9월 3주차 그래프 오마카세


Voucher Abuse Detection with Prompt-based Fine-tuning on Graph Neural Networks
[https://arxiv.org/pdf/2308.10028.pdf]
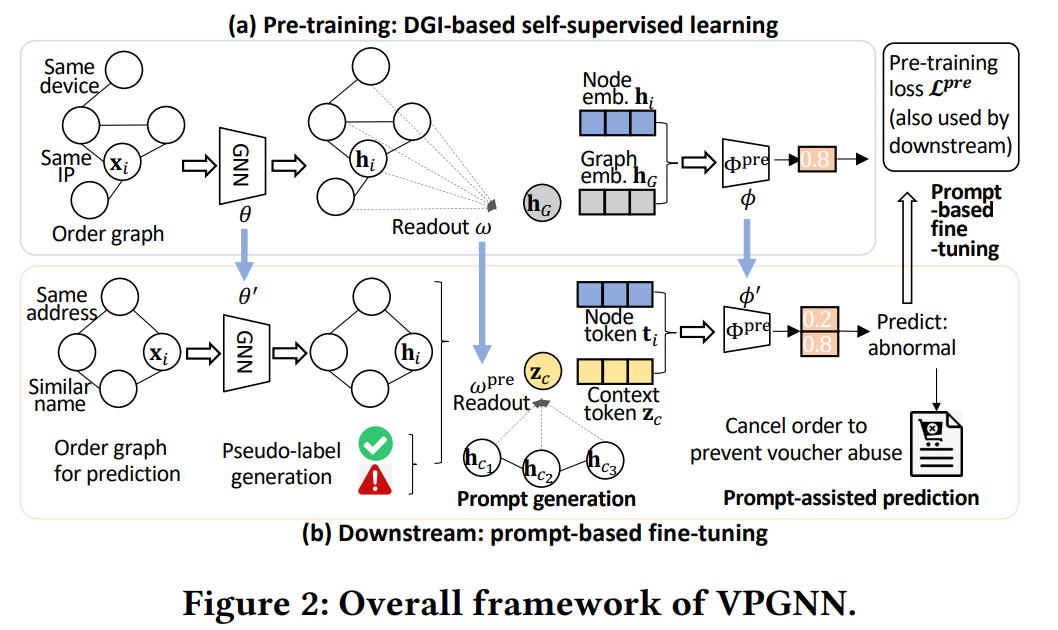
저번주 오마카세에서도 언급했었죠. GNN 이 각광받고 있는 이유중 하나 바로 준지도학습을 통해 라벨링 되어있지 않은 데이터에 대해 추론이 가능하다 였습니다. 이를 활용하기 좋은 분야는 바로 FDS 즉 이상치 탐지분야인데요. 오늘은 저번 오마카세에서 다룬 내용과 다르게 딥러닝 기술을 적극 활용합니다. 저도 상상으로만 가능할까 싶었던 부분을 본 논문에서 구현을 해주었습니다. 타 FDS 논문 대비 더욱 신빙성이 간건 바로 Offline 그리고 Online setup 이 모두 담겨있었다는건데요. 그말은즉슨, 현업에서 적용할 수 있는 아이디어임을 의미합니다. 논문 Related work 에서도 industry 에 활용한 Graph Deep learning 레퍼런스들을 잘 담아놓았으니 GNN 적용에 대해 기획하고 계신분들이 있다면 많은 도움이 될 거 같습니다.
실용성 끝판왕 논문이라 해도 과언이 아닐정도로 현업에서 필요한 요소들을 모두 담은 논문입니다. 예를 들자면, 라벨링이 안된 데이터들의 추론을 위해 적용한 Graph pre-training , fine-tunning 기법 , 앞서 기법을 적용하였을시 Online, Offline 에서 어떤식으로 평가할지 등등 논문의 저자들이 어떻게 하면 GNN 을 통해 FDS를 구축할 수 있을것인가에 대한 고민이 많이 엿보이는 논문이였습니다. 특히, 오마카세 주방장은 개인적으로 Figure 6: Deployment pipeline and feature ngineering 과 그래프 모델링 그리고 Pre-training, Fine-tunning 접근법이 굉장히 신선했기에 두고두고 다시 볼 논문이라 생각했네요. 여러분들도 각자 필요한 부분이 있다면 구현하기 전 사고 실험에 본 논문이 많은 도움이 되었으면 합니다.
Accelerating Personalized PageRank Vector Computation
[https://arxiv.org/pdf/2306.02102.pdf]

페이지랭크 알고리즘. 다들 익숙하게 들어보셨을 알고리즘입니다. 구글 검색엔진 하면 떠오르는 알고리즘으로 기억하실텐데요. 알고리즘이 등장한지 시간이 꽤 지났지만 여전히 그래프 분야에서는 이를 개선하기 위해 많은 노력을 기울이고 있습니다. 여러 개선 요소 중 하나는 행렬 업데이트를 할때마다 발생하는 과한 연산비용 입니다. 노드간 정보가 전달되며 바뀌는 구글 행렬(Google matrix)의 정보를 반복적으로 반영 및 표현해주기 위해서는 그래프 전체 변형 상태를 파악해야 하는데, 그래프 사이즈가 크다면 이를 파악하기에 부담이 된다는거죠.
이 점을 개선하기 위해, 본 논문에서는 FwdPush 알고리즘을 차용합니다. 간단하게 말씀드리자면, 특정노드 그리고 그 주변이웃들을 엑세스합니다. 이후, 분포 변화에 대한 파악을 합니다. 이때, 분포 변화가 크고 작음에 따라 active or inactive 로 나눕니다. 이렇게 나뉜 노드들을 기반으로 정보를 전달하며 최적 구글 행렬을 도출합니다. 지금까지 일련의 과정을 통해 결국 최적값을 도출하기 위해 필요한 노드들이 자연스레 인덱싱되기에 기존 방법론 대비 훨씬 빠르다고 합니다.
아이디어까진 좋습니다. 근데 과연 어떻게 구현을 할까요? 여기에서는 가우스-자이델(Gauss-Seidel) 모델을 활용해 반복적으로 행렬계산이 어떻게 진행되는지 Proof 를 통해 보여줍니다. FwdPush는 가우스-자이델 모델의 한 종류입니다. 논문 저자는 여기에서 그치지않고 연산 수렴을 가속하기 위해 Successive Over Relaxation(SOR) 방식을 추가 적용합니다. 여기에서는, w라는 relaxation parameter 를 추가하면서 행렬값을 빠르게 혹은 느리게 수렴할 수 있는 도구를 붙입니다. 왜 갑자기 relaxation parameter 가 나오냐 할 수 있는데요. 만일 수렴을 위해, 특정 노드가 선정되었는데 그 노드가 수렴되기에 너무 오래걸릴수 있는 노드일 가능성도 있습니다. 이 가능성을 최소화 하기위해 추가적인 안전 장치를 도입했는데 그게 바로 SOR방식이라고 보시면 되겠습니다.
자자, 여기에서 중간 정리를 해보면 다음과 같습니다. 구글 행렬을 개선하기 위해 전체 그래프를 반복적으로 업데이트해야하는데, 대용량 그래프일시 여기에 소요되는 비용이 많습니다. 이를, 개선하기 위해 정보 전달에 활용할 노드 / 활용하지 않을 노드를 선택하는 방식 FwdPush 를 적용하였습니다. 하지만 이때, 최적 행렬 도출을 위한 연산 과정 중 활용 노드가 수렴 속도에 지장을 주는 노드라면 문제가 생깁니다. 이를 조정하고자 SOR 방식을 도입하였고, 그게 바로 w 하이퍼 파라미터입니다.
제가 언급한 것 이외에도 왜 FwdPush 에서 분포변화에 대한 파악을 하는지, SOR 의 w 하이퍼 파라미터를 어떻게 선정하는지 , optimization function (NAG, HB) 방식 등 재밌는 요소가 많이 담겨 있습니다. 선형대수 및 해석학 그리고 최적화 등 수학적 개념을 활용해 기존 알고리즘을 어떻게 개선할 수 있을것인가에 대한 총체적인 논리전개가 잘 되어있기에, 만일 이를 고민하고 있는 분이시라면 많은 도움이 될 거 같습니다.
RAG , 요새 화두인 기술입니다. 이를 구현하기 위해 여러 요소들이 필요하지만 가장 필요한 요소는 Retrieval 할 store의 성능 그리고 데이터가 어떤 store 에 저장을 해야 잘 작동할지에 대해 고민한 후 적절한 선택 이라 생각합니다. 아래 세가지 포스팅은 RDF(knowledge graph store) , GDB(graph store) , RDB(tabular store) , Vector(Vector store) 4가지 관점을 비교하시면서 보시기에 적절한 포스팅이라 생각하여 가져왔습니다.
What is an RDF Triplestore?
[https://www.ontotext.com/knowledgehub/fundamentals/what-is-rdf-triplestore/]
Graph Database vs Relational Database
[https://memgraph.com/blog/graph-database-vs-relational-database]
Diving into Databases: Graph & Vector for Retrieval Augmented Generation – Point of View
과연 현대 추천시스템에서 한계는 무엇일까요? 각자 생각하시는 관점들이 다르시겠지만, 저는 본 포스팅이 그 챌린징들에 대해 잘 다루었다고 생각합니다.
1.Directed graph 2. Delayed feedback 3.Prediction uncertainty 물론, 추천시스템 또한 도메인에서 각각의 역할이 다를거라 생각하기에 정답은 아닐거라 생각합니다. 하지만 모두 엇비슷한 고민을 하고 있을거라 생각하기에 추천시스템 하면 생각나는 분야인 이커머스에서 추천시스템 한계는 무엇인가 라는 관점을 견지한 상태에서 본 포스팅을 읽어보시면 어떨까 싶네요.
RecSys: Rajeev Rastogi on three recommendation system challenges
[https://www.amazon.science/blog/recsys-rajeev-rastogi-on-three-recommendation-system-challenges]