6월 2주차 그래프 오마카세


Graph Travel 1화, members only
[www.graphusergroup.com/graph-tutorial-1/]

Graph Travel 1화가 막을 열었습니다. Preview 는 다음과 같습니다.
- Graph & Subgraph & Degree
- Undirected Graph & In-degree & Out-degree
- Weight & Connectivity & Centrality
- Density & Adjacency Matrix
코드와 함께 Graph 기초 개념을 다룬 튜토리얼이다보니 누구나 쉽게 접할 수 있을거라 생각되네요! 본 콘텐츠를 통해 그래프를 공부하고 싶었으나, 어렵다고 느껴져 망설였던 분들에게 많은 도움이 될 거라 생각됩니다.
Spatio-Temporal Meta-Graph Learning for Traffic Forecasting
[https://arxiv.org/pdf/2211.14701.pdf]
Introduction
그래프 입문할 때를 더듬어보시면 기억이 나실듯 합니다. Königsberger Brückenproblem , 다리 7개를 통해 어떻게 효율적으로 목적지로 도착할 것인가? 를 해결하는 문제죠. 이 고전 문제를 현대에 대입해보면 저희가 흔히 사용하는 지도앱에서 최단거리 도착계획 기능이라고 볼 수 있습니다.
최단거리를 실시간으로 반영하기에도 벅찰텐데, 도로마다 Incident awareness, rush hour 등 돌발 상황이 발생하였을시 이에 따라 즉각적으로 최단 거리를 계획 , 연산 및 적용하는 3가지 과정을 빠르고 정교하게 하는것이 지도 서비스에서 핵심 역량이라고 할 수 있습니다.
이 핵심 역량 개발을 위해 관련 서비스 회사들은 한가지 챌린징을 두고 고민을 하고 있습니다. 바로, 즉각적으로 발생하는 여러 요소들을 동시에 어떻게 최적화 할것인가? 입니다. 여러 요소들이라 말씀드렸지만, 개중에 중요한 요소를 꼽자면 time variant(시간) , input signal(공간) 두 가지라고 할 수 있습니다.
이 두가지 요소를 그럼 그래프로 어떻게 접근할 수 있으며 퍼포먼스에 기여할 수 있을까요? 본 논문에서 그에 대해 이야기합니다.
Preliminary
[Spaito-temporal learning]
그래프 신경망(GNN)에서의 spatio-temporal learning 은 그래프로 표현된 데이터의 공간적 및 시간적 패턴을 학습하는 task를 의미합니다.
- 그래프: 그래프는 노드(node)라 불리는 개체들이 관계(edge)로 연결된 수학적인 구조를 나타냅니다. GNN의 맥락에서 그래프는 노드가 개체(예: 사용자, 분자, 위치 등)를 나타내고, 엣지는 이러한 개체들 간의 관계 또는 상호작용을 나타냅니다.
- 공간 학습: GNN의 공간 학습은 그래프 내 이웃 노드들 사이의 패턴과 관계를 파악하는 것을 의미합니다. 그래프 내의 각 노드는 엣지를 통해 이웃 노드들과 연결되어 있으며, 공간 학습은 주변 노드로부터 정보를 수집하고 처리함으로써 각 노드에 대한 지역적인 문맥 정보를 파악하는 것을 목표로 합니다.
- 시간 학습: GNN의 시간 학습은 그래프 데이터 내에서 시간적인 패턴과 변화를 파악하는 것을 의미합니다. 이는 그래프 구조가 변화하거나 노드와 엣지의 특성이 동적으로 변하는 상황에서 특히 중요합니다. GNN은 역사적인 정보에 기반하여 노드와 엣지 특성을 업데이트함으로써 시간적인 의존성을 모델링할 수 있습니다. 이를 통해 그래프의 미래 상태를 학습하고 예측할 수 있습니다.
- 공간-시간 학습: 공간-시간 학습은 GNN에서 공간적 및 시간적인 측면을 결합하여 그래프 내에서 발생하는 복잡한 패턴을 파악하는 것을 의미합니다. 이는 노드와 엣지 간 상호작용으로부터 발생하는 복잡한 패턴을 파악하기 위해 지역적인 공간 패턴과 그래프 구조 및 특성의 시간적 의존성을 모델링하는 것을 포함합니다. 공간과 시간 정보를 동시에 고려함으로써 GNN은 그래프로 표현된 동적 시스템의 동작을 효과적으로 모델링하고 예측할 수 있습니다.
요약하자면, GNN의 공간-시간 학습은 그래프로 표현된 데이터의 지역적 패턴과 시간적 의존성을 모두 파악하여 기반 시스템의 동적인 특성을 이해하고 예측하는 능력을 갖추는 것을 의미합니다.
Summary
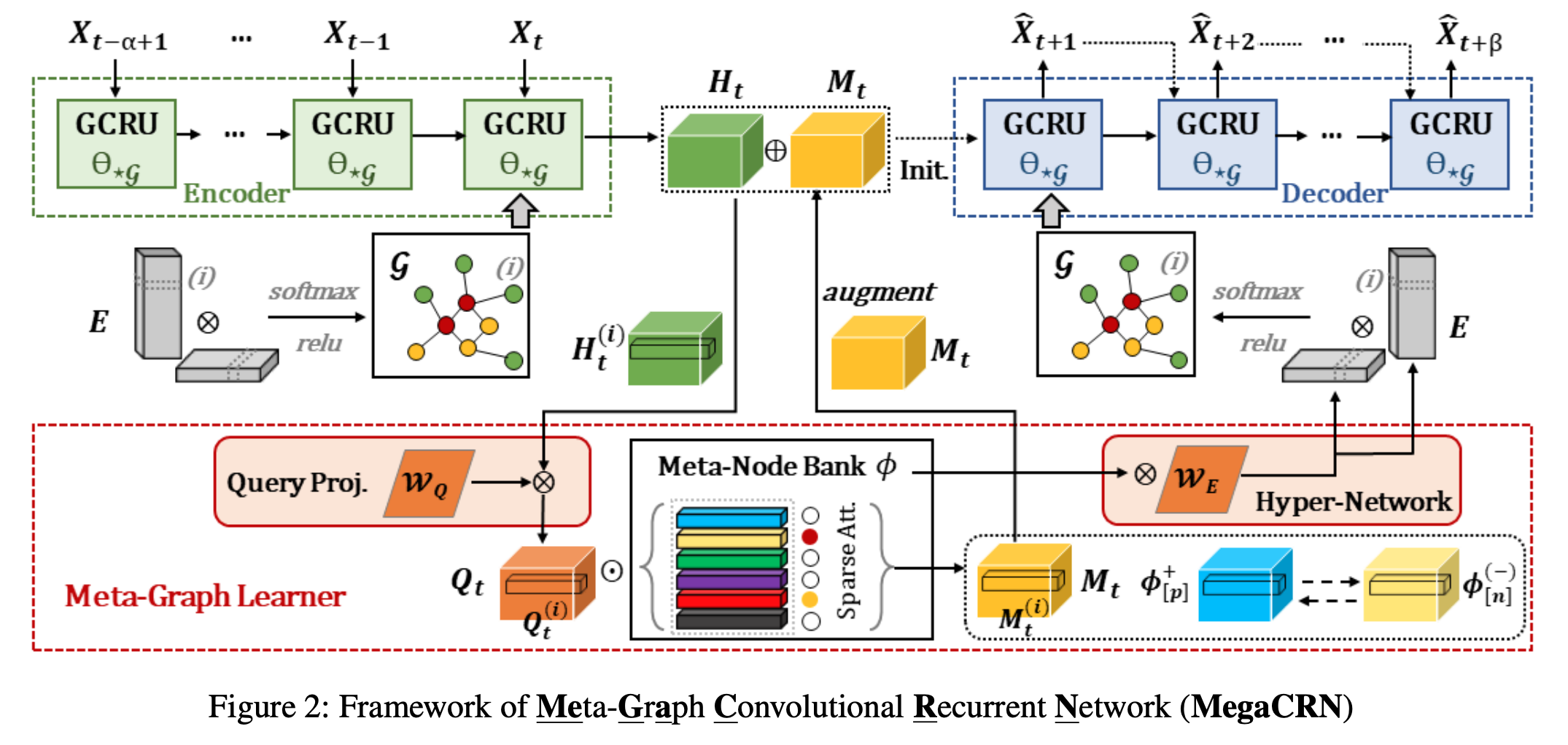
공간 , 시간 두 요소를 동시에 최적화하여 과거 패턴을 기반으로 미래 패턴을 예측하는게 핵심이라고 할 수 있겠습니다. Figure 2의 윗부분은 GCRU 라는 아키텍쳐를 활용했습니다. 간단하게 GCN 에 time variant 를 적용하기 위해 GRU 를 추가한 모델이라고 보시면 되겠습니다. 여기에서 GCRU는 Meta-Graph Learner 라는 본 논문의 핵심 아이디어를 활용하기 위해 사용하는 툴 중 하나로써 마이너한 역할을 합니다.
그럼 Meta-Graph learner 는 무엇일까요? 다음 3가지 요소를 통해 구성되어 있습니다.
Meta-Node Bank
본 논문의 핵심입니다. 직역하면 메타 데이터를 보관하는 공간을 따로 만들어 적재적시에 활용하는 공간을 따로 마련해두었다고 보시면 되겠습니다. 그럼 이 meta-node bank 가 왜 필요한걸까? 라는 의문이 드실텐데요. 메타 데이터 관리와 비슷합니다. 여러 경우의 수들을 저장해둔뒤, streaming 으로 들어오는 데이터를 하나하나 모두 재학습하고 추론하기에는 한계가 존재하니 이 때 이 meta 정보와 비슷한지를 파악하고 scope 를 줄인 후 추론하는거죠. 다시말해, 컴퓨터의 cache memory 와 비슷한 기능을 한다고 보시면 되겠습니다.
HyperNetwork
앞에서 만들어진 memory(meta) 들을 추가로 활용하기 위한 방법론입니다. memory 들을 기반으로 형성되어 있는 meta-graph 정보들을 FC layer 에 태워 weight 를 도출한 뒤, decoder init layer 에 agumentation information inject 합니다. 다시 말해, decoder start layer (GCRU) weight 에 meta 정보를 반영(공유)하기 위함이 본 과정의 목적이라 할 수 있습니다.
Loss function constraint for robustness.
비슷한건 비슷하게 , 비슷하지 않은건 비슷하지 않게끔 학습하는 loss function을 활용합니다. meta-node bank에서 도출된 node 정보들이 있을텐데, 이 정보들간의 similarity 기반으로 비슷한 패턴은 더욱 비슷한 임베딩 벡터로, 비슷하지 않은것은 정반대로 유도하는게 목적입니다. 이 과정을 통해 최종적으로 meta , pos 그리고 neg pattern 들이 학습된 weight 를 가진 New layer(GCRU) 가 탄생합니다.
크게 나누어보면 meta 를 반영하지않은 레이어 그리고 반영한 레이어가 앞선 과정을 통해 도출되는데요. 이 두 레이어를 concat하여 inference 합니다.
Insight
weight sharing 을 위한 network , HyperNetworks [https://arxiv.org/pdf/1609.09106.pdf]
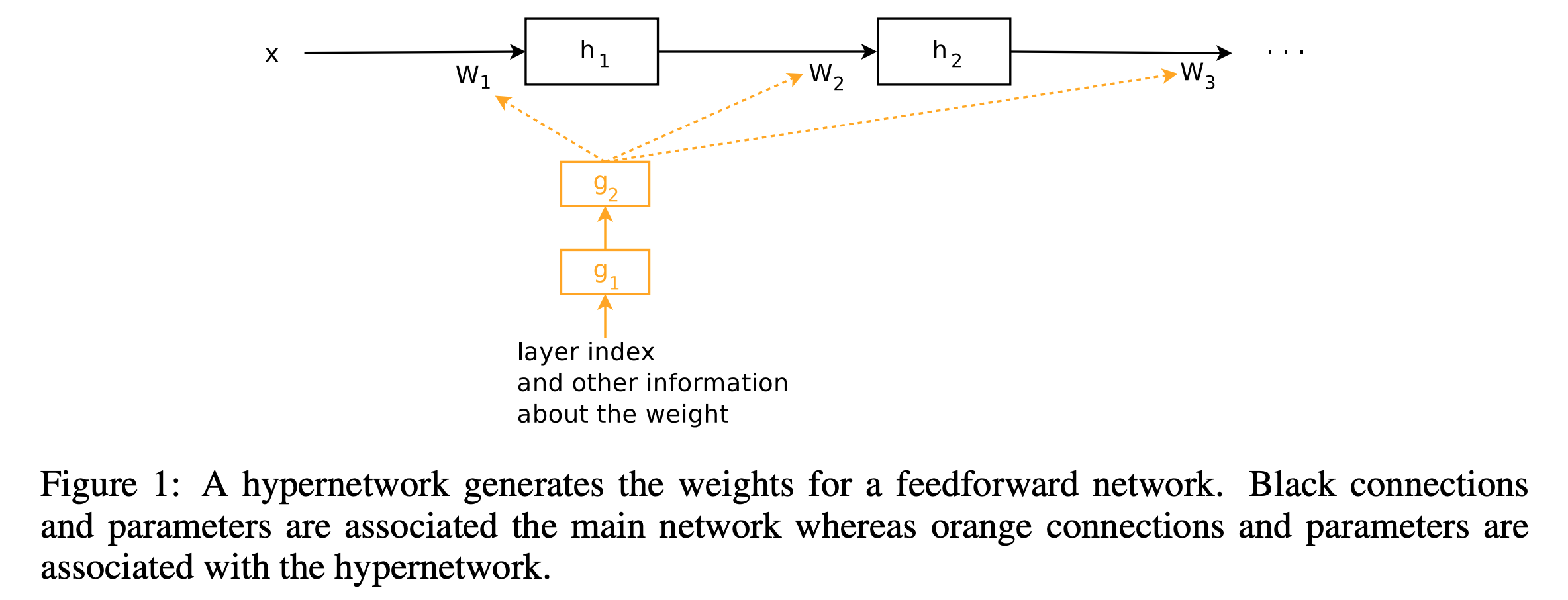
하이퍼네트워크는 신경망에서 다른 네트워크의 매개변수(가중치)를 생성하거나 공유하기 위해 사용되는 기술입니다. 가중치 공유를 위한 하이퍼네트워크는 특정 입력 조건이나 맥락에 기반하여 네트워크 가중치를 동적으로 생성하는 유연한 메커니즘을 제공하여 여러 방면으로 많이 활용되고 있습니다. 본 기술에서는 meta weight 반영을 위해 사용되었으나, 이외에도 Recommender system , abnormal deteciton 과 같은 meta 정보가 필수적인 분야에서 유용하게 쓰일거라 생각되네요.
Temporal Knowledge Graph Reasoning with Historical Contrastive Learning
[https://arxiv.org/pdf/2211.10904.pdf]
Introduction
지식그래프 관계 추론은 기존 그래프 관계 추론보다 더욱 어려운 task 라고 할 수 있습니다. 사실(knowledge)에 기반한 데이터를 통해 추론해야하기 때문이죠. (s,p,o) 중 하나를 예측하는 task 난이도가 높은건 기정사실인데, 여기에 temporal 상황까지 부여된 (s,p,o,t) quadruple task 는 얼마나 더 어려울까요? 예를 들어보자면, 이전에는 나는 사과를 OO 가 기존 task 였다면 여기에 나는 언제 사과를 OO 와 같이 ‘언제’ 라는 time 요소가 들어가기에 그 난이도가 더욱 어려워집니다.
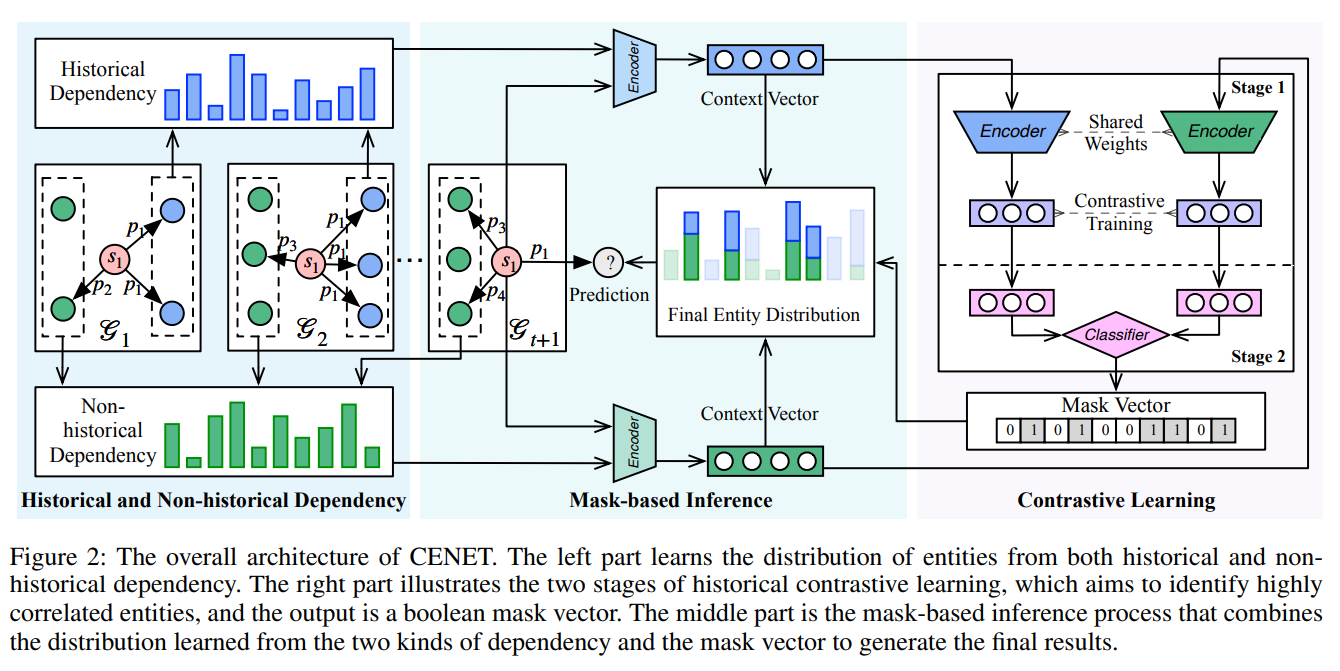
본 논문에서는 어려워진 난이도를 극복하기 위해 historical , non-historical dependency 를 활용하는 아이디어를 제안합니다.
*s-subject , p-predicate , o-object
Preliminary
[contrastive learning]
그래프 신경망에서 대조 학습(contrastive learning)은 데이터의 유사도와 차이를 활용하여 모델을 학습시키는 방법입니다. 대조 학습은 그래프 데이터에서 유의미한 표현을 학습하는 데 사용되며, 다양한 응용 분야에서 유용하게 적용될 수 있습니다.
대조 학습은 다음과 같은 방식으로 작동합니다:
- 양성 쌍과 음성 쌍 생성: 먼저, 그래프 데이터에서 양성 쌍(유사한 쌍)과 음성 쌍(차이가 있는 쌍)을 생성합니다. 양성 쌍은 유사한 특징이나 속성을 가진 두 개체로 구성되며, 음성 쌍은 다른 특징이나 속성을 가진 개체로 구성됩니다.
- 임베딩 생성: 생성된 양성 쌍과 음성 쌍을 그래프 신경망에 입력하여 개체의 임베딩(저차원 표현)을 생성합니다. 임베딩은 개체를 유사성에 따라 공간 상에서 가까운 위치에 매핑하는 역할을 합니다.
- 유사성 및 차이 강화: 생성된 임베딩을 기반으로 유사성을 강화하고 차이를 구별할 수 있는 방법을 적용합니다. 일반적으로는 유클리디안 거리나 코사인 유사도를 사용하여 양성 쌍 간의 거리를 최소화하고 음성 쌍 간의 거리를 최대화합니다.
- 손실 함수 최적화: 유사성과 차이를 기반으로 손실 함수를 정의하고 이를 최적화하여 그래프 신경망을 학습시킵니다. 대표적인 손실 함수로는 contrastive loss나 triplet loss 등이 사용됩니다.
Summary
historical , non-historical dependency 를 활용하기 위해 contrastive leanring 개념을 활용합니다. 쿼리가 주어졌을때(s,p,?,t) , 이 쿼리가 어느 historical , non-historical factor 에 좌지우지되는지를 확인하여 context vector 를 생성하고, 그 vector 에 기반하여 inference 를 합니다. 이때, inference efficiency 를 위해 masked-technique 를 활용합니다.
그렇다면 여기에서, ‘좌지우지 되는지를 확인한다’에서 무엇을 통해 확인하는지에 대해 궁금하신 분들이 계실텐데요. 바로 similarity score function , frequency score function 입니다. 간단히 말씀드리자면, 내적곱을 통해 유추하고자 하는 query 와 similarity 를 측정하는 function 과 특정 Time 전에 해당 query 가 얼마나 frequency 발견되는지를 indicator operator을 통해 1과 0으로 표현하는 function. 이 두가지를 통해 time dependency 를 측정하여 Context vector 로 정량화 합니다.
Insight
Ablation study 가 진국이라 생각합니다. hard-mask,soft-mask, positive ratio 그리고 negative ratio 등 아이디어 component 마다 성능차이를 확인함에 따라, 무슨 요소들이 KGE 에 영향을 미치는지에 대해 유추해 볼 수 있기에 향후 이런 task 를 맡게되신분들로 하여금 good starter point로 활용될 수 있을거라 생각되네요.
추가로, KGE embedding baseline 과 본 논문의 아이디어에서 결과를 비교해보며 왜 baseline 보다 성능이 높은지 라는 본연적인 물음을 해결하시다보면 Knowledge graph embedding 에 대한 전반적인 프레임을 익힌 여러분들의 모습을 발견하실 수 있을겁니다.
[오마카세 퀄리티 향상을 위해 수련하고 왔습니다.]

여러분들에게 재밌는 인사이트를 전달하기위해 출장 수련 다녀왔습니다. VAIS 비아이즈 컨퍼런스는 VISION 분야에 관심있는 재야의 고수분들이 모인 커뮤니티인데요. 이번 컨퍼런스에서는 LLM with medical , Cuda programming , Diffusion 도시전설 이렇게 세가지 파트로 나누어 연사분들께서 인사이트를 공유해주셨습니다.
특히, stable diffusion 계보부터 시작해서 U-net layer by layer weight 마다의 결과 차이에 대한 실험결과를 보고 충격을 받았습니다. 특정 요소를 생성하는데 유리한 layer 가 있다. 즉, parameter 가 존재한다는게 드러난거죠. 이를 그래프 관점에서 접목해보면 diffusion(flow-based) model 이 신약개발에서 자주 활용되고 있는데, 많은양의 graph(molecular)를 학습하고 여기에서 특정 목적(domain)에 걸맞는 molecular 를 생성하기 위해 적합한 layer 만을 발견한다면, 적절한 범주를 빠르게 도출할 수 있을거란 생각이 들었네요.
무튼 위 3가지 파트들 모두 연관성이 없어보일수도 있으나 저는 한가지 연관성을 발견했습니다. 바로 ‘Large model handling’ 입니다. large model을 저희가 from scratch 부터 활용하기엔 어려우니 적어도 Fine-tunning 이라도 해야한다. 라는게 요새 추세인데요. 그 추세에 걸맞는 방법론 그리고 교보재로 쓰이면 좋을 논문을 가져왔습니다.
LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS
[https://arxiv.org/pdf/2106.09685.pdf]
간단히 말씀드리면, transformer 의 Trainable parameter 를 최소화하며 어떻게 성능을 유지 혹은 상승시킬수 있을것인가를 research question 으로 언급하고, 그 해결방안에 대해 이야기합니다.