7월 2주차 그래프 오마카세


FACTKG: Fact Verification via Reasoning on Knowledge Graphs
[https://arxiv.org/pdf/2305.06590.pdf]
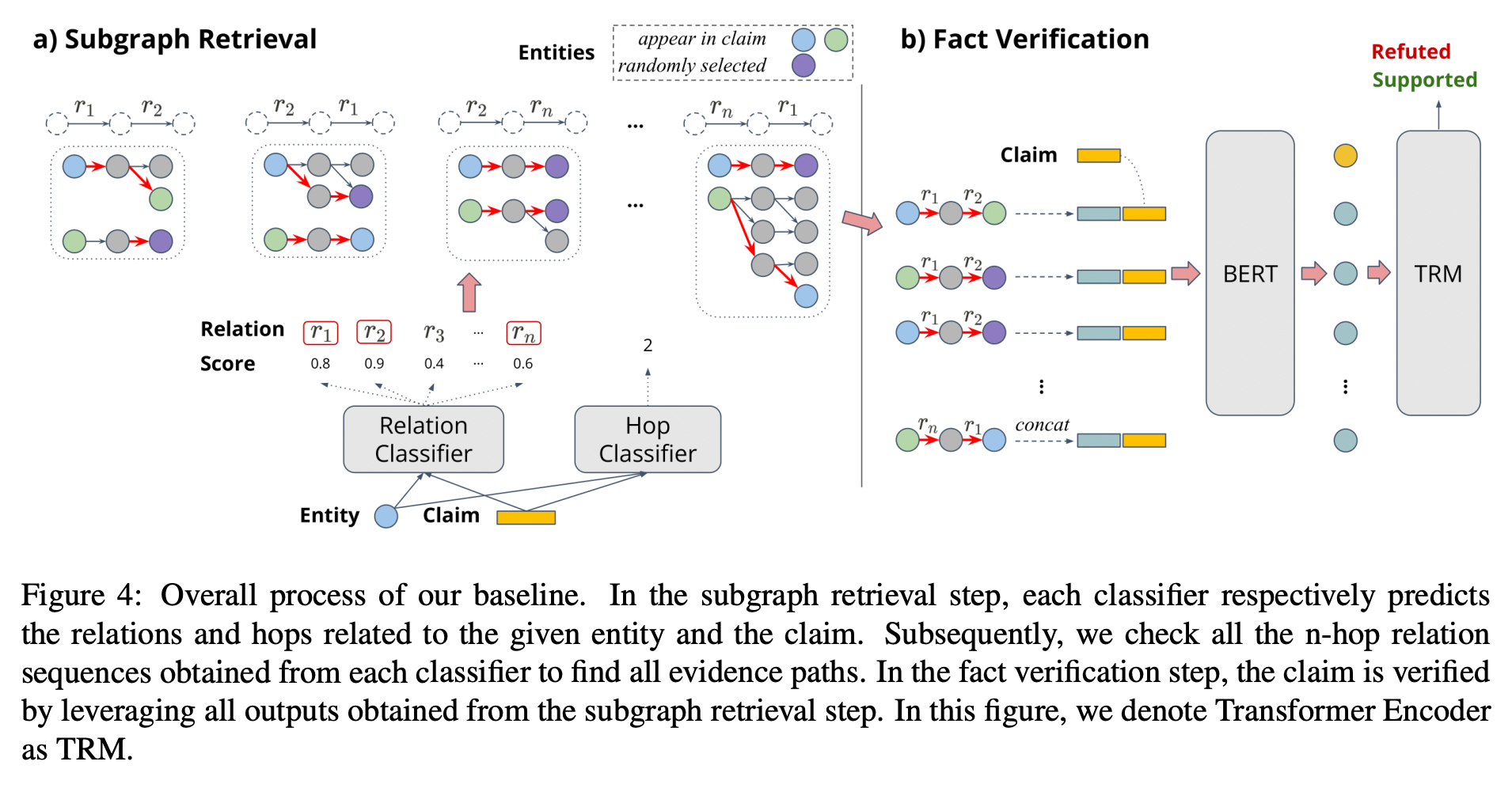
Introduction
FACT, 정보들에 대한 진위를 파악하기 위해 범세계적으로 각고의 노력을 기울이고 있는 요즘입니다. 사실진위 여부를 파악하기에는 주장에 대한 근거들을 추적하는게 범용적인 프로세스 인데요. 이 ‘근거’ 들은 저희가 어떻게 수집할 수 있을까요? 여러 방법들이 존재하겠지만, 본 논문에서는 Knowledge graph를 통해 그 근거들을 수집하여 사실 진위여부를 확인합니다. 좀 더 엄밀하게 말하면 Knowledge base(DBpedia)를 활용합니다.
Preliminiary
[Serveral steps for Building a knowledge graph from a knowledge base]
- Data Extraction: The first step is to extract relevant data from the DBpedia knowledge base. DBpedia provides structured data extracted from Wikipedia, represented in the RDF (Resource Description Framework) format. RDF represents information as subject-predicate-object triples, where the subject and object are entities, and the predicate represents the relationship between them.
- Entity Recognition and Linking: The extracted data may contain references to entities such as people, places, organizations, etc. In this step, entity recognition and linking techniques are applied to identify and disambiguate these entities. This involves matching the extracted names or phrases with the entities in DBpedia.
- Relationship Extraction: The next step is to extract relationships between entities. This can be done by analyzing the predicates in the RDF triples. For example, if there is a triple (John, hasOccupation, Engineer), it indicates that "John" has the occupation "Engineer." By extracting such relationships, we can start building the connections in the knowledge graph.
- Graph Construction: Using the extracted entities and relationships, a graph structure is created. Each entity becomes a node in the graph, and relationships between entities become edges. The graph can be represented using various graph database models or formats like RDF or property graphs.
- Entity Disambiguation and Merging: Sometimes, different entities in the knowledge base may refer to the same real-world entity. In this step, entity disambiguation techniques are applied to identify and merge these similar entities. This helps in reducing redundancy and improving the quality of the knowledge graph.
- Enrichment and Linking: To enhance the knowledge graph, additional data sources can be incorporated. This can involve linking external datasets or sources to the entities in the graph, adding more attributes or properties, or expanding the graph with new relationships.
- Ontology Alignment: DBpedia follows a specific ontology that defines the schema and structure of the knowledge base. In this step, the extracted data can be aligned with other ontologies or standardized schemas to ensure interoperability and integration with other knowledge graphs or systems.
- Querying and Analysis: Once the knowledge graph is constructed, it can be queried using graph query languages like SPARQL or graph traversal techniques. These queries allow retrieving specific information or performing complex analysis on the interconnected data.
Summary
WebNLG 라는 ground truth dataset 을 기반으로, 본 논문에서 제안한 방식 KG 도입여부에 따라 신뢰성 향상 의 가설을 검증합니다. 즉, 여러 claim 들을 수집하여 이것을 KG 로 형성하는 과정이 필요한거죠. 본 섹션에서는 그 과정에 대해 이야기 하겠습니다.
1.Reasoning type
graphical reasoning 을 위해 1.one-hop 2.conjuction 3.Existence 4. Multi-hop 5. Negation 5가지 타입으로 나누어 KG subgraph structure pre-define 합니다.
2.Colloquial Style Transfer
여러 사실들을 training 하기 위해 전처리 과정이 필요합니다. 본 논문에서는 1) model-based 2) presupposition 두 가지 방식을 활용하는데요.1) 에서는 T5-plain model을 활용해 paraphrasing을 해주고, 2)에서는 factive , non-factive , sturcutre 글의 어절에 대한 순서 구조에 따라 어떤식으로 가정을 할지에 대한 이야기를 합니다.
3.Quality control
앞서 진행된 1,2 과정을 통해 데이터셋이 형성됩니다. 이 데이터가 과연 적합하게 형성되었는지에 대해 검증이 필요한데요. 이 과정을 모두 hand-craft로 진행했습니다. 즉, 하나하나 모두 사람들이 검증했다는거죠. 그 검증을 한 대상을 보고 경악을 금치 못했습니다.. Labeling strategy “To evaluate this substitution method, randomly sampled 1,000 substituted claims were reviewed by two graduate students”
1,2,3 을 통해 형성된 KG (Subgraph)를 fact verification 에 활용하여 최종적으로 TRM(transformer encoder)에서 Refuted, Supported 를 추론합니다.
Insight
KB → KG 그리고 KG construction 에 대한 프로세스를 익히고 싶으신분들에게 도움이 될거라 생각합니다.
최근 LLM이 급부상함에 따라, reasoning 도 많은 관심을 받고 있습니다. LLM의 결과까진 만족하나 왜 그 결과가 나왔는지에 대한 의문 그리고 신빙성 때문에 그러지 않을까 생각하고 있습니다. 이 의문에 대한 해답을 주로 knowledge base 를 통해 해결하고 있는 추세를 보이고 있습니다.
본 논문에서도 이 해답을 도출하기 위해 활용되는 근거를 gold reference 라고 언급할 정도로 그 중요성을 강조하고 있습니다. 근거로써 활용하기 위해 저희가 해석할 수 있고 기계학습에 적용할 수 있는 전처리가 필요할텐데, 그 과정들을 본 논문에서 잘 전개해주었기에 이쪽 분야에 대해 관심 있으신분들에게 많은 도움이 될 거라 생각합니다.
Valentine: Evaluating Matching Techniques for Dataset Discovery
[https://arxiv.org/pdf/2010.07386.pdf]
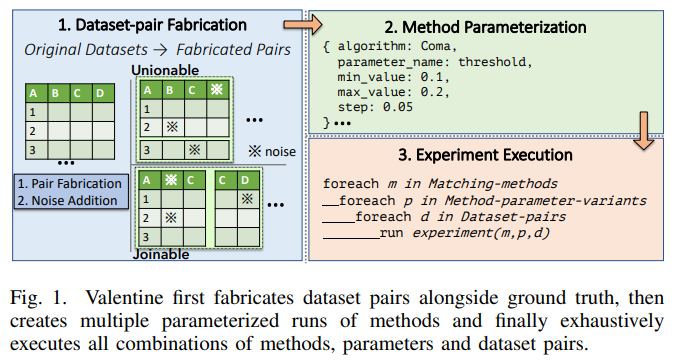
Introduction
Graph modeling 너무나도 중요한 요소죠. Graph analytics , graph machine learning 을 통틀어 가장 중요한 요소라고 저는 생각하기에 이 부분에 대해 고민이 많았습니다. 그렇게 리서치를 하던 도중 Neptune blog [https://aws.amazon.com/ko/blogs/big-data/automate-discovery-of-data-relationships-using-ml-and-amazon-neptune-graph-technology/]에 적힌 포스팅을 보고 어쩌면..? 이라는 생각을 하게 되었는데요. 바로 원시 데이터에서 유의미한 데이터들만을 추출하여 그래프 형태로 만드는 과정을 자동화 할 수 있겠다? 라는 레퍼런스를 찾게 되었기 때문입니다. 늘 상상으로만 생각했던 일을 Neptune 에서 진행했기에 현실성이 있다 즉, 구현이 가능하다! 라는걸 간접적으로 증빙할 수 있는거죠.
Insight
아이디어 자체가 너무나 신선하고 중요하다고 생각한 논문입니다. 그래프를 통해 만나뵙게 되는 분들께서 가지고 계신 고민 중 하나인 그래프를 어떻게 만드는게 좋을지 모르겠어요. 라는 의문에 대해 중요한 지침서가 될 아이디어라 생각합니다. 첨부드린 AWS neptune blog 와 paper 를 모두 일독하시길 강력하게 추천드립니다 !! 너무 너무 중요한 테크닉을 쉽고 재밌게 풀어냈습니다 :)
An Efficient Graph Convolutional Network Technique for the Travelling Salesman Problem
[https://arxiv.org/pdf/1906.01227.pdf]
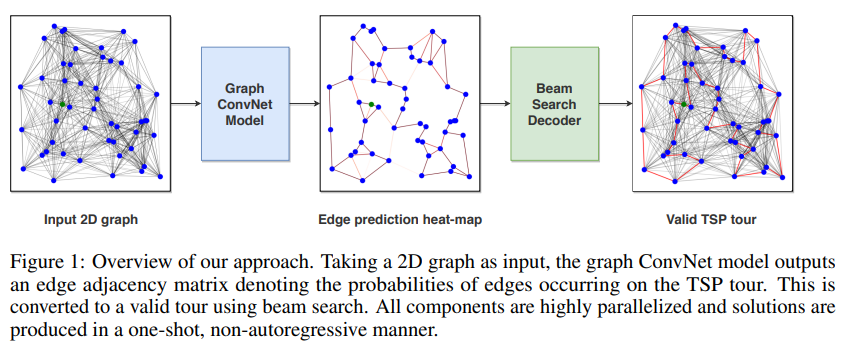
Posting version[w code] - Tackling the Traveling Salesman Problem with Graph Neural Networks
Introduction
Traveling Salesman Problem , target node 까지 optimal path 를 찾는 문제를 의미합니다. 주변 곳곳에서 그 활용처를 볼 수 있는데요. 대표적인 예가 네비게이션이지 않을까 싶습니다. 도착지에 빠르게 도착하고 싶은 유저의 니즈를 충족하기 위해 갖가지 경우의수를 모두 고려하여 최적의 루트를 제공하는것. 하지만 저희가 고려치 못한 내생 , 외생 변수들이 많기에 그 모두를 반영하기엔 한계가 존재합니다.
그렇기에, 합리적이며 효율적인 변수들만을 추출하여 적용하는게 핵심이라 할 수 있는데요. 이 변수들또한 조합방식에 따라 그 효율이 다르기에 어떤 경우의수를 고려해야하는지에 대해서도 생각해야합니다. NP hard 문제라고도 부르는데요. 이를, 해결해보고자 학 산업계를 가리지않고 다양한 시도를 하고 있습니다. 오늘은 그 중, 최적의 Path 를 찾기위해 GNN 그리고 beam search 를 적용한 연구에 대해 알아보겠습니다.
Preliminiary
[Beam search and Greedy search comparsion]
Beam Search:
- Advantage 1: Beam search is a more informed search algorithm compared to greedy search. It explores multiple paths simultaneously by maintaining a beam width, which allows it to consider a set of promising candidates at each step. This increases the chances of finding better solutions compared to a single-minded greedy approach.
- Advantage 2: Beam search can handle local optima better than greedy search. By considering multiple paths, beam search can escape local optima by exploring alternative routes.
- Disadvantage 1: Beam search may not guarantee the optimal solution. The beam width restricts the number of paths considered, and there is a possibility that the best solution is not included in the current set of candidates. Therefore, beam search can be suboptimal in certain cases.
- Disadvantage 2: Beam search requires more computational resources compared to greedy search. The need to maintain and evaluate multiple paths at each step increases the computational complexity, making beam search slower than greedy search.
Greedy Search:
- Advantage 1: Greedy search is simple and computationally efficient. It makes locally optimal choices at each step by selecting the best available option based on immediate gains. This simplicity allows it to quickly find solutions, especially for smaller problem instances.
- Advantage 2: Greedy search can be useful when an approximate solution is acceptable. In some cases, the optimal solution may not be necessary, and a good enough solution obtained quickly through greedy search is sufficient.
- Disadvantage 1: Greedy search can get stuck in local optima. Since it only considers immediate gains, it may overlook better long-term choices. This can lead to suboptimal solutions, especially in complex optimization problems.
- Disadvantage 2: Greedy search lacks backtracking. Once a decision is made, it cannot be undone. If an early choice leads to a suboptimal path, the algorithm cannot backtrack and correct it.
Summary
본 논문의 핵심은 다음 3가지라 할 수 있습니다.
1.Solution quality: optimal cost 를 도출하기 위해 효율적인 ConvNet 를 고안한것.
2.Inference speed: 그간, TSP 문제를 해결하기 위해 주로 autoregressive 방식을 적용했으나 추론시 sequential decoding procedure 때문에 많은 연산량이 필요했습니다. 이를 극복하기 위해 non-autoregressive 방식을 적용합니다. 이 방식이 바로 Beam search 입니다.
바로 눈앞의 최적 대안을 선택하는 Greedy search 대비 다양한 변수들을 heurstic 하게 고려한 방식인 Beam search 를 통해 local optimal 를 극복하였다는게 본 핵심의 요지라고 할 수 있습니다. 그렇다면 여러 변수들을 고른만큼 cost 도 비례하여 커졌을텐데요, 이 때 여러 변수들을 parallized 하게 계산하여 그 cost 에 대한 부하를 줄였습니다.
3.Sample efficiency: 본 문제는 결국 ML문제입니다. 그렇다면 data label 이 필요할텐데요. 기존 방식(reinforcement learning)에서는 data label 를 위해 sampling 할 때, cost 가 상당했습니다. 이를 본 논문에서는 KNN-graph를 활용해 그 cost 를 낮춤으로써, sample efficiency 하게 만듭니다.
Insight
‘실시간성’이 중요한 분야이긴하지만 저는 개인적으로 ‘anisotropic’를 다루기 위해 dense attention map를 적용한 아이디어가 흥미로웠습니다. 그래프 관련 논문들을 볼 때, undirected 를 가정하고 연구를 전개합니다.
graph data domain 에 따라 다르긴 하겠으나 directed , undirected 에 따라 성능이 좋아지고 나빠진다 라는 논문들이 많이 나오는 가운데 그 영향력을 고려하는 하나의 지표로써 활용할 수 있지 않을까 하는 생각에서 재밌었네요.
또한 , 네비게이션 뿐만아니라 공급사슬망에서도 node, edge weight 에 따라 시시각각 바뀌는 상황을 잘 반영하여 최적의 공급, 수요 계획을 세울수 있겠다 라는 생각에서 본 기술이 많은 도움을 줄 수 있을거라 생각합니다.