그래프 튜토리얼: Graph & Deep Walk



- Random Walk
- Node Embedding
- Deep Walk (Word2Vec - Skip-gram)
- Node Classification
반가워요, GUG 여러분! 그래프 튜토리얼의 가이드 Erica 입니다✨🚀
우리는 저번 시간에, Graph를 구성하는 개념 요소들을 만나봤어요. 그 과정에서 edge와 node와 연관되어 더욱 다채롭게 그래프를 표현할 수 있게 해주는 특성들을 배웠죠. 어떤 곳들을 여행했었냐면... 어디 보자, degree, weight, direction, connectivity, centrality, density... 정말 많은 곳을 돌아봤네요!
🚂 그럼 이제 Graph Neural Network로의 2번째 여행을 떠나볼까요?
코드를 한번에 실행해 볼 수 있는 .ipynb 파일은 아래 링크에 있답니다.
 H4Y3J1N
H4Y3J1N
# Tutorial Code 실행 환경 및 라이브러리
torch: 2.0.0
torch-geometric: 2.3.1
networkx: 2.8.4
matplotlib: 3.3.4
numpy: 1.24.3
pandas: 2.0.1
sklearn: 1.2.2
gensim: 4.3.1
python: 3.10.10
Load the Data
여행에 비유하자면, 오늘의 내용은 유적을 찾기 위해 사막을 지나가는 것과 같아요.
오늘 Erica와 함께할 여행에서는 저번 주의 여행 경험을 바탕으로 첫 GNN 알고리즘을 만들어 볼 예정입니다. Node Classification 에 도전해 보자구요!
이번 튜토리얼에서도 우리는 Cora 데이터셋을 사용할 거에요. CORA 데이터셋은 인용 네트워크를 나타내는 데이터셋으로, 학술 논문들의 인용 관계를 그래프 형태로 나타냅니다. 각 Node는 논문을 나타내고, Edge는 논문 간의 인용 관계를 나타내죠.
다음 주에는 또 다른 데이터셋을 만나게 될 거에요. 기대해도 좋답니다! 우선 일단은 데이터를 로드해 봅시다.
# 필요한 모든 라이브러리 임포트
import numpy as np
import pandas as pd
import random
import networkx as nx
import torch
from torch_geometric.datasets import Planetoid
from torch_geometric.utils import to_networkx
import matplotlib.pyplot as plt
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report
from sklearn.manifold import TSNE
from gensim.models import Word2Vec
# CORA 데이터셋 로드
dataset = Planetoid(root='/tmp/Cora', name='Cora')
data = dataset[0]
# torch_geometric의 데이터를 NetworkX 그래프로 변환
edge_index = data.edge_index
edges = edge_index.t().numpy()
G = nx.from_edgelist(edges, create_using=nx.Graph())Walk with Adjacency Matrix
첫 번째 여행에서 마주쳤던 개념들을 잘 기억하고 있나요?
저번 튜토리얼에서 마지막으로 다루었던 Adjacency Matrix(인접 행렬)는 무척 중요한 기초 개념인데요, 그 이유는 인접 행렬이 Graph의 기본적인 Structure Information(구조 정보)를 제공하기 때문이에요.
작은 Subgraph는 귀여운 시각화 결과를 내놓았지만, 우리가 가장 처음 그려보았던 전체 데이터 Graph는 파워에이드🥤를 쏟아놓은 것처럼 하늘색 점들로 뭉쳐서, 도무지 알아볼 수가 없었죠.
우리가 큰 그래프의 복잡한 구조를 탐색하고 이해하기 위해서는 Adjacency Matrix의 도움을 받아야 한답니다. 더 정확히 이야기하자면, Random Walk라는 알고리즘이 Adjacency Matrix의 Graph Structure information을 활용하도록 해야 돼요. 이 2가지 개념은 서로를 보완하며 복잡한 구조와 패턴을 효과적으로 파악할 수 있게 도와준답니다!
Random Walk
그래서 Random Walk가 뭐냐구요? 한 문장으로 쉽게 정리하자면, "Graph의 특정 Node에서 시작해 임의의 Direction(방향)으로 이동하는 과정"입니다.
Random Walk가 대단하고 중요한 이유는, Node 간의 Connectivity(연결성)뿐만 아니라 Node 간의 전체적인 연결 패턴까지 파악할 수 있다는 거랍니다. 또, GNN에서는 *Node Representation을 학습할 때 랜덤 워크를 이용하는 경우가 많아요.
- 하지만 우연히 노드를 방문했을 뿐이잖아요?
음, 그런 말을 들어 보았나요? 우연이 반복되면 인연, 인연이 반복되면 운명! Random Walk가 중요한 이유는 이렇습니다. 노드가 단순히 무작위로 선택되는 것은 맞지만, 랜덤하게 선택된 노드들 사이에서도 "함께 자주 나타나는 Node들은 서로 '가까운(closeness)' 관계라고 판단"할 수 있기 때문이에요.
여기서 '가깝다'라는 개념은 Network homophily hypothesis(네트워크 동질성 가정)과 관련이 있습니다. 쉽게 다시 설명해 드리자면, 가까운 거리에 있는 Node들은 서로 비슷한 Attribute(특성, =Feature)을 갖는다는 거에요. - 비슷한 Attribute를 갖는다는 게 뭔데요?
예시를 들어 볼게요. 우리는 GUG에 contribute하거나, GUG 뉴스레터를 subscribe하는 사람들이죠. IT 필드에 관심이 많거나 종사하고 있고, 그 중에서도 GNN에 관심이 특히 많다는 공통점을 가지고 있어요. 하지만 linkedIn에서 촌수가 멀어질수록 어떻게 될까요? 전혀 다른 필드에 있는 모 항공사 기장님의 프로필까지 닿게 되겠죠!
LinkedIn 소셜미디어를 Graph로 보자면, GUG 구성원은 Subgraph, 그리고 여러분과 저는 하나의 Node랍니다. 정말 흥미롭죠. 아참, Erica의 LinkedIn 주소는 이쪽이랍니다. 1촌 신청이나 팔로우도 언제나 환영이에요!
본론으로 돌아옵시다. Random Walk의 작동 방식은 아래와 같아요.
- Start Node(시작 노드) 선택
- 현재 노드에 연결된 이웃 노드 중 하나를 random하게 선택해 그 방향으로 이동
- 일정 횟수 혹은 조건이 만족될 때까지 2번 과정을 반복
이제 작동 원리를 직접 눈으로 확인하기 위해, 가까이 걸어가 볼 차례네요!
def random_walk(G, start_node, walk_length):
walk = [start_node] # 시작 노드를 포함하는 리스트 walk를 생성
# walk 리스트는 무작위 경로의 노드를 저장하는 데 사용
for i in range(walk_length - 1):
# 시작 노드가 이미 walk안에 있으니, -1.
neighbors = list(G.neighbors(walk[-1]))
if len(neighbors) == 0:
break
next_node = random.choice(neighbors)
walk.append(next_node)
return walk알아두세요! 위 튜토리얼 코드는 Random Walk 작동원리의 이해를 돕도록 최대한 가볍게 구현한 것입니다. 이 함수는 지정된 시작 노드(start)에서 시작하는 한 번의 랜덤 워크만을 생성합니다. 워크의 길이는 length 매개변수에 의해 결정되고 있죠.
따라서, 그래프의 모든 노드에서 시작하는 많은 수의 랜덤 워크를 생성하려면 코드를 개선해야 합니다.
- 앗, 원래 Random Walk는 모든 노드에 대해 수행되나요?
맞아요! 각 노드에서 여러 번의 랜덤 워크를 수행함으로써 그래프의 전체적인 구조와 각 노드의 지역적인 특성을 포착하는 것이 가능해집니다. 하지만 랜덤 워크의 세부적인 동작 방식이나 사용 목적에 따라 Start Node의 선택이나 walk의 수 등이 다르게 설정될 수 있습니다.
예를 들어 일부 노드만 중점적으로 분석하고 싶은 경우, 그 노드들에서만 랜덤 워크를 수행할 수도 있어요. 혹은 일부 노드를 샘플링해 랜덤 워크를 수행하는 경우도 있습니다. Task나 데이터의 특성에 따라 다양하게 조정하면 돼요.
Random Walk의 개념을 차용해서 Local information을 사용하는 건, 전체 그래프를 분석하는 것보다 효율적인 방법을 제공해요. 전체 그래프를 처리하는 것은 대체로 computational cost가 높아 비효율적이거든요. 반면에 Random Walk는 적은 정보들을 사용해 Global attribute를 추정해낸답니다.
print(random_walk(G,0,20))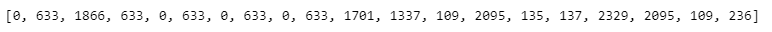
결과를 어떻게 해석해야 할까요?
위 print 코드는, Node 0에서 시작하는 랜덤 워크를 20번 수행하라는 것을 의미합니다. 따라서 출력 결과는 0에서 시작하여 무작위로 이동한 20개의 노드를 보여주고 있어요.
Random Walk는 이전 노드의 이웃 중 하나를 무작위로 선택하여 이동하는 방식으로 진행되기 때문에, 결과 리스트는 이 과정에서 방문한 노드의 순서를 나타냅니다.
- 어? Node 633이 5번이나 나왔는데요!
랜덤 워크의 특징상, 동일한 시작점과 이동 횟수를 가지더라도 실행할 때마다 다른 결과를 출력할 수 있습니다. 이는 랜덤 워크가 각 단계에서 무작위로 노드를 선택하기 때문입니다.
이 리스트를 통해 그래프의 구조나 특정 노드의 중요성 등을 파악할 수도 있어요. 예를 들어, Node 633처럼 특정 노드가 랜덤 워크 결과에 빈번하게 등장한다면, 그 노드는 그래프 내에서 중요한 역할을 하는 것일 수 있답니다.
정말 신기하지 않나요? 하지만 아직 놀라긴 이르답니다. Random Walk의 진짜 멋진 점은, Node Embedding 생성에 사용되는 DeepWalk, Node2Vec같은 알고리즘의 기반이라는 사실이거든요.
이 알고리즘들은 Node 사이의 경로를 sampling하는 데에 Random Walk를 사용합니다. 조금 더 구체적으로 말하자면, 두 알고리즘은 Node simiarity를 capture한 Vector Representation(Embedding)을 학습해요.
...음, 아무래도 방금 설명은 초심자를 위한 게 아니었던 것 같네요. 좋아요. 그러면 더 쉽게 다시 설명해 드릴게요!
Deep Walk
음, 여기서부터는 특히 인내심과 집중력을 챙겨주셔야 해요. 지금부터는 오아시스🗺를 찾아 나서는 사막길🏜이 잠시 펼쳐질 거거든요.
우선 Deep Walk를 명료하게 정리하자면, "Graph Embedding"을 생성하는 알고리즘이라고 할 수 있습니다. 이 알고리즘은 Graph Network의 Node 간의 Similarity Score(유사도 점수)를 측정하는 방식으로 작동하죠.
좀 더 정확하게는 서로 가까운 노드들의 유사도 점수를 높게, 멀리 떨어진 노드들의 유사도 점수는 낮게 설정함으로써 그래프 네트워크의 Structure Feature(구조적 특성)을 학습하고, 각 Node를 효과적으로 represent하는 low dimentional vector를 생성해냅니다.
어떤 개념을 파악하는 가장 효과적인 방법은 차이점을 파악하는 것입니다. 앞서 배운 Random Walk와 비교해 볼까요?
1. Random vs Deep
Random walk가 그래프 상의 노드들을 무작위로 순회하는 가장 베이직한 방법론이라면, DeepWalk는 Random walk를 사용하여 Node를 Vector Space에 투영하는 방법론이에요.
DeepWalk = Random walk + Word2Vec ?
🚶♂️Random Walk의 역할 : Random walk의 실행결과로 Node Sequence를 생성합니다. 이것은 일종의 '문장'이라고 봐도 좋아요. Sequence에 포함되는 각 Node는 '단어'에 해당합니다.
📑Word2Vec의 역할 : 일반적으로는 단어들의 벡터 표현(임베딩)을 학습하는 데 사용되는 머신러닝 모델입니다. 비슷한 문맥에서 등장하는 단어들이 벡터 공간에서 가까이 위치하도록 단어들의 벡터를 조정하는 방식으로 작동해요. 최종적으로 모델 임베딩은 단어 사이의 의미적 관계를 반영하게 되죠.
GNN, 다시 말해 이 튜토리얼에서는 생성된 시퀀스(문장)를 사용해 Word2Vec(특히 Skip-gram 아키텍처)를 통해 각 노드의 Vector Representation(벡터 표현, ==Embedding)을 학습합니다.
- skip-gram 아키텍처가 무슨 일을 하는데요?
Skip-gram 아키텍처는 중심 단어를 기반으로 주변 단어를 예측하는 방식으로 작동합니다. 이 방법은 주변 단어의 문맥을 이해하는 데에 특히 효과적이죠! - Vector Representation은 뭐죠?
Vector Representation(벡터 표현 또는 임베딩)은 단어나 노드를 고차원 벡터로 표현하는 것을 의미합니다. 이 벡터는 해당 Node의 Attribute을 캡쳐하며, 이는 원래의 데이터 공간에서는 알아챌 수 없는 패턴을 발견하는 데 도움이 될 수 있습니다. 다른 건 잊더라도, 이것만큼은 기억하세요! Deep Walk의 목표는 Feature Representations of Nodes(==embedding, Vector Representation)를 만들어내는 것입니다.
지금부터의 여행 코스는요 🧭
- Unbiased Random Walk 구현
- Word2Vec을 통해 Node Embedding 학습
- 임베딩을 t-SNE를 통해 2차원으로 축소하여 시각화
- Random Forest 모델로 분류 작업 수행
그럼 우선, 가장 먼저 길잡이가 되어줄 random walk를 만나 봅시다.
def unbiased_random_walk(G, node, walk_length):
walk = [node]
for _ in range(walk_length - 1):
neighbors = list(G.neighbors(walk[-1]))
if len(neighbors) == 0:
break
walk.append(random.choice(neighbors))
return walk
# Random Walk 생성
walks = [unbiased_random_walk(G, node, 10) for node in range(data.num_nodes) for _ in range(10)]위 튜토리얼 코드에서는 Biased random walk 함수를 정의하고, walk를 추출해냈어요. Input으로는 그래프 G, 시작 노드 node, 걸을 길이 walk_length를 받고 있네요. 그 다음엔 모든 노드에 대해 10 step의 biased random walk를 10번 반복했어요.
- 어? 그럼 Biased Random Walk도 있는 건가요?
맞아요! Walk가 진행될 때, 'p', 'q' 매개변수를 통해 노드 선택에 관여하는 bias(편향성)을 조절할 수도 있답니다. 하지만 이 개념은 사실 Node2Vec 알고리즘에서 제안 되었어요. 베이직한 DeepWalk는 일반적으로 Unbiased Random Walk를 사용합니다. 따라서, 튜토리얼에서는 이 부분을 고려해 DeepWalk의 원래 개념을 정확하게 구현했답니다.
# String 형태로 변환 (Word2Vec 입력을 위해)
walks = [[str(node) for node in walk] for walk in walks]
# Word2Vec 학습
model = Word2Vec(walks, vector_size=100, window=5, min_count=0, hs=1, sg=1, workers=4, epochs=10)
# 노드 임베딩 추출
embeddings = np.array([model.wv.get_vector(str(i)) for i in range(data.num_nodes)])그 다음엔 Word2Vec 학습을 위해 워크 내의 모든 노드를 문자열로 변환했습니다. gensim 라이브러리에서 불러온 Word2Vec 모델에게 이런저런 변수들을 건네줬고요. 그 결과로 Node가 걸어간 경로들로 Embedding을 추출해낼 수 있었네요!
# t-SNE를 통한 시각화
embeddings_2d = TSNE(n_components=2).fit_transform(embeddings)
plt.scatter(embeddings_2d[:, 0], embeddings_2d[:, 1], c=data.y)
plt.show()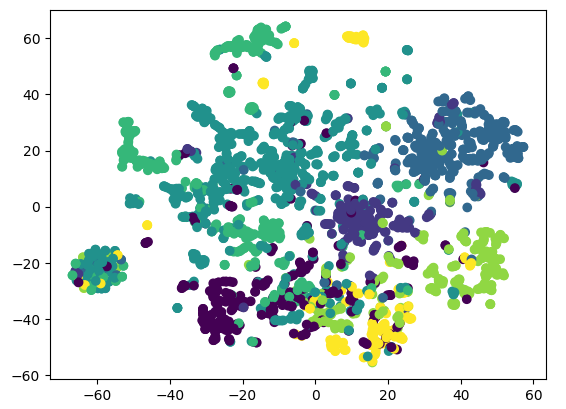
그 다음에는 제대로 된 여행 코스를 따라가고 있는지 확인하기 위해, t-SNE를 사용해 봤어요. t-sne는 GNN에서도 카메라📸 같은 역할을 합니다. 복잡한 고차원을 2~3차원으로 축소해 주거든요. 결과적으로 노드 간의 관계를 이해하는 데에 도움을 줍니다.
포인트는 clustering이 잘 되었는지, 다시 말해 임베딩이 잘 학습되었는지, 원하는 attribute를 잘 capture하고 있는지 확인해 보는 거랍니다! 노드들이 원하는 방식으로 군집화되지 않았다면, 임베딩 방법에 문제가 있는지 의심해봐야 해요.
확실히 큰 데이터셋인 티가 나네요. 하지만 색을 보면 clustering은 꽤 잘 된 것 같아요. 부록으로 Subgraph를 그려서 형태를 살펴볼까요?
# 레이블 추출
labels = data.y.numpy()
# 노드 선택 (예: 첫 50개 노드)
selected_nodes = range(500)
subG = G.subgraph(selected_nodes)
# 레이블에 따른 색상 매핑
label_color_mapping = {label: idx for idx, label in enumerate(np.unique(labels[selected_nodes]))}
node_colors = [label_color_mapping[label] for label in labels[selected_nodes]]
plt.figure(figsize=(12,12), dpi=300)
plt.axis('off')
nx.draw_networkx(subG,
pos=nx.spring_layout(subG, seed=42, k=0.15), # k 인자를 조정하여 노드 간의 거리를 늘릴 수 있습니다.
node_color=node_colors,
node_size=400, # 노드의 크기를 줄입니다.
edge_color='black', # 엣지의 색상을 변경합니다.
width=1.5, # 엣지의 두께를 두꺼워지도록 설정합니다.
cmap='coolwarm',
font_size=14,
font_color='black')
plt.show()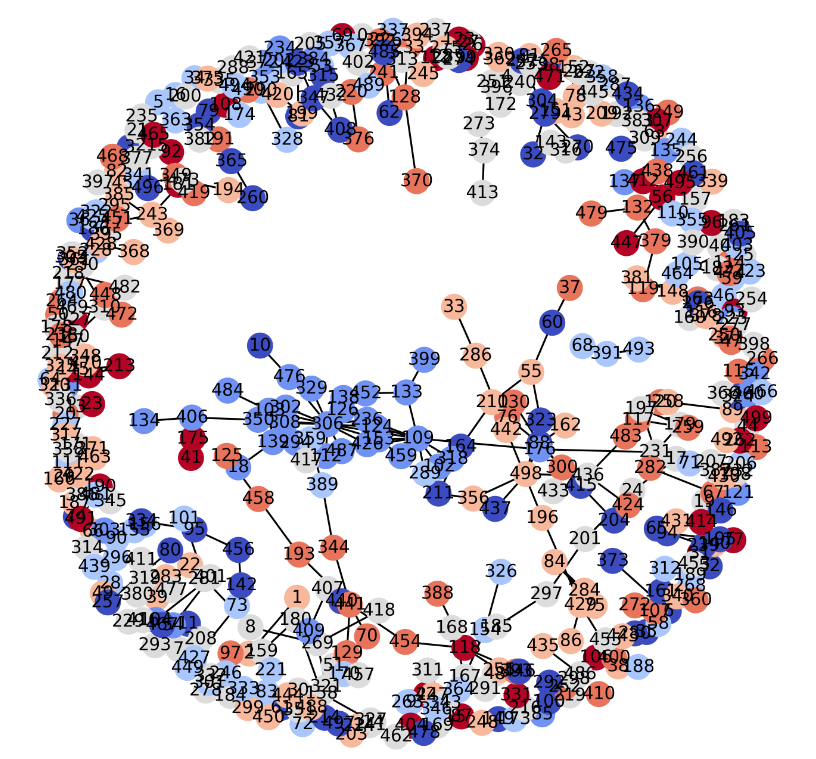
정말 재밌네요. 꽤 그럴듯해 보이는 그래프가 그려졌어요! 참고로 Node의 색깔은 lable에 따라 칠해져 있답니다. 원의 중심부에는 특정 색의 노드들이 모이기 시작했네요. 개수를 늘려서 새로 출력해봐도 재밌겠지만, 노드 개수가 많아질수록 plotting 속도가 느려진다는 점도 잊지 마세요!
Node Classification
각 Node마다 label이 주어져 있다는 것을 확인했으니 이제는 Graph를 가지고 더 재미있는 것들을 할 수 있겠네요. 지금부터 Node classification을 해봅시다.
아, 그런데 그 전에 잠깐! 우리가 정확히 뭘 하려고 하는지, Task의 목적이 무엇인지는 알아야겠죠?
노드 분류란 무엇일까요?
Node Classification이란, 그래프 내의 각 노드를 특정 카테고리나 클래스로 분류하는 작업을 의미합니다. 예를 들면, 한 비행기✈에 탑승한 승객들의 취미, 직업, 국적 등을 예측하는 거죠.
GNN의 포인트는 그래프를 구성하는 Node의 Attribute(==Feature, 특성)을 학습하는 거에요. 학습 과정에서는 Target node의 정보뿐만 아니라, 연결되어 있는 neighborhood nodes의 정보도 함께 고려됩니다. 이렇게 학습된 Node Embedding은 노드들의 특성을 잘 반영하고, 이 임베딩을 통해 분류 작업이 가능해져요.
Node Classification Task의 예시로는 유저의 행동 패턴을 예측이나, 추천 시스템에서 유저에게 가장 relevance가 높은 아이템을 추천하는 것이 있습니다. 여담이지만 우리도 다음주의 Graph Travel에서 GNN을 가지고 유사도 기반 추천을 직접 해 볼 거에요!
이번 여행의 마지막 코스로는🧭
1. RandomForestClassifier에 Embedding을 학습시키고
2. Node classification을 진행한 다음
3. 분류 보고서를 확인해 볼게요.
# 레이블이 있는 노드만 선택
labels = data.y.numpy()
idx_train = data.train_mask.numpy()
idx_test = data.test_mask.numpy()
X_train, y_train = embeddings[idx_train], labels[idx_train]
X_test, y_test = embeddings[idx_test], labels[idx_test]
# 랜덤 포레스트 분류기 학습
rf = RandomForestClassifier(random_state=42)
rf.fit(X_train, y_train)
# 예측 및 성능 평가
y_pred = rf.predict(X_test)
print(classification_report(y_test, y_pred))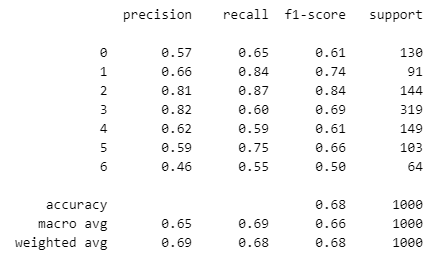
굉장히 간단한 코드이므로, 특별한 해설은 덧붙이지 않을게요. 대신 우리는 보고서 결과 해석에 초점을 맞춰 봅시다.
분석 결과를 보면, class 3은 support가 가장 높은 반면, recall이 상대적으로 낮네요. class 2는 precision과 recall이 모두 높아 잘 분류되고 있는 걸로 보여요.
전체적으로는 accuracy가 0.68로, test set의 약 68%를 정확하게 분류했습니다. 하지만 class별 f1-score의 수치가 class별로 격차가 크네요. 이런 차이는 모델이 데이터의 특정 패턴을 더 잘 학습했거나, 데이터 불균형 때문입니다. 따라서 모델을 개선할 땐, class별 성능 차이를 줄이는 데에 집중하는 게 좋겠습니다.
이렇게 우리는 Node Classification까지 해냈네요! 제대로 온 것 같아요. 저 멀리 Node2Vec 유적🛣 의 실루엣이 보이나요? 기념으로 CORA 데이터셋과 사진이라도 한 장 찍고 가죠!
# 하나, 둘, 셋, 치즈! 📸
plt.figure(figsize= (12,12), dpi= 300)
plt.axis('off')
nx.draw_networkx(G,
pos = nx.spring_layout(G, seed = 0),
node_color = labels,
node_size = 300, # 노드 크기 조정
cmap = 'coolwarm',
font_size = 14,
font_color = 'white',
edge_color = 'grey', # 엣지 색상 설정
width = 1, # 엣지 두께 설정
with_labels = False) # 노드 라벨 표시 여부. True로 바꾸면 노드 이름이 출력됩니다!


와! 이렇게 벌써 두 번째 여행이 끝났습니다. 우리는 이제 GNN 알고리즘들을 탐험하기 위한 기본 토대를 쌓았어요.
오늘 배운 내용들은 지금부터 무궁무진한 가능성으로 확장될 거예요!
🎫 Node2Vec?!
다음 이 시간에는 DeepWalk를 더욱 발전시킨 Node2Vec모델을 튜토리얼로 만나볼 거에요. 지금까지 배운 모든 내용을 심화응용해 Random Walk에 Search Bias를 적용하는 작업을 직접 해볼 거랍니다!
그러면 우리는 다음 주에 다시 만나요, 안녕~!
Reference | DeepWalk: Online Learning of Social Representations
