
9월 4주차 그래프 오마카세

Transformers Meet Directed Graphs
[https://arxiv.org/pdf/2302.00049.pdf]
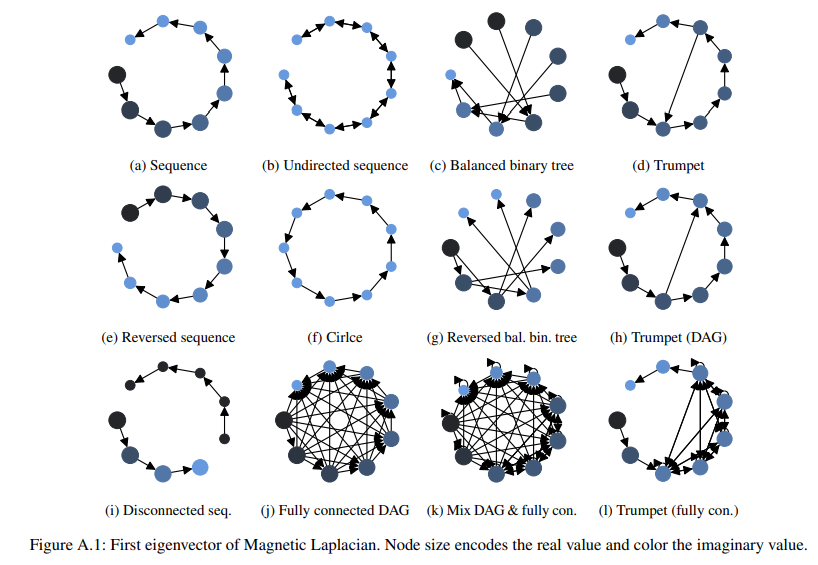
트랜스포머 시대에 살고있다해도 무리가 없을 정도로 데이터 종류를 가리지않고 많은곳에서 트랜스포머를 활용하고 있는 요즘입니다. 하지만, 그래프 데이터에서만 유난히 기를 못쓰는데요.
그 이유로는 1. 동형 사상 2. 토폴로지 종류 라고 저는 생각합니다. 본 논문에서는 위 두 가지를 한계점으로 꼽고 해결하고자 새로운 PE(Positional Encoding) 방식을 적용합니다. 바로 유향그래프에 적합한 PE인데요. Magnetic Laplacian 이라는 개론을 차용해 기존 라플라시안 행렬에 방향성을 적용할 수 있는 PE 아이디어를 제안합니다.
물론 성능은 타 PE대비 좋습니다. 여러분들께 추천드리는 관점은 트랜스포머 아키텍쳐가 유독 그래프에서 왜 힘을 못 썼는지부터 그를 극복하기 위한 각종 PE와 토폴로지에 따른 차트 그리고 성능 향상의 주 요인까지의 서사를 보시는걸 추천드립니다.
이 서사들이 논문 appendix 에 적혀있기 때문에, 논문 본문을 한 번 정독하신후 왜?왜? 라는 관점을 견지하신 상태에서 appendix를 보시면 더욱 맛있게 본 논문을 음미하실 수 있으실 겁니다.
A Survey on Graph Neural Network Acceleration: Algorithms, Systems, and Customized Hardware
[https://arxiv.org/pdf/2306.14052.pdf]
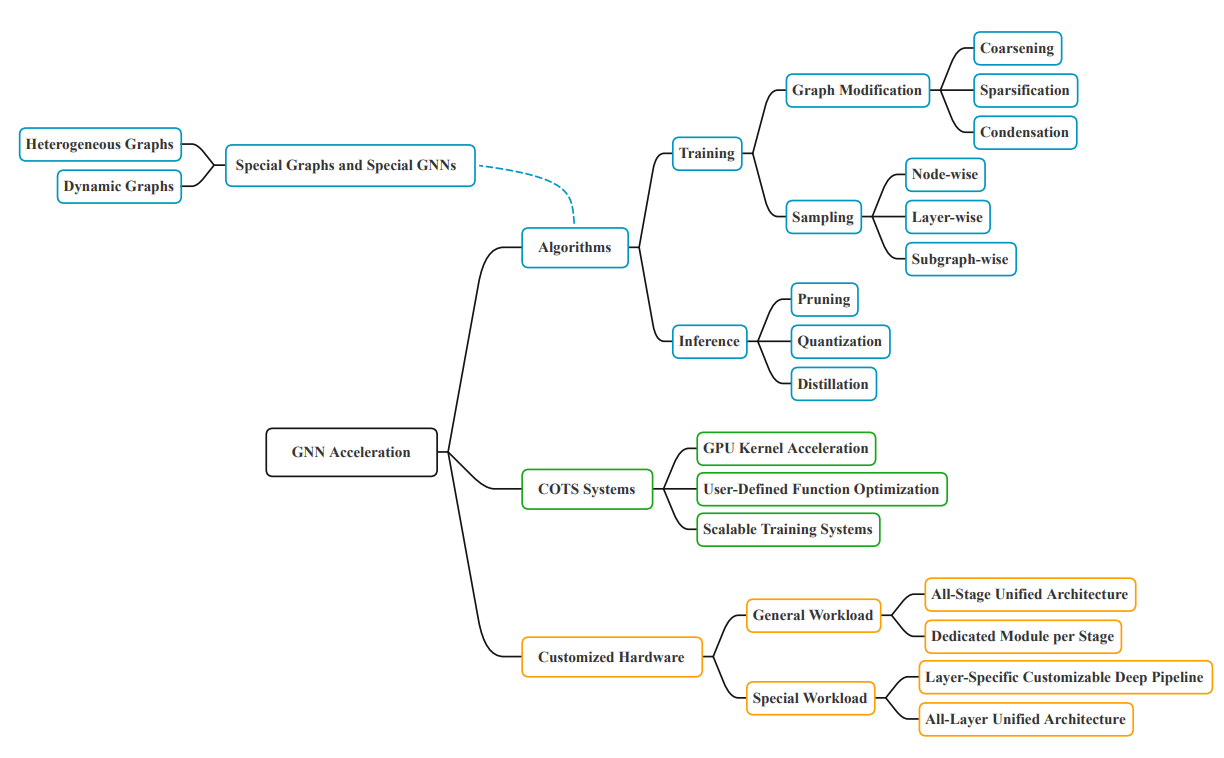
그래프 모델링에 대한 고민을 어느정도 깊게하고, 그에 따라 그래프 딥러닝 설계를 마친 후 성능 향상이라는 벽을 마주쳤을때 보면 완전 도움이 될 논문입니다. 그래프 딥러닝 성능 향상을 할 때 무엇부터 시작해야할지 막막하셨던분들 강력하게 추천드립니다.
1.알고리즘 2.COTS(Commercial-off-the-Shelf) 3. Customized Hardware 3가지 카테고리로 나눠놓았기에, 오마카세 구독자 여러분들의 현재 상황에 대해 메타인지를 진행해보시고, 거기에 걸맞는 방법론을 따라가면 되기에 밥상이 다 차려져있다 라고 생각하셔도 좋을만큼 가이던스 측면으로 너무나도 잘 작성해놓은 논문입니다. GNN 입문자분들이시라면 인쇄해두시고 두고두고 읽어도 좋을 논문이라 생각합니다.
Community detection with node attributes in multilayer networks
[https://www.nature.com/articles/s41598-020-72626-y]

커뮤니티 디텍션 알고리즘. 네트워크 사이언스 분야를 공부하다보면 여러가지 알고리즘을 마주치곤 합니다. 그 알고리즘들 중 단연 으뜸으로 실용적인 알고리즘이라 생각했었습니다.
현업에서 여러 클라이언트들을 설득하기 전까지는 말이죠. 여기에서 제가 이 커뮤니티 알고리즘을 과거형으로 실용적이다 라고 말한 이유는 여러 한계들을 마주했기 때문인데요. 그 중 대표적인 세 가지만 꼽아보자면 1.결과에 대해 고객에게 설명하기가 어렵다. 2.대용량 데이터에 적용하기가 어렵다. 3. 노드와 엣지 특성을 적용하기가 어렵다 입니다. 총체적으로 정리해보면 비즈니스 및 프로덕트 적용하기 어렵습니다.
본 포스팅은 위 세 가지 한계점들중 3번째인 노드 특성 적용이 어렵다 를 보완해보고자 알고리즘에 EM 개론을 접목했습니다. 간단하게 말하면, 그래프 토폴로지와 그래프 특성간 밸런스를 위해 파라미터를 하나 둡니다. 이 파라미터의 최적화를 위해 EM 개론을 활용한다라고 생각하시면 되겠습니다.
실험 대상이 애매하긴 하지만 결국 성능은 좋습니다. 성능 측면도 물론 논문의 우수성 입증에 중요한 역할을 하지만, 제 관점으로는 커뮤니티 디텍션이라는 알고리즘의 결과를 평가할 때, 평가 대상은 파티셔닝을 어떻게 평가하는지 , 하이퍼 파라미터에 따라 결과가 어떻게 바뀌는지 그리고 커뮤니티 디텍션에 타 개론을 어떻게 접목하는지 이상 세 가지를 중점으로 보시면 좋을거라 생각되어 공유드립니다.
제가 늘 아쉽게 생각하고 있었던 1.결과를 고객에게 설명하기 어렵다 와 3.노드와 엣지 특성을 적용하기 어렵다를 본 논문에서 시원하게 긁어주기 때문인데요. 저와 비슷한 생각을 가지고 계신분들 꼭 읽어보시길 추천드립니다.
Amazon at WSDM: The future of graph neural networks
[https://www.amazon.science/blog/amazon-at-wsdm-the-future-of-graph-neural-networks]
GNN이 벡터 공간상에 표현되는 방식 그리고 GNN 성능에 그래프 모델링이 어떤 영향을 끼치는지 두 부분에 대해 언급합니다. 저는 이 두 가지 챕터 중 후자 GNN 성능과 그래프 모델링 상관성에 대해 이야기한 부분이 좋았는데요. 이전부터 거듭강조한 그래프 모델링에 대한 중요성을 아래 근거들을 통해 명쾌하게 풀어냈기 때문이죠.
1.GNN models that can tolerate variations in how the underlying data is modeled will go a long way toward reducing the effort required to develop successful GNN-based approaches. 2.For domains for which there are multiple ways to model the underlying data via a graph, it often takes a lot of trial and error to develop successful GNN-based approaches because we need to consider the interplay between graph and GNN models.
data driven vs. model driven 방식이 화두인 요즘 전자인 data driven 에서 말하고자하는 내용이 그래프 관점으로 적혀있다고 보시면 되겠습니다. 다만, 다른 데이터 관점과 다르게 데이터 토폴로지를 직접 설계해야하기 때문에 어떻게 무엇에 기초하여 설계하는지에 대한 기획이 타 데이터 대비 더욱 중요하다고 할 수 있겠습니다. 결국 토폴로지에 따라 가중치들이 업데이트되기 때문이죠.
본 포스팅의 제목을 살펴보시면 The future of graph neural networks 인걸 확인하실수 있습니다. 미래를 예측하기엔 어렵지만, 해당 분야에 오래 몸담은 사람들의 경험과 지혜를 통해 유추는 가능할 수 있다고 생각하는데요. 이 분야에 구루인 저자의 관점을 잘 수용하셔서 오마카세 구독자 여러분들 또한 내공이 쌓이길 기원하는 바램에 소개드립니다.