7월 1주차 그래프 오마카세


정보과학회 다녀온 후 다양한 인사이트를 얻었으나 그 중 단연 으뜸이였던건 바로 Efficient AI 였습니다. 학회 오전 오후 각각 세션을 모두 할애할 정도로 학계 그리고 산업계를 가리지않고 모두들 열광하고 있었습니다. Model 에 대량의 데이터를 ‘잘’ 학습 하는게 주된 관심사인거죠. 여기에서 ‘잘’ 학습한다 의 기준 및 중요하게 바라볼 지표는 다양하겠으나, 그중 딱 하나를 꼽아보자면 저는 ‘분산처리’라고 생각을 했습니다. 바로 데이터들을 고르게 나누어 모델에게 효율적으로 전달하는거죠.
전달시 발생하는 가장 큰 문제 중 하나를 ‘병목현상’ 이라 생각합니다. 대량의 데이터를 동시다발적으로 memory 에 올리게 될 때마다, 마주하는 문제 ‘OOM’ 이를 해결해보고자 다양한 시도들이 존재하죠. 배치 사이즈를 줄이는게 가장 기본이긴하나 , 말 그대로 원래 한 개의 데이터를 다량의 데이터로 분리하여 모델에 학습을 시키다보면, 그에 따라 정보의 연속성이 감소하며 유의미한 bias 를 잃어 오히려 일반화 측면에서 불리할 수 있습니다. 또한 batch size 에 따라 lr, optimizer, epochs , dropout rate, 등을 고려한 적절한 조합을 통해 overfitting 도 방지해야 하기때문에 고민해야할게 너무나도 많아집니다.
그럼 batch size 에 robust 하게 모델 학습 파이프라인을 만들되, 적재적소의 데이터 그리고 학습을 어떻게 잘 융화시킬것인가? 라는 고민까지 이르게됩니다. 이 고민을 어떻게 해결할까요? 이번주 오마카세에서는 여러분들이 쉽게 적용할 수 있는 방법론 그리고 그 기원에 대해 알아보겠습니다.
Cluster-GCN: An Efficient Algorithm for Training Deep and Large Graph Convolutional Networks.
[https://arxiv.org/pdf/1905.07953.pdf]
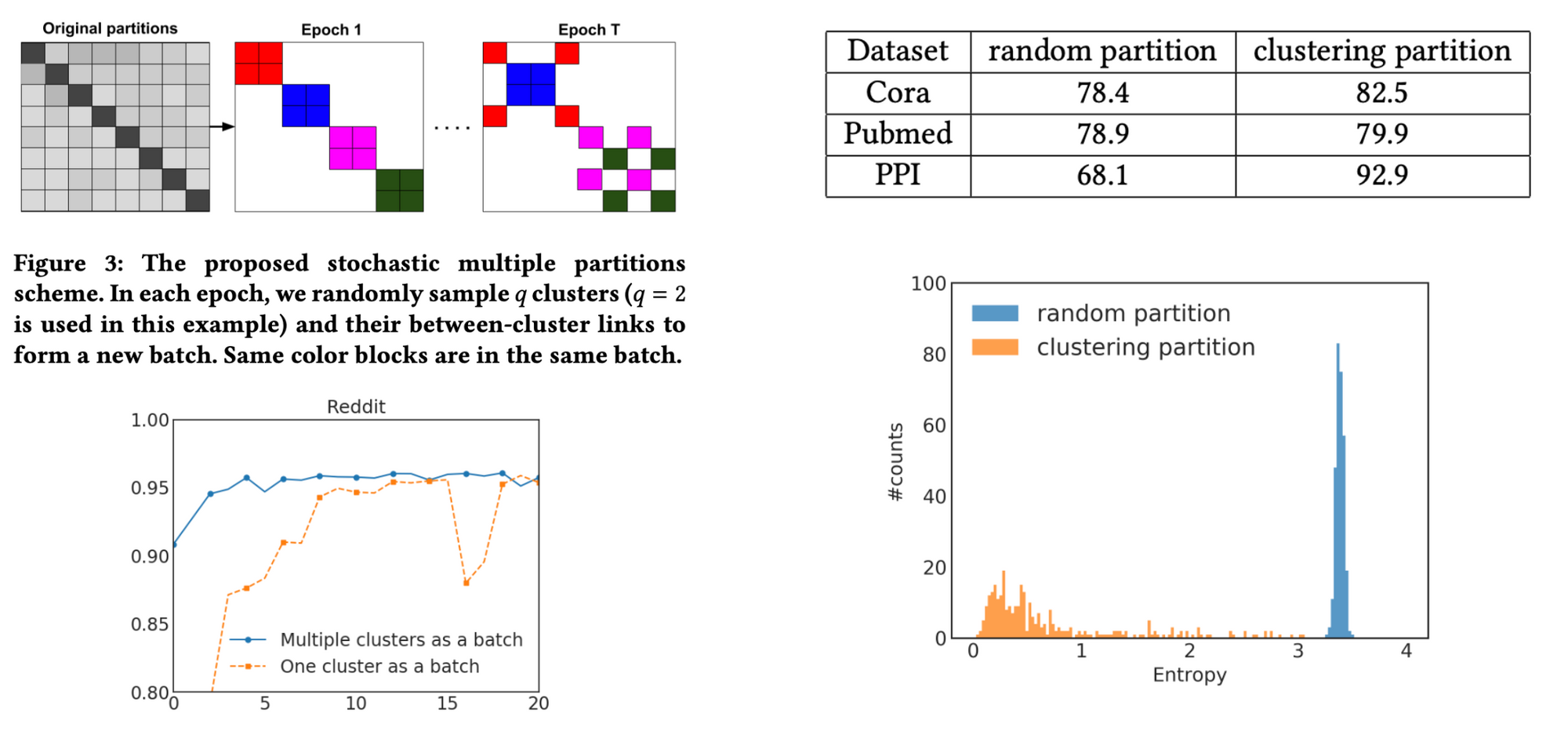
Cluster-GCN 의 핵심요소 3가지를 꼽아본 결과는 다음과 같습니다.
1.METIS, graph partioning algorithm.
GCN , overall message passing 이 일어나는만큼 graph 의 크기가 커질수록, 연산량도 선형적으로 비례하기 때문에 계산 비용이 상당함을 유추할 수 있습니다. 다시 말해서, 모든 그래프를 한 번에 memory 에 올리기 때문에 OOM이 발생할 가능성이 크다는거죠. 본 논문에서는 ‘모든 그래프’에서 ‘서브 그래프 샘플링’을 통해, redundancy 를 최소화하여 유용한 정보만들을 활용해보자는 거죠.
그렇다면 결국 ‘서브 그래프 샘플링’ , 유용한 정보들만을 잘 추출하는게 핵심이라고 할 수 있습니다. 본 논문에서는 그 정보들을 잘 추출하기 위해 METIS 라는 graph partioning algorithm 을 적용합니다. METIS란, edge connectivity 를 효율적으로 설계해서 batch 마다 중요하다 라고 생각되는 graph 들끼리를 co-location 할 수 있게 re-build 하는 알고리즘입니다. 최종적으로 이를 통해 유용한 서브그래프들을 batch 에 담아 학습을 진행합니다.
2.Embdding utilization.
message-passing 하기 위한 modified message passing 알고리즘을 제안합니다. 앞서 METIS 를 통해 효율적인 서브그래프 들이 추출되었다면, 그 정보들을 ‘잘’ 학습시켜야 하는데요. 이 embedding utilization 테크닉을 고려하게 된 배경은 다음과 같습니다. 저희는 여태까지 graph structure 를 모두 학습하기에 어려움이 존재하여, Sub-graph 샘플링을 했습니다. 이 sub-graph 샘플링의 결과를 단순히 1-hop 으로만 적용한다면 기존 방식대비 정보량이 상당히 모자라게 됩니다. 그렇기 때문에, sub-graph 내에서 layer 를 증가시켜 4~5 HOP 까지 적용해야 한다 라는 결론까지 이르게 됩니다.
이때, trainig deep layer 의 고질적인 문제 over-smoothing 을 해결하고자 본 논문에서는 previous layer weight 에 Identity 등과 같은 재료들을 추가해서 그 distant 따른 가중치를 더해줍니다. 그렇다면, 결국 diagonal enhancement 에 강화된 message passing 이 탄생하게 되는거죠.
3.Partition evaluation with Entropy.
여태까지 저흰 어떻게 효율적으로 서브그래프를 추출(1)하며 그 정보들을 노드에 잘 전달할것(2)인가에 대해 알아 보았습니다. 이 일련의 과정이 효율적인가 를 판단하기 위한 기준이 필요한데요. 본 논문에서는 그 기준을 entropy 를 활용해 알아보았습니다. 그 대조군으로써, random partioning 을 활용합니다. 간단하게 말해보자면 , METIS 를 통해 도출된 서브그래프 vs. random 으로 selection한 서브그래프 마다의 엔트로피를 비교한다. 라고 생각하시면 되겠습니다.
친절의 대명사 pyg 에서 scaling tutorial 도 colab 형태로 작성해놓았습니다. 이론 공부에만 그치지마시고, 실제 적용까지 한 번 시도해보시며 체화시켜보시면 공부의 효과가 배가 될거라 생각됩니다. 꼭 시도해보시길 !
https://colab.research.google.com/drive/1XAjcjRHrSR_ypCk_feIWFbcBKyT4Lirs?usp=sharing
Partial Parallelization of Graph Partitioning Algorithm METIS.
[http://courses.csail.mit.edu/6.895/fall03/projects/papers/kasheff.pdf]
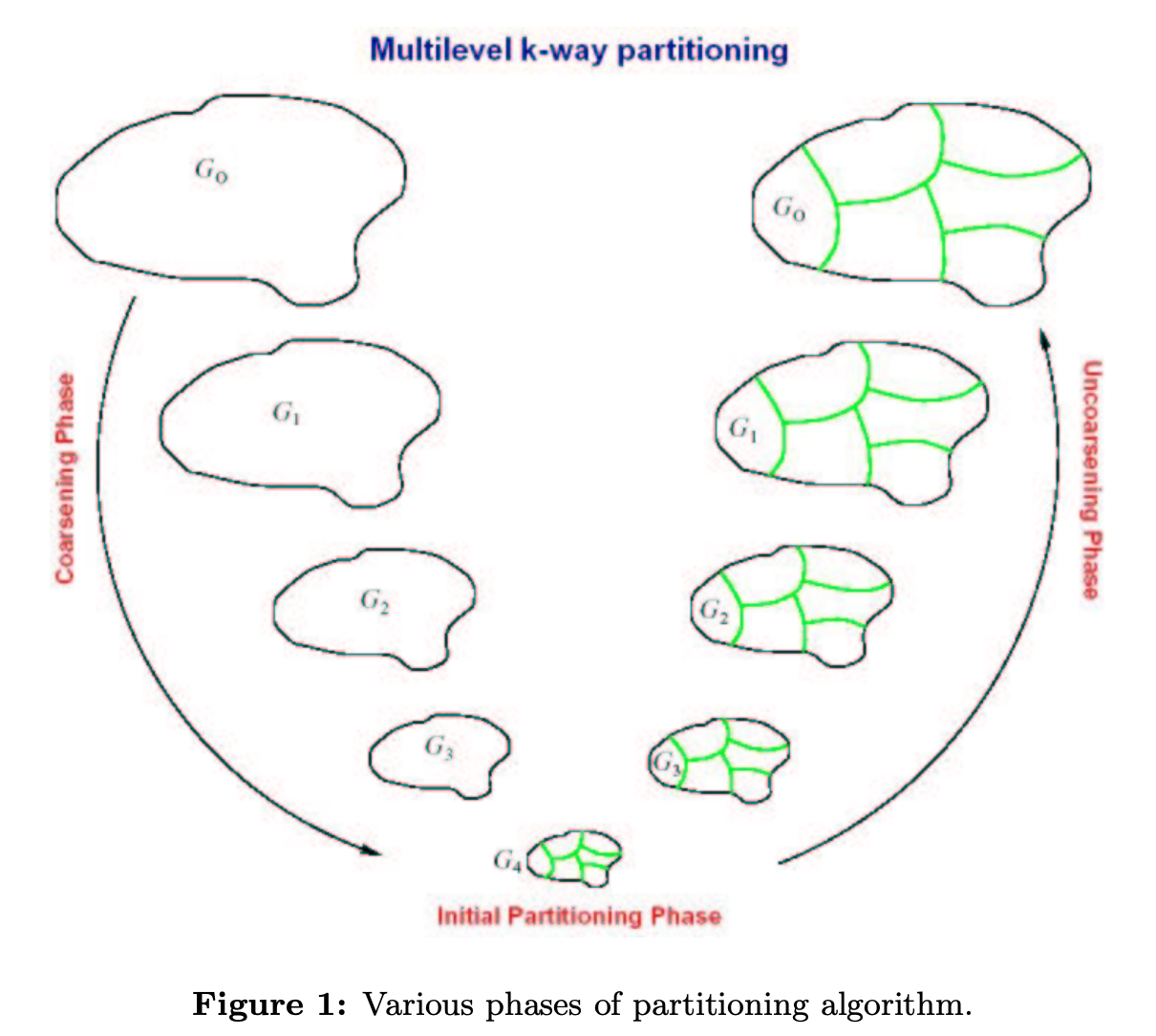
총 3가지 과정으로 partitioning 이 진행됩니다. Coarsening. Initial Partition. Refinement. 잘개쪼개고, 그룹핑을 하는 과정이 Iterative 하게 진행된다.라고 생각하시면 되겠습다. 이 때 핵심은 대략 3가지로 볼 수 있겠습니다. 1. 동시 다발적으로 변형되는 Graph structure 를 효율적으로 representation 하기. 2. coraseing 과정시 적절한 threshold 를 설정하여 일정 기준을 만족하면 stop 하기. 3. 앞서 두 과정을 효율적으로 적용하기 위한 병렬화 과정.
adj 를 어떻게 병렬화 하는지 , 그래프에는 structure 정보를 모두 적용하기 위해 어떤식으로 adj 를 표현하는지 , data placement issue 를 어떻게 해결하는지 와 같이 그래프 파티셔닝를 접근하기 위한 기초 지식들이 모두 적혀있습니다. 당연하게도 효율적인 병렬화를 위해 컴퓨터 공학 (round-robin , lock , multi-processor …등) 사전 지식들이 필요합니다. 하지만, 성장을 위해 언젠간 마주할 지식이기에 모른다하여 피하시지마시고 검색을 통해 대략적인 개념 이해를 병행하시며 본 논문을 함께 음미하시는걸 추천드립니다. 두고두고 굉장히 유용할 지식이 될거라 생각되어 추천드립니다.
reference information.
cs240A graph partioning.
[https://sites.cs.ucsb.edu/~gilbert/cs240a/slides/old/cs240a-partitioning.pdf]
수학, 컴퓨터 공학적인 접근법에 대한 갈증이 있는 분들을 위해 참고자료로 준비했습니다. 본 슬라이드만을 정독하고 공부하시는것만으로도 파티셔닝에 대한 기초는 확실히 다질 수 있다 라고 자신할 수 있습니다.
cs224w scalable.
[http://web.stanford.edu/class/cs224w/slides/16-scalable.pdf]
scalability 는 중요한 과제이기에 cs224w 에서도 한 섹션으로 과정에 배치해놓았습니다. cluster-GCN 의 수식같은 복잡한 요소들을 보기에 피곤하신 분들은 이 섹션을 보시는걸 추천드립니다. advanced version , simple gcn 까지 이야기했기에 확장된 인사이트를 얻을 수 있습니다.
scheduling definition.
https://jwprogramming.tistory.com/17
scheudling 에 대한 개념을 잘 설명해놓은 블로그가 있어 함께 전달드립니다.
KG(knowledge graph) 관련 내용입니다. LLM의 열기가 식을줄 모르고 나날이 더 뜨거워지고 있는 요즘입니다. 호기심 한가득인 저에게는 LLM의 효율적인 use-case 발굴에도 많은 관심을 가지고 있으나, 반대로 LLM이 풀기엔 적합하지 않은 즉, LLM이 적합하지 않은 분야는 무엇일까?라는 의문이 있었습니다. 더 나아가, 그 적합하지 않은 부분을 graph 가 해소할 수 있을까? 라는 심층 고민을 하곤 했는데요. 그 고민을 저만 했던게 아니였습니다.
다음 두 게시물에서는 KG 가 LLM에 기여할 수 있는 방식 그리고 KG 만의 analytics story 가 담겨있습니다. LLM의 시대에 있는 지금 과연 KG를 어떻게 활용해볼 수 있을까? 라는 고민을 하고 계셨던 분들에게 추천드리는 게시물들입니다.