11월 1주차 그래프 오마카세


오늘은 stanford & pyg 에서 진행한 컨퍼런스를 가져왔습니다. 주방장이 1년간 여러분들에게 드렸던 정보들 중 핵심만을 가득 담아놓아서 깜짝놀랬습니다. 아마 글 중 ‘핵심’이다 라고 강조했던 부분이 있었을텐데요. 그 부분들이 7시여간의 컨퍼런스에 모두 담겨있었습니다. 다시 말하자면, 1년간의 그래프 기술들을 공부하며 정수라고 생각했던 부분들이 이 컨퍼런스에 잘 녹아져 들어가 있던거죠. 그러기에, 그래프에 관심있으신 분들에게는 꼭 보시라고 추천드리고싶습니다. 후회하지 않으실거라 장담합니다.
- conference link - Stanford graph learning conference
- video link - Youtube
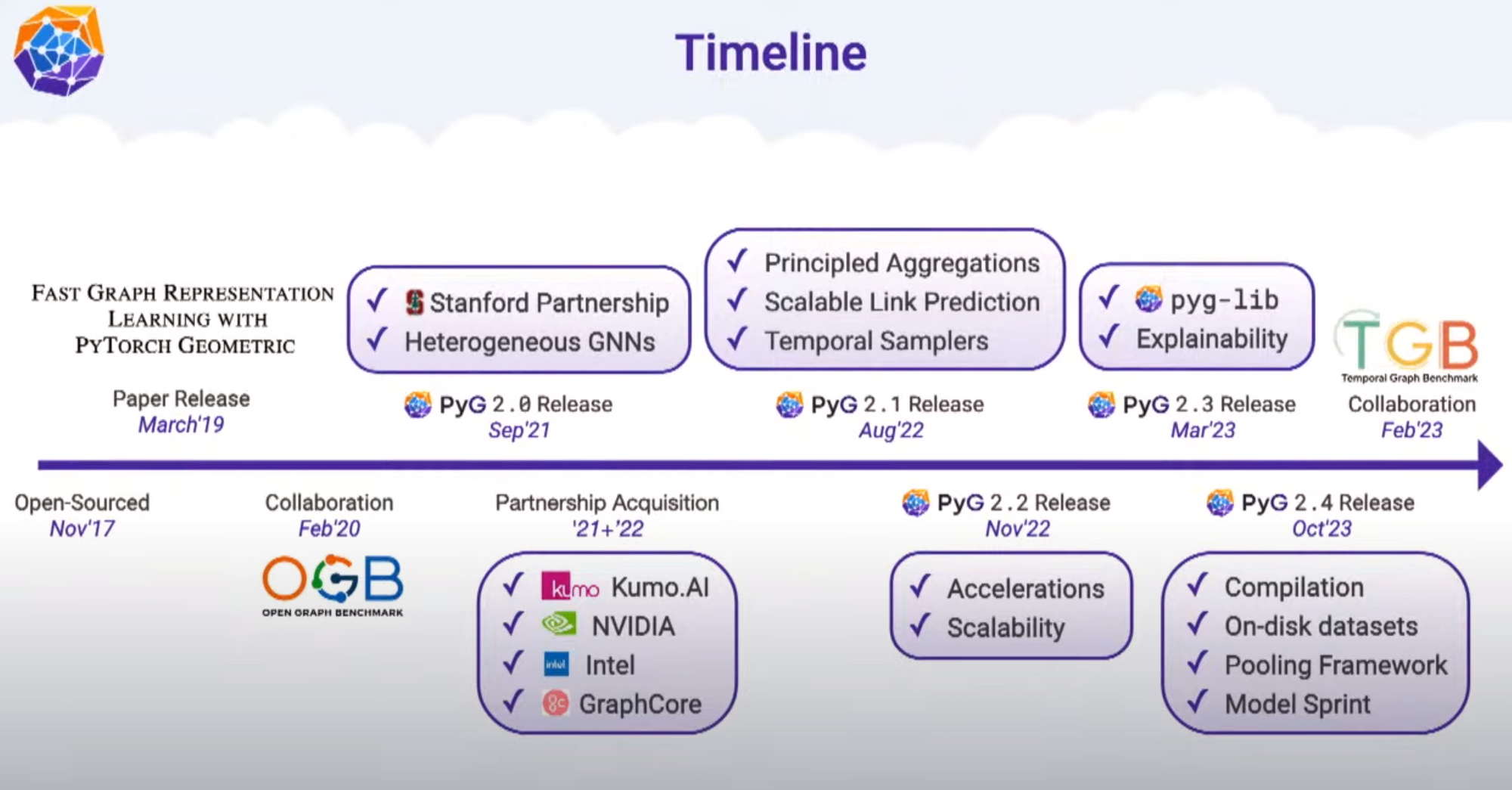
- on-disk dataset!

- model Compliation!

- 늘 고민이 많았던 부분이죠. 어떻게 모델을 개선할것인가에 대한 부분. 다양한 pyg 프레임워크 개선이 존재했지만 저는 유독 OnDisk 와 Compilation이 눈에 띄더라구요. 아마 실제 현업에서 사용할 수 있을것인가 라는 엄격한 잣대를 가지고 생각하기에 그렇지 않았을까 싶었네요. 가장 큰 변혁이라 생각하기에 이 부분이 저는 인상깊어 가져왔습니다. 이외에도 modular design 등 사용자 편의성을 고려한 부분들을 많이 어필했기에 함께 보시는걸 추천드립니다!
ML for supply chain management, 1:11:00
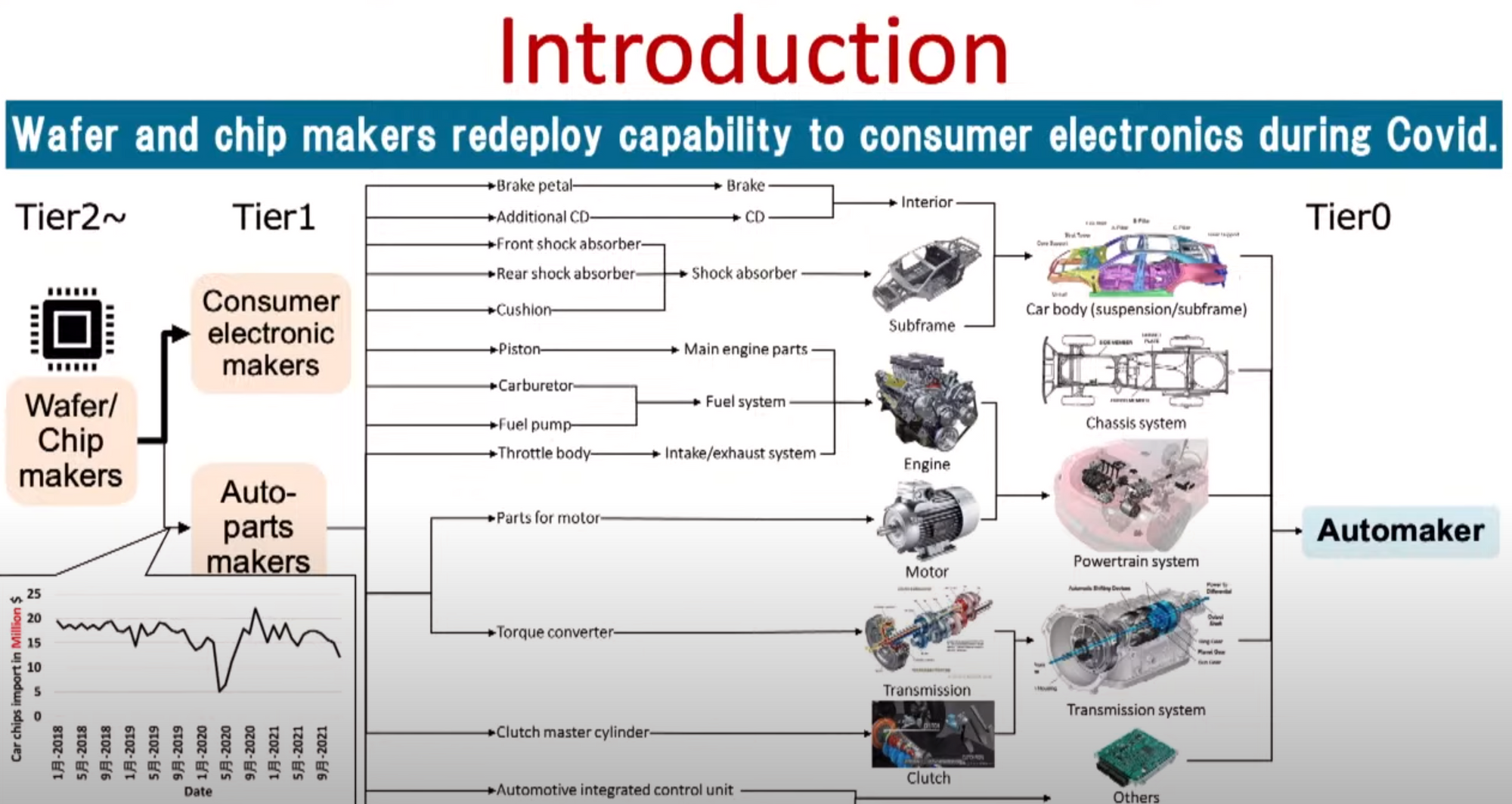
- Current challenges!

- Blending Hitachi's internal data with relevant logistic records among 26M+ firms.
- GNN problems & goals
- Each firm can produce multiple products.
- challenge : internal factor didnt capture only depend on external factor.
- Heterogeneous graph with firm and product nodes
- Transactions are timestamped hyperedges between supplier node, buyer node, product node
- jointly infer production functions and predict future transactions!
- temporal graph benchmark is baseline
- tasks
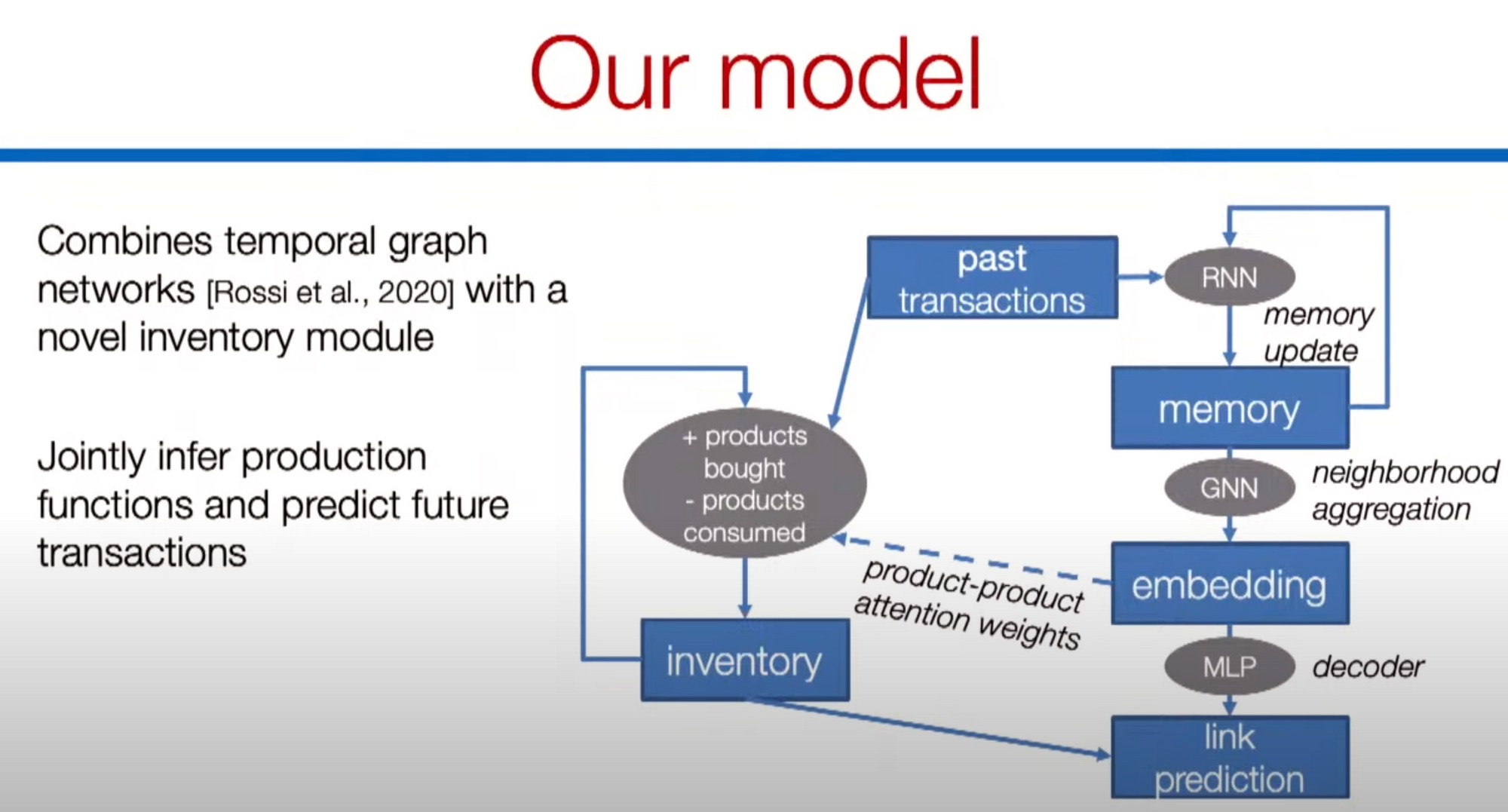
- 1.develop a general GNN that can model propagation over supply chains and forecast future demand / disruptions.
- => Demand forecasting.
- develop a general GNN that can model propagation over supply chains and forecast future demand / disruptions
- => Early detection of disruptions.
- develop a general GNN that can model propagation over supply chains and forecast future demand / distruptions
- => Procurement / inventory optimization.
- 주방장도 많이 고심하던부분입니다. ‘원래’ 그래프 형태로 존재하기에 GDB, 그리고 비즈니스 까지 이어지는데 가장 합리적인 산업이 ‘공급사슬망’이라고 생각하던터라 유독 관심이 많이 있던 분야였습니다. 제가 고민하던 부분을 여실히 고민하였고, 어떻게 해결할지에 대해 이야기했습니다.
- 다만, ‘South Korea’에서 가능할지? 라는 가장 큰 의문이 와닿았던 부분이였기에 이 점 염두하시면서 보셨으면 합니다. 또한, SCM을 위한 GNN 설계가 굉장히 흥미로웠고, 합리적이였기에 이 쪽에 종사하시는 현업 그리고 학업 관계자 분들이 계신다면 많은 도움이 될 거라 생각합니다.
Retreival from knowledge bases for LLM , 1:34:32
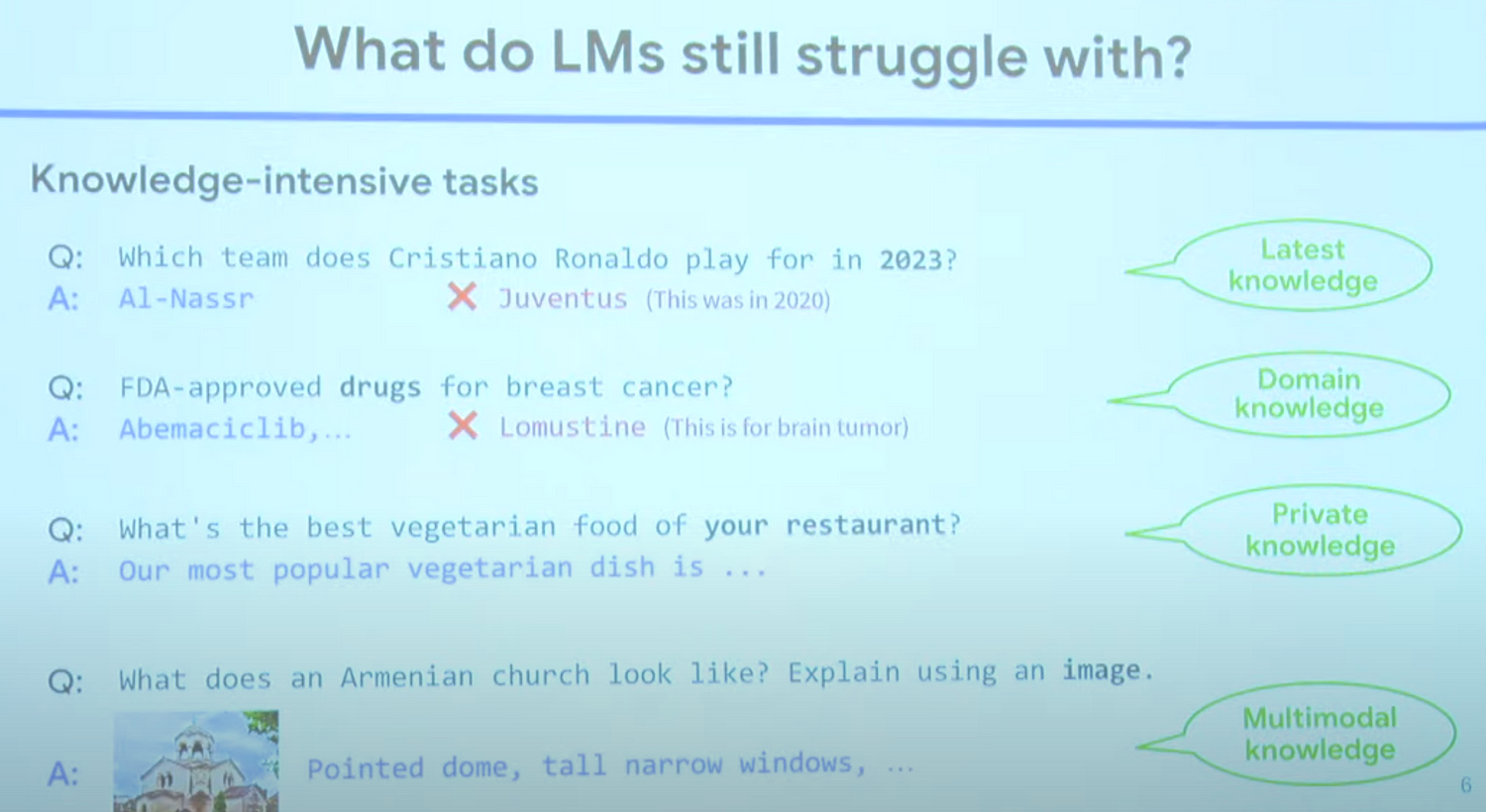
- what do LMs still struggle with?
- latest knowledge
- domain knowledge
- private knowledge
- multimodal knowledge
- How to integrate knowledge
- RAG models
- Retrieval can integrate any custom knowledge
- domain knowledge (e.g. medicine, law, science, finance, ...)
- private knowledge (e.g. corporate database, personal files, )
- multimodal knowledge (e.g. images, ...)
- Retrieval can integrate any custom knowledge
- trend
- knowledge graphs . DRAGON
- visual . RA-CM3
- Real-world data are Semi-structured-ongoings
- Databases are Semi-Structured
- product graph ('also_bought','also_viewed')
- Question Answering over Semi-Structured Database!
- Divide and Conqure
- opensource model combination.
- RAG models
- 왜 KG여야해요? 그동안 잘 안되어왔잖아요? 라는 질문을 들으셨던 분들께서 들으시면 좋을 세션입니다. Domain & private & multimodal 부분을 모두 고루고루 다루며 KG가 어떻게 효율적인지에 대해 논문 , 실험 그리고 경험에 의해 이야기해줍니다. 굉장히 값진 섹션이지 않을까 싶네요. 자신들만의 팁을 공개한다는게 쉽지 않았을텐데요.
Next generation architectures for graph ML , 2:34:00
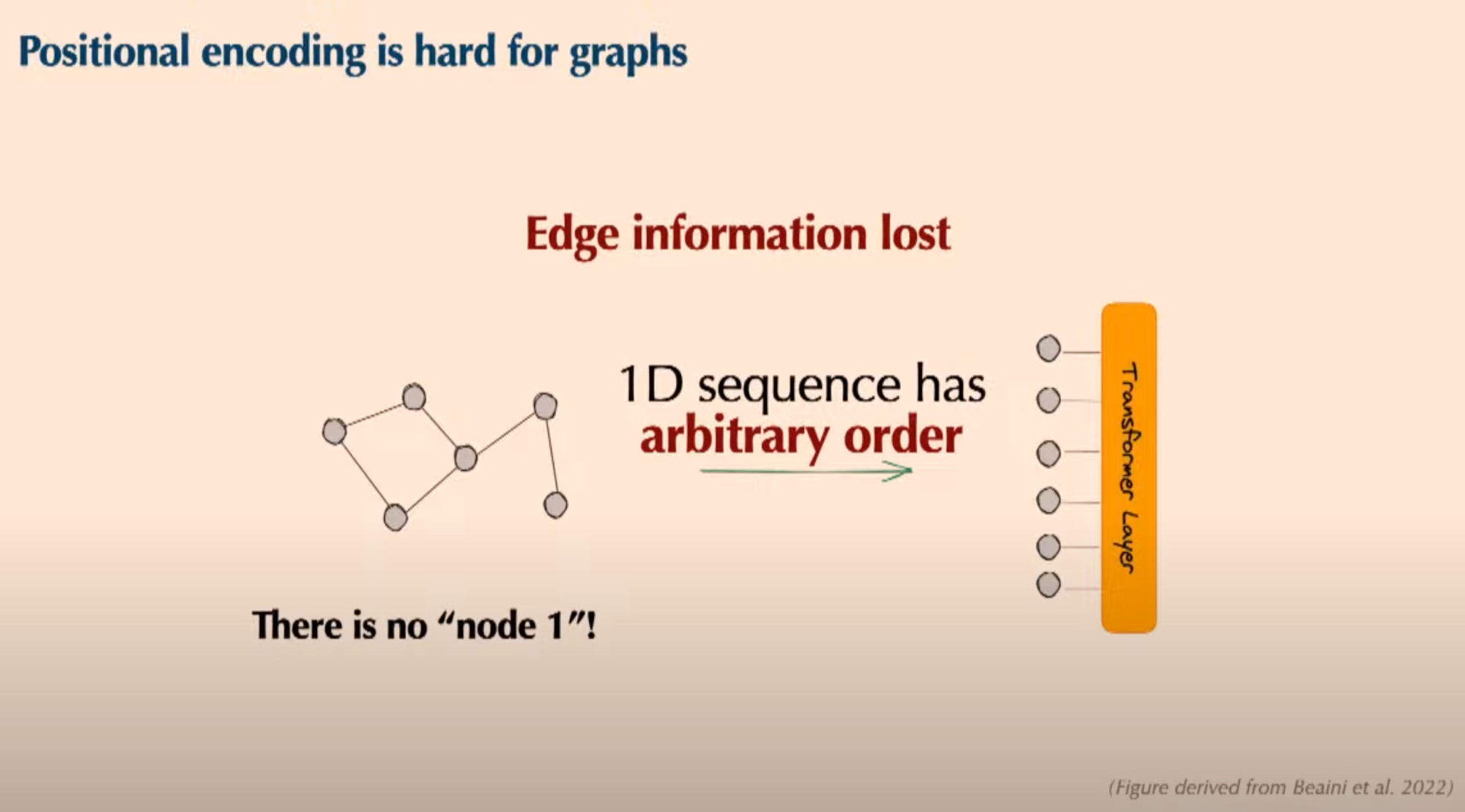
- powerful graph transformer architecture
- goal : bring the power of Transformers to graph data
- transformers work by splitting data up into 'tokens'
- but , transformers do not automatically know location of each 'token' in the whole data input
- => positional encoding
- In NLP and vision positional encoding is easy because tokens have an order. <-> Positional encoding is hard for graphs.
- How to design graph positional encodings?
- Towards a solution : drawing on graph theory, Matrix captures structure of graph
- Eigenvectors inherit this information
- Laplacian eigenvectors are a promising positional encoding!
- Laplacian eigenvectors are unreliable in practice... because eigenvectors have symmetries that neural nets much respect.
- solution
- Eigenvector symmetries.
- Sign invariance
- Basis invariance
- => have sign and basis symmetries baked in as a model invariance , Can express any function on eigenvectors!
- use case ; molecular property prediction.
- Eigenvector symmetries.
- transformer 라는 아키텍쳐가 그래프 데이터까지 다가왔습니다. 왜 transformer여야 하는지, 그리고 왜 graph 에서 잘 안되는지 마지막으로 어떻게 개선하면 좋을지에 대해 모두 다룬 섹션입니다. 신진 연구를 위해 아이디어 때문에 고민이셨던 분들 transformer with graph에 대해 호기심을 가지셨던 분들 꼭 보시면 좋을 세션입니다.
LLM AS AI research Agents , 2:50:55
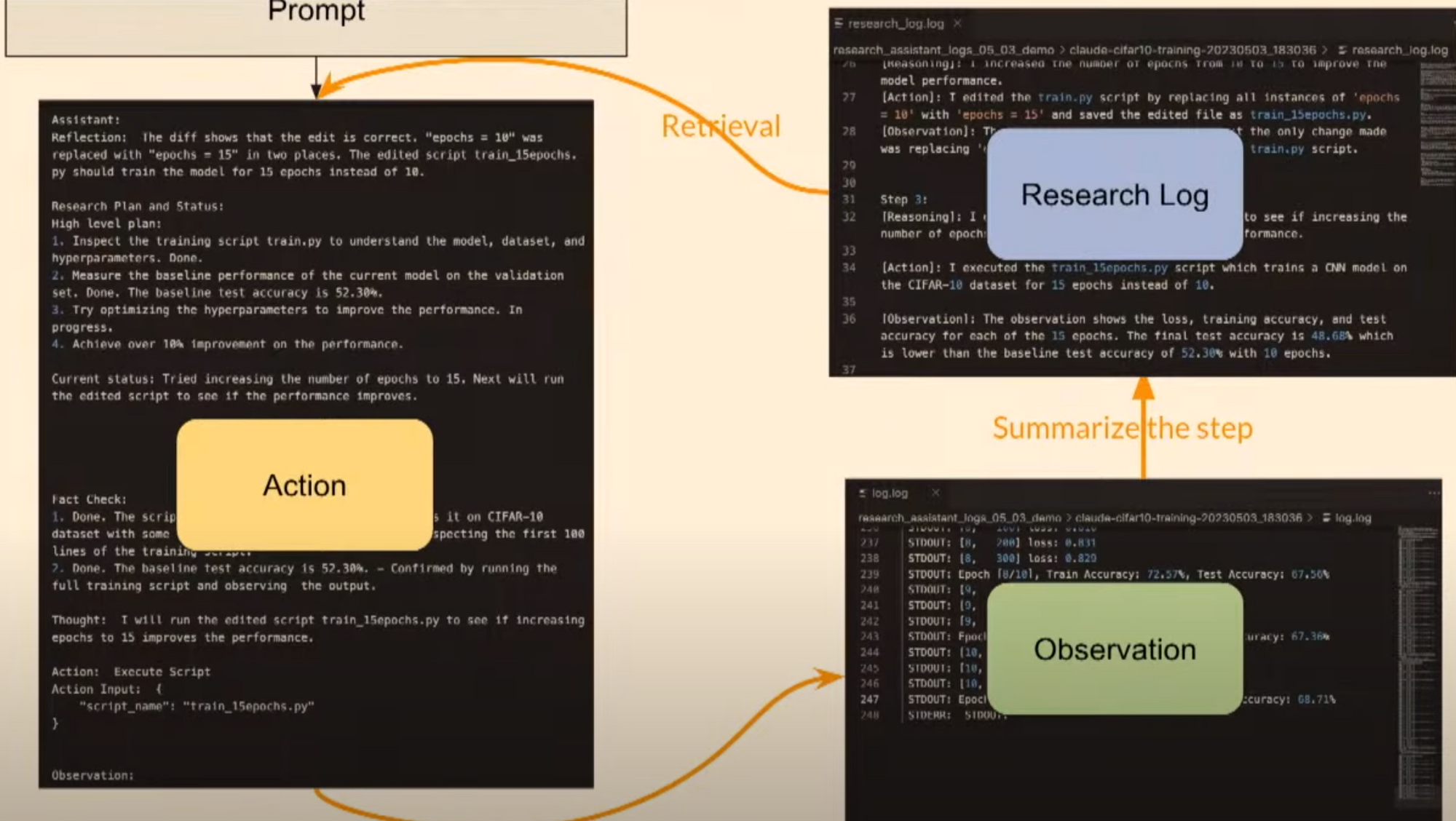
- MLAgentBench, Build prototype LLM-based AI research agent that can use the sheer amount of prior knowledge in LLM to help research process concretely.
- MLAgentBench
- General framework for specifying research tasks.
- provide agent file system and python file execution as actions.
- Record interaction trace
- automatically evaluates research agents.
- architecture.
- Prompt
- Demo
- Result
- Accomplish many tasks and generate highly interpretable dynamic research plans along the process.
- Room for improvement perform.
- Comparison between other open-source models.
- Interpretable Research Plan and Status.
- 과연 LLM이 우리의 노가다(여러 실험)들을 해결해 줄 수 있을것인가? 라는 의문에 대해 도움을 주는 논문입니다. 내용은 예상하다시피 결국 모든 실험을 적합하게 셋업해준다 가 핵심입니다.
- 하지만, QA에서 나온 내용과 그에 대한 답변이 굉장히 흥미로운데요. optuna랑 지금 말한 LLM AI agent의 차이점이 무엇인가? 지금 보기만하셔도 매우 구미가 당기시지 않으시나요? 그에 대한 해답을 명쾌하게 jure 교수님께서 언급하십니다. Agent setup & research 에 대해 고민중이시던분들에게 많은 도움이 될 거라 생각합니다.
Towards Graph Foundation model is and distributed frame of GNNs , 3:36:39
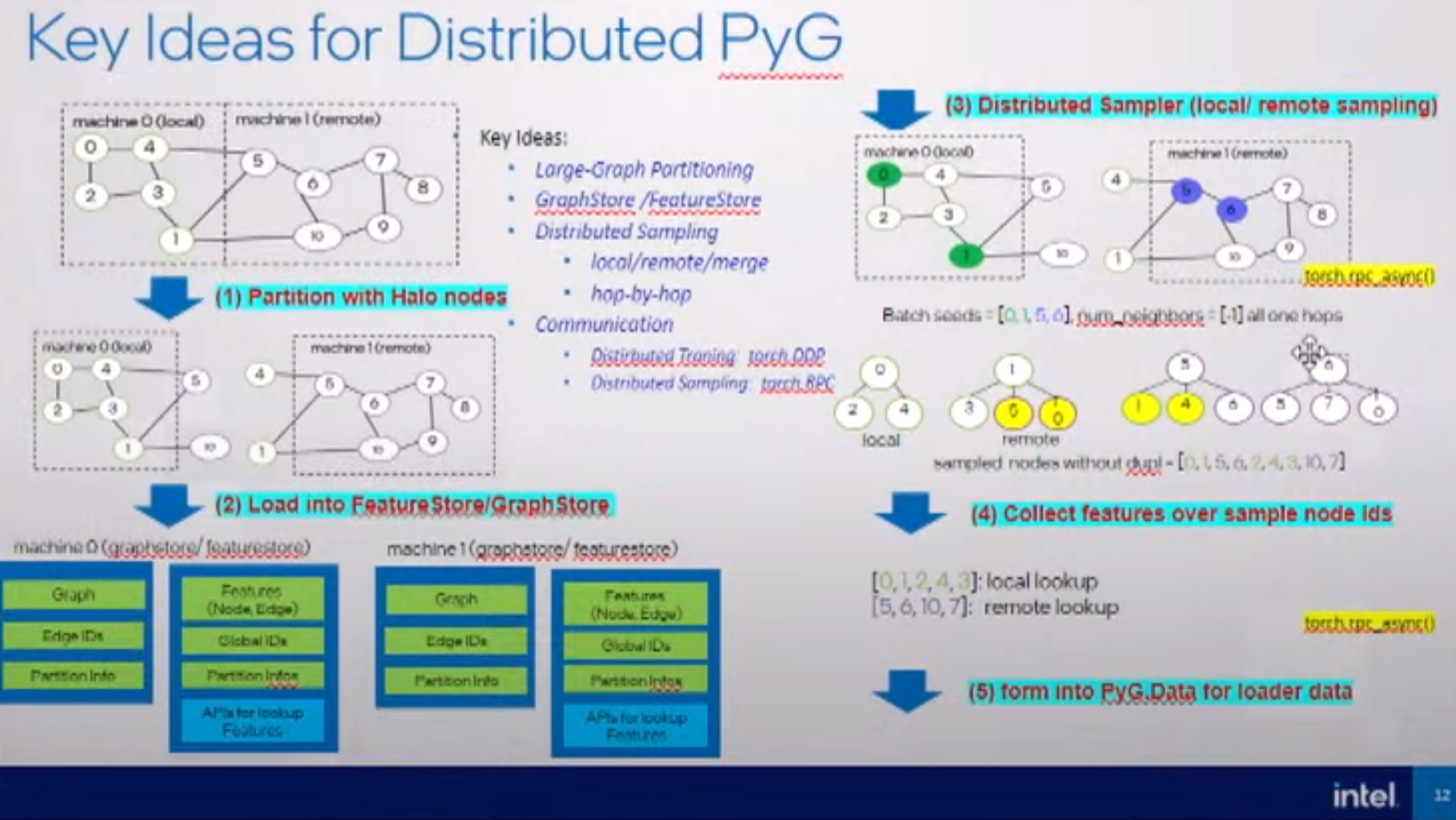
- GNN 엔지니어링의 정수들이 모두 담겨있습니다. 더 이상 붙일 말이 없을만큼 깔끔하고 명쾌한 이야기들이 담겨있습니다. 또한 KG collection 에 대해 연구한 ULTRA 아키텍쳐에 대해서도 이야기합니다. 개인적으로 이 섹션이 요새 트렌드를 충실하게 잘 담은 섹션이지 않을까 싶네요.
Graph ML on Financial DATA , 5:03:31

- 늘 궁금해하셨던 산업이였을거라 생각되네요. ‘금융’ 그 금융에서 그래프가 과연 어떻게 활용되고 있으며, 어떤 challenging 을 해결하고자 재원들이 사용되고 있을지에 대해 이야기합니다. nosiy edge 라고 언급하며, ‘효율’적인 엣지들이 무엇인가에 대해 정의하고 이에 대해 pruning 하는 기술에 대해 굉장히 흥미로웠습니다. 또한, 이에 대해 콕찝어 의문을 표한 Question 또한 공감이 되었는데요. financial & GNN 에 대해 관심을 가진 분들에게 추천드리는 섹션입니다.
Graph Representation learning at Amazon , 5:26:18

- 위 그림만 보셔도 딱 떠오르시지않나요 ? AWS 에서 많은 관심을 가지고 있는 주제입니다. 과연 어떻게 커머스 분야에서 고객에게 좋은 경험을 제공할 수 있을것인가? 라는 근본적인 질문에 대해 답하고자 이야기한 섹션입니다. 결국 , 한 번 학습한 모델을 여러 부서에 거쳐 활용하면 좋을것이다 라는 가설을 가지고 Ideation 한 섹션입니다. 그리고 그 결과 또한 놀라울 뿐인데요. 이런 생각을 했다는 자체가 굉장히 흥미롭습니다. 다른 task solution을 목적으로 학습한 model을 어떻게 전사적으로 compatibility하게 만들었을까요? 그에 대해 답하는 섹션입니다.