. 이 세션에서는 해당 아키텍처를 개발한 전문가와 직접 만나 볼 수 있을 뿐만 아니라 아키텍처에 대한 자세한 설명을 들을 수 있습니다. 또한 질의응답 시간을 통해 GDB에 대한 깊은 통찰을 얻을 수 있을 것입니다. 만나고 배우며, GDB의 혁신적인 기능과 장점을 직접 체험해보세요!
** 논문이 아닌, 캐쥬얼한 내용을 보고 싶으신분은 [https://www.ultipa.com/article/technical/the-evolution-of-graph-data-structures] 를 참조하시면 비슷한 내용을 확인하실 수 있습니다.
위 내용에서 Native graph storage에 대해 언급했습니다. 이에 대해, 보면 좋으실 포스팅이 있어 핵심 내용만 간단히 가져왔습니다. 원글은 링크를 통해 접속하실 수 있습니다.
[what is the native graph storage?]
from neo4j posting
What’s Special About Native Graph Storage and Processing
Native graph processing refers to how a native graph database processes database operations, including both storage and queries. A key capability of a native graph database is the ability to navigate through the connections in the data quickly – without the overhead of index lookups or other join strategies. This capability to traverse the related data without the overhead of an index lookup for each move across a relationship is something we call index-free adjacency.
Non-native graph processing often needs to use index lookups to get to the next element in a chain for completing a read or write transaction; this may be okay with just one or two relationships, but in today’s use cases with hundreds or thousands, it won’t work. The complexity of an index lookup is often O(log(n)) versus the O(1) for following a direct pointer of the relationship to a target node.
Graph storage refers to the underlying structure of the database that contains graph data. When built specifically for storing graph-like data, it is known as native graph storage. Graph databases with native graph storage are optimized for graphs in every aspect, ensuring that data is stored efficiently by using storage layouts that co-locate nodes and relationships close to each other.
Graph storage is classified as non-native when the storage comes from an outside source, such as a relational, wide-column, document, or other NoSQL databases. These databases store data about nodes and relationships as unrelated entities, which may end up far apart and disconnected in actual storage. Just as with processing, non-native graph storage doesn’t meet the performance and scale needs of modern applications.
Let’s look closer at why native graph storage and native graph processing are so critical.
Native Graph Storage: Optimized For Connected Data
What makes graph storage distinctively native is the architecture of the graph database from the ground up. Graph databases with native graph storage have underlying storage designed specifically for the storage and management of graphs. They are designed to maximize the speed of traversals during arbitrary graph algorithms.
For example, let’s take a look at the way Neo4j – a native graph database – is structured for native graph storage. Every layer of this architecture – from the Cypher query language runtime to managing the store files on disk – is optimized for storing and querying graph data, and not a single part is sitting on top of other non-graph technologies.
In a native graph database, a node record’s main purpose is to simply point to structured lists of relationships, labels, and properties, making it a lightweight record.
So, what makes non-native graph storage different from storage in a native graph database?
Non-native graph storage uses a relational database, a columnar database, or some other general-purpose data store rather than being specifically engineered for the requirements of graphs. They would store nodes and relationships in their native data paradigm (e.g. as tables or documents).
While the typical operations team might be more familiar with a non-graph backend (like MySQL or Cassandra), the disconnect between graph data with non-graph storage results in a number of performance and scalability concerns.
Non-native graph databases are not optimized for storing graphs, so the algorithms utilized for managing data need to update or read nodes and relationships all over the place. This then also causes performance problems at the time of retrieval because all these nodes and relationships have to be reassembled for every single query. In a 24×7 production scenario, that could be thousands of queries per second.
On the other hand, native graph storage is built to handle highly interconnected datasets from the ground up and is therefore the most efficient when it comes to the storage and retrieval of graph data.
Native Graph Processing: Index-Free Adjacency
A graph database has native processing capabilities using index-free adjacency. This means that each node directly references its adjacent (neighboring) nodes, meaning that accessing relationships and related data is simply a memory pointer lookup. This makes native graph processing time proportional to the amount of data processed, not increasing exponentially with the number of relationships traversed and hops navigated.
Without index-free adjacency, a large graph dataset will be crushed under its own weight because queries take longer and longer as the dataset grows. On the flip side, native graph queries perform at a constant rate based on the amount of data they touch, no matter the total size of your data.
Since graph databases store relationship data as first-class entities, relationships are easier to traverse in any direction. With processing specifically built for graph datasets, relationships – rather than over-reliance on indexes for joins – are used to maximize the efficiency of traversals.
See the image below of a basic social network where queries are performed on the natively stored relationship data (who is connected to whom?) without further index lookups.
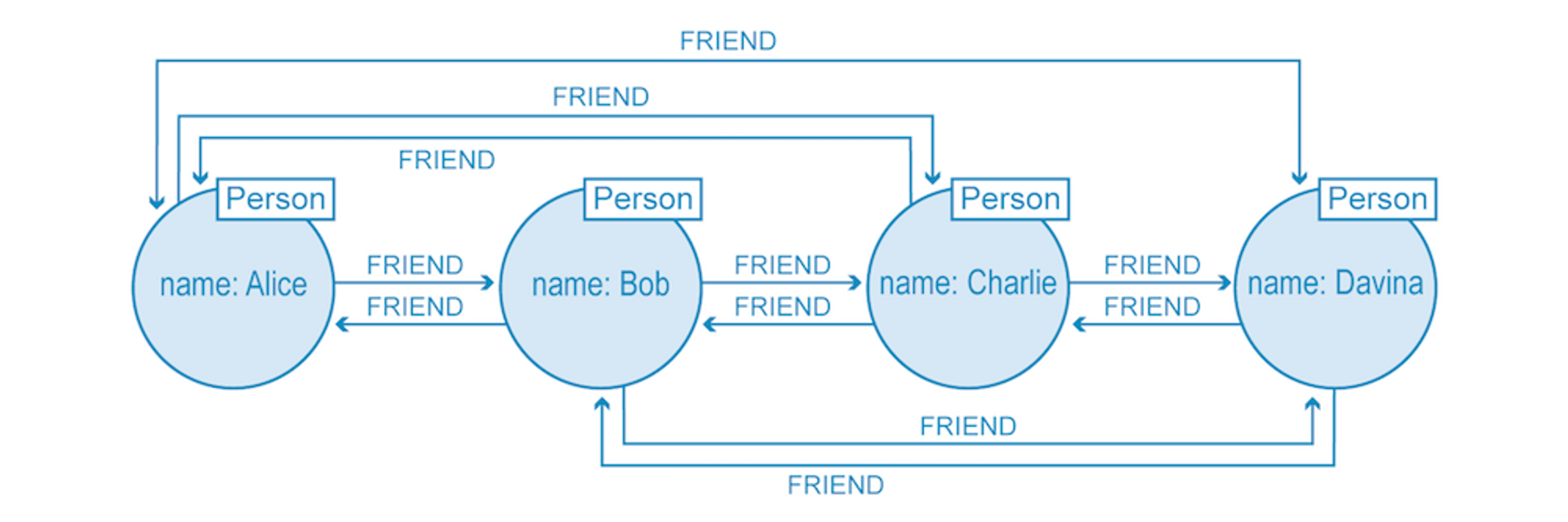
On the other hand, non-native graph databases use many types of indexes to compute the joins to link entities together. This method is more costly, as the indexes add another layer to each read and write, which slows processing considerably.
Queries with many more than one level of connection (i.e., the very type of query you’d want or need from a graph database) further reduce traversal performance with non-native graph processing.
The image below illustrates an example of a non-native graph query looking up just one level of connection (in a many-to-many relationship), each connection computing two index lookups – imagine how much the processing complexity grows as you query across more hops.
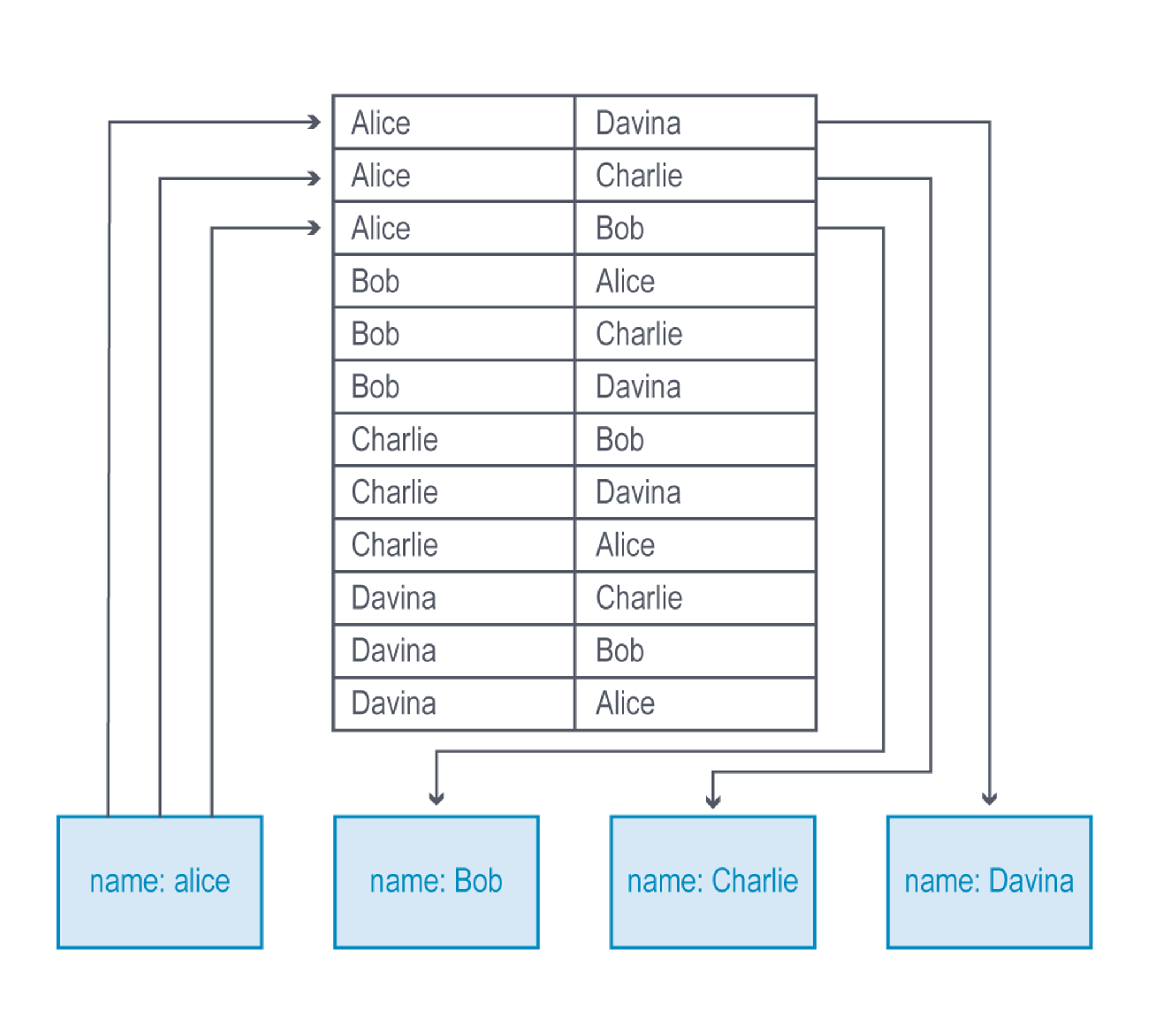
In addition, reversing the direction of a traversal is extremely difficult with non-native graph processing.
To reverse a query’s direction, you must either create a costly reverse-lookup index for each traversal or perform a brute-force forward search through the original index. Both of these workarounds will get you the result you’re looking for – eventually – but they defeat the purpose of using a graph database to begin with: to efficiently query relationships in your data.
The Bottom Line: Why Native vs. Non-Native Matters
When deciding between native and non-native graph databases, it is crucial to understand the tradeoffs of working with each.
Non-native graph technology usually has a persistence layer that your development team is already familiar with (such as Cassandra, MySQL, or another relational database), and when your dataset is small or less connected, choosing non-native graph technology isn’t likely to significantly affect the performance of your application.
However, our world is becoming increasingly connected, and data is a representation of our world. Your data is quite likely to become more connected over time. Even if your dataset is small to begin with, it’s important to plan for the future. In this case, a native graph database serves you better over the long term since the performance of non-native graph processing crumbles with larger, more connected datasets.
Not all applications require low latency or processing efficiency, and in those use cases, a non-native graph database might just do the job. (Really though, would you really use a graph database in these cases?)
But if your application requires storing, querying, and traversing large interconnected datasets in real time for a 24×7, always-on, mission-critical application (such as fraud detection, real-time recommendations, supply chain management, etc.), then you need a database architecture specifically designed for handling graph data at scale.
The bottom line: The importance of native vs. non-native graph technology depends on the particular needs of your application, but for enterprises wanting to leverage their connected data, native graph database technology is critical for success.
Target AutoComplete: Real Time Item Recommendations at Target
[https://tech.target.com/blog/target-autocomplete]
Real-Time Personalization Using Microservices
[https://tech.target.com/blog/real-time-personalization]
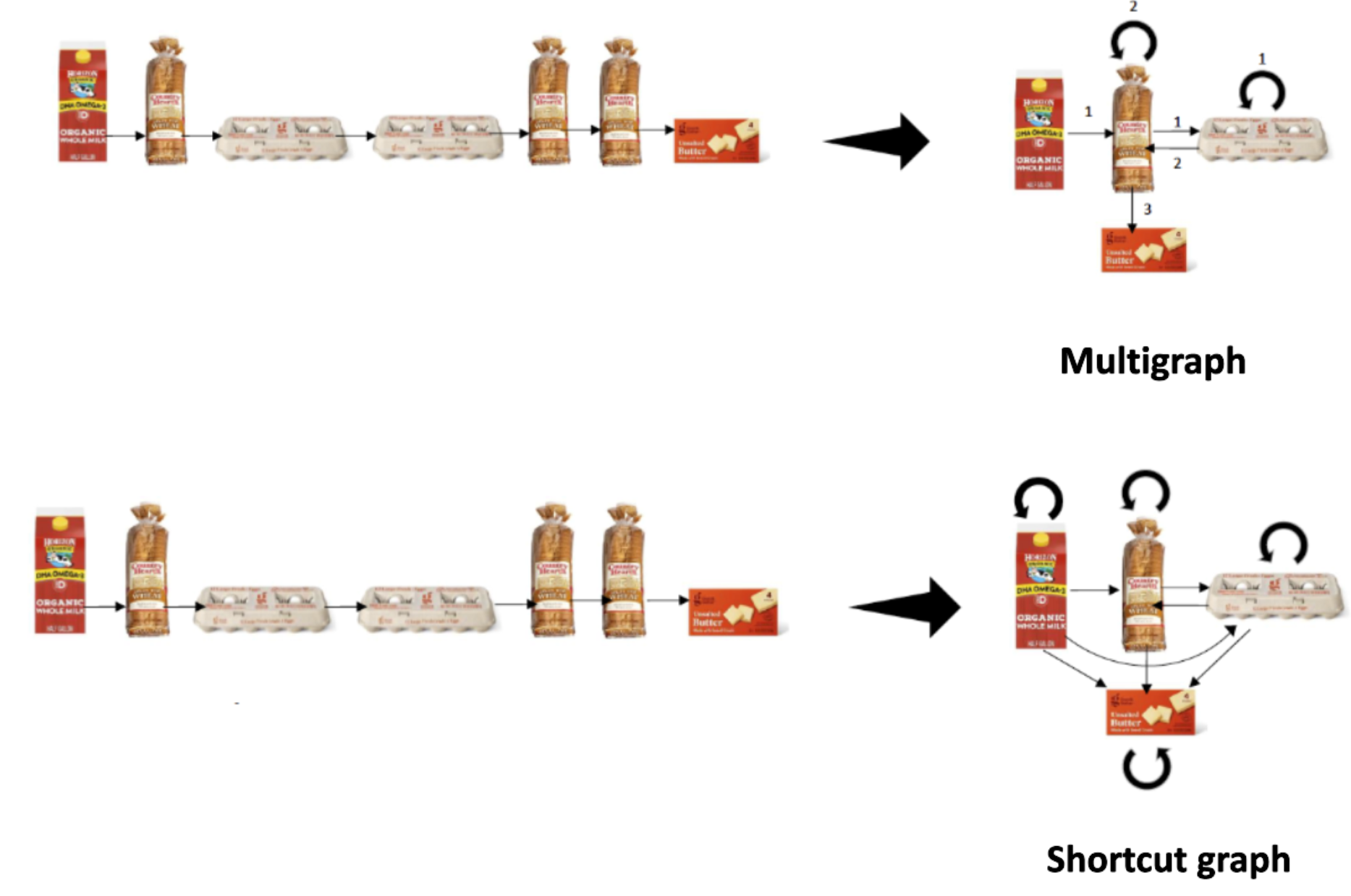
Target 이라는 리테일 기업에서 어떤식으로 개인화 추천 시스템을 구현하는지 그리고 그 기술을 어떻게 실시간에 근접하게 결과를 볼 수 있게끔 구현했는지에 대한 내용을 준비해보았습니다. 두 게시물을 연달아 소개드리는 이유는 ‘그래프를 활용해 유저 세션 추천에 대한 설계 방식’ 그리고 ‘실시간 추천을 실현 가능하게끔 설계한 아키텍쳐’ 가 인상 깊었기 때문입니다.
먼저 처음 게시물에서는, 세션 추천을 위해 그래프를 활용합니다. Multigraph 와 Shortcut graph 개념을 적용합니다. 각각 짧은 주기 , 긴 주기에 대한 유저 행동을 반영하고자 이렇게 나누었다고 하네요. 기존 방법과는 다르게 cumulatively 하게 **추천을 할 수 있다. 라는게 그래프를 적용한 이유라고 합니다. 예시를 들어보겠습니다. ‘Milk’가 담겨있는 장바구니에서 ‘Egg’라는 물품이 추가로 장바구니에 들어왔을시, ‘Egg’에만 연관되어 있는 아이템을 다음에 추천하는게 기존 방식이였다면, 그래프는 ‘Milk’ , ‘Egg’를 모두 고려한 아이템을 추천할 수 있게끔 관계에 추가 가중치를 부여해준다고 합니다. 이렇게 설계한 모델을 A/B test에 적용해보았을때, lift 기준으로 많은 향상을 이루었다고 하네요.
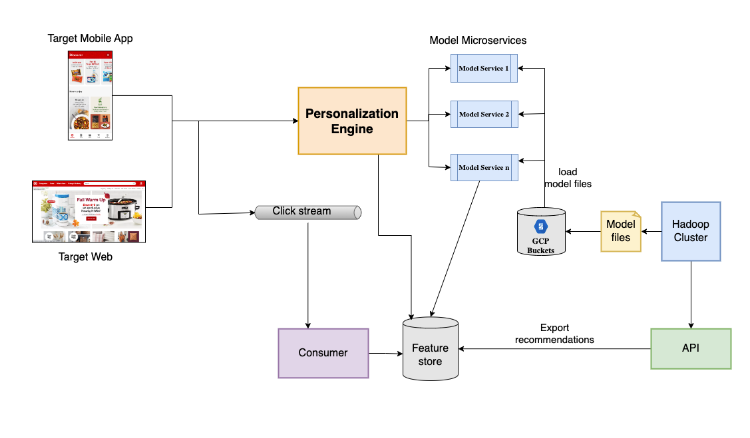
다음 게시물은 아키텍쳐입니다. 특히 , request 와 traffic 이 증가할 때, 실시간으로 어떻게 이를 관리할지에 대해 언급합니다. Model Microservice 레이어에서 모델 파일과 엔진의 결과값을 기반으로 feature 를 관리하고 추천까지 진행합니다. 각 microsevrice 들의 SLA(service level agreement) 값이 50ms latency for an average throughput of 100tps 라고 할 정도니, 실시간성에 근접한 latency 를 가지지 않았을까 싶네요. 그 비결이 무엇인지 궁금하시다면 두번째 게시물을 확인해보시는걸 추천드립니다. 양이 짧으나, 미사여구가 적고 숫자로 그 결과들에 대해 이야기합니다.
'GUG Conference 개최를 준비 중입니다. 이번 행사에서는 특별하게 포스터 세션을 마련할 예정입니다. 여러분께서 진행 중이거나 현업에서 그래프를 적용하고 있는 연구나 경험을 공유하고 싶다면 아래의 Gmail로 연락 주시기 바랍니다.
NIPA의 지원을 받아 진행되기 때문에, 포스터 인쇄비용은 전액 지원됩니다! 여러분의 흥미로운 아이디어, 연구, 그리고 경험을 기다리고 있겠습니다.
추가로 연사분들도 모집하고 있기에, 관심있으신분들도 아래 메일로 연락 부탁드립니다 !
** 소정의 연사비가 지급될 예정입니다 :)
=========================================================
=========================================================