24년 6월 2주차 그래프 오마카세


안녕하세요 여러분! 이번주말에 기다리고 기다리던 GUG 세미나가 개최됩니다! 이번 세미나는 GraphRAG에 대한 관심이 커짐에따라, Graph의 품질과 연관성이 깊은 온톨로지를 메인 토픽으로 세미나가 진행됩니다.
추가로, Neo4j 를 활용한 DB 설계 그리고 Graph Generation Model 중 하나인 Diffusion model 계열의 트렌드에 대해 알아보며 실무와 학계 경계없는 알찬 주제들로 구성해보았습니다. 그래프에 대한 트렌드를 알아가며 보람찬 주말 오후를 보내보는건 어떠실까요?! 행사 때 뵙겠습니다 😄

신청 링크 :

Graph Neural Network and Superpixel Based Brain Tissue Segmentation
IJCNN 2022
배지훈
Keywords
Medical Imaging, Superpixel clustering, Graph Neural Network, Graph representation Learning
Summary
- 최근 의료 이미지 도메인 상에서 그래프 표현 학습을 적용하는 연구들이 많이 증가하고 있습니다. 뇌 구조, 세포 활동 등의 복잡한 상호관계를 유연하게 표현할 수 있는 그래프의 장점을 최대한 활용하여 CNN의 구조적 메커니즘 한계를 극복하고 다양한 Tasks 상에서 인상적인 성능을 보여주고 있습니다.
- 하지만, 직접적으로 이미지 위에 그래프를 생성하는 방법은 큰 한계점이 존재합니다. 픽셀 개수에 비례하여 그래프 크기가 커지기 때문에 컴퓨팅 파워에 따라서 연산적 한계가 쉽게 발생할 수 있습니다. 예를 들어, 28 x 28 크기의 작은 이미지라 하더라도 784개의 노드를 갖는 꽤나 큰 그래프가 구성되어지게 됩니다. 이러한 그래프를 데이터로더에 직접 올려 학습을 하고자 할 때, 상당한 메모리 요구가 발생할 수 있습니다.
- 다음 한계를 완화하기 위하여 등장한 방법이 바로 픽셀 클러스터링된 이미지, 혹은 슈퍼픽셀 이미지, 상에 그래프를 구성하는 것입니다. 확실하게 그래프 크기도 효율적으로 줄일 수 있으면서, 중요한 정보에 더욱 집중되어 학습시킬 수 있는 장점을 가질 수 있습니다.
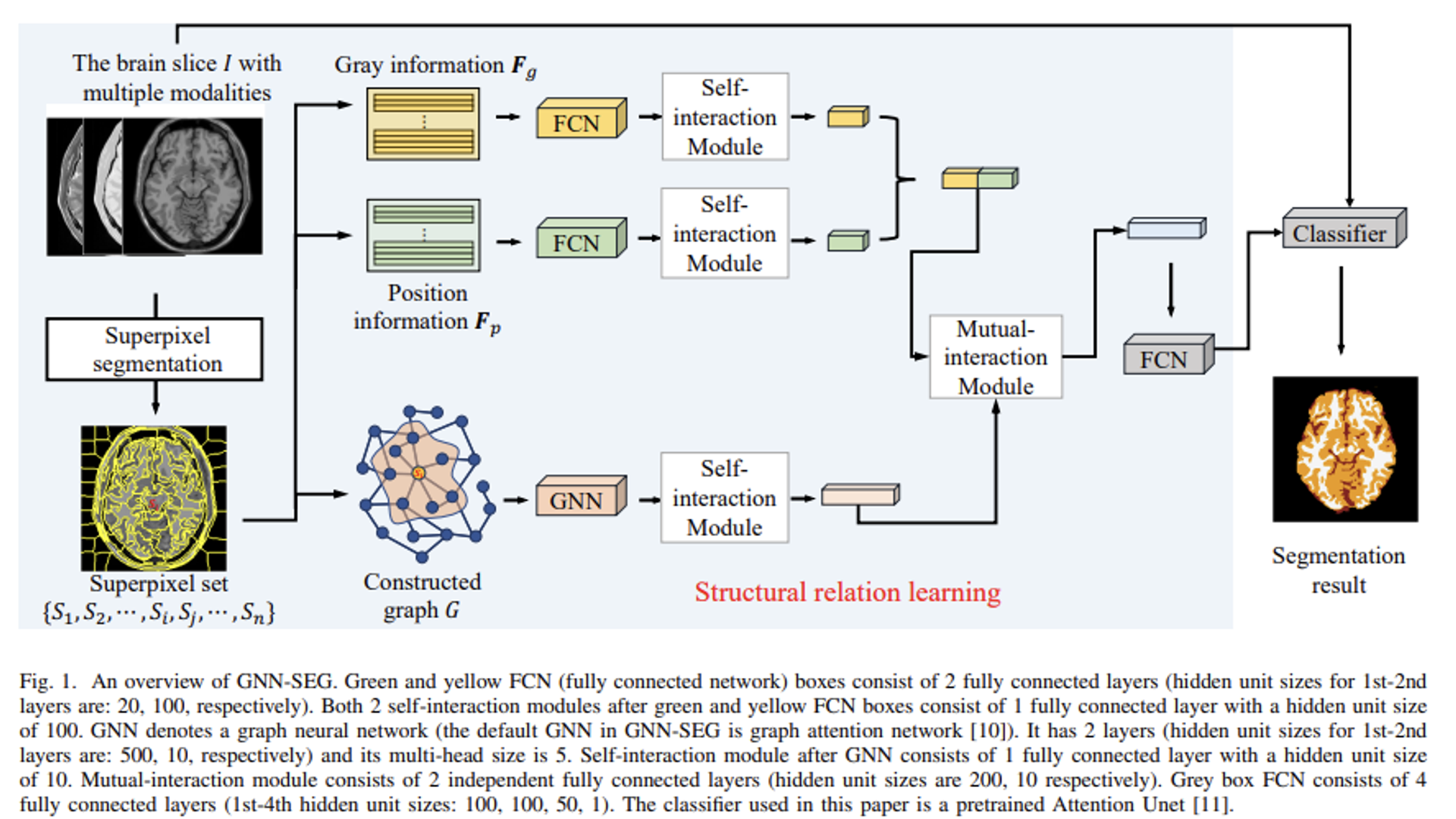
- 다음 논문에서는 슈퍼픽셀 이미지의 특징, 픽셀 평균 값 및 위치정보를 활용, 을 잘 포착해낼 수 있는 FCN 블록과 슈퍼픽셀 간 구조적 관계성을 포착해낼 수 있는 GNN, 여기에서 GAT를 활용,을 동시에 차용하였습니다. 추가적으로 각 블록으로부터 출력되어진 벡터들 간 내부적 상호작용 메커니즘을 활용하기 위해 다른 파라미터를 갖는 FCN 블록을 추가 배치하여 Self-interaction Module를 설계합니다.
- 마지막으로 이미지 특징 및 그래프 특징 사이의 상호작용도 같이 포착하기 위한 Mutual-interaction Module를 추가 설계하여 배치시킴으로써 풍부한 정보들을 바탕으로 분할 작업을 수행합니다.
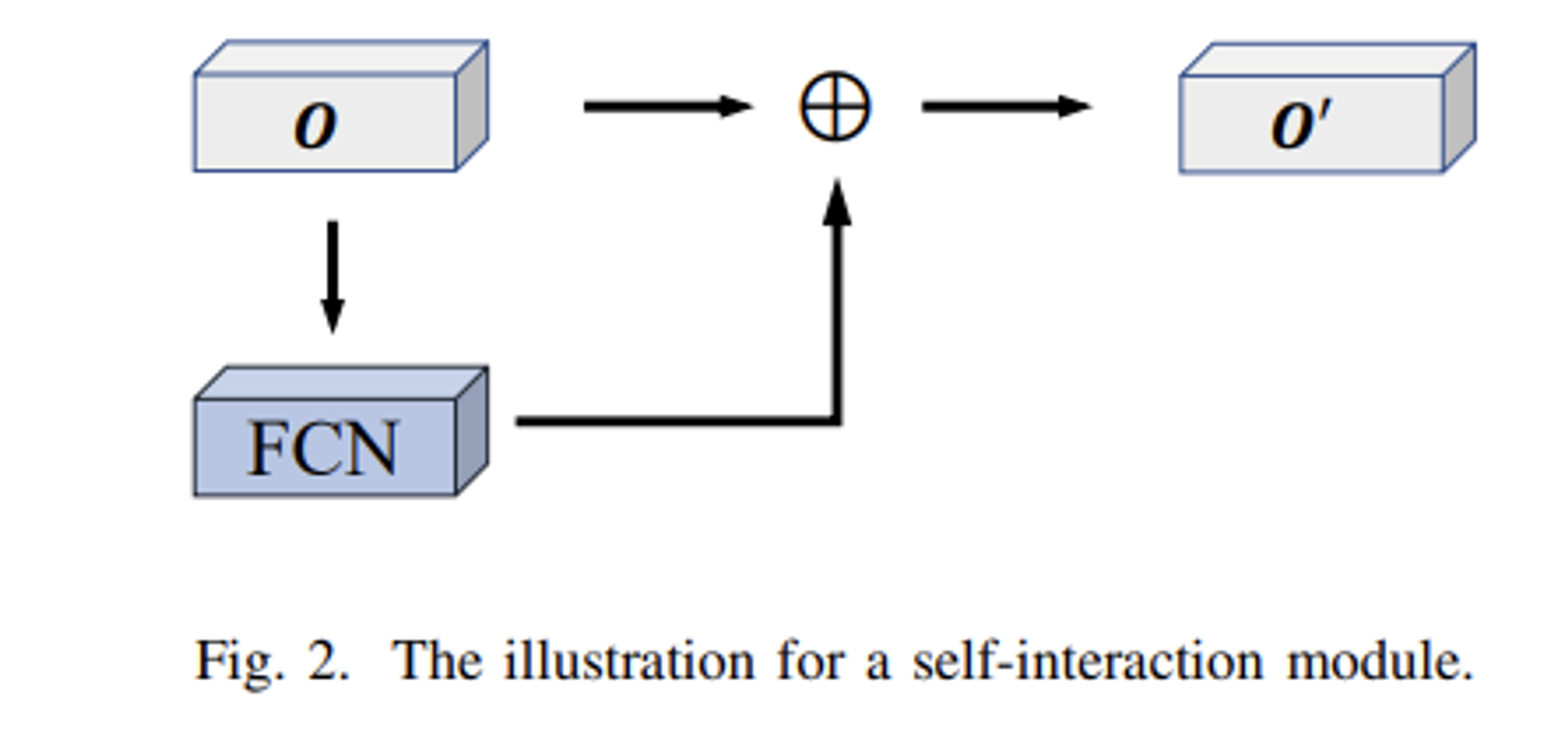
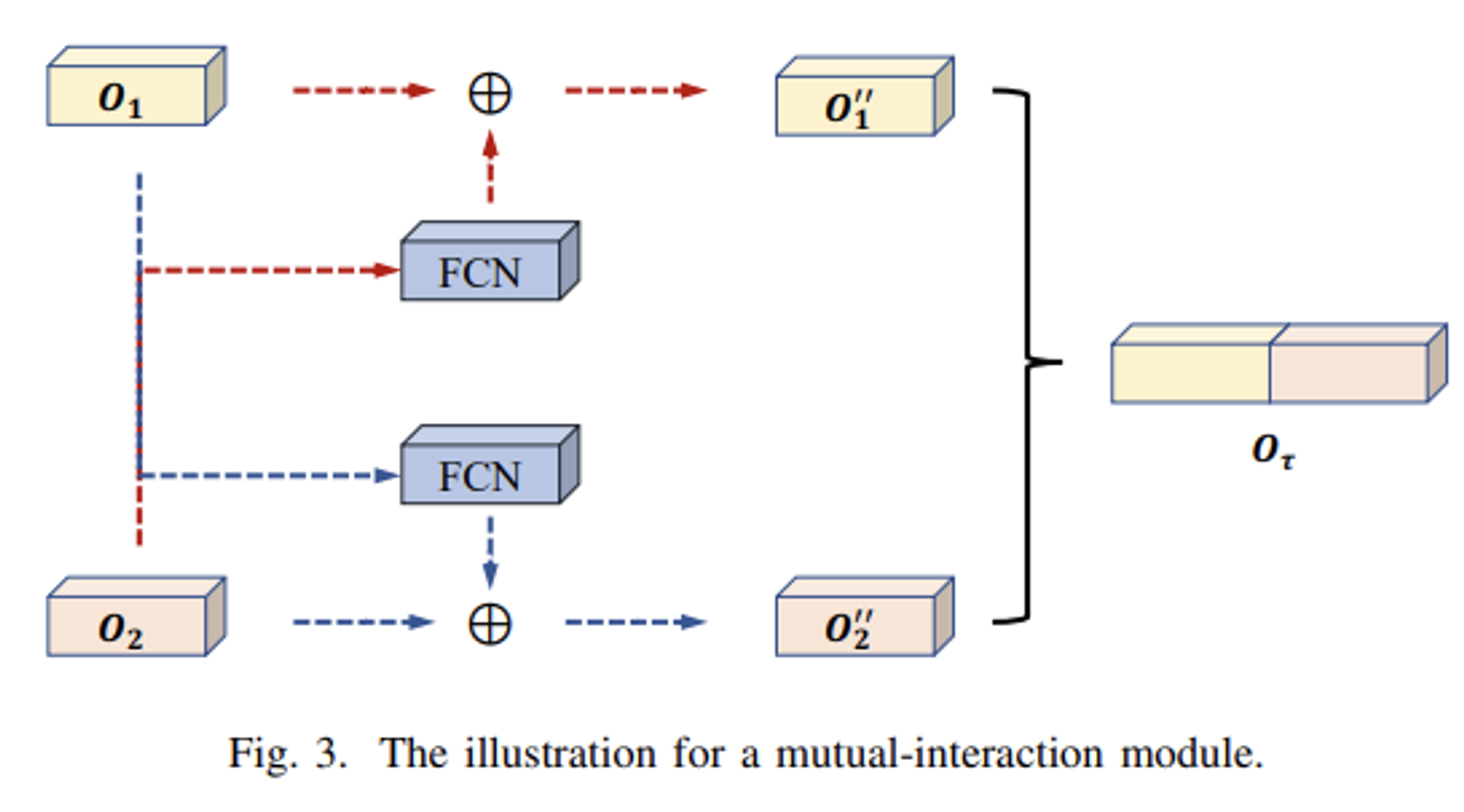
- 다음 구조를 갖는 제안 모델을 GNN-SEG라고 칭하였으며, 생성 데이터셋 Brainweb을 기반으로 3가지 평가 지표 (Dice, TP, APD) 상에서 기존 CNN 방법들보다 좋은 성능을 얻어낼 수 있었음을 본 논문에서 보여줍니다.
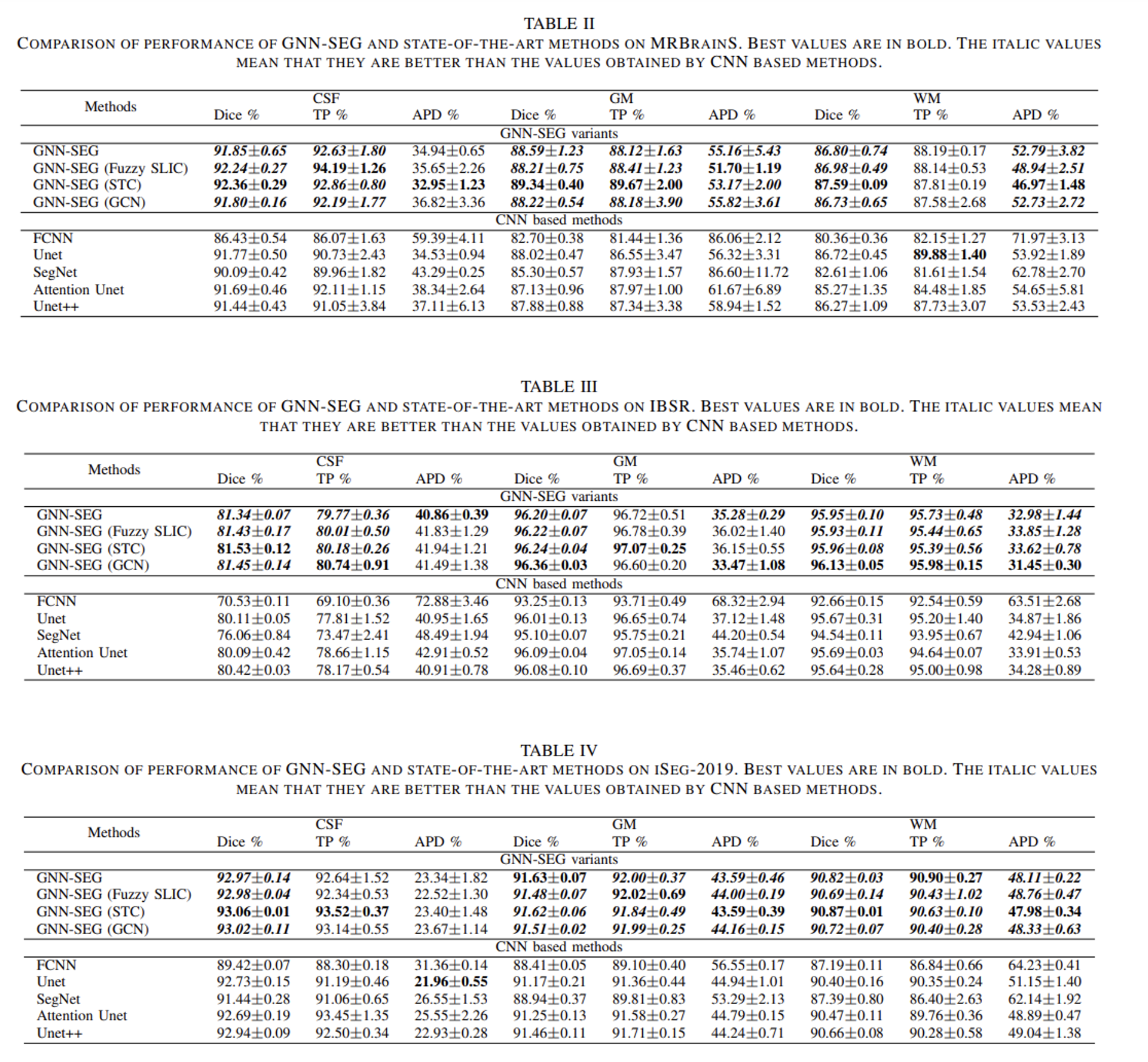
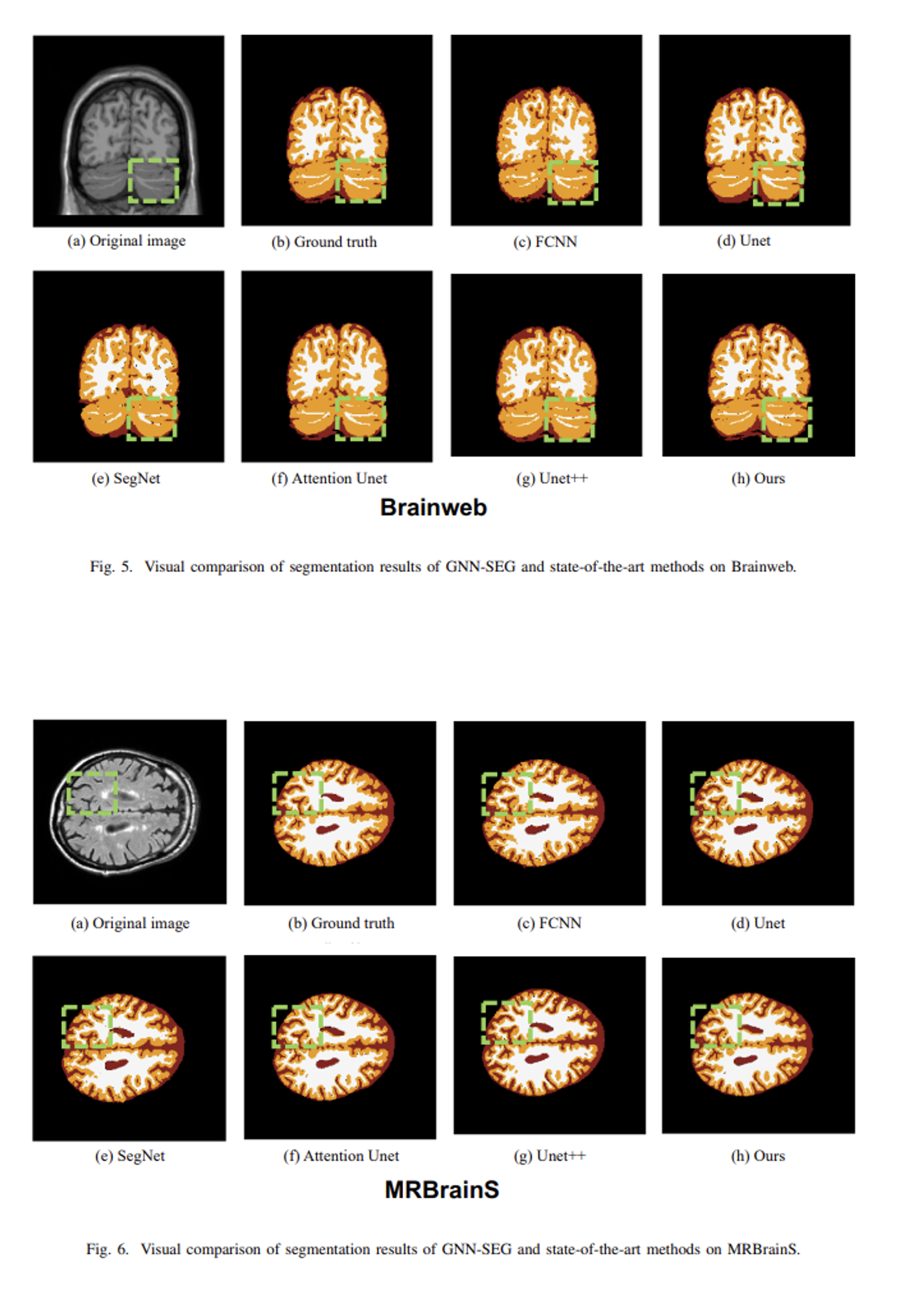
- 위 내용을 간략하게 요약해본다면, 연산적 한계를 해소하기 위해 슈퍼픽셀 이미지로 전처리된 입력 MRI 상의 특징정보들을 내부적, 외부적으로 모두 포착하는 두가지 새로운 모듈을 배치시켜 의료이미지 분할 도메인 상에서 인상적인 성능을 달성할 수 있는 그래프 표현 학습 방법을 소개해주었습니다.
[Contact Info]
Gmail : jhbae1184@akane.waseda.jp
Twitter (X): @jhbae1184
From Local to Global: A Graph RAG Approach to Query-Focused Summarization.
https://arxiv.org/pdf/2404.16130
정이태
Microsoft에서 야심차게 준비한 GraphRAG 오픈소스를 다룬 논문을 가져왔습니다.
제가 생각하기에 여러분들이 이 논문을 보시면서 곰곰이 생각해보고, 얻어가시면 좋겠다 싶은 3가지는 다음과 같습니다.
- 기존 RAG의 어떤 점을 문제로 정의하였고, 이를 기반으로 왜 GraphRAG를 솔루션으로 택했는지까지의 논리
- GraphRAG의 당위성을 고려하시는 분들께서 많이 하시는 고민일거라 생각들어요. RAG 에서 어떤 점이 부족하여 Graph를 Retrieval하는지를요. 그 관점을 견지하며 논문을 읽어보는게 좋아요.
- 본 논문에서의 GraphRAG 워크플로우
- 기존 GraphRAG들의 워크플로우 방식들과 다른 방식으로 GraphRAG를 구현합니다. 어떤 점이 다른지를 고려해보시면 좋아요.
- 평가 방식
- 산업에서 RAG의 평가 방식에 대한 연구가 활발한 가운데, 다소 새로운 분야인 GraphRAG 에서는 어떻게 평가를 할지에 대한 호기심을 가지고 논문을 보시면 좋아요.
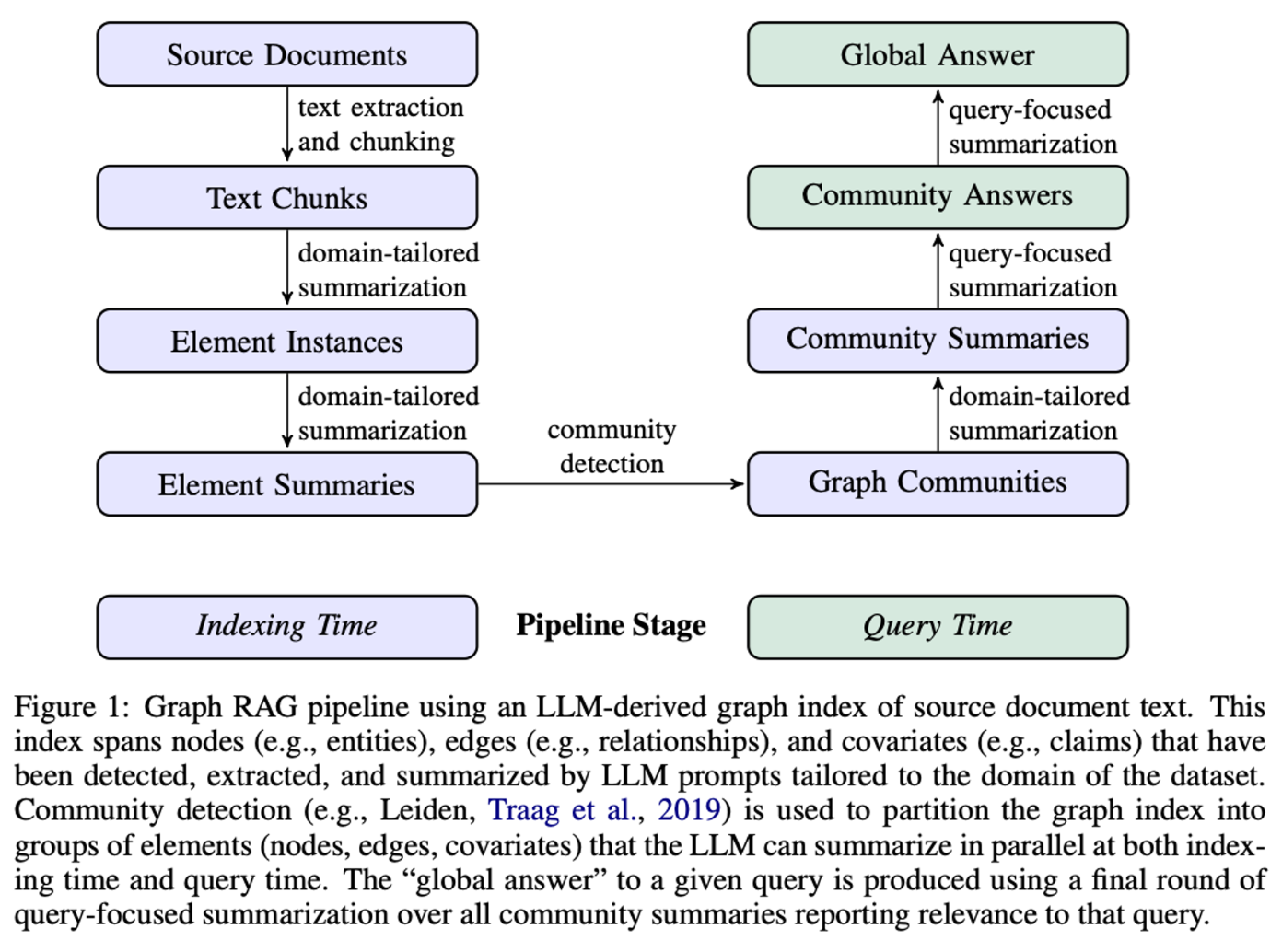
GraphRAG 논문을 자주 보셨던 분들이라면 Figure1을 보고 흠칫 하시지 않았을까 싶네요. 갑자기 Community Detection 이라니? 라는 단어가 그 원인이지 않을까 하네요. 사실 한동안 네트워크 사이언스 논문만 보았다가 LLM의 트렌드에 휩쓸려 RAG 공부를 시작한 저에게는 굉장히 반가운 단어였습니다. 주구장창 보았던 Community detection이 여기에..! 하면서요. 기존에 많이 보아왔던 개체명인식기가 핵심이였던 GraphRAG와는 조금 다른 방식으로 접근하구나? 라는 생각이였습니다.
잠시 RAG(Retrieval Augmented Generation)에 대해 이야기해보겠습니다. RAG가 화두가 된 이유는 LLM 프롬프팅이 답변 생성에 유의함이 입증되며, 프롬프트 내 답변 생성에 도움이 될만한 정보를 가져다주면 좋을것이다. 그리고 이 정보를 가져다주는 비용을 파인튜닝과 비교해보니 상당히 저렴하다. 라는 측면이 가장 큰 이유였지 않았을까 하네요.
그럼 여기에서 또 이슈가 발생합니다. 정보를 가져다 주긴하나 너무 긴 context 때문에, 도중에 그 정보를 LLM이 잃어버리거나 (lost in the middle), 부정확한 정보를 가져다주니 LLM이 정직하게도 성능이 바로 감소되어버리는 이슈가 발생하는거죠.
결국 LLM이 아무리 긴 context (token limit)을 가지고 있다하더라도, context 들끼리 잘 조합시켜주어야 그 성능이 잘 발휘한다는것을 간접적으로 저희는 여러 논문 및 산업계 발표를 통해 보아왔습니다.(Chain of Thought…)
본 논문은 context(Source Document)들을 그래프 관점으로 접근하여, Community detection 알고리즘을 적용해 그 내에서 커뮤니티(연결관계가 유사한 element)들을 활용해 거시적 , 미시적 관점으로 context를 추출해 LLM에게 전달합니다.
한 경우를 예로 들어서 생각해보겠습니다. “이 데이터셋의 메인 테마는 무엇이야?” 라는 거시적인 관점의 질문이 들어오게 된다면, LLM은 모든 데이터셋을 살펴보고 ‘메인 테마’를 추출하는 업무를 진행하게 됩니다. 하지만, 여기에서 데이터셋이 너무나도 클경우 context를 진행함에 따라 좀전에 이야기한 바와같이 ‘맥락을 잃어버리는’문제가 발생하게 됩니다.
이를 개선하고자 본 논문에서는 Source Document 를 하이퍼 파라미터인 chunk size에 맞춰 나누어줍니다. 다음은 결과물인 chunk 내에 entity를 추출합니다. 이 때, chunk의 Text에 담겨있는 name , type 그리고 description 3가지를 중점으로 element 를 가져옵니다. 이 때, entity 의 범주를 지정하여 특정 카테고리에 특화된 element 를 가져올 수 있습니다. 이를 본 논문에서는 domain-tailored summarization 이라 이야기합니다. 어떤 도메인을 입력해주느냐에 따라 element가 달라지기 때문입니다. 추가로, 추출된 element(node)들간 공변성을 정보로 담기 위해 claims 라는 링크를 통해 subject, object , type ,description , source text span 그리고 시작 , 끝 날짜 등의 정보를 추가로 추출하여 관리합니다.
방금 과정에서 추출된 요소들 중 description를 기억하실까요? 이 요소는 LLM에게 text를 description 엔티티로 추출하라 했기에, 자연스럽게 abstraction summarization된 결과물이라 볼 수 있습니다. 이를 활용해 각각의 document , chunk 의 맥락이 1차적으로 완성이 된거죠. 하지만, chunk 만의 결과를 기반으로 description이 형성된 결과물을 전적으로 신뢰하기 어렵기에 추가적인 instance matching 을 통해 chunk 들간 시멘틱을 추가로 활용하여 정보를 추가해야한다는 점을 논문에서 이야기합니다.
이렇게 도출된 노드 - 엣지들을 기반으로 Leiden 알고리즘을 적용하여 community 를 도출합니다. 이를 통해 hierarchical community structure 를 형성되고, 각각의 노드들은 mutually-exclusive, collective-exhaustive 형태의 정보를 가지게 됩니다. 이 부분이 중요한데요. 직접적인 연결이 되어있지 않은 노드들이라 하더라도, 전역적으로 community detection을 진행했기에, 간접적으로 연관이 있을것 같은 유사한 노드들끼리 community로 편입되고 발견할 수 있게됩니다.
Community detection 으로 2분류의 커뮤니티가 형성됩니다. Root , Sub-community 각각 커뮤니티는 modularity (커뮤니티가 잘 나눠진 정도)에서 가장 최상단이 되는 노드들 그리고 그 아래 속해있는 노드들을 의미합니다. Root, sub 를 통해 여태까지 만들어온 그래프 내 노드들끼리 위계가 생기게 됩니다. 구체적인 위계 단계는 root , high , intermediate , low 형태로 나눕니다. 이 위계를 활용해 어떤 정보를 LLM context으로 주입할 지 판단하게 되는거죠. 만일 User query 가 전역적 질문 국소적 질문의 비율이 8:2라 하면, 전역적 질문은 Root 위계에 속한 형태 부터 답변하는게 좋기에 이를 고려하여 token context로 배치하게 됩니다.
본 논문 아이디어가 유용한지 판단하기 위해 총 6가지 조건을 지정하여 각 상황마다의 결과값을 확인합니다. 각 위계인 root , high , intermediate , low 4가지 조건 , 위계 없이 단순히 chunk 마다의 suumarization만 진행된 조건 그리고 기존에 주로 활용하던 Semantic Search를 활용한 조건
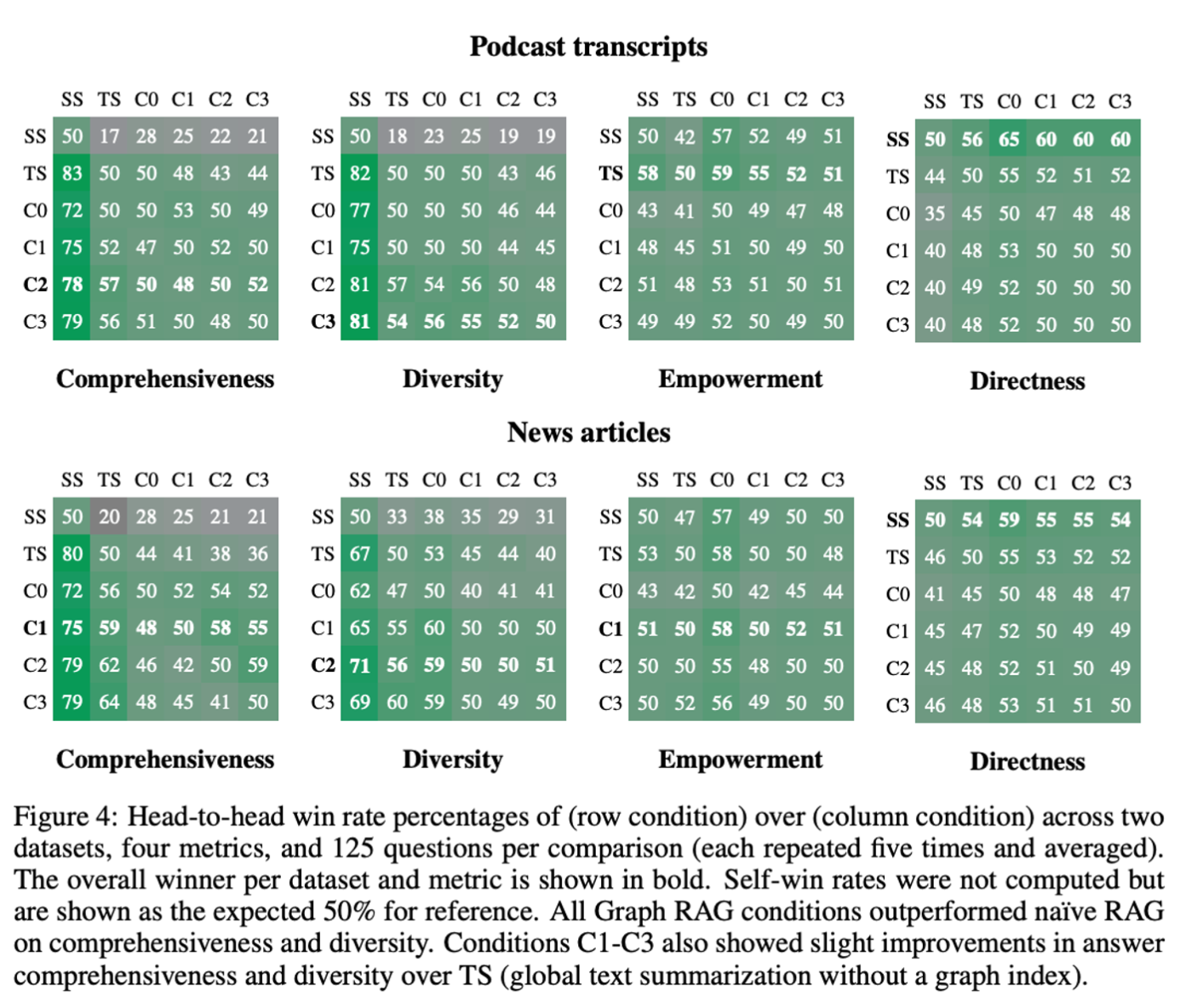
각각 조건마다의 결과값을 비교하기 위해 Comprehensiveness, Diversity, Empowerment, Directness 4가지 요소들을 측정기준으로 활용합니다. Global approach 와 Naive RAG 그리고 Community summaries 와 source texts 관점으로 실험에 대한 해석을 진행하는데 그 결과가 굉장히 재밌습니다. 주로 토큰 소요비용 대비 4가지 지표들의 결과가 어떻게 다른지에 대해 비교합니다. GraphRAG를 구현함에 있어 마냥 궁금했던 부분들에 대한 힌트를 얻기 좋은 결과들이기에 꼭 한 번 살펴보시는걸 추천드립니다.
참고하시면 좋을 자료
https://aws.amazon.com/ko/blogs/tech/amazon-bedrock-graph-rag/ , 본 논문에서 이야기한 내용들의 앞부분인 Document - Chunk 를 어떻게 구현하는지가 상세히 설명된 자료입니다. (저도 주기적으로 다시 볼 만큼 굉장히 설명이 잘 되어 있습니다.)
https://arxiv.org/abs/2402.11199 , 본 논문과 다르게 Multi-hop reasoning 을 통해 Evaluation 하는 논문입니다. 어떤 차이가 있는지를 중점으로 보면 대략적으로 GraphRAG가 어떤식으로 진행이 되구나 하며 감이 오실겁니다.