25년 5월 1주차 그래프 오마카세
Affordable AI Assistants with Knowledge Graph of Thoughts
paper link : https://arxiv.org/abs/2504.02670
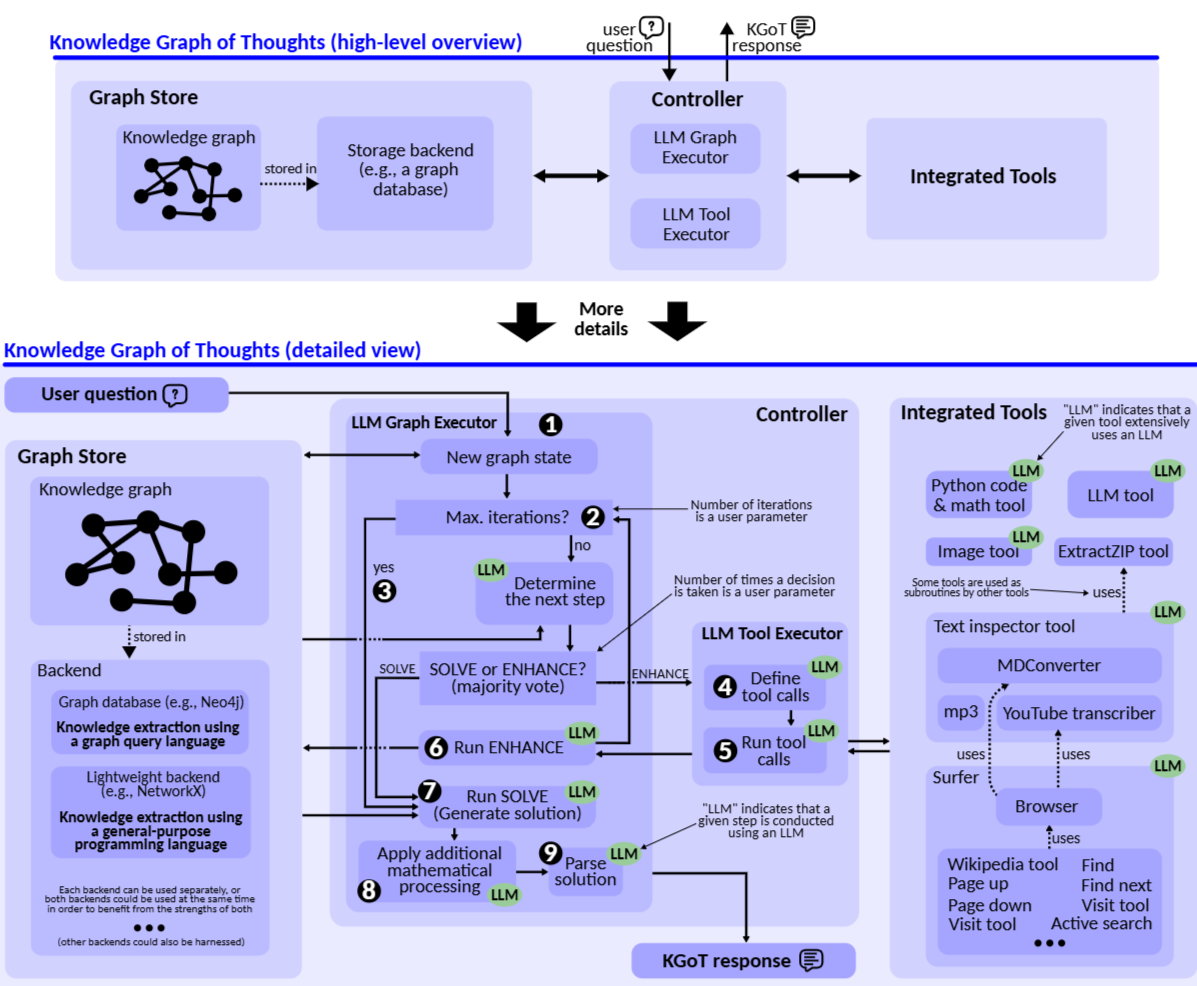
- 지식 그래프(KG)와 LLM 추론을 통합하는 혁신적인 AI 어시스턴트 아키텍처, KGot (Knowlede Graph of Thoughts)를 소개하는 논문을 전달해드리고자 합니다. 최근 LLM 논문에서 다양하게 찾아볼 수 있는 그래프, 특히 KG의 강세가 크게 체감되는 듯 싶습니다.
- 다음 논문은 LLM기반 AI 어시스턴트의 높은 운영 비용 및 GAIA (General AI Assistant) 벤치마크에서 낮은 성공률 문제를 해결하기 위한 목적성을 가지고 있습니다.
- 위 Figure로 나타난 전반적인 아키텍처를 살펴보시면, KGoT는 해결 도메인 관련 지식을 추출하여 동적 KG를 구축하고, 수학 문제 해결 & 웹 크롤러 & Python 스크립트 등과 같은 외부 도구들을 통해 반복적으로 구축된 KG를 개선합니다.
- 이렇게 구조화된 지식 표현은 저비용 모델이 복잡한 작업을 효과적으로 해결할 수 있도록 합니다. 해당 실험파트에서 GAIA 데이터셋을 대상으로, KGoT는 GPT-40 mini를 운영 비용을 약 36배 가까이 절감하면서 29%나 향상된 성능을 보여주었습니다.
- KGoT의 핵심 방법론은 다음과 같습니다.
- 지식 그래프 (KG) 구성 : LLM은 주어진 작업에 대한 "생각(thoughts)"을 생성하고, 이 생각들을 바탕으로 작업 솔루션 상태를 표현하는 KG를 구축합니다. KG는 엔티티(vertex)와 관계(edge)로 구성된 트리플(triple) 형태로 정보를 구조화합니다.
- 예를 들어, 유튜브 영상에서 특정 인물이 언급한 숫자를 찾는 작업에서, 인물 이름(예: "골룸")을 엔티티로, 배우 이름(예: "앤디 서키스")을 다른 엔티티로 추가하고, "interpreted by"라는 관계로 연결합니다.
- 수학적으로 다음 관계는 방향성 레이블 그래프 (G = (V, E, L))로써 정의될 수 있습니다. 여기에서 L은 엣지에 할당된 레이블 집합입니다.
- 외부 도구 활용 : KGoT는 KG를 개선하기 위해 다양한 외부 도구와 상호 작용합니다.
- 인터넷 검색을 통해 특정 인물이 등장한 비디오를 식별하거나, 유튜브의 transcriber 도구를 활용하여 해당 비디오의 내용을 분석할 수 있습니다.
- 정보 추출 : KG에서 정보를 추출하는 다양한 방법을 활용합니다.
- KG에서 특정 subgraph, relation, pattern 등을 추출하기 위해 Cyper 또는 SPARQL과 같은 그래프 질의 언어를 활용합니다.
- Python과 같은 범용 프로그래밍 언어를 사용하여 KG를 탐색하고 필요한 정보를 추출합니다.
- KG의 내용을 직접적으로 LLM 컨텍스트에 입력하여 LLM이 직접 해당 작업을 해결할 수 있도록 합니다. (Direct Retrieval)
- 지식 그래프 (KG) 구성 : LLM은 주어진 작업에 대한 "생각(thoughts)"을 생성하고, 이 생각들을 바탕으로 작업 솔루션 상태를 표현하는 KG를 구축합니다. KG는 엔티티(vertex)와 관계(edge)로 구성된 트리플(triple) 형태로 정보를 구조화합니다.
- 위 Figure의 아키텍처는 크게 3가지 주요 요소들로 구성됩니다.
- Graph Store : KG를 저장 및 관리. Neo4j 또는 NetworkX를 통해 구현됩니다.
- Controller : KG 구축 및 관리를 위한 LLM Graph Executor 및 LLM Tool Executor로 구성된 dual-LLM 아키텍처를 사용하여 KG와 통합 도구 간의 상호작용을 관리합니다.
- Integrated Tools : Python Code Tool, LLM Tool, Image Tool 등과 같은 해당 작업에 필요한 다양한 도구들을 제공합니다.
- KGoT의 시스템 안정성을 위해 다수결 (majority voting) 알고리즘을 활용하고, LangChain의 JSON Parsor를 사용하여 LLM 생성 구문의 오류를 관리하고, Exponential backoff 및 로깅 시스템을 통해 API 및 시스템 관련한 오류를 처리합니다. 그로부터 GAIA 벤치마크에서 더 많은 작업을 해결할 수 있고 운영 비용의 효율성을 크게 높힐 수 있었습니다.
- 다음 KGoT 논문로부터, KG 기반 표현의 LLM 추론 능력을 향상시킬 수 있는 잠재성을 확인해볼 수 있는 좋은 논문이라고 생각합니다. 보다 구체적인 내용은 본 논문을 확인해보시면 좋을 것 같습니다.
[Contact Info]
Gmail: jhbae1184@akane.waseda.jp
Twitter (X): @jhbae1184
안녕하세요 정이태입니다. 2주차입니다.
이번주차까지 기본 개념을 다루는 시간을 가졌습니다. Team1,2,3 마다 모두 역할이 다르기에, 그 각각의 팀마다 필요한 개념들인 Team1 분들에게는 온톨로지 반드는 방식 Team2 분들에게는 GraphRAG&LightRAG 리뷰 Team3 분들에게는 기획을 위한 데이터셋들을 설명하고 질문 및 응답하는 시간을 가졌어요.
굉장히 방대한 개념이라, 자료 준비하는데에도 시간이 많이 소요되고 설명하는데도 오랜 시간이 걸려서 모든걸 한번에 다 해야하는게 맞을까라는 고민을 했지만, GraphRAG는 각각의 task 들이 모두 연관성이 깊기에, 3팀 모두 모일수 있는 시간에 한번에 하는게 좋겠다 라는 생각으로 진행했네요.
Team 1 -온톨로지 만드는 방식
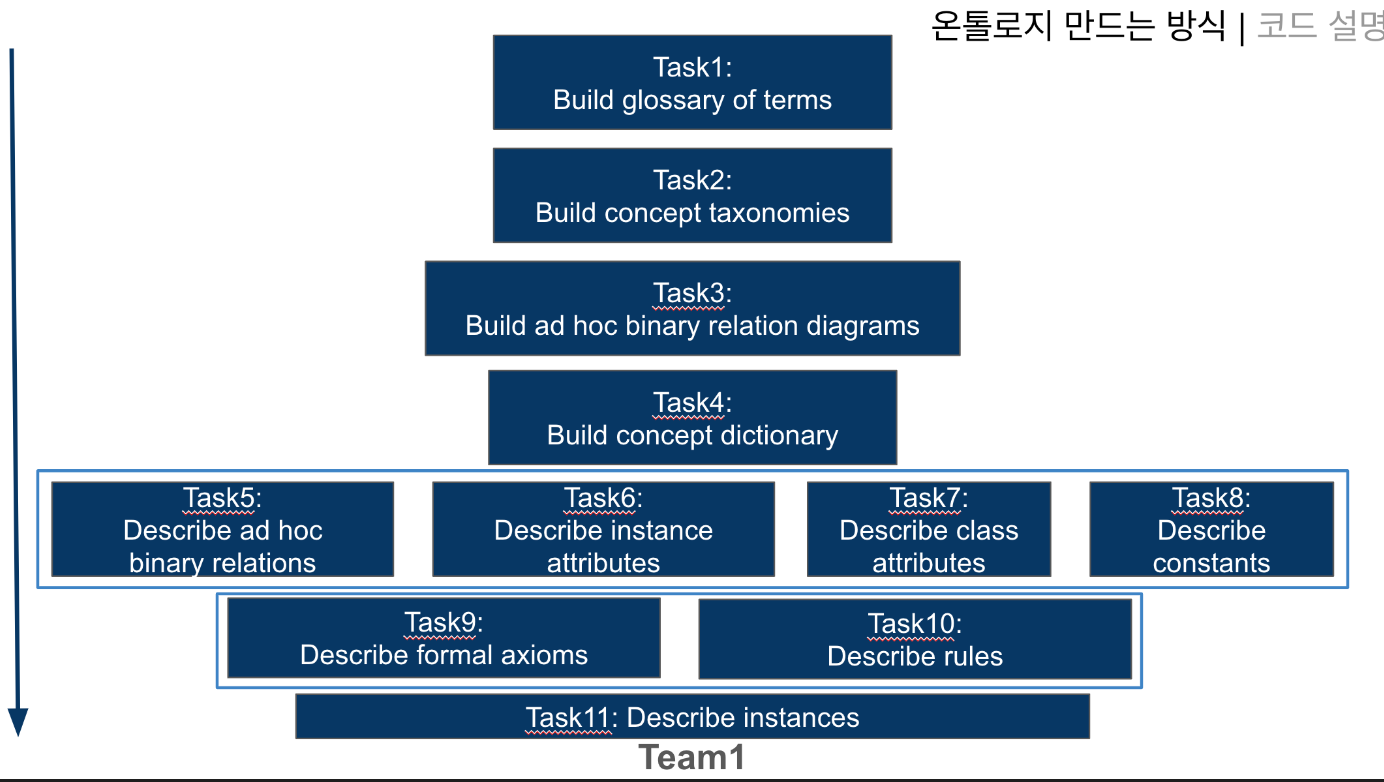
온톨로지를 만드는 방식을 설명했어요. Team1에서는 직접 온톨로지를 구축하지는 않지만, 어떤식으로 온톨로지를 구축하는지 프로세스 도메인이라 생각하고, 이를 인지한 상태에서 작업을 진행하면 좋겠다라는 생각으로 설명했네요. Task1~11 과정은 온라인상에 모두 잘 나와있어서 오버뷰는 블로그(https://graphwoody.inblog.ai/graphrag-with-document) 에 설명이 되어 있어서, 제가 생각하기에 까다롭고 애매한 부분인 Task9와 Task10 을 그래프 오마카세에서 중점적으로 언급해볼게요.
Task9는 semantic set theory 라고도 볼 수 있는 ontology 에서 사실들을 그룹핑하는 단계라고 할 수 있습니다. 어떤 객체들이 어느 그룹에 속하는지, 속하지않는지를 표현하는 단계입니다.

위 첨부 그림을 예시로 들어볼게요. 첫번째는 strategic resource 에 속한 것들은 모두 supplychaininput 에 속한다. 라는 사실을 표현했고 두번째는 니어쇼어링(가까운 국가에서 이루어지는 아웃소싱)이 진행되는 나라 고위험군나라에 속하지 않는다 라는 사실을 표현했습니다. 이처럼 이전 Task 에서 만들어진 결과물들을 Task9에서는 그룹핑해줍니다.
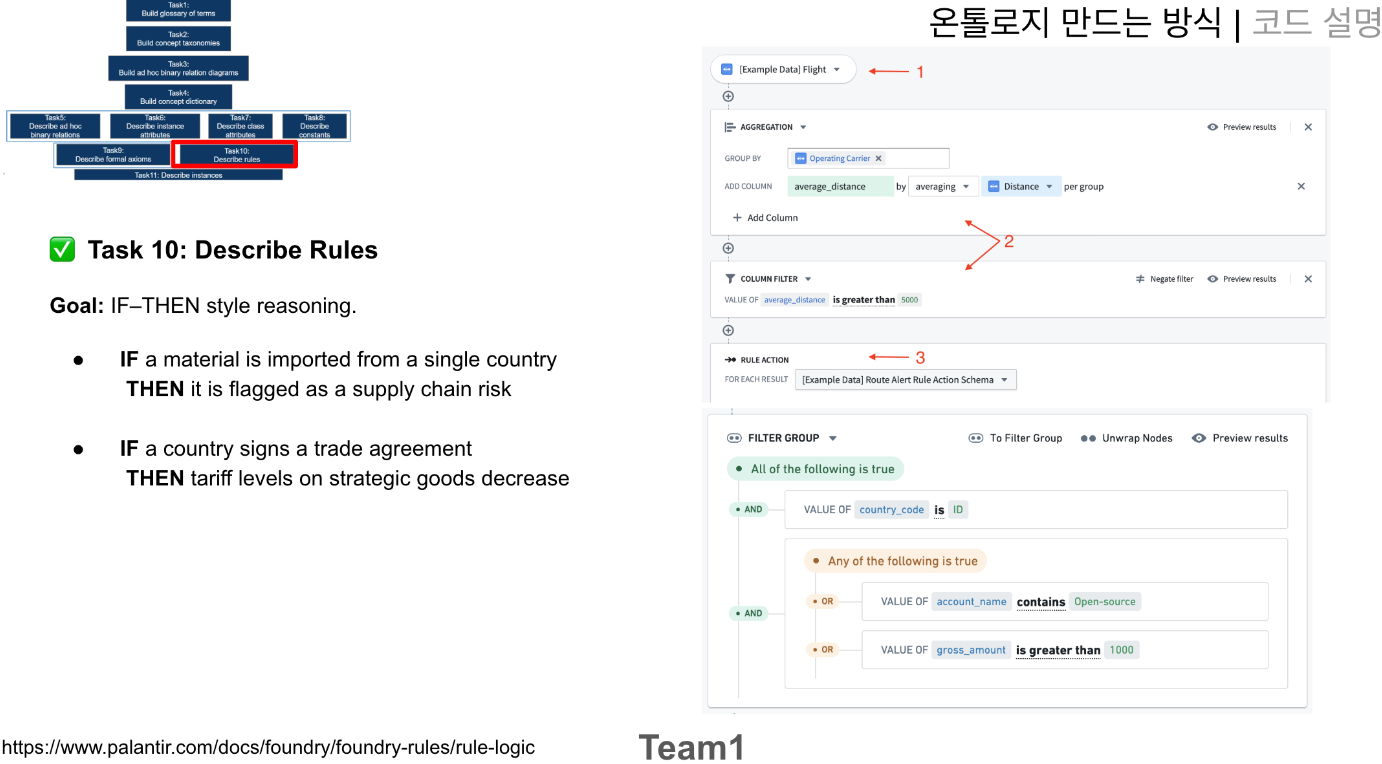
위에 만들어진 공리들을 기준으로 새로운 사실들(데이터)들이 주입됐을때, if-then 방식으로 판단하고 이를 분류하는 작업이라고 봐주시면 되겠습니다. 예시를 들어보자면, 만약 단일 국가에서 원자재를 수입했다면, supply chian 에서 red flag 를 표해라 와 만약 해당 국가에서 trade agreement 에 사인을 했다면, 전략 물자에 대한 관세 수준이 감소한다. 라는 룰을 이야기합니다.
** traiff level (국가가 외국 상품에 부과하는 세금, 즉 관세를 뜻합니다.) , Strategic goods: 국가 안보, 경제 안정을 위해 중요하다고 여겨지는 전략 물자를 의미합니다. (예: 반도체, 배터리, 첨단 장비 등)
보시다시피, Task9와 10은 도메인과 연관성이 굉장히 깊습니다. 현상들에 대한 연관성과 그 연관성 속에 새로운 데이터들이 추가됐을때 분류할 기준을 도메인 기반으로 판단해야하기 때문입니다. 때문에, 도메인 이해도가 높을수록 이 퀄리티가 높아질 것임을 직감적으로 알 수 있습니다.
또한, 보시다시피 어려운 용어들 즉 도메인 전문가들만이 통용되는 단어들을 위주로 지식들이 기존 Knowledge base에 작성되어있거나 암묵지 형태로 보관되어 있기에, 이를 도출해서 공리와 룰 형태로 표현하는게 Ontologist 의 핵심 역량이라고 할 수 있습니다.
우측의 사례는 팔란티어에서 실제 rule-logic을 어떻게 만들고 관리하는지를 보여준 예시에요. ChatGPT 에 Foundary rule logic 3줄 요약을 요청하니 다음과 같은 답변을 내주네요. 위에 기존 온톨로지에서 설명하는 공리 및 룰 설계와 유사한 형태를 띔을 확인할 수 있어요.
룰 로직의 구조:
Foundry의 각 룰은 세 가지 주요 구성 요소로 이루어집니다: 입력(Input) (데이터셋이나 오브젝트 같은 데이터 소스), 로직 블록(Logic Block) (필터, 수식, 집계, 조인과 같은 변환 처리), 그리고 룰 출력(Output) (룰이 최종적으로 생성하는 데이터셋)입니다.
로직 블록의 기능:
로직 블록은 입력 데이터를 순차적으로 처리하면서 사용자가 지정한 변환을 적용합니다. 이를 통해 복잡한 비즈니스 로직을 로우코드(low-code) 방식, 즉 포인트-앤-클릭 인터페이스로 쉽게 정의할 수 있습니다.
커스터마이징 및 워크플로우 통합:
룰 출력은 처리된 데이터의 구조와 저장 위치를 정의하며, 워크플로우 소유자는 이를 통해 특정 스키마를 강제하거나 Foundry 내의 더 큰 데이터 워크플로우에 룰을 통합할 수 있습니다.
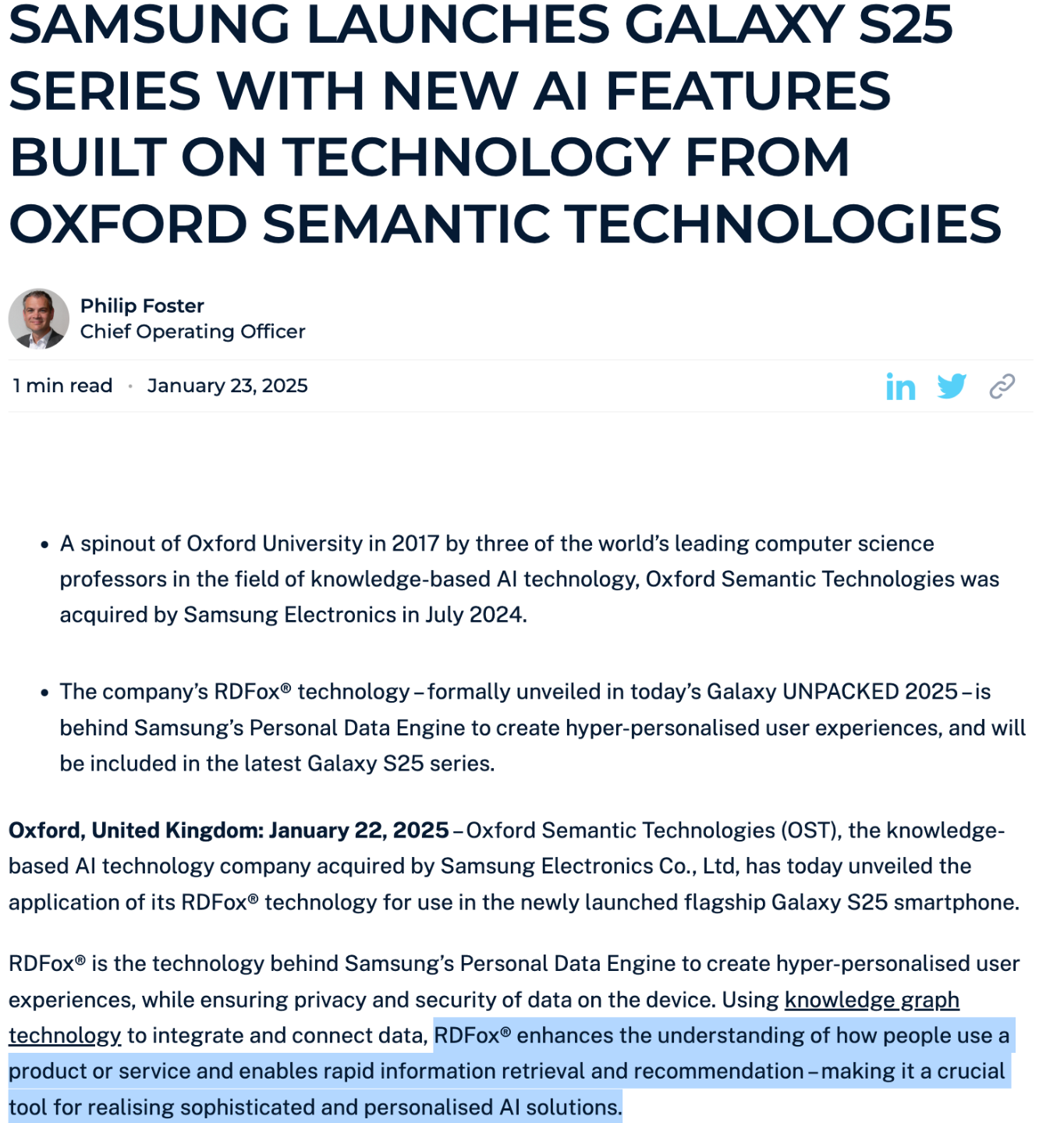
그럼, 여기에서 팔란티어 외에 다른 곳에서는 어떻게 온톨로지가 활용되느냐 궁금하실거 같아요. 다른 사례로는 삼성에서 갤럭시 S25-ondevice 형태로 적용되고 있다 하네요. 자세한 내용은 아쉽게도 찾질 못했고, RDFox 에서 언급한 내용을 한 번 같이 살펴보겠습니다. 내용만 살펴보면, RDFox 라는 RDF 활용하는 GraphDB 를 갤럭시 25에 적재해서 엔진으로 활용하는거 같네요.
'how people use a product or service and enables rapid information retrieval and recommendaion' 이라는 부분이 인상적입니다. 아마도 그 내부에는 휴대폰에서 기존 유저들이 활용하는 패턴을 온톨로지 형태로 구축해놓고, 위 Task9,10과 같이 유저별 공리 및 룰들을 만들어둬서 추론하지 않을까 싶네요. 덕분에, 기존 Ondevice 에서 추론시에 발생하는 연산량을 대폭 감소하고 이를 중앙 서버까지 전달하지않고 기계 내부에서 연산을 할 수 있으니 security 와 speed 성능까지 얻을 수 있을거란 생각이 듭니다.
자세한 내용은 아마 조만간 개최되는 KGC에서 공개하지 않을까 싶네요. 관심있으신 분들이 계실까하여, 관련 링크들 첨부합니다.

컨퍼런스 링크 : https://events.knowledgegraph.tech/event/7ffec6d4-b17d-4fce-b55c-fcd77fa58146/home

출처 : https://www.palantir.com/docs/foundry/ontology/why-ontology
그럼 이 과정을 진행해서 과연 어디에 좋을까 라는 추상적이고 근본적인 물음이 드실수도 있는데요. 팔란티어에서 주장하는 온톨로지를 만들면 좋은 5가지 이유에 대해서도 언급했네요.
- 대규모 연결성(Connectivity at Scale) – 서로 다른 부서, 시스템, 데이터 소스를 하나의 일관된 구조로 연결합니다.
- 해석 가능성(Interpretability) – 복잡한 데이터를 사람들이 이해할 수 있도록 명확하게 표현합니다.
- 규모의 경제(Economies of Scale) – 동일한 온톨로지 모델을 기반으로 여러 팀과 워크플로우가 재사용 가능해 효율성이 올라갑니다.
- 의사결정 기록(Decision Capture) – 누가, 왜, 어떤 데이터로 의사결정을 내렸는지 온톨로지에 자연스럽게 저장할 수 있습니다.
- 운영 AI/ML 지원(Powering Operational AI/ML) – 온톨로지를 기반으로 더 정확하고 실시간 대응 가능한 AI/ML 시스템을 구축할 수 있습니다.
간단히 이야기해보면, 각 부서마다 데이터 기반해서 의사결정을 진행할텐데, 이를 통합해서 타부서(IT,비IT 관계없이) 에서 모두 투명하게 이를 확인할 수 있다는게 핵심이였습니다. 때문에, 동일한 의사결정 상황이 아니지만, 유사한 비즈니스 의사결정이 필요할때 이를 기반으로 참고해서 의사결정을 할 수 있기때문에 효율적이라는거죠.
추가로, 비IT부서도 이 의사결정에 참여하기에 접근장벽을 낮출 수 있는 툴로써 온톨로지가 효율적이라고 이야기합니다. 예를 들면, 비IT 부서에서는 데이터 기반으로 의사결정을 하고 싶을때, IT 부서에 데이터 분석 결과를 요청하게 될 것이고, 이때 IT 부서 내에서도 데이터분석가 - 데이터 엔지니어 - 인프라 엔지니어 와 같이 내부 체이닝이 존재할텐데, 이 체이닝을 거쳐가며 병목이 걸린다는거죠.
비즈니스 사이클이 이전대비 점점 빨라지고 있는 요즘 딜레이가 있을수록 티핑 포인트를 놓치게 될텐데, 이를 보완할 수 있는 툴로써 온톨로지가 효율적임을 이야기합니다.
Team 2 - GraphRAG & LightRAG 리뷰
팀2에서는 GraphRAG 전반적인 내용과 LightRAG 프로세스를 이야기했습니다. LightRAG 논문에서 비교군을 GraphRAG로 삼았고, 이때 비교한 팩터들이 token usage 와 speed 였기 때문에 어디에서 과연 이 차이가 발생하는지를 기초 개념으로 인지한 상태에서 LightRAG를 활용해야 그 가치를 극대화할 수 있을거란 생각에서 이렇게 구성했네요.
neo4j 에서 구현한 Microsoft GraphRAG 블로그 포스팅을 활용해서 설명했어요. 저자인 Tomaz 님을 개인적으로 좋아하는데요. 많은 이유가 있겠지만, 한 가지만을 꼽자면 Graph 기술을 실용적으로 접근하기 때문입니다. 때문에, 실제 프로덕트에 적용할때 고민할만한 포인트들을 많이 짚어줍니다. 이 포인트들을 처음 기획할 때 인지하지 못한 상태에서 발생할 문제인 아차 모먼트를 줄여줄 수 있는거죠. 즉, 사고실험시에 놓칠법한 여러 trial-error 들을 미리 예상하고 어떻게 대처할 수 있을지를 대비할 수 있습니다.
GraphRAG에 대한 설명은 워낙 여러곳에서 설명이 되어있기에, 게시물에서 유의깊게 보면 좋을 부분을 이야기해볼게요. 바로 entity 와 token 간 상관관계인데요. Entity 가 핵심인 GraphRAG 에서 유의미한 그리고 다양한 엔티티들을 추출하기 위해 chunk size를 늘리곤 합니다. 근데 과연 chunk size를 늘린다고해서 엔티티들을 많이 추출할 수 있을까요? 그 물음에 대한 답변을 이야기합니다.
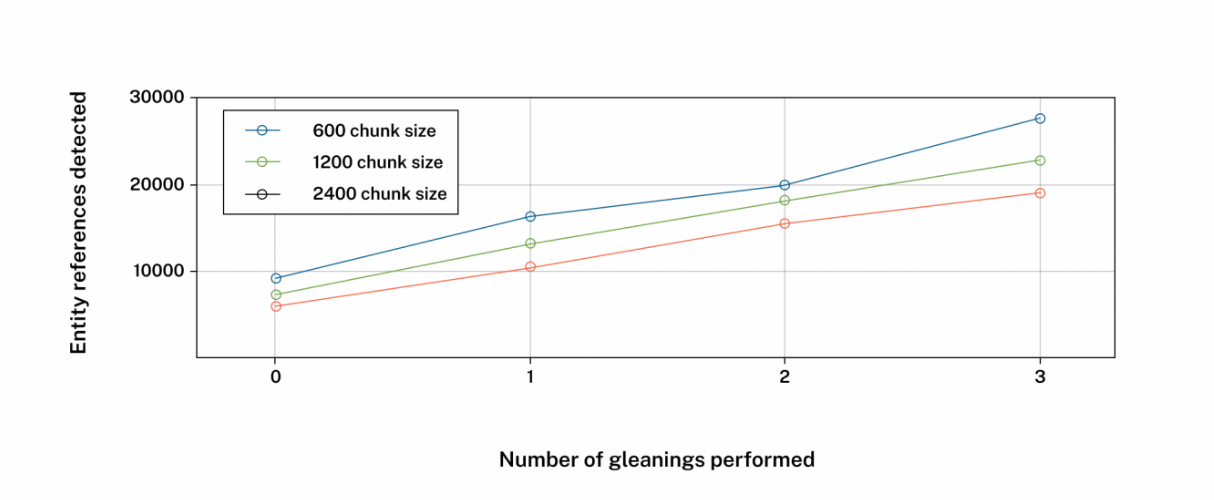
위 그림에서 나타나 있듯이, 청크사이즈가 크다하더라도 Entity reference 가 비례해서 많이 도출되지 않음을 확인할 수 있습니다. 오히려 chunk size 가 가장 적은 600 사이즈에서 entity 를 가장 많이 도출했다는 거죠. 함의하는바가 큽니다. chunk size 가 중요한게 아닌, entity extraction 프롬프트의 entity type이 중요하고, 이 entity type은 결국 도메인 그리고 graphrag를 진행해서 풀고자하는 문제들과의 교집합 포인트를 잘 잡아서 넣어줘야 된다는거죠.

다음은, node degree distribution 입니다. 그래프가 real-world 케이스에서 대다수 멱급수 분포를 띈다는건 공공연한 사실일거라 생각됩니다. 과연 document -> entity 도 이 현상이 동일할까 라는 의문이 들었을텐데요. 그렇습니다. 마찬가지입니다. 직관적으로 보시기에도 edge 가 많은 entity들을 조회할때, 병목현상이 발생할 것이라는 생각이 강하게 들겁니다.
아무리 entity 퀄리티들 즉 knowledge graph가 잘 만들어졌다 하더라도, 조회 에서 latency 가 발생한다면 더나아가 OOM 그리고 Disk spiling 이 발생한다면 과연 유저가 이를 이해해줄 수 있을까 라는 본질적인 의문을 갖게되는거죠. 서비스 관점에서는 latency 가 굉장히 중요하기 때문에, Team2에서는 이를 인지하고 tail 에 속해있는 Node degree > 100 인 entity 들을 따로 indexing 해주는게 과제 중 하나임을 언급했구요.

tomaz 님 포스팅 : https://neo4j.com/blog/developer/global-graphrag-neo4j-langchain/
추가로, microsoft 에서 community detection 이 동작할때 활용하는 알고리즘은 leiden 에서도 간단히 이야기했습니다. modularity 라는 지표를 기반으로 클러스터링 내에 특정 노드가 추가 / 삭제 되었을때 이 값들이 어떻게 변하는지 그 추세를 보면서 community 최적화가 진행되고 이 최적화 과정속에서 위계가 만들어지기 때문에, 결국 graphrag 의 강점인 Global query가 도대체 내부에서 어떻게 만들어지는가 를 Team2분들에게 전달드리고 싶었던 의도가 담긴 설명이였습니다.

leiden 알고리즘 : https://arxiv.org/abs/1810.08473
이후엔 LightRAG 알고리즘을 리뷰했습니다. 자세한 내용은 제가 이전에 리뷰한 https://www.graphusergroup.com/25-january-4weeks-graphomakase/ 를 보시면 될 거 같습니다.

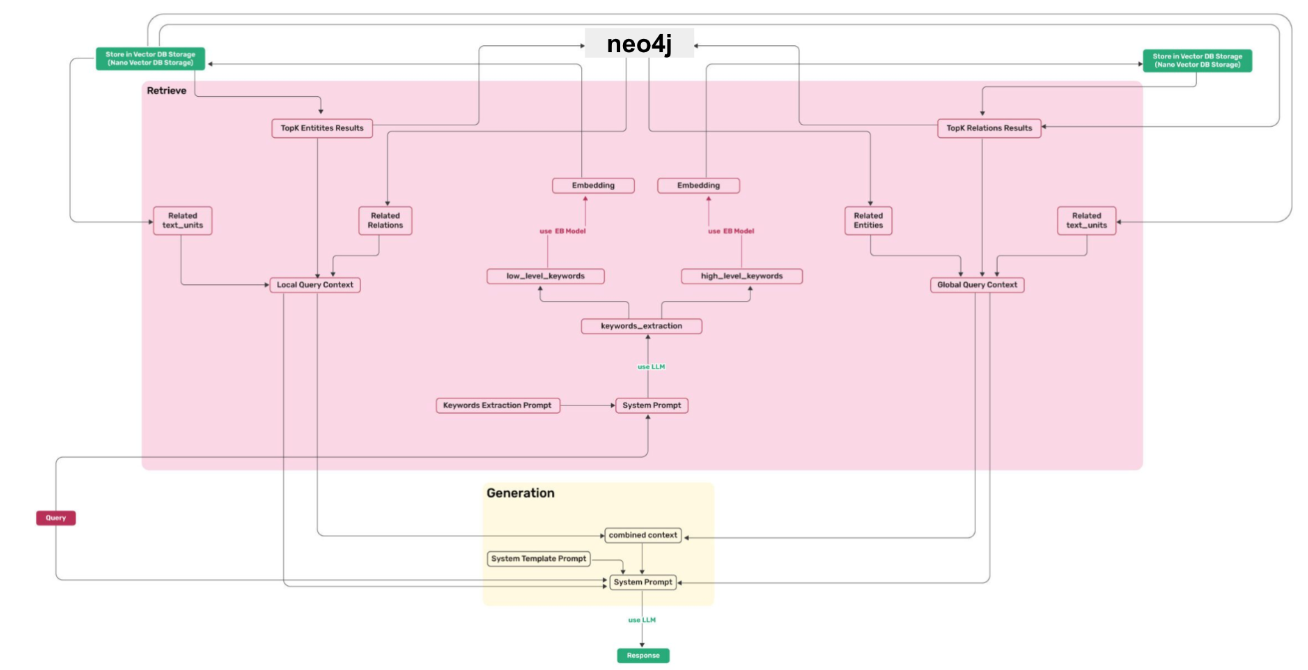
직접 활용하는게 목적인 Team2 분들에게 알고리즘 리뷰와 그에 맞춰 코드 및 워크플로우가 어떻게 되는지를 아래 두 그림(indexing, querying) 을 활용해서 설명했습니다.
indexing 단계에서 난해했던 부분이였던 key-value 를 도대체 어떻게 관리하는지가 명확히 표현되어 있습니다. 과연 무슨 값들이 KV storage에 저장이 되는지를요. KV storage를 언급한 이유는 GraphRAG 대비 LightRAG의 강점을 fast adaptition 이라고 언급했기 때문입니다.
기존 graph CRUD 대비 lightRAG는 key-value로 데이터 일관성 즉, persistence 를 관리할 수 있기때문에 비즈니스 레벨에서 중요한 데이터 일관성 유지를 효율적으로 할 수 있다 라고 설명하는데, 과연 이게 어디에서 어떻게 되는지가 되게 난해했거든요. 이를 설명하고, 더나아가 knowledge graph storage 에 어떤 데이터들이 적재되고, vector storage에 어떤 데이터들이 적재되는지를 이야기합니다.

Querying 단계에선 유저의 쿼리가 들어왔을때, 어떻게 답변이 생성되고 유저에게 전달되는지를 이야기합니다. 여기에서 유의깊게 보시면 좋을 부분은 low-level , high-level keyword 가 임베딩되고, 이 임베딩된 결과물들이 Vector DB와 어떤 연관성이 있는지, 또한 이 vector DB의 결과물들과 Knowledge graph storage 조회가 어떤 연관성이 있는지 이 keyword start graph end chaining 과정을 이해하는게 중요하기 때문에 이를 설명했습니다.
설명뒤, 멘티분들께서 질문해주셨던 두 개를 같이 공유드려보자면,
1. Team1에서 만든 Ontology 가 GraphRAG의 Retrieval 혹은 Generation 까지 갔을때 얼마나 유의미한지를 어떻게 측정하는지.
첫째 질문에 대한 답변은 지금 멘토링 레벨에서 다루기엔 힘든 부분이다. 프로덕션 레벨에서 다루면 좋을거 같은데, 그 이유는 Ontology 품질 평가에 대한 기준부터 임베딩 모델 , 벡터 디비의 인덱싱 , 벡터 디비의 조회 결과(벡터 디비 retrieval result) 등 Graph 까지 가는데, 엮여있는 포인트들이 많기 때문입니다.
이 모든 포인트들의 경우의수가 많기때문에, 지금 멘토링 과정에서 다루기엔 범주가 너무 넓다. 그러기에, 이론적으로 GraphRAG까지 어떤 요소들이 개입되는지 그 요소들만 인지하는 것만으로도 성공적이다. 라고 이야기를 했습니다. 여태까지 GraphRAG를 구현한다고 하는 여러 컨퍼런스 세미나를 관찰한 결과 이 포인트들을 모두 언급한 곳은 제가 아는한에서는 없었기 때문이죠.
2.LightRAG에서는 querying 모드가 크게 5가지가 있다고 하는데, 위 그림에서는 mode를 어디에서 판별하고 어떻게 플로우가 달라지는지 이해가 되지않는다. 였습니다.
LightRAG는 querying 시 크게 5가지 모드로 동작합니다.
- "local": Focuses on context-dependent information.
- "global": Utilizes global knowledge.
- "hybrid": Combines local and global retrieval methods.
- "naive": Performs a basic search without advanced techniques.
- "mix": Integrates knowledge graph and vector retrieval.

위 테이블은 명확치 않아서 코드 내 query_param 으로 살펴본 결과입니다. hybrid, native 그리고 Mix는 익숙한 graphrag 방식인 반면에, low-level , high-level 는 익숙치 않으실텐데요. 유저가 쿼리를 입력했을때, 해당 쿼리에서 low-level , high-level 키워드를 추출하고 그 키워드 기반으로 search하는 방식입니다. GraphRAG 의 Community report 기반으로 global level 질의를 답변하는 반면에, lightrag 에서는 high-level keyword 를 기반으로 답변하는게 가장 큰 차이점이라고 할 수 있겠습니다.
프롬프트와 함께 살펴볼까요? 여기에서 의문점을 가질 부분이 있습니다. 분명 document 에서는 entity 를 추출했는데, 이 entity 가 keyword 랑 어떻게 대조할 수 있지? 라는 부분을요. entity들은 vector db에 적재가 되고, keyword 또한 추출된 이후 vector db에서 검색이 되기때문에 vector db에서 두 관점들이 만나게 됩니다. 때문에, 등한시여겼던 vector db 관리가 lightrag에서는 중요한 포인트임을 알 수 있습니다.
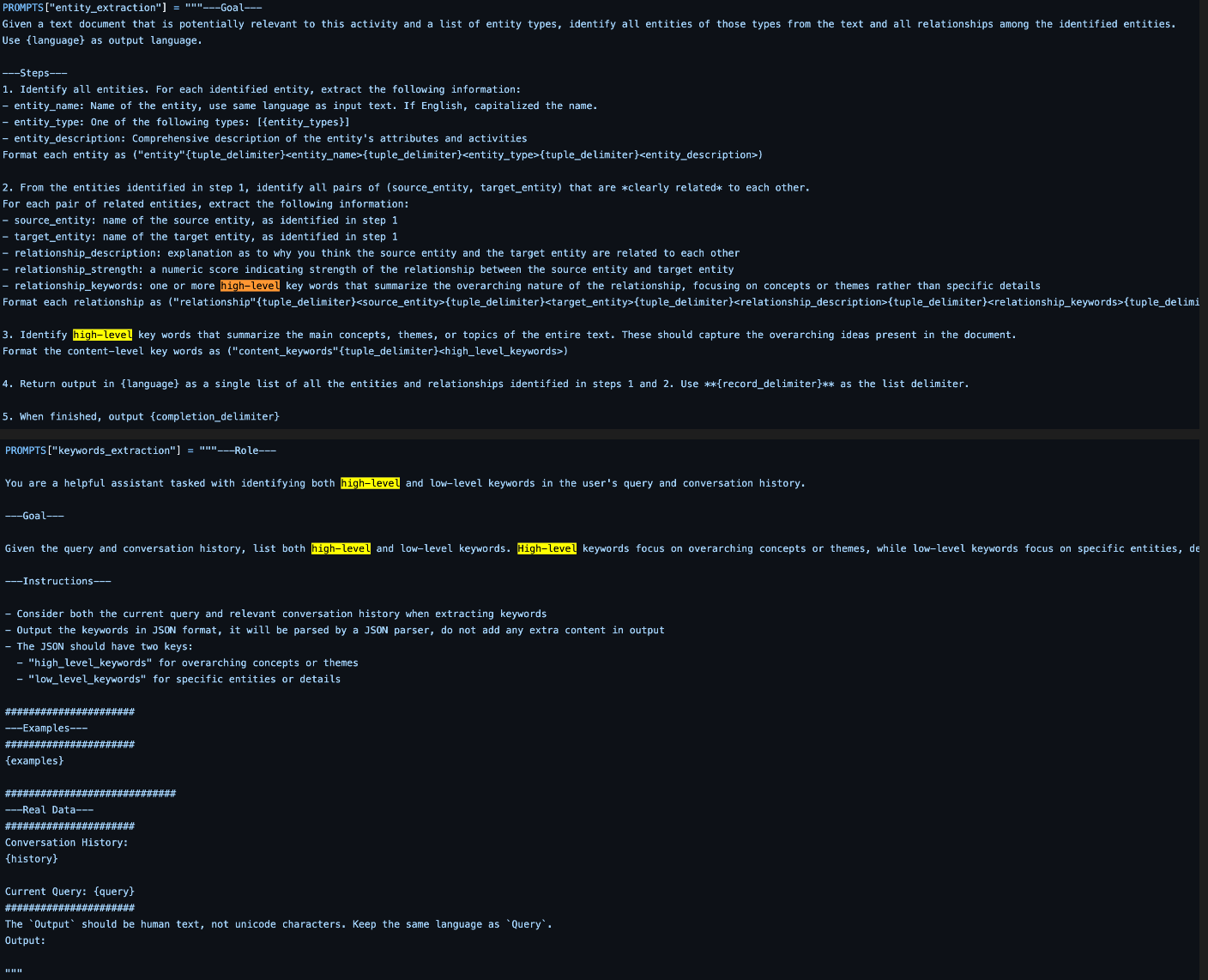
LightRAG 자료 : https://github.com/HKUDS/LightRAG/blob/main/lightrag/prompt.py

PathRAG에 대해서 간단히 언급했습니다. PathRAG를 활용하지 않지만, 논문에 작성도니 그림을 활용해서 설명하면 좋겠다 라는 생각이 들어서 였는데요. 위 그림을 보시죠. 아까 GraphRAG 와 LightRAG 이 각각 global query를 답변할때, community report 그리고 high-level keyword 를 추출해서 활용한다 라고 이야기했습니다. 그 내용이 그림에 직관적으로 잘 표현되어 있네요.
LightRAG 가 MS GraphRAG대비 비용효율적이라고 하지만, topk 기반 subgraph를 모두 retrieval 결과로 활용합니다. PathRAG는 이를 문제로 제기해서 유의미한 subgraph를 추출해야하고, 이를 pruning 해서 더욱 가볍고 유의미한 서브그래프들을 추출합니다. 때문에 성능과 비용 또한 GraphRAG, LightRAG 대비 효율적이겠죠.
PathRAG 그림 : https://arxiv.org/pdf/2502.14902
GraphRAG , LightRAG 그리고 PathRAG를 설명한 영상이 있어서 공유드립니다. 흐름이 궁금하신 분들이 계시다면, 한 번 살펴보셔도 좋을거 같습니다.

유튜브 영상 : https://www.youtube.com/watch?v=oetP9uksUwM
Team 3 - 구상 데이터셋 소개
Team3에서는 이 데모를 활용할 예상 유저를 기획하고 GraphRAG만의 장점인 multi-hop query & answer 을 정량적으로 평가할 수 있는 Graph Evaluation Dataset을 만드는 역할을 합니다. 때문에, 데이터셋을 합리적으로 결정하고 이 데이터셋에서 어떤 비즈니스 임팩트를 낼 수 있는지를 고려해야합니다. 이번 주차에서는 제가 데이터셋을 어떤 논리로 선정했는지, 이 데이터셋 관점을 활용할 때 어떤 임팩트를 낼 수 있는지 예시를 들어 이야기했습니다.
우선 1주차에서 이야기한 supply chain 데이터셋과 결합하면 좋을 6가지 후보군을 이야기했고, 거기에서 USTR(무역대표부) 를 선정함을 가정했을때를 이야기했습니다. 그 이유로는 supply chain 데이터셋이 2023년도이기때문에, 1. 연결고리인 date 즉, 2023년도에 대한 데이터를 온전히 활용할 수 있어야 함. 2. 공신력 있고 파급력 있는 기관이여야함. 이 두가지 조건을 만족했기 때문입니다.
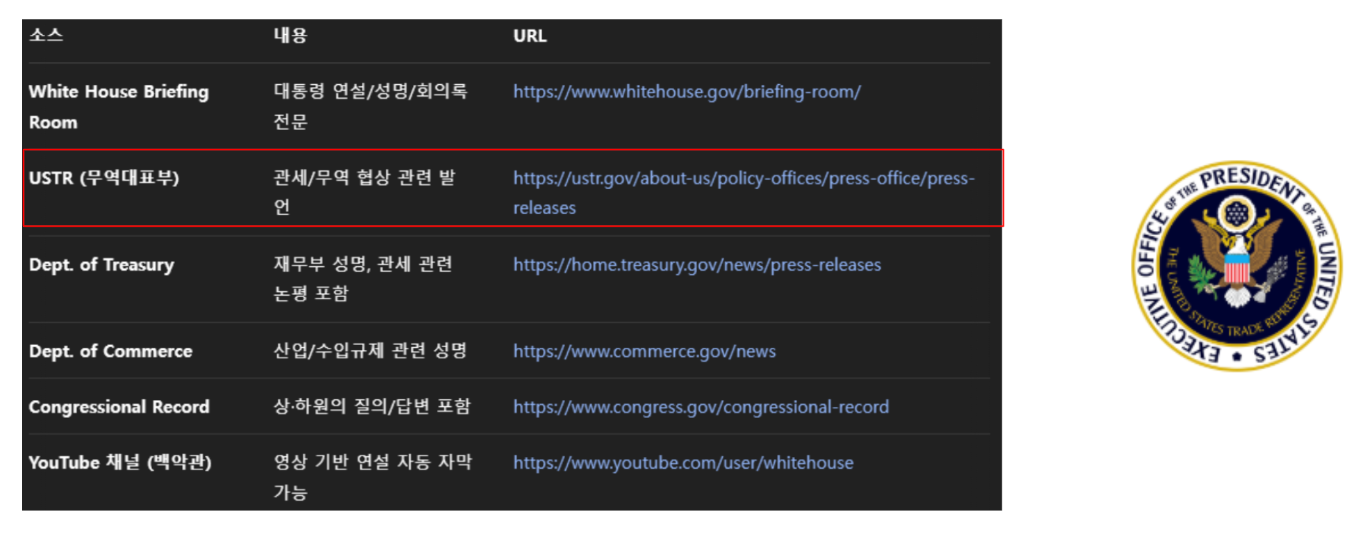
실제 웹 홈페이지를 들어가보면 news 란에 press release , fact sheets, speeches and remarks 그리고 blog and op-eds 4가지 데이터가 있습니다. 각각이 의미하는 바는 아래 그림에서 이야기한 것처럼 사실들을 event 시점 전/후 혹은 의도 에 따라 나눠집니다.
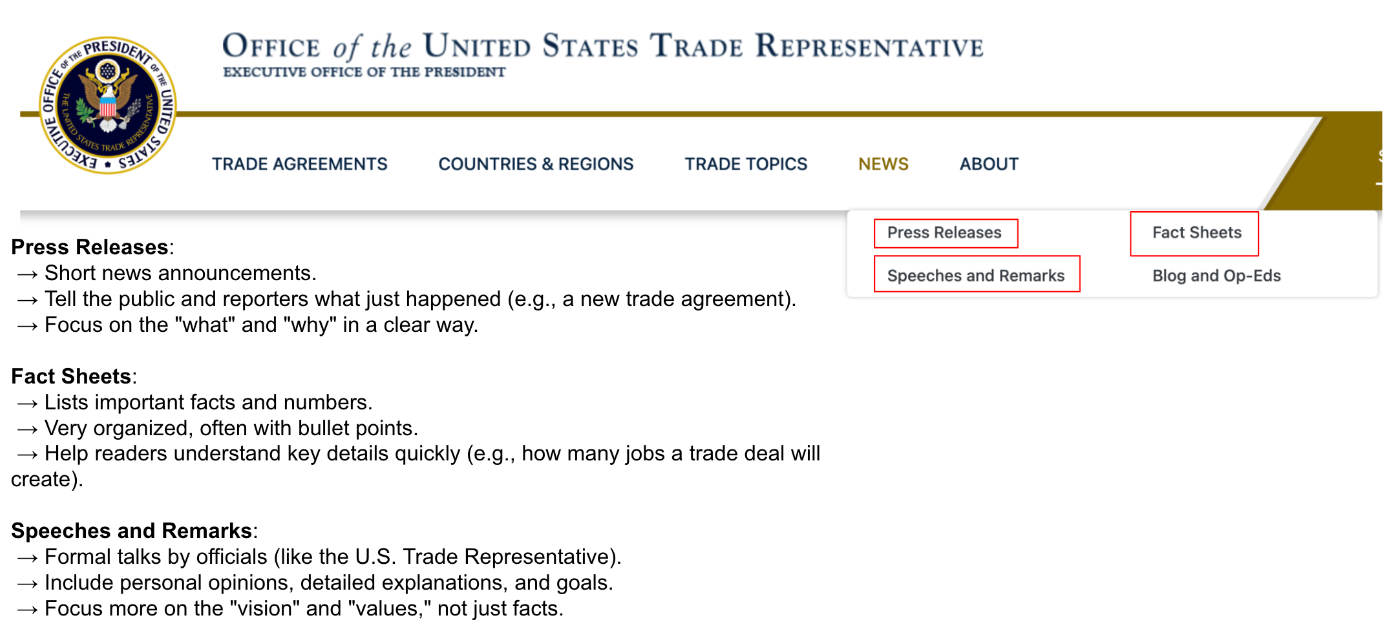
그럼 이 데이터들이 어떤 임팩트가 있는지를 고민해봐야하는데요. Press releases, fact sheets, speeches and remarks 3가지 각각 just happended & 'what' and 'why' , 'improtant facts' , 'organized' , 'formal talks by official' , "vision" and "values' , not just facts 가 핵심입니다. press release 와 fact sheets 는 모두 사실을 이야기하는 반면에, speeches and remarks 는 추상적이며 큰 방향성만을 이야기합니다. 즉, 사실이 아닐수도 있다는거죠.
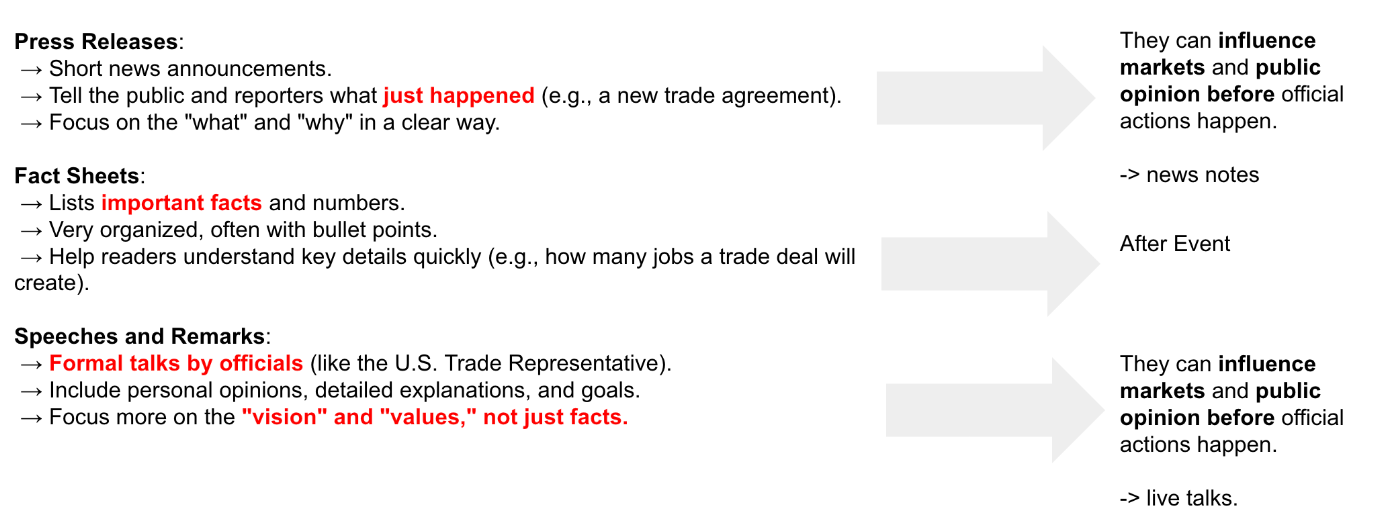

그럼 이 데이터셋들이 과연 실제 비즈니스 그리고 시장에서 어떤 임팩트를 지니는지 한 번 생각해봤습니다. Speech 는 실제 액션이 아니고, 비젼이긴 하지만 시장에선 이 정보가 가장 최근이며 방향성이라는 가정하에 이벤트가 발생하기에 Speech가 가장 임팩트가 큽니다. 반면에, Fact는 특정 이벤트가 발생한 이후에 실제 어떤 내용들이 현상 반영되었는지를 작성되어 있기때문에 임팩트가 미미합니다.

그럼 이제 저희가 진행할 수 있는 시나리오는 다음 두가지입니다. Domain & lexical graph 즉, 메타들을 통합해서 내/외부 변인들간 복잡한 관계성을 Retrieval 할 수 있는 GraphRAG, Document 에서 발생하는 Multi-hop 에 대한 답변에 도움이 되는 데이터들을 Retrieval 할 수 있는 GraphRAG. 이 결과물들이 어떤 유저들 그리고 어떤 시장들의 니즈에 맞는지는 Team3 분들과 논의해봐야할 거 같네요. 기술 관점도 물론 중요하지만, 이 기술을 활용해 어떻게 비즈니스 임팩트를 낼지 또한 중요하니깐요.
다음 주차에는 이번 주차까지 진행했던 기획 그리고 이론들을 한 번 돌려볼 수 있는 샘플 구현체를 기반으로 가이드 라인을 멘티분들에게 드릴 예정입니다. 제가 직접 구현하면 action list 가 도출되고, 그 action list를 프레임으로 삼아서, 멘티분들의 아이디어를 덧붙인다면 멘티분들만의 강력한 무기가 될 수 있다 생각합니다. 냉랭한 시장 상황속에서 본인만의 강점이 너무나도 중요해지고 있고, 그 강점을 GraphRAG로 만들어보고싶다 가 멘티분들의 니즈였기 때문이죠.
이번주차 정보들도 여러분들에게 유익했으면합니다. 궁금하신 부분이 있으면 편하게 연락주세요. Graphusergroup@gmail.com 에서 기다리고 있겠습니다. 그럼 다들 한 주 고생많으셨고, 다음주에 뵙겠습니다.