25년 11월 2주차 그래프 오마카세
GraphFrames: Architectural Evolution from GraphX for Big Data and AI Applications
GraphFrames: an integrated API for mixing graph and relational queries
Graph data is prevalent in many domains, but it has usually required specialized engines to analyze. This design is onerous for users and precludes optimization across complete workflows. We…
New GraphFrames release with improved performance and new algorithms | Sem Sinchenko posted on the topic | LinkedIn
On behalf of the GraphFrames maintainers, I am happy to announce the delivery of a new release. It is a significant improvement! It improves performance and memory management:
The new release provides 3-50x faster performance for all algorithms. The x5 performance improvement in Connected Components is especially important, as it allows one to perform graph-based identity resolution much faster with the new GraphFrames. All Pregel-based algorithms, such as Shortest Paths and Label Propagation, received a boost of around 3x. The new release comes with its own internal fork of Apache #Spark GraphX due to its deprecation in upstream Spark. This allows us to improve the performance of GraphX-based Label Propagation by 50x and fix memory leaks. Now, it is usable for graph processing inside Structured Streaming. New algorithms were added:
New algorithms for K-core centrality, cycle detection, and maximal independent set were added. All of them are based on advanced scientific papers and operate fully in a distributed manner. New APIs: A new API for computing vertex degrees based on edge types was added. The motifs finding API now supports undirected, bidirectional, and multi-hop patterns. The #PySpark API has all the recent improvements in the Scala Core, so there is feature parity between the core and Python. Documentation improvements:
The documentation has been significantly expanded, especially the sections on the arguments and parameters of the algorithms. To simplify the onboarding process for new users, the documentation website now contains an llms.txt file in the root directory. Asking an LLM chatbot or coding assistant about how to use GraphFrames is now more efficient. It is already published in Maven Central and PyPi! Blog-post:
https://lnkd.in/dU4kRmSD

- 잘 아시다시피, 오늘날 그래프 기반 데이터 분석 기술들은 단순한 표 형식을 넘어 엔티티와 관계를 통해 객체 간의 연결성을 설명 및 분석함으로써 그 가치를 창출하는 데 중요한 도구로 자리잡았으며, 동적 환경 모델링, 비즈니스 솔루션, 사기 탐지, 전염병 예측, 추천 개인화, 학술 연구 등 다양한 분야에 응용될 수 있습니다.
- 소셜 네트워크, 온라인 플랫폼, 센서 기반 시스템의 규모, 정보 내용, 복잡성이 기하급수적으로 증가함에 따라 분석의 새로운 영역이 주목받게 되었는데, 바로 대규모 그래프 분석입니다. 사용 가능한 데이터가 빠르게 확장되면서 새로운 과제가 생겨났는데, 바로 이런 상황에서 관계형 처리, 패턴 매칭, 그래프 알고리즘을 결합한 통합 시스템 GraphFrames가 좋은 아키텍처로써 고려될 수 있습니다.
- 이번 주 오마카세는 "GraphFrames : 빅데이터 및 AI 애플리케이션을 위한 GraphX의 아키텍처 진화" 라는 제목의 내용으로 전달해드리고자 합니다. 아래에 공유드리는 관련 유튜브 영상을 통해서도 다음 프레임워크에 대한 세부적인 내용을 이해할 수 있습니다.
GraphFrames의 작동 방식
- GraphFrames는 분산 컴퓨팅에서 대규모 데이터 처리를 위한 가장 강력한 엔진으로 잘 알려진 Apache Spark의 클러스터 기반 그래프 처리를 위한 기본 라이브러리인 GraphX의 문제점을 보완한 프레임워크를 제공합니다.
- GraphX는 RDD (Resilient Distributed Datasets)의 강력한 기능과 효율적인 그래프 구축을 위해 특별히 설계된 특화 API를 결합하여 개발 시간, 표현 복잡성, 셔플 연산을 줄입니다. 이러한 통합을 통해 Spark의 기능을 활용하여 데이터 테이블에서 그래프 구조로, 또는 그 반대로 쉽게 전환할 수 있습니다.
- 하지만 GraphX는 몇 가지 한계를 가지고 있습니다. Scala만 지원하고, RDD 인터페이스만 제공하며, Spark SQL/DataFrame 엔진의 최신 최적화 기능을 활용하지 못합니다. 반면 GraphFrames는 Python, Scala, R 등의 언어에서 접근할 수 있는 DataFrame 기반 API를 제공하는 라이브러리로 폭넓은 호환성을 보장합니다.
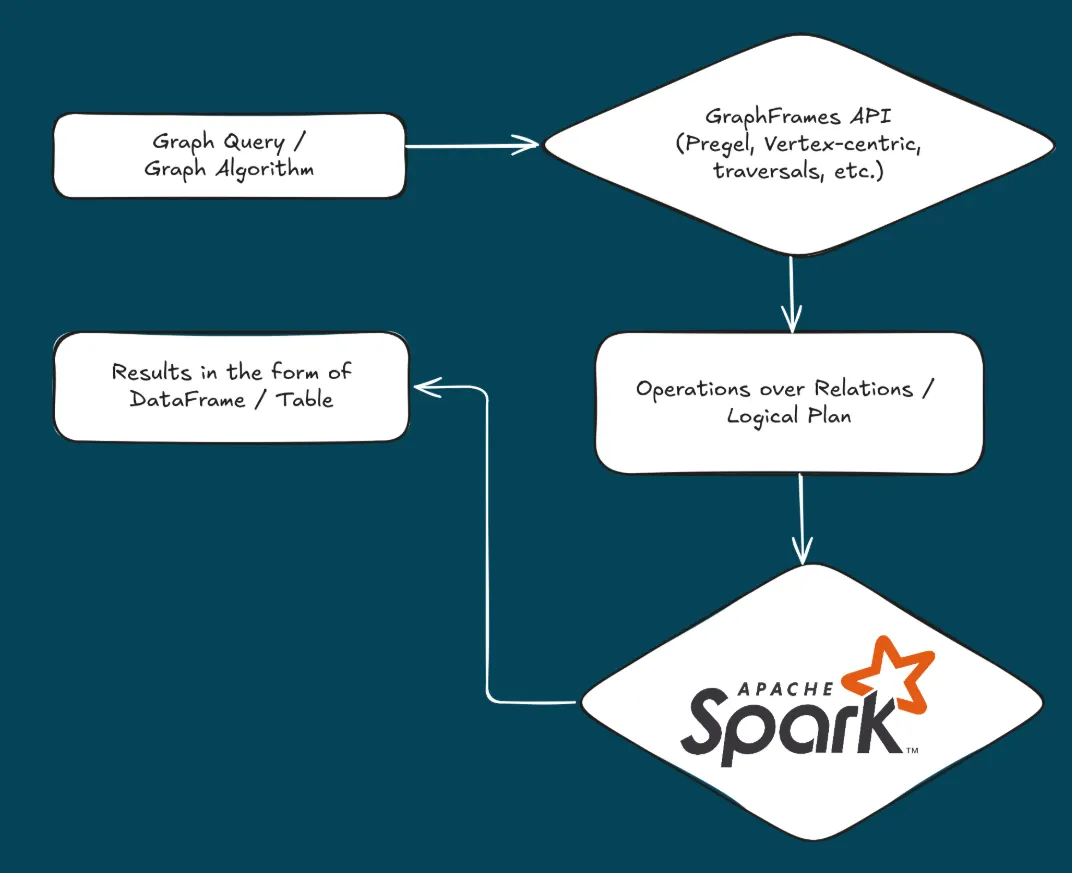
- GraphFrames가 제공하는 API는 Spark의 강력한 쿼리 최적화 프레임워크와 효율적인 메모리 관리를 위한 실행 엔진을 통해 전체 연산 시퀀스를 자동으로 최적화하고, DataFrame(SQL 테이블과 유사한 분산 데이터 구조) 기반 인터페이스를 통해 관계형 쿼리와 그래프 분석 및 알고리즘을 자연스럽게 통합하도록 설계되었습니다.
- GraphFrames는 graph-aware join optimization(데이터 구조의 특징을 명시적으로 고려하여 최적의 경로를 찾는 기술) 및 view selection 알고리즘(대용량 데이터베이스 시스템에서 쿼리 성능을 최적화하는 기술) 전략을 통해 전체적으로 최적화된 계산을 제공합니다.
- GraphFrames에 구현된 일부 알고리즘은 Pregel이라는 정점 중심 계산 모델을 활용합니다. 이는 확장 가능하고 분산된 방식으로 대규모 그래프에 대한 반복 처리를 처리하도록 설계되었습니다.
- 전통적으로 그래프 분석에는 그래프 데이터를 로드하고 준비하는 전처리 툴과, Pagerank, 최단 경로, 노드 차수 계산과 같은 알고리즘을 실행하는 엔진, 그리고 패턴 매칭, 모티프 발견, 서브그래프 추출과 같은 쿼리 기반 연산을 위한 데이터베이스 등 서로 다른 전문화된 시스템이 필요했습니다. 그러나 실제 애플리케이션에서는 이러한 작업이 중복되는 경우가 많아 모든 작업을 단일 통합 워크플로우로 통합해야 하는 필요성이 언급되어져 왔습니다.
- 이러한 관점에서 GraphFrames는 빅데이터와 AI를 연결할 수 있는 워크플로의 필수 단계들을 단일 파이프라인으로 통합할 수 있도록 지원합니다. Spark를 이용한 데이터 로딩 및 변환(ETL) , GraphFrames를 이용한 DataFrames의 그래프 구성 , 그리고 MLlib을 통한 머신 러닝 알고리즘의 직접 적용이 가능합니다.
- 이 파이프라인에서는 특징 추출 알고리즘과 그래프 분석 기법을 머신 러닝 단계 이전에 적용하여 입력 데이터를 보강할 수 있으며, 이후에는 모델링 과정의 결과를 분석하고 해석할 수 있습니다. 또한 단일 Spark 환경에서 관리되어 DataFrames의 확장성과 필요에 따라 사용자 정의 함수(UDF)를 통합할 수 있는 가능성을 활용합니다.
- 이를 통해 데이터 엔지니어링과 머신 러닝 및 그래프 분석 및 모델링을 통한 유의미한 통찰이 가능해질 것이라 기대하며, 실제로 빅데이터 환경에서 대규모 그래프 분석을 수행하는 독자 엔지니어들에게 매우 중요한 소식이라고 생각합니다. 도움이 되셨기를 바랍니다.
[Contact Info]
Gmail: jhbae1184@akane.waseda.jp
Twitter (X): @jhbae1184