8월 5주차 그래프 오마카세


Paper on graph database schemata wins best-industry-paper award
[https://www.amazon.science/blog/paper-on-graph-database-schemata-wins-best-industry-paper-award]

그래프 모델링에 대해 궁금하신 분들께서 보시면 좋을 콘텐츠 입니다. LPG(label property graph)에 대한 개요부터 PG-schema 까지. 그래프 schemata 를 위해 어떤식으로 접근하고 발전되어가고 있는지에 대해 본 포스팅에서 다룹니다. 주방장도 늘상 그래프 모델링의 중요성을 언급했지만, 그래프 모델링(schemata)의 변천사에 대해서는 모르고 있었는데요. No schema , Flexibility , Partial 그리고 Schema first 까지 복잡한 그래프 데이터를 ‘잘’ 보관하기 위해 어떤 개선 그리고 고민들이 있었는지에 대해 이야기합니다. 추가로, 현재 기준 가장 적합하다 판단된 그래프 schemata 에 대해서도 다루니, 현 트렌드에서 어떤 그래프 schemata 가 SOTA 인가? 라는 궁금증이 있으셨던 분들이 보시면 도움되실겁니다.
GraphFM: Improving Large-Scale GNN Training via Feature Momentum
[https://arxiv.org/pdf/2206.07161.pdf]

Large-scale GNN, 늘 마주치는 OOM 그때마다 줄여가는 batch-size 등 하이퍼 파라미터. 한번쯤은 겪어보셨을 문제들이라 생각합니다. 이번 논문에서는 batch 를 기반으로 줄였을시, 발생하는 문제와 그 문제를 해결하기 위해 momentum feature 라는 아이디어를 활용합니다.
간단히 말씀드리자면, 미니 배치마다 불필요한 노드들이 샘플링 되는 경우를 방지하고자, pseudo sampling 을 활용합니다. 여기에서 불필요하다 라는 기준은 optimization error 를 오히려 키우는 노드를 의미합니다.
이를 방지하기 위해 pseudo sampling 즉, 샘플링에 적용하지 않은 노드들을 불러오는거죠. 필요한지 불필요한지에 대한 기준은 당연히 gradient 를 통해 정량화하여 측정합니다. 이 때 gradient 를 정량화하며 error 를 측정할때 momentum 관점을 차용하기에 본 논문의 타이틀에 적힌바와 같이 feature momentum 이라 이야기합니다.
Sampling 그리고 aggregation feature 에 따라 GNN 성능이 어떻게 바뀌는지에 대해 궁금하셨던 분들이 보시면 좋을거라 생각합니다. ‘Staleness of historical embedding’ 이라는 섹션에서 staleness score라는 지표를 활용하여 과연 해당 embedding (weight)가 유의미할지에 대해 다룹니다. 마냥 모든 정보를 가져오는 full이 좋을수도, 반대로 몇몇의 정보만을 가져오는 sub-sampled이 좋을수도 있습니다. 이를 어떻게 비교할까? 라는 고민이 있으셨던분들 보시면 도움될거라 생각합니다.
Complex Embeddings for Simple Link Prediction
[http://proceedings.mlr.press/v48/trouillon16.pdf]
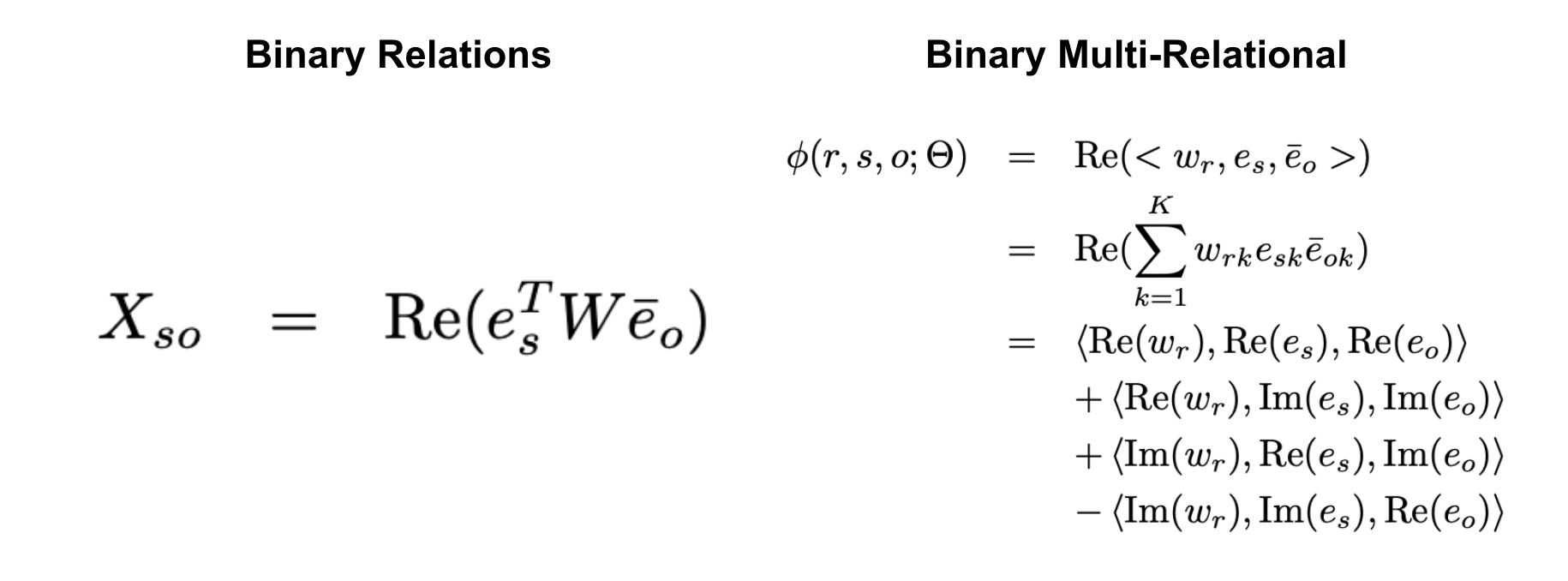
Link prediction 하면 생각나는 방법, 바로 dot product 입니다. Knowledge graph 는 heterogeneous graph 의 한 종류라고 볼 수 있는데요. 이 때 kg 의 incomplete link prediction task 에서도 dot product를 활용합니다. 하지만, 일반 heterogeneous graph 와 다르게 굉장히 다양한 엔티티 그리고 링크로 구성되어 있기에, 이를 간단한 dot product 로는 처리하기에 여러 제한점들이 존재하는데요. 이를 보완해보고자 “Hermitian dot product”를 차용합니다. 간단하게 말해보자면, 실수와 허수를 모두 dot product 에 반영하여 single relation 뿐만 아니라, multi relation 도 linear 하게 계산한다는 아이디어입니다.
Unifying Large Language Models and Knowledge Graphs: A Roadmap
[https://arxiv.org/pdf/2306.08302.pdf]
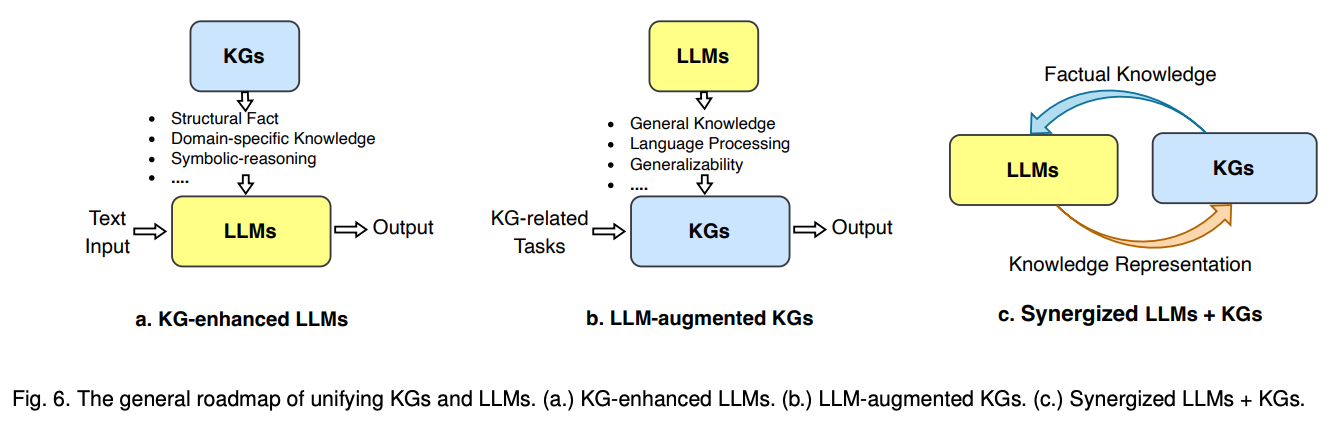
LLM, 이젠 유튜브 개그 소재로도 chatGPT 가 나올정도로 대중 인지도가 굉장히 올라갔으며, 그만큼 친근해졌다는걸 체감하는 요즘입니다. 불과 2~3여년전 , 오작동하는 chatbot가 희화화의 주 소재였던 이전과 비교해보면 참 많은 변화가 있었구나 싶습니다. 이 변화속에서도 고질적인 문제가 존재하는데요. Chatgpt 의 가장 큰 약점 1. 2021 년도까지의 학습 데이터때문에 시의적절성을 반영하지 못함. 2. 없는 사실을 있는 사실처럼 꾸며 답변하는것. 이 두가지에 대한 문제는 아직까지도 해결해야할 문제로 자주 이야기 나오고 있습니다.
이를 해결해보고자 많은 시도들이 존재하는데요. 크게 3가지 종류로 나뉘는것 같습니다. 1. Efficient fine tunning 2. Prompt engineering 3. RAG(Retrieval augmented generation) 각자 장단이 뚜렷하기에 각자 처한 문제에 따라 적절한 솔루션을 취사선택하시면 좋을거 같은데요. 그 자세한 내용은 [https://medium.com/@pandey.vikesh/should-you-prompt-rag-tune-or-train-a-guide-to-choose-the-right-generative-ai-approach-5e264043bd7d] 에서 쉽고 재밌게 다루었으니, 참고하시는 걸 추천드립니다.
다시 돌아와서, 특히 3번 RAG 덕분에 Knowledge graph 가 많은 관심을 받고 있습니다. 바로, knowledge base , graph 로부터 받아온 정보를 LLM의 pretraining stage 나 inference stage 에서
활용하면 답변의 정확도가 더욱 향상될거라는 실험 결과들이 속속 보이고 있기 때문입니다. 본 논문에서는 그 내용들에 대해서 다룹니다. KG 를 통해 LLM task performance를 향상시키는 방법 , LLM을 통해 KG task performance 를 향상시키는 방법, KG + LLM 둘 다를 활용해 시너지를 일으키는 방법. 체계적으로 잘 작성되어 있습니다.
온톨로지를 연구하시는 분이나, 자연어처리를 연구하시는 분, 두 분야에 종사하시는 분들이라면 한번쯤은 보셨으면 하는 서베이 논문입니다. 상호보완하는 내용에 포커싱이 되어있기에 오버뷰를 파악하시는데 굉장히 좋을거라 생각합니다.
** 데이터 인사이트 세미나.
우연찮게도, 이번주에 위 논문에서 언급한 내용과 유사한 세미나가 있어 참여했습니다. 김장원 교수님 김학래 교수님 그리고 HIKE 연구원 분들께서 쉽게 잘 설명해주신덕에 이번주 오마카세 재료 손질에도 많은 도움이 됐습니다.

(김장원 교수님 대담 즐거웠습니다. 좋은 자리 마련해주시고 인사이트 공유해주신 김학래 교수님, HIKE 연구원분들, openknowledge forum 관계자분들 감사합니다.)
세미나 내용 하나하나 주옥같았지만, 그 중 하나를 꼽아보자면 "It didnt work" 라는 구절을 시작으로 knowledge graph 로 '추론'을 하려고 하다보니, 오히려 적합한 도구가 있음에도 불구하고 'Knowledge graph'만을 고집하여 작동치 않음 과 openai , google , knowledge graph 3가지 관점으로 무언가를 검색했을때, openai 보다 knowledge graph 가 훨씬 빠름을 이야기해주시며, 적절한 모듈을 활용하는게 중요하다 를 꼽을 수 있겠네요. 결국 LLM , KG 가 적합한 task 가 있을것이고 그 task 를 빠르게 문제로 정의하고 솔루션으로 무엇이 좋을지 판단하는 역량이 중요하다 라고 저는 이해했습니다. 살이 되고 뼈가 되는 좋은 말씀을 해주셔서 오마카세 여러분들과도 공유해봅니다.
국내에도 Knowledge graph forum 이 따로 존재하는데요. [https://forum.datahub.kr/] 에 접속하시면, 현재 주소 지식 데이터 통합부터 시작하여 지식데이터 관련 논의까지 여러 인사이트들이 여러분들을 기다리고 있습니다. 지식베이스 그리고 그래프 관련해서 리소스를 얻고 싶은 분들은 한번 방문해보시는걸 추천드립니다.
** 2st seminar
"9월 23일에는 GUG 2차 세미나가 열립니다. 이번 행사에서는 LLM(자연어 이해 및 생성)과 KG(지식 그래프), 그리고 GDB(그래프 데이터베이스)에 중점을 둘 예정입니다. 특히, LLM 및 LLM 할루시에이션 현상에 대한 대안으로 떠오르고 있는 KG에 대한 토론과 발표가 예정되어 있어 많은 관심과 참여를 부탁드립니다.
또한, 이번 2차 세미나 연사진은 이전 1차 세미나와 견줄 만한 수준의 강연자들을 초빙하여 LLM 및 KG 분야에서 굉장한 지식을 공유해드릴 예정입니다. KG 분야의 거장과 LLM 분야의 거장이 발표를 통해 LLM + KG에 대한 풍부한 정보를 제공할 것이며, 여러분의 학습과 이해에 큰 도움이 될 것입니다.
세미나에 많은 참석 부탁드립니다."
** graph travel
Graph Travel 재개! 기다리시던 분들 많으셨을거라 생각됩니다. 이번주차부터 다시 시작합니다. 주차를 거듭할수록 콘텐츠가 흥미로워지는거 같아요! 정말 그래프를 통해 여행을 떠나는 느낌이 드네요!