9월 2주차 그래프 오마카세


MESH: A Flexible Distributed Hypergraph Processing System
[https://ieeexplore.ieee.org/document/8790188]
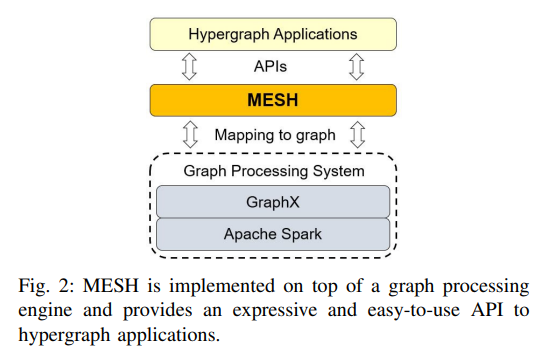
“Think likie a vertex” 점처럼 생각하라. 본 논문을 읽으며 처음 접한 문장이지만, 그래프 처리 시스템들의 개발 이념 중 하나라고 하네요. 객체 지향 프로그래밍과 유사한 개념입니다. ‘점’ 기준으로 모든걸 생각한다. 라고 생각하시면 이해가 수월하실수 있겠습니다. 점의 상태 그리고 행동(이웃들간의 교류)를 기준으로 프로그래밍 하는것. 오늘 언급드릴 MESH 라는 엔진에서도 마찬가지로 이 핵심 이념을 담아 hypergraph processing engine 을 개발했습니다.
MESH 는 1.Expressiveness & Ease of Use 2.Scalability 3.Flexibility and ease of Implementation 3가지 가치들을 중점으로 기존 hypergraph processing engine 인 HyperX와 비교하여 성능측면으로 우월하다 라고 이야기합니다. 요약하면, HyperX 와 다르게 MESH 는 from scratch 로 hypergraph structure 에 적합하게 개발하였기에 앞서 언급한 3가지를 모두 충족하였다가 핵심입니다.
그럼 이 장점들이 과연 어디에 필요할까요? 곰곰이 생각을 해보신다면, 결국 실제 데이터에 hypergraph 관점을 적용할 때 여러분 각자 마주하고 있는 문제를 해결하기 위한 여러 가설들을 설정할텐데요. 그 가설들을 검증하기 위해 다양한 상황을 시뮬레이션할겁니다. 이 때, ‘다양한’ 상황을 시뮬레이션 하기 위해선 유연한 적용이 필요한데 그 적용을 이전 엔진들은 어려웠을뿐더러 코드가 길었다고 합니다. 반면, HyperX는 가능하게끔 구현을 해놓았다고 하네요(다양한 paritioning 전략적용).
본 논문의 연식이 꽤 되었음에도 불구하고 제가 이번주 오마카세 식탁에 올린 이유는 다음과 같습니다. 1. 대용량 데이터를 마주했을 때 partioning 을 어떤식으로 선정하면 좋을지 참고하면 좋을 논리 및 레퍼런스 2. Spark 에 대한 인지
현업에서 Graph 도입을 위해 여러 고민들을 하곤합니다. 가장 중요한 건 그래프를 활용한 비즈니스 임팩트 기여이겠지만, 허황찬란한 그래프 기획을 설계한다면 이는 오히려 마이너스가 될 수 있습니다. 다시말해서, 이상과 현실사이에서 적절한 합의점을 잘 찾는게 핵심이죠. 기획과 구현 사이에서 Spark (GraphX)가 좋은 대안이지 않을까 하여 말씀드립니다. 물론 CPU, cluster 그리고 memory 에 따라 어떻게 자원을 배분할지는 또 다른 고민사항이기에 많은 공부가 필요하긴하지만, 그 공부에 걸맞는 아웃풋이 분명 나올거라 확신합니다.
Hadoop vs. Spark 무엇이 좋은 선택일까?
[https://www.geeksforgeeks.org/difference-between-hadoop-and-spark/]
LLM AS DBA
[https://arxiv.org/pdf/2308.05481.pdf]
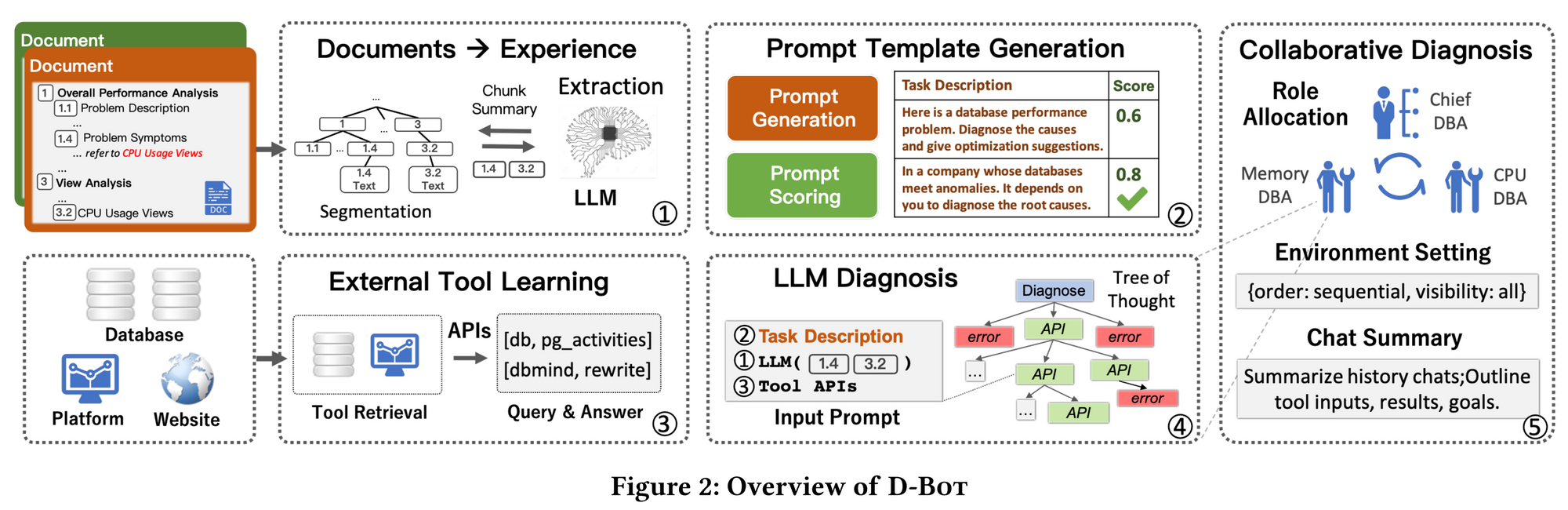
DBA(Database architecture Administration), 말 그대로 데이터베이스를 관리하는 직무입니다. 데이터 보관 및 처리의 중요도가 높아짐에 따라 DBA들의 가치도 높아지고 있는 요즘인데요. 이를 LLM이 대체할 수 있다 라는 논문입니다. 데이터 분석가 및 데이터 사이언티스트분들께서 아마 필요한 데이터를 가져올 때, SQL 쿼리를 사용하게 될텐데요. 이 때, 타팀(DBA, 데이터엔지니어)분들과 협업이 필요합니다.
데이터에 대한 관리를 하는 입장과 활용하는 입장은 분명 다르기에 각기 다른 업무에 충실하기 위해 데이터를 바라보는 관점이 다르죠. 그 관점이 일치하는 상황도 발생하겠으나, 그렇지 않은 경우도 존재합니다. 분석가들이 당연시하게 활용하는 SQL 쿼리가 DBA 분들 입장에서는 답답할 수 있겠죠. 잘못하면 서버내의 병목현상을 발생하는 쿼리를 사용하여, 관계자들 모두에게 피해를 입힐 수 있습니다. 이런 상황을 미연에 방지하는 역할이 DBA, 데이터 엔지니어 분들이시죠.
중요한 관점이라 생각하여 글을 쓰다보니 서론을 길게 썼네요. 본 논문에서는 DBA들을 대체할 LLM bot을 개발하는 과정 및 결과를 공유합니다. Appendix 에는 LLM들의 비기라고 할 수 있는 Prompt 와 Test case까지 작성되어 있습니다. 이게 어떻게 가능할까? 라는 생각을 할 수 있습니다. DBA 분들만의 암묵지가 많이 작용하는 부분일수도 있지만 사실 상황에 따른 솔루션들은 Document 형식으로 많이 배부 되어 왔습니다. 그 Document 를 보고 이해하기에 다른 직무를 맡은 사람들이 이해하기에 어렵기에 접근장벽이 높았던 것이였고, LLM 조차도 RCA(root cause analysis) 에 대한 지시가 없었기에 이를 Chatgpt에 물어보았을때 환각현상이 발생하였던거죠.
본 논문에서는 이 두 가지 관점을 접목한 Bot을 개발합니다. Document 를 잘 이해할수있게하고, RCA를 위해 tree of thought 에 특화되게 만든거죠. 주목할만한 점은 각기 다른 부분을 도맡은 DBA간 협업 및 토의를 통한 답변을 도출하는 부분입니다. Chief, Memory 그리고 CPU DBA, 참 재밌는 아이디어라는 생각이 들면서도 한편으론 무섭습니다. chatgpt 가 개발됨에 따라 가장 먼저 대체될 직업이 화이트 칼라 직군이라 하였는데, 변호사 검사 판사 등 저와 동떨어진 직군이라 와닿지 않았는데 이제 저도 곧..? 이라는 생각이 들 정도니깐요.
이런 시대에 저흰 끊임없는 공부가 필요하겠죠? 본 논문에서는 DBA bot 을 만들기 위해 DBA 들은 어떻게 원인을 분석하고 해결하는지에 대한 일련의 과정을 잘 적어두었습니다. 이 과정들 그리고 무엇을 기준으로 의사결정하는지에 대한 지혜들이 굉장히 유익합니다. DB 에 관심있는 분들 그리고 LLM을 활용해 bot 을 만들어 서비스하실 분들에게 유용할 거라 생각합니다. DB 에 대한 기초가 부족하면 읽기에 어려운 부분이 있을텐데요. 그 분들을 위해 DB 공부하기에 좋은 자료를 첨부합니다.
DB 공부하기에 좋은 자료.
[https://cs145-fall22.github.io/]
GraphFC: Customs Fraud Detection with Label Scarcity
[https://arxiv.org/pdf/2305.11377.pdf]
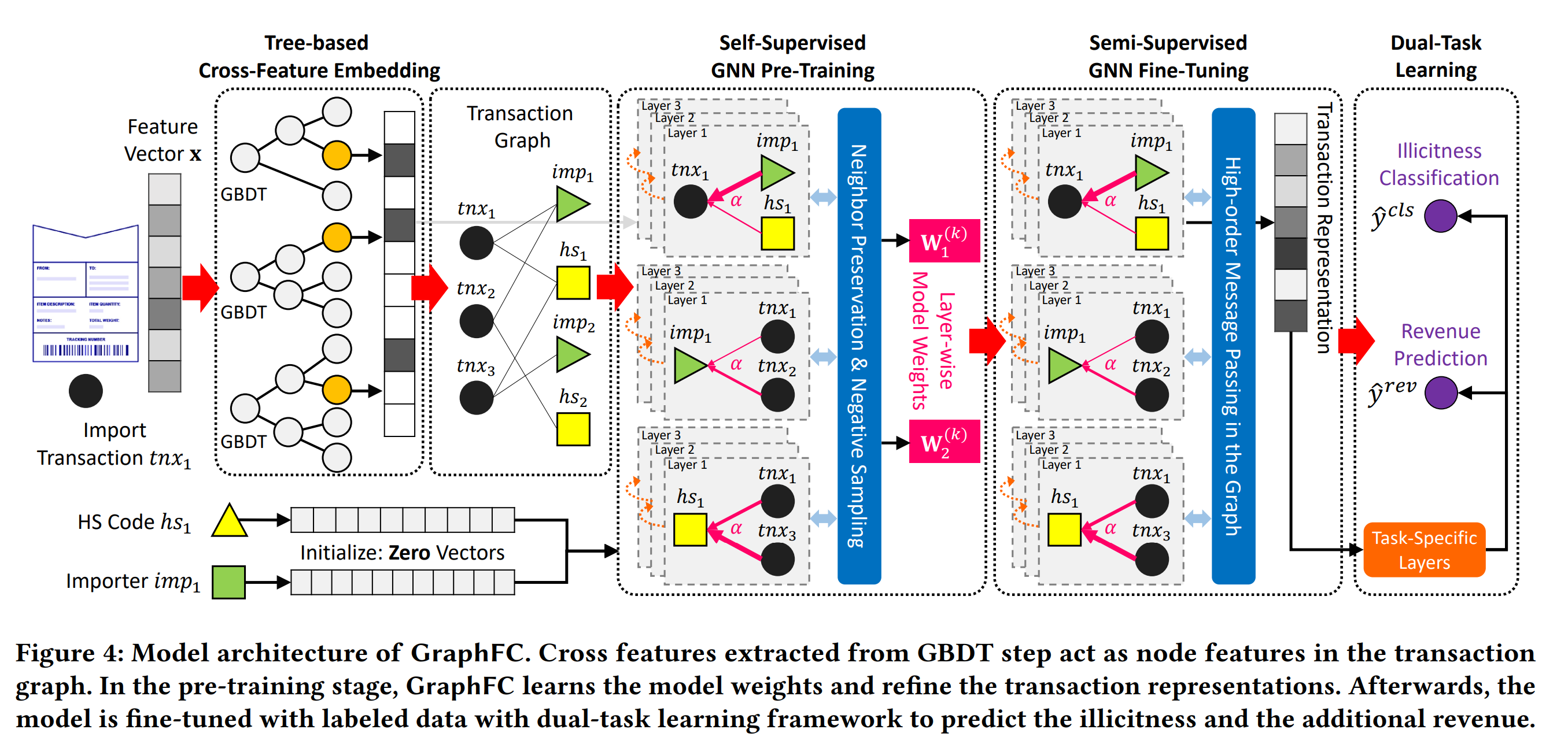
GNN 활용 사례들 중 많이 언급되는 부분이죠. FDS(fraud detection system), 여러 이상적인 데이터들이 잘 적재되어 있고 관리되어 있으면 그래프를 도입하는데 큰 어려움이 없기에, 앞서 언급한 데이터 조건들이 전제되어 있는 상황에서는 굉장히 유용합니다. 반면, 그 반대는 어떨까요? 여러 어려운 상황 중 하나를 말씀드리자면 먼저 기계학습에 활용할 그래프 데이터 그리고 라벨링된 데이터가 얼마 없는 상황입니다. 너무나도 당연한 상황입니다. 초마다 발생하는 TB 데이터를 과연 일일이 라벨링 할 수 있을까요? 본 논문에서는 이를 타개하기 위해 그래프 관점을 활용한 아이디어에 대해 이야기합니다.
Semi-supervised learning. 그래프 데이터 특성을 잘 반영한 기계학습 과제이지 않을까 생각합니다. topology 를 활용하여 Label Scarcity 현상을 완화하고 이를 기계학습에 적용할 시 타 방법론(tabluar) 대비 우수함을 실험 결과로써 입증합니다.
Pre-training, Fine-tunning 과정은 기존 GNN 논문과 별 차이는 없습니다. 다만, 그 앞과정인 Tree-base cross-feature embedding 과 Transaction Graph 모델링 과정이 굉장히 재밌습니다. 또한 각기 다른 message passing model 를 활용하는데요, RGCN GraphSAGE 그리고 GAT 이 모델들간 차이가 FDS 그것도 unlabeled 데이터에서 어떻게 작용하는지 보는 포인트도 유익합니다.
Graph FDS 적용을 원하는 분들께 종종 문의를 받습니다. 어떻게 DBMS 를 설계하고 여기에서 Rule 을 도출하며 ML 적용할지를요. 언급한 모든 부분을 커버할 순 없지만, ML 관점에서 그 분들에게 한줄기 빛이 될 논문이라 생각합니다. 현업에서 자주 언급하는 문제인 Label Scarcity 를 중점으로 다루었기 때문이죠. 저도 요즘엔 DB 관점으로만 FDS 를 고민해왔었는데, ML 관점에서 키포인트인 unlabeled data에서 어떻게 data augmentation 할지 그리고 무슨 모델을 활용하면 좋을지에 대해 참고할 좋은 레퍼런스를 찾게되어, 논문을 읽으면서 굉장히 즐거웠었네요.

여러분들의 그래프 관심덕분에 당초 기획했던 행사인원 50명을 훌쩍 넘어선 85분께서 행사 참여신청을 해주셨습니다. 주말 황금시간대인 오후시간대를 잡은터라 오히려 호응이 좋지 않을까 걱정했지만 기우였지 않았나 싶네요. 여러분들에게 도움될만한 콘텐츠가 무엇일까 고민을하며 연사분들을 모셨으니, 많은 배움 인사이트 얻어가셨으면 합니다. 그럼 행사때 뵙겠습니다.